TOON 协议与 AIDotNet.Toon 实践指南+Java使用指南
官方定义要点摘录(来源:toon-format/toon 仓库 README):
-
Token-efficient:通常比 JSON 少 30–60% 的 tokens(Key Features 列表) -
LLM-friendly guardrails:显式长度与字段,便于验证 -
Minimal syntax:移除冗余标点(大括号、方括号、许多引号) -
Indentation-based structure:类似 YAML,以空白缩进代替大括号 -
Tabular arrays:一次声明列头,数据按行流式书写
官方基准与工具:
-
README 的 Benchmarks 表格展示了多个数据集下的 token 节省比例;此外提供“Format Tokenization Playground”可交互比较不同格式的 token 用量 -
当前规范版本:v1.3(README 徽章与 SPEC.md 指向的专用仓库)
规范入口与一致性:
-
规范迁移至独立仓库:https://github.com/toon-format/spec(SPEC.md 明确“moved to a dedicated repository”) -
跨语言一致性依赖 conformance tests(README 的 Other Implementations 区块提供说明)
二、为什么 TOON 相比 JSON 更省 tokens
本质原因是“以结构换冗余”:在 LLM 语境下,重复的键名和标点都会占用 tokens。TOON 通过以下策略显著减少冗余(均可在 README 与语法速查中找到实例):
-
表格数组:为均匀对象数组声明一次列头,如 users[2]{id,name}: 后续行直接写 1,Alice -
行内原子数组:tags[3]: a,b,c,避免多余方括号与引号 -
键名可不加引号:安全键裸写,减少引号数量 -
缩进代替大括号:以空白表达层级
同时,官方 README 也清晰指出边界:对于深度嵌套或非均匀结构的数据,JSON 可能更高效。这意味着在“树深且分支不规则”的任务上应优先评估 JSON。
三、语法速查与对照示例
下列示例与含义对应自 README 的 Syntax Cheatsheet 与“Why TOON”示例(术语与格式请以规范 v1.3 为准):
-
对象 { id: 1, name: 'Ada' } → id: 1 换行 name: Ada
-
嵌套对象 { user: { id: 1 } } → user: 换行缩进 id: 1
-
行内原子数组 { tags: ['foo', 'bar'] } → tags[2]: foo,bar
-
表格数组(均匀对象) { items: [ { id: 1, qty: 5 }, { id: 2, qty: 3 } ] } → items[2]{id,qty}: 换行缩进 1,5 换行缩进 2,3
-
混合或非均匀数组 { items: [ 1, { a: 1 }, 'x' ] } → items[3]: 换行缩进 - 1 换行缩进 - a: 1 换行缩进 - x
四、AIDotNet.Toon:.NET 实现概览
AIDotNet.Toon 对齐 upstream 规范与设计,面向 .NET 提供与 System.Text.Json 风格一致的 API。关键入口如下:
-
序列化: C#.ToonSerializer.Serialize() · C#.ToonSerializer.Serialize() -
反序列化: C#.ToonSerializer.Deserialize() · C#.ToonSerializer.Deserialize() -
编码实现: C#.ToonEncoder.Encode() -
解码实现: C#.ToonDecoder.DecodeToJsonString() -
选项模型: C#.ToonSerializerOptions · 分隔符枚举 C#.ToonDelimiter · 默认实例 C#.ToonSerializerOptions.Default -
错误模型: C#.ToonFormatException
实现思路(节选自源码注释与 README):
-
Encode 路径:.NET 对象 → JsonElement → Encoders 结构化写出(对象、行内原子数组、表格数组、列表回退等) -
Decode 路径:TOON → 规范化 JSON 字符串 → System.Text.Json 反序列化为目标类型 -
数值与特殊值:允许命名浮点字面量,经编码阶段将 NaN 与 ±Infinity 规范化为 null,-0 规范化为 0(细节见编码器与选项)
五、安装与快速开始
通过 NuGet(发布后)或源码引入本库:
dotnet add package AIDotNet.Toonusing AIDotNet.Toon;
var options = new ToonSerializerOptions
{
Indent = 2,
Delimiter = ToonDelimiter.Comma,
Strict = true,
LengthMarker = null
};
var data = new
{
users = new[] { new { id = 1, name = "Alice" }, new { id = 2, name = "Bob" } },
tags = new[] { "a", "b", "c" },
numbers = new[] { 1, 2, 3 }
};
var text = ToonSerializer.Serialize(data, options);
// users[2]{id,name}:
// 1,Alice
// 2,Bob
// tags[3]: a,b,c
// numbers[3]: 1,2,3读取原子值:
var s = ToonSerializer.Deserialize<string>("hello", options); // "hello"
var n = ToonSerializer.Deserialize<double>("3.1415", options); // 3.1415互操作:TOON ↔ JSON ↔ .NET
// 将 TOON 文本转为目标类型,内部先经 [C#.ToonDecoder.DecodeToJsonString()](src/AIDotNet.Toon/ToonDecoder.cs:15)
var user = ToonSerializer.Deserialize<Dictionary<string, object>>("id: 1", options);
// 将 .NET 对象经 JSON DOM 编码为 TOON
var t = ToonSerializer.Serialize(new { id = 1, name = "Ada" }, options);六、选项与行为
统一选项入口 C#.ToonSerializerOptions 与默认预设 C#.ToonSerializerOptions.Default:
-
Indent:每级缩进空格数,默认 2 -
Delimiter:分隔符,枚举 C#.ToonDelimiter,用于行内与表格;底层转换为具体字符见 C#.ToonSerializerOptions.GetDelimiterChar() -
Strict:严格模式,校验缩进、空行、计数一致性等 -
LengthMarker:数组长度标记,仅支持 # 或 null -
JsonOptions:直通 System.Text.Json;默认启用 AllowNamedFloatingPointLiterals,并注册转换器以将 NaN 与 ±Infinity 写出为 null
七、错误模型与定位
解码错误统一抛出 C#.ToonFormatException 并包含错误分类与位置信息:
-
工厂方法:Syntax C#.ToonFormatException.Syntax() · Range C#.ToonFormatException.Range() · Validation C#.ToonFormatException.Validation() · Indentation C#.ToonFormatException.Indentation() · Delimiter C#.ToonFormatException.Delimiter()
八、进阶示例
-
表格数组写出
var rows = new[] { new { id = 1, name = "alice" }, new { id = 2, name = "bob" } };
var toon = ToonSerializer.Serialize(rows, options);
// [2]{id,name}:
// 1,alice
// 2,bob-
行内原子数组
var arr = new[] { 1, 2, 3 };
var t2 = ToonSerializer.Serialize(arr, options); // "[3]: 1,2,3"-
混合数组回退为列表
var mixed = new object[] { 1, new { a = 1 }, "x" };
var t3 = ToonSerializer.Serialize(mixed, options);
// [3]:
// - 1
// - a: 1
// - x九、何时使用 TOON,何时选 JSON
基于官方 README 的定位:当你的数据是“均匀对象数组、字段重复较多、需要给 LLM 更大输入上下文”时,TOON 通常更省 tokens 且更易校验验证;当数据“深度嵌套、非均匀或树形变化大”时,JSON 可能更高效更直接。
十、数据流与实现关系图

十一、来源与参考
-
官方仓库与 README:https://github.com/toon-format/toon -
规范仓库 v1.3:https://github.com/toon-format/spec -
README“Key Features”“Benchmarks”“Syntax Cheatsheet”“Other Implementations”板块提供了本文引用的特性描述、节省比例与示例 -
本文 .NET 实现地址:https://github.com/AIDotNet/Toon.NET
十二、结语
TOON 让 LLM 输入里的结构化数据更加紧凑、可校验、可读;AIDotNet.Toon 则在 .NET 世界提供熟悉的 API 体验与选项模型。建议从表格数组与行内原子数组的典型场景开始落地,并结合规范 v1.3 与测试数据持续验证。
Special thanks to the upstream project toon-format.
附:官方 Benchmarks 数据集节选
以下数字直接摘录自官方 README 的 Benchmarks「Token Efficiency」小节,原文与上下文见:https://github.com/toon-format/toon#benchmarks(其中提示这些数据集偏向 TOON 的优势场景:均匀表格化数据,真实效果取决于数据结构)。交互式对比工具:
Token 效率
⭐ GitHub Repositories ██████████████░░░░░░░░░░░ 8,745 tokens vs JSON (-42.3%) 15,145 vs JSON compact (-23.7%) 11,455 vs YAML (-33.4%) 13,129 vs XML (-48.8%) 17,095
📈 Daily Analytics ██████████░░░░░░░░░░░░░░░ 4,507 tokens vs JSON (-58.9%) 10,977 vs JSON compact (-35.7%) 7,013 vs YAML (-48.8%) 8,810 vs XML (-65.7%) 13,128
🛒 E-Commerce Order ████████████████░░░░░░░░░ 166 tokens vs JSON (-35.4%) 257 vs JSON compact (-2.9%) 171 vs YAML (-15.7%) 197 vs XML (-38.7%) 271
───────────────────────────────────────────────────────────────────── Total ██████████████░░░░░░░░░░░ 13,418 tokens vs JSON (-49.1%) 26,379 vs JSON compact (-28.0%) 18,639 vs YAML (-39.4%) 22,136 vs XML (-56.0%) 30,494
检索准确率
4 种大型语言模型在 154 个数据检索问题上的准确率:
gpt-5-nano → TOON ███████████████████░ 96.1% (148/154)
CSV ██████████████████░░ 91.6% (141/154)
YAML ██████████████████░░ 91.6% (141/154)
JSON compact ██████████████████░░ 91.6% (141/154)
XML █████████████████░░░ 87.0% (134/154)
JSON █████████████████░░░ 86.4% (133/154)
claude-haiku-4-5-20251001 JSON ██████████░░░░░░░░░░ 50.0% (77/154) YAML ██████████░░░░░░░░░░ 49.4% (76/154) → TOON ██████████░░░░░░░░░░ 48.7% (75/154) XML ██████████░░░░░░░░░░ 48.1% (74/154) CSV █████████░░░░░░░░░░░ 47.4% (73/154) JSON compact █████████░░░░░░░░░░░ 44.2% (68/154)
gemini-2.5-flash
CSV ██████████████████░░ 87.7% (135/154)
XML ██████████████████░░ 87.7% (135/154)
→ TOON █████████████████░░░ 86.4% (133/154)
YAML ████████████████░░░░ 79.9% (123/154)
JSON compact ████████████████░░░░ 79.9% (123/154) JSON ███████████████░░░░░ 76.6% (118/154)
grok-4-fast-non-reasoning → TOON ██████████░░░░░░░░░░ 49.4% (76/154) JSON ██████████░░░░░░░░░░ 48.7% (75/154) XML █████████░░░░░░░░░░░ 46.1% (71/154) YAML █████████░░░░░░░░░░░ 46.1% (71/154) JSON compact █████████░░░░░░░░░░░ 45.5% (70/154) CSV █████████░░░░░░░░░░░ 44.2% (68/154)
注意:上述样本强调 TOON 在“均匀对象数组/表格化数据”场景的节省效果;对于深度嵌套或非均匀数据,官方 README 指出 JSON 可能更高效。建议在落地前结合自身数据结构评估与小规模验证。
LLM调用的最佳数据格式:TOON,成本直降50%|附Java使用指南
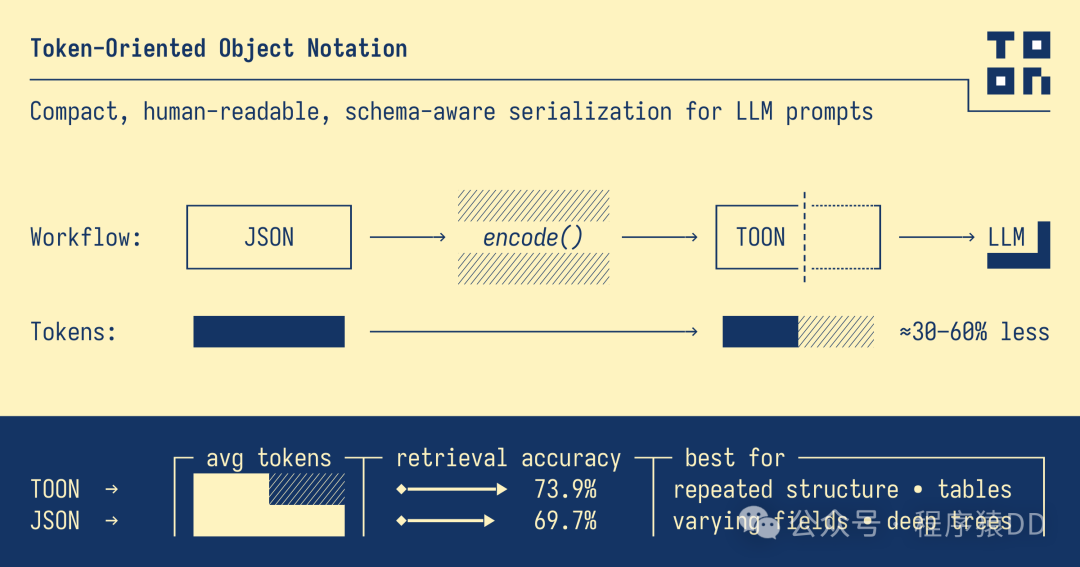
在大模型逐渐融入业务系统的阶段,结构化数据输入/输出已成为落地应用的必需:RAG 检索结果、Agent 工具调用参数、业务查询结果、批处理列表等都需要让自然语言与“可机读”的结构化格式互通。事实标准是 JSON,但在高频调用、海量数据场景下,JSON 的标点开销会显著推高 token 成本。
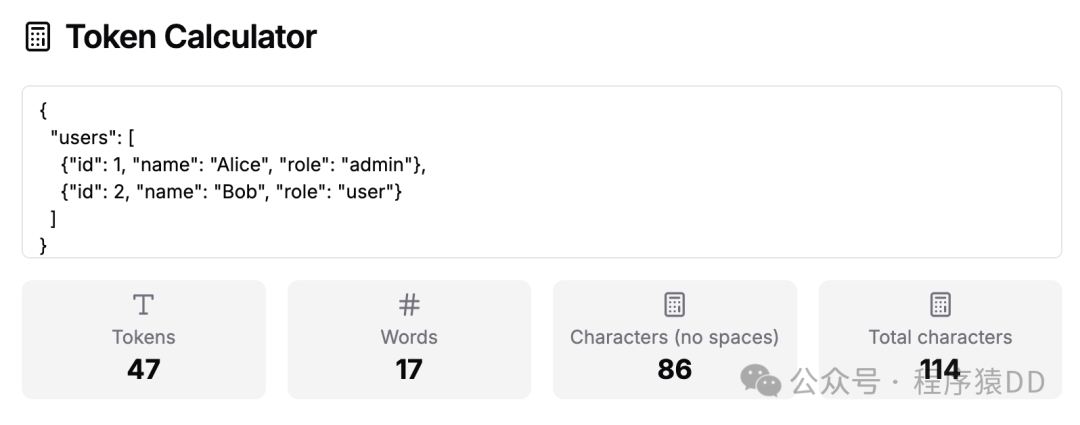
如下JSON格式的例子:
{
"users": [
{"id": 1, "name": "Alice", "role": "admin"},
{"id": 2, "name": "Bob", "role": "user"}
]
}Tokens 为 47:
采用 TOON 格式之后,内容明显减少:
users[2]{id,name,role}:
1,Alice,admin
2,Bob,userTokens 为:24
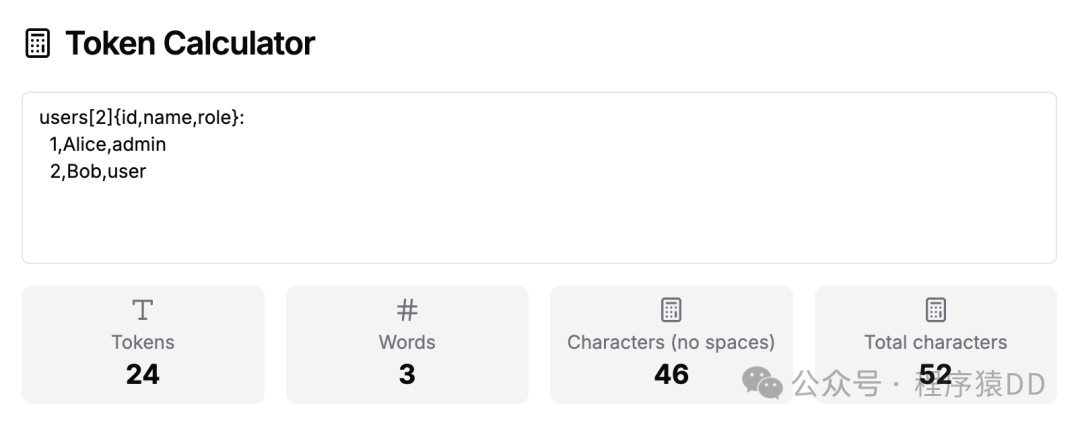
差异的核心在于:TOON 用“缩进 + 一次性字段声明”的方式消除了绝大部分语法标点的冗余;当你在生产环境每天传输成千上万条记录时,冗余标点的累计开销会直接转化为可观的 API 费用。实践表明,TOON 在输入侧常带来 40–60% 的 token 节省。
基准测试:TOKEN减少、准确率上升
TOON格式在LLM调用时候除了在Token数量上的优化之外,不可忽略的是LLM检索准确率。如果单纯Token数量减少了,而准确率下降了,那意义就不大了。
以下是TOON官方仓库给出的综合效率排名:
TOON ████████████████████ 26.9 │ 73.9% acc │ 2,744 tokens
JSON compact █████████████████░░░ 22.9 │ 70.7% acc │ 3,081 tokens
YAML ██████████████░░░░░░ 18.6 │ 69.0% acc │ 3,719 tokens
JSON ███████████░░░░░░░░░ 15.3 │ 69.7% acc │ 4,545 tokens
XML ██████████░░░░░░░░░░ 13.0 │ 67.1% acc │ 5,167 tokensTOON 的准确率达到 73.9% (JSON 的准确率为 69.7%),同时使用的标记数减少了 39.6% 。可以看到TOON不仅在Token数量上有优势,在准确率上也有明显优势。更多基准测试结果请参考TOON官方仓库:
https://github.com/toon-format/toon
什么时候不用 TOON
TOON 格式在处理统一类型的对象数组时表现出色,但在某些情况下,其他格式更为合适:
-
• 嵌套过深或结构不规则 (表格适用性 ≈ 0%):JSON-compact 通常使用较少的标记。例如:具有多个嵌套层的复杂配置对象。 -
• 半均匀数组 (约 40-60% 符合表格格式):Token节省量减少。如果您的pipline已经依赖于 JSON,则建议优先使用 JSON。 -
• 纯表格数据 :对于平面表格,CSV 比 TOON 格式文件更小。TOON 格式仅需少量额外开销(约 5-10%)即可提供结构信息(数组长度声明、字段头、分隔符作用域),从而提高 LLM 的可靠性。 -
• 对延迟要求严格的应用 :如果端到端响应时间是您的首要考虑因素,请在您的实际环境中进行基准测试。某些部署(尤其是像 Ollama 这样的本地/量化模型)即使 TOON 的Token数量较少,处理紧凑型 JSON 的速度也可能更快。请测量两种格式的 TTFT、每秒Token数和总时间,并使用速度更快的格式。
Java 中如何使用 TOON
对于数据格式转换,各主流语言都有好用的SDK可以直接拿来使用。以Java为例,可以使用:
<dependency>
<groupId>com.felipestanzani</groupId>
<artifactId>jtoon</artifactId>
<version>0.1.2</version>
</dependency>用法也是非常简单,核心API如下:
// Java 对象 → TOON 字符串
String toon = JToon.encode(object);
// JSON 字符串 → TOON
String toon = JToon.encodeJson(jsonString);
// TOON → Java 对象
Object obj = JToon.decode(toonString);
// TOON → JSON 字符串
String json = JToon.decodeToJson(toonString);小结
本文介绍了LLM调用时JSON格式调用在Token消耗的劣势,从而引出TOON格式。对于合适场景,如果目前Token消耗量偏高的应用,可以考虑在数据格式上进行优化,从而实现成本的优化。目前你都用什么格式呢?是否有用过TOON呢?留言区可以聊一聊。
LLM调用的最佳数据格式:TOON,成本直降50%|附Java使用指南

 浙公网安备 33010602011771号
浙公网安备 33010602011771号