MySQL高效分页-mybatis插件PageHelper改进
MySQL分页在表比较大的时候,分页就会出现性能问题,MySQL的分页逻辑如下:比如select * from user limit 100000,10
它是先执行select * from user 扫描满足这个SQL语句,拿到执行结果后, 一页一页的找到行号为100000的行,返回接下来的10行数据,出现性能问题的原因有两个,1:它先全表扫描了,整个表,而不是扫描到了满足条件的数据就不扫描了,比如select * from user limit 1,10 这个,它不是扫描到满足条件的10行数据就完事了,而是扫描了整个表,然后从这个结果集中从上往下扫描,只到找到行号为1的后面10行数据,这里出现性能问题的原因2就在于MySQL的寻找行号的逻辑是怎么寻找的,是不是像如果是像数组那样通过下标一步定位行号就不存在页码大小的问题了,但是MySQL不是一步到位的找到这个页码的,具体是怎么找到页码的感兴趣的可以去看MySQL的源码,我们能做的就是将MySQL的逻辑转换为直接定位数据的位置。
比如Mybatis 上的SQL语句为
<select id="queryUserListLikeName" parameterType="java.lang.String" resultType="com.entity.user">
select
<include refid="Base_Column_List" />
from user t
WHERE t.name LIKE '%${name}%'
order by id desc
</select>
mybatis的 PageHelper 插件会在上面直接加上 limit 语句,源码如下
public class MySqlDialect extends AbstractHelperDialect {
@Override
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
if (page.getStartRow() == 0) {
sqlBuilder.append(sql);
sqlBuilder.append(" LIMIT ");
sqlBuilder.append(page.getPageSize());
} else{
sqlBuilder.append(sql);
sqlBuilder.append(" LIMIT ");
sqlBuilder.append(page.getStartRow());
sqlBuilder.append(",");
sqlBuilder.append(page.getPageSize());
pageKey.update(page.getStartRow());
}
pageKey.update(page.getPageSize());
return sqlBuilder.toString();
}
就是直接调用MySQL的分页limit函数。
如何mybatis的PageHelper插件能将我们的SQL语句改成如下,那就大大提高大表的翻页查询效率,我本人亲七万行数据的表分页到最后一页这种方式比直接limit的方式快10倍,更大的表效率更大,其实原理很简单,我们给查询结果集加一个行号,查询出ID,和行号,再和原表通过ID关联,因为关联走了索引,索引速度很快,然后直接通过行号定位数据,速度大大提高
select id, name from
(Select id as id2,(@rowNum:=@rowNum+1) as rowNo From user,(Select (@rowNum :=0) ) b) r ,
user t
where r.id2= t.id and r.rowNo> 100000 and t.name like '%小明%' order by id desc LIMIT 10
我们来修改mybatis的源码:其实非常简单。如下
很多人可能mybaits的分页插件都没用过,我这里也将其全部使用过程。
我用的springboot
在pom.xml中引入:
<!-- 分页插件pagehelper -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.0.0</version>
</dependency>
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-autoconfigure</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.3</version>
</dependency>
<!-- 分页插件pagehelper -->
如果你的mybatis版本和它的不同可能会提示有的jar没有啥的,我的用的是
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
接下来就直接使用就行了比如在controller中直接使用
@RequestMapping(value = "/")
@ResponseBody
public Object say(HttpServletRequest request) {
PageHelper.startPage(2, 4);//仅仅一行代码就搞定,没有其他的地方要改了。其他代码原来怎么写还是怎么写
List<user> list = userMapper.queryUserListLikeName("小明");
pagedata pagedata= new pagedata(list);//这个pagedata对象是我自己写的,我嫌mybatis提供的太啰嗦,主要是 从list中拿到实际的对象。
return pagedata;
}
接下来我们来修改mybatis分页插件的拼接limit语句的逻辑代码,方法非常简单,新建一个这样的类,下面的的代码全部不要改,包名,类名都不能改。其目的就是利用Java类加载机制,替代其原来jar包里面有的这个对象,因为这个对象已经存在了,Java就不会再去加载其原来插件里面的这个对象了,从而巧妙的修改了其源码。
package com.github.pagehelper.dialect.helper;
import org.apache.ibatis.cache.CacheKey;
import com.github.pagehelper.Page;
import com.github.pagehelper.dialect.AbstractHelperDialect;
/**
* @author yangjiangcai
* qq 1097657841
*/
public class MySqlDialect extends AbstractHelperDialect {
@Override
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sql= sql.toLowerCase();//全部转换成小写形式
if (page.getStartRow() == 0) {
sqlBuilder.append(sql);
sqlBuilder.append(" LIMIT ");
sqlBuilder.append(page.getPageSize());
}
else if(page.getStartRow()>10000&&this.inSingletonTable(sql)){//判断是否是大页码并且单表查询
String[] tables = this.getTableName(sql);
String sql1 =sql.split(tables[0])[0];
sqlBuilder.append(sql1);
sqlBuilder.append(" (Select id as id2,(@rowNum:=@rowNum+1) as rowNo From ");
sqlBuilder.append(tables[0]);
sqlBuilder.append(",(Select (@rowNum :=0) ) b) r ,");
sqlBuilder.append(tables[0]);
sqlBuilder.append(" ");
sqlBuilder.append(tables[1]!=null?tables[1]:" ");
sqlBuilder.append(" where r.id2= ");
sqlBuilder.append(tables[1]!=null?tables[1]:tables[0]);
sqlBuilder.append(".id ");
sqlBuilder.append(" and r.rowNo> ");
sqlBuilder.append(page.getStartRow());
if (sql.contains("where")) {//拼接原来SQL语句中的where语句后面的语句
sqlBuilder.append(" and ");
sqlBuilder.append(sql.split("where")[1]);
}else {
//拼接原有的SQL表名后面的一段后面
if (tables[1]!=null) {//表有别名
String[] sql2 =sql.split(tables[1]);
sqlBuilder.append(" ");
sqlBuilder.append(sql2.length>1?sql2[1]:" ");
}else {
String[] sql2 =sql.split(tables[0]);
sqlBuilder.append(" ");
sqlBuilder.append(sql2.length>1?sql2[1]:" ");
}
}
sqlBuilder.append(" LIMIT ");
sqlBuilder.append(page.getPageSize());
}else{
sqlBuilder.append(sql);
sqlBuilder.append(" LIMIT ");
sqlBuilder.append(page.getStartRow());
sqlBuilder.append(",");
sqlBuilder.append(page.getPageSize());
pageKey.update(page.getStartRow());
}
pageKey.update(page.getPageSize());
return sqlBuilder.toString();
}
private boolean inSingletonTable(String sql) {
if (sql.contains("join")||sql.contains("JOIN")) {
return false;
}
if (sql.contains("where")) {
if (sql.contains("from")) {
String tables= sql.split("from")[1].split("where")[0];
if (tables.contains(",")) {
return false;
}
}
}
return true;
}
private String[] getTableName(String sql) {
String[] tables = new String[2];
if (sql.contains("where")) {
String tablenames = sql.split("from")[1].split("where")[0];
tablenames = this.removekg(tablenames);//删除表名前后的空格
if (tablenames.contains(" ")) {
tables=tablenames.split(" ");
return tables;
}else {
tables[0]=tablenames;
return tables;
}
} else if (sql.contains("group")&&!sql.contains("order")) {
String tablenames = sql.split("from")[1].split("group")[0];
tablenames = this.removekg(tablenames);//删除表名前后的空格
if (tablenames.contains(" ")) {
tables=tablenames.split(" ");
return tables;
}else {
tables[0]=tablenames;
return tables;
}
} else if (sql.contains("order")&&!sql.contains("group")) {
String tablenames = sql.split("from")[1].split("order")[0];
tablenames = this.removekg(tablenames);//删除表名前后的空格
if (tablenames.contains(" ")) {
tables=tablenames.split(" ");
return tables;
}else {
tables[0]=tablenames;
return tables;
}
} else if (sql.contains("order")&&sql.contains("group")) {
int orderIndex =sql.indexOf("order");
int groupIndex =sql.indexOf("group");
if (orderIndex<groupIndex) {
String tablenames = sql.split("from")[1].split("order")[0];
tablenames = this.removekg(tablenames);//删除表名前后的空格
if (tablenames.contains(" ")) {
tables=tablenames.split(" ");
return tables;
}else {
tables[0]=tablenames;
return tables;
}
}else {
String tablenames = sql.split("from")[1].split("group")[0];
tablenames = this.removekg(tablenames);//删除表名前后的空格
if (tablenames.contains(" ")) {
tables=tablenames.split(" ");
return tables;
}else {
tables[0]=tablenames;
return tables;
}
}
}else if (!sql.contains("where")&&!sql.contains("order")&&!sql.contains("group")) {
String tablenames = sql.split("from")[1];
tablenames = this.removekg(tablenames);//删除表名前后的空格
if (tablenames.contains(" ")) {
tables=tablenames.split(" ");
return tables;
}else {
tables[0]=tablenames;
return tables;
}
}
return tables;
}
//删除字符串两头的空格
private String removekg(String textContent) {
textContent = textContent.trim();
while (textContent.startsWith(" ")) {//这里判断是不是全角空格
textContent = textContent.substring(1, textContent.length()).trim();
}
while (textContent.endsWith(" ")) {
textContent = textContent.substring(0, textContent.length() - 1).trim();
}
return textContent;
}
}
完了,逻辑就这样简单。这里我是给他加了一个分支逻辑,当页码很大的时候,并且是单表查询的时候执行我这个分页SQL的拼接逻辑,多表关联的以后我想到好方法了再帖出来。
前端收到的{"data":[{"id":1,"name":"小明55"}],"pageNum":1,"pageSize":4,"total":1,"pages":1}
List<user> list = userMapper.queryUserListLikeName("小明");
//简单封装
pagedata pagedata= new pagedata(list);
return pagedata;
pagedata 对象的代码我也帖到下面来,你们完全可以不使用,想用的就用吧,这个对象是纯Java写的,不依赖任何依赖
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
public class pagedata implements Serializable{
/**
*
*/
private static final long serialVersionUID = 1L;
// Page{count=true, pageNum=1, pageSize=2, startRow=0, endRow=2, total=10, pages=5, reasonable=false, pageSizeZero=false}
private List data;
private int pageNum;
private int pageSize;
private int total;
private int pages;
public pagedata(List list) {
if (list instanceof com.github.pagehelper.Page) {
this.data=new ArrayList<>();
for (Object object : list) {
data.add(object);
}
String strs= list.toString();
this.pageNum=Integer.parseInt(getVluse(strs,"pageNum"));
this.pageSize= Integer.parseInt(getVluse(strs,"pageSize"));
this.total= Integer.parseInt(getVluse(strs,"total")) ;
this.pages= Integer.parseInt(getVluse(strs,"pages"));
}
}
public List getData() {
return data;
}
public int getPageNum() {
return pageNum;
}
public void setPageNum(int pageNum) {
this.pageNum = pageNum;
}
public int getPageSize() {
return pageSize;
}
public int getTotal() {
return total;
}
public int getPages() {
return pages;
}
@Override
public String toString() {
return "pagedata [data=" + data + ", pageNum=" + pageNum + ", pageSize=" + pageSize
+ ", total=" + total + ", pages=" + pages + "]";
}
/*
* 直接从json字符串中获取对应key的value值
* */
public static String getVluse(String jsonStr,String key) {
//本方法大概耗时25纳秒
char[] strs = jsonStr.toCharArray();
String result="";
for (int i = jsonStr.indexOf(key)+key.length()+1; i < strs.length; i++) {
if (strs[i]!=','&&strs[i]!='}') {
result+=strs[i];
}else {
return result;
}
}
return "";
}
}
MyBatis-Plus 自带分页 PaginationInterceptor 对象,但想要用 MyBatis-Plus 自带的分页功能的话需要在 mapper 对象中传入一个 Page 对象才可以实现分页,这样耦合度是不是太高了一点,从 web 到 service 到 mapper,这个 Page 对象一直都在传入,这样的使用让人感觉有点麻烦,但是 Mapper Plus 不得不说真的是很好用的。
PageHelper 是国内非常优秀的一款开源的 mybatis 分页插件,它支持基本主流与常用的数据库,例如 mysql、oracle、mariaDB、DB2、SQLite、Hsqldb 等。只要一行代码就能实现分页
现在将这两个好用的框架整合在一起
1. pom 引入
<!--pagehelper分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.5</version>
</dependency>
<!-- Mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.2.0</version>
</dependency> 我用的是 Spring Boot 框架,在 pom 中直接引入 MyBatis Plus 和 PageHelper 就可以了;
2. 配置文件
MyBatis-Plus的配置我就不贴出来了,主要贴出 PageHelper 的配置
application.properties
#分页插件会自动检测当前的数据库链接,自动选择合适的分页方式。 你可以配置helperDialect 属性来指定分页插件使用哪种方言。
pagehelper.helper-dialect=mysql
#分页合理化参数,默认值为 false 。当该参数设置为 true 时, pageNum<=0 时会查询第一页, pageNum>pages (超过总数时),会查询最后一页。
pagehelper.reasonable=true
#支持通过Mapper接口参数传递page参数,默认值为falset
pagehelper.support-methods-arguments=true
#默认值为 false ,当该参数设置为 true 时,如果 pageSize=0 或者 RowBounds.limit =0 就会查询出全部的结果(相当于没有执行分页查询,但是返回结果仍然是 Page 类型)。
pagehelper.pageSizeZero=true
#为了支持 startPage(Object params) 方法,增加了该参数来配置参数映射,用于从对象中根据属性名取值
pagehelper.params=count=countSqlapplication.yml
pagehelper:
auto-dialect: mysql
reasonable: true
support-methods-arguments: true
page-size-zero: true
params: count=countSql3. 使用
使用起来很方便,我用一个 controller 的 list 接口作为示范
@RequestMapping("/page/{pn}")
public ResultData<PageInfo> cityPage(@PathVariable Integer pn){
try {
//1.引入分页插件,pageNum是第几页,pageSize是每页显示多少条,默认查询总数count
Page<City> page = PageHelper.startPage(pn,3);
//2.紧跟的查询就是一个分页查询-必须紧跟.后面的其他查询不会被分页
List<City> cityList = cityService.list();
//3.使用PageInfo包装查询后的结果,3是连续显示的条数
PageInfo pageInfo = new PageInfo(cityList, 3);
}finally {
//清理 ThreadLocal 存储的分页参数,保证线程安全
PageHelper.clearPage();
}
return new ResultData<PageInfo>().setData(pageInfo);
}PageHelper.startPage(pageNum, pageSize); 这一行代码就实现了分页,
通过 PageInfo 对象将数据包装返回即可。
PageHelper 中文文档
重要提示:
- 只有紧跟在 PageHelper.startPage()方法后的第一个 Mybatis 的查询(Select)方法会被分页。
- 请不要在系统中配置多个分页插件 (使用 Spring 时,mybatis-config.xml 和 Spring 配置方式,请选择其中一种,不要同时配置多个分页插件)!
- 对于带有 for update 的 sql,会抛出运行时异常,对于这样的 sql 建议手动分页,毕竟这样的 sql 需要重视。
- 由于嵌套结果方式会导致结果集被折叠,因此分页查询的结果在折叠后总数会减少,所以无法保证分页结果数量正确。
4. 效果
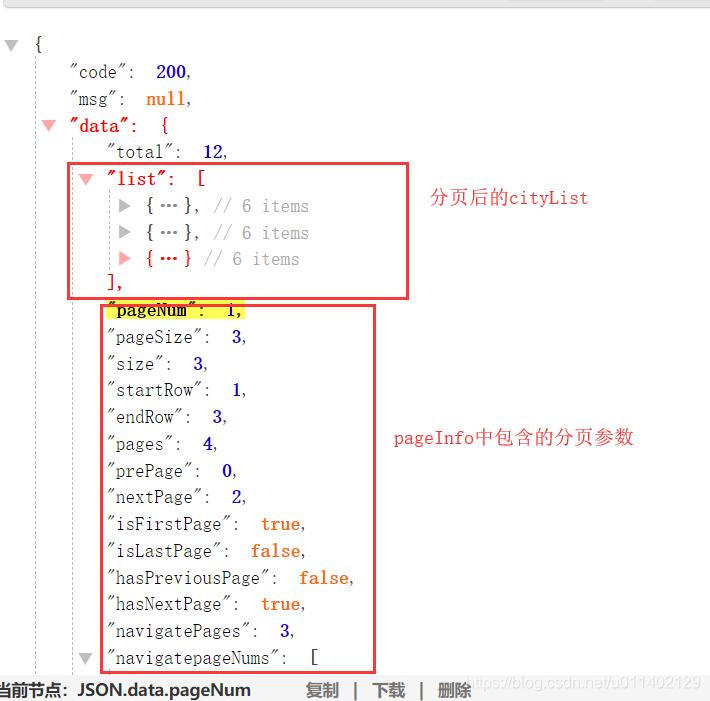
未分页
PageInfo 类所有属性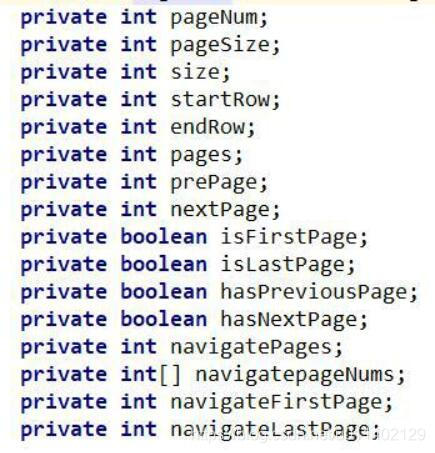
pageNum:当前为第几页
pageSize:每页的数据行数
startRow:当前页数据从第几条开始
endRow:当前页数据从第几条结束
pages:总页数
prePage:上一页页数
nextPage:下一页页数
hasPreviousPage:是否有上一页
hasNextPage:是否有下一页
navigatepageNums:所有页码的数组
我们可以根据这几个属性控制页面切换的操作,比如 hasPreviousPage 为 false 表示没有上一页,
当前为首页,我们可以控制页面不显示或者不能使用首页和上一页功能。非常的简单。
下面是我做的一个小项目示例图: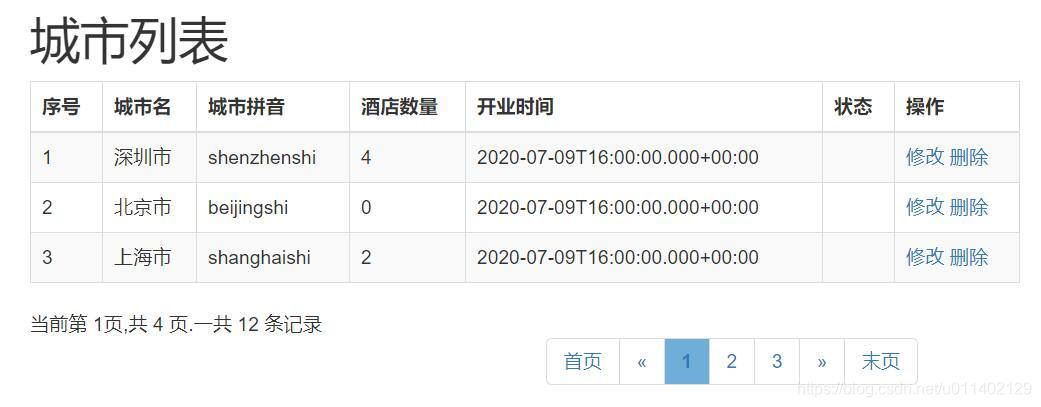
有人说 PageHelper 是不安全的分页?
实际上 PageHelper 方法使用了静态的 ThreadLocal 参数,分页参数和线程是绑定的。
只要你可以保证在 PageHelper 方法调用后紧跟 MyBatis 查询方法,这就是安全的。因为 PageHelper 在 finally 代码段中自动清除了 ThreadLocal 存储的对象。
参考博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号