
2025,每天10分钟,跟我学K8S(四十一)- Dashboard
2025,每天10分钟,跟我学K8S(四十一)- Dashboard_kubernetes dashboard-CSDN博客
什么是Kubernetes Dashboard?
Kubernetes Dashboard 是 Kubernetes 官方提供的可视化 Web 界面,用于简化集群资源管理和监控操作。简单来说,就是我们之前的所有操作,都是通过 kubectl 命令来完成的,为了简便操作,官方提供了一个web控制台,很多操作可以通过控制台来完成。例如通过 Dashboard 部署容器化的应用、监控应用的状态、执行故障排查任务以及管理 Kubernetes 各种资源。
一、核心功能与适用场景
-
核心功能
- 资源管理:支持 Pod、Deployment、Service 等资源的创建、删除、更新及弹性伸缩操作。
- 监控与排障:实时查看资源状态、容器日志及事件告警,支持 Pod 终端访问。
- 配置管理:通过 YAML 文件或表单直接修改资源配置,支持批量操作。
- 权限控制:集成 RBAC 机制,可精细化控制用户操作权限。
-
适用场景
- 开发测试:快速验证资源配置,避免频繁使用
kubectl命令。 - 运维监控:集中查看集群健康状态,定位资源瓶颈。
- 多租户管理:通过命名空间隔离不同团队资源,降低误操作风险。
- 开发测试:快速验证资源配置,避免频繁使用
二、安装演示
目前官方Dashboard 版本为kubernetes-dashboard-7.11.1,而从7版本开始,官方已经只支持helm的方式安装。所以本文也采用helm方式安装。
2.1 添加仓库并安装
官方演示操作为下面步骤
-
# 添加 Helm 仓库并部署
-
helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
-
-
helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard
但是由于国内网络问题,可能无法添加官方源,只能去github上将软件包下载到本地
 https://github.com/kubernetes/dashboard/releases/download/kubernetes-dashboard-7.11.1/kubernetes-dashboard-7.11.1.tgz
https://github.com/kubernetes/dashboard/releases/download/kubernetes-dashboard-7.11.1/kubernetes-dashboard-7.11.1.tgz-
# 下载
-
root@k8s-master:~/dashboard# wget https://github.com/kubernetes/dashboard/releases/download/kubernetes-dashboard-7.11.1/kubernetes-dashboard-7.11.1.tgz
-
-
# 解压
-
root@k8s-master:~/dashboard# tar zxvf kubernetes-dashboard-7.11.1.tgz
-
kubernetes-dashboard/Chart.yaml
-
-
# 查看目录结构
-
root@k8s-master:~/dashboard# tree
-
.
-
├── kubernetes-dashboard
-
│ ├── Chart.lock
-
│ ├── charts
-
│ │ ├── cert-manager
-
│ │ │ ├── Chart.yaml
-
│ │ │ ├── README.md
-
......

2.2 修改镜像地址
-
vim kubernetes-dashboard/values.yaml
-
-
repository: docker.io/kubernetesui/dashboard-auth
-
repository: docker.io/kubernetesui/dashboard-web
-
repository: docker.io/kubernetesui/dashboard-metrics-scraper
-
repository: docker.io/kubernetesui/dashboard-api
-
====修改为====
-
repository: m.daocloud.io/docker.io/kubernetesui/dashboard-auth
-
repository: m.daocloud.io/docker.io/kubernetesui/dashboard-web
-
repository: m.daocloud.io/docker.io/kubernetesui/dashboard-metrics-scraper
-
repository: m.daocloud.io/docker.io/kubernetesui/dashboard-api
-
-
-
-
-
vim kubernetes-dashboard/charts/kong/values.yaml
-
repository: kong
-
====修改为====
-
repository: m.daocloud.io/docker.io/kong
-
-
-
-
-
-
# 安装
-
root@k8s-master:~/dashboard# helm upgrade --install kubernetes-dashboard kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard
-
Release "kubernetes-dashboard" does not exist. Installing it now.
-
.....
-
Dashboard will be available at:
-
https://localhost:8443
-
-
-
# 等待所有pod运行正常后,查看svc和pod状态
-
root@k8s-master:~/dashboard# kubectl get pod -n kubernetes-dashboard
-
NAME READY STATUS RESTARTS AGE
-
kubernetes-dashboard-api-7744c84465-z76gq 1/1 Running 0 2m28s
-
kubernetes-dashboard-auth-5ff6f5889b-74r28 1/1 Running 0 2m28s
-
kubernetes-dashboard-kong-75dd496684-gf62v 1/1 Running 0 2m28s
-
kubernetes-dashboard-metrics-scraper-9b9f5c9d5-sgh7j 1/1 Running 0 2m28s
-
kubernetes-dashboard-web-6c8f4d7666-jskjg 1/1 Running 0 2m28s
-
root@k8s-master:~/dashboard#
-
root@k8s-master:~/dashboard# kubectl get svc -n kubernetes-dashboard
-
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
-
kubernetes-dashboard-api ClusterIP 10.102.121.61 <none> 8000/TCP 2m36s
-
kubernetes-dashboard-auth ClusterIP 10.103.103.175 <none> 8000/TCP 2m36s
-
kubernetes-dashboard-kong-proxy ClusterIP 10.99.183.86 <none> 443/TCP 2m36s
-
kubernetes-dashboard-metrics-scraper ClusterIP 10.101.165.125 <none> 8000/TCP 2m36s
-
kubernetes-dashboard-web NodePort 10.99.103.97 <none> 8000:32528/TCP 2m36s
-
2.3 创建用户和token
-
# 创建管理员账户
-
kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard
-
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin
-
# 获取 Token
-
kubectl -n kubernetes-dashboard create token dashboard-admin

注意:Token 默认有效期 1 小时,可通过 --duration=24h 延长
2.4 登录web界面验证
由于默认情况下,dashboard是没有开启nodeport对外的,所以需要临时修改端口转发类型
-
# 修改端口类型
-
kubectl patch svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard --type='json' -p '[{"op":"replace","path":"/spec/type","value":"NodePort"}]'
-
-
-
# 若需要指定端口,可以指定一个固定的 nodePort,这里修改为30083:
-
kubectl patch svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard --type='json' -p '[{"op":"add","path":"/spec/ports/0/nodePort","value":30083}]'
-
除了上述的命令行修改,还可以通过编辑配置yaml文件的方式来修改。
kubectl edit svc -n kubernetes-dashboard kubernetes-dashboard-kong-proxy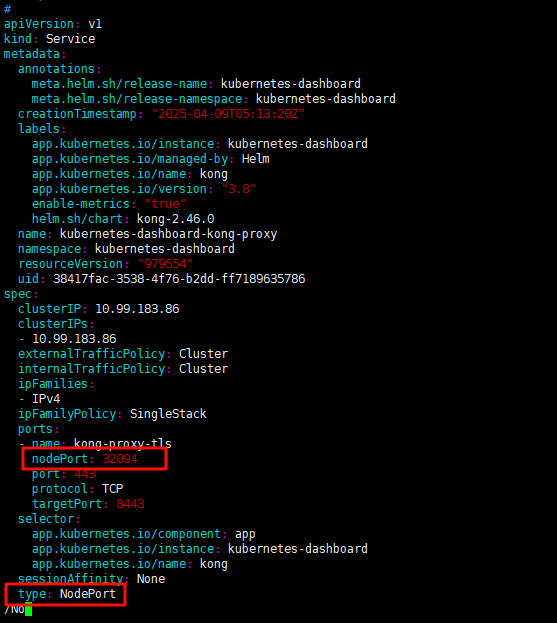
打开web浏览器,通过nodeport来访问。输入刚才获取到的token
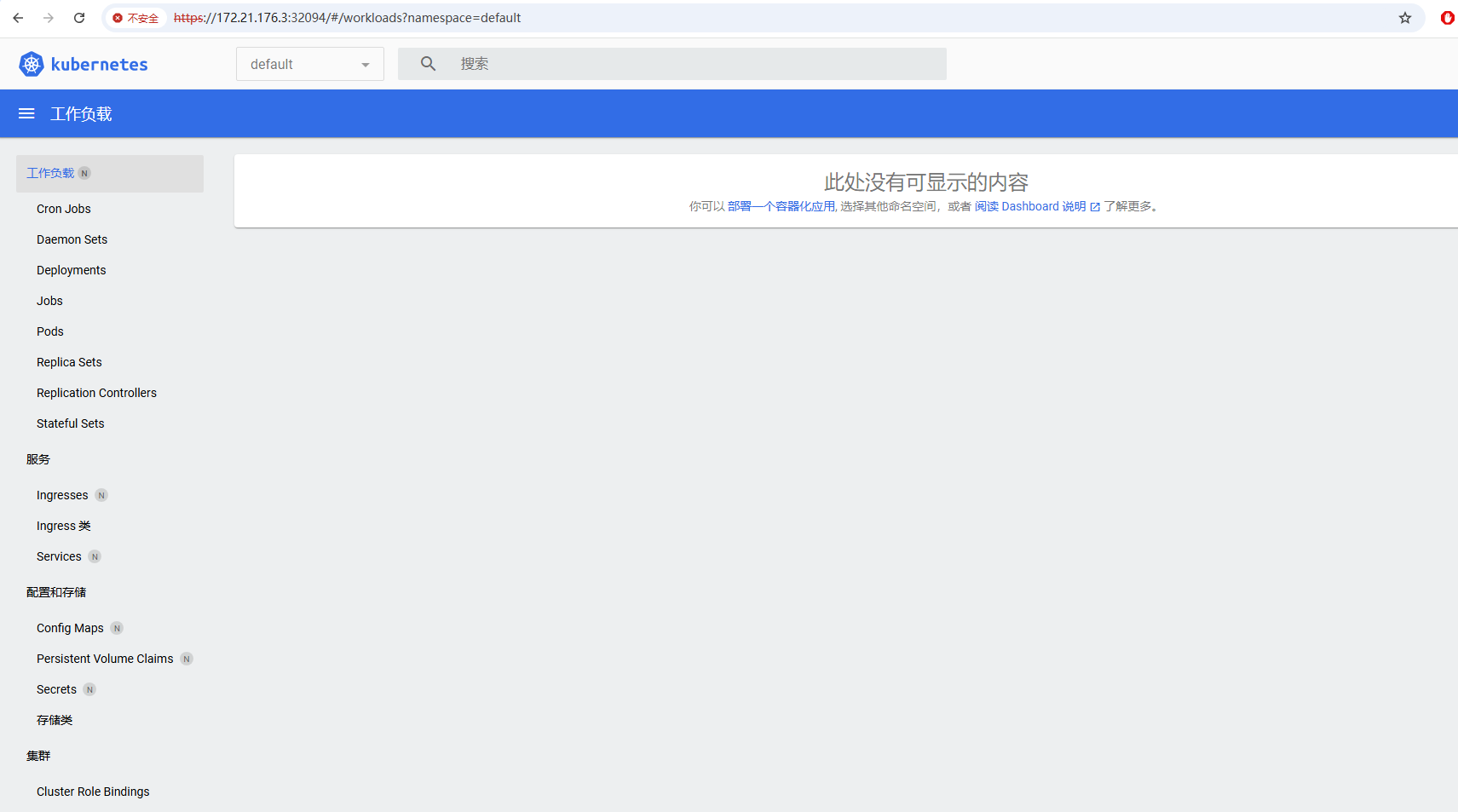
输入token后可以进入主界面,由于还没有安装监控,所以这里的负载显示为空。但是至此一步,dashboard已经安装完毕
2025,每天10分钟,跟我学K8S(四十二)- Kuboard _kuboard详解-CSDN博客
上一章,学习了k8s中的dashboard的安装,但是由于网络、厂商差异等原因,其实这个使用率并不高,有很多其他厂家的dashboard也做的挺不错,本章推荐一款国产的dashboard----Kuboard 。
Kuboard for Kubernetes
特点介绍
相较于 Kubernetes Dashboard 等其他 Kubernetes 管理界面,Kuboard 的主要特点有:
-
多种认证方式
-
多集群管理
-
微服务分层展示
-
工作负载的直观展示
-
工作负载编辑
-
存储类型支持
-
丰富的互操作性
-
套件扩展
-
告警配置
-
操作审计
具体内容可以参考官网:Kuboard_Kubernetes教程_K8S安装_管理界面
Kuboard的安装
安装 kuboard
目前Kuboard生产环境已经到了V3版本,可以使用docker单独安装,也可以采用pod的方式安装。本文将采用后者。详细步骤可以参考官网:安装 Kuboard v3 - kubernetes | Kuboard
-
# 为了避免kuboard-v3-xxxxx 的容器出现 CrashLoopBackOff 的状态
-
# 给master节点打标
-
kubectl label nodes your-node-name k8s.kuboard.cn/role=etcd
-
-
-
kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
-
# 您也可以使用下面的指令,唯一的区别是,该指令使用华为云的镜像仓库替代 docker hub 分发 Kuboard 所需要的镜像
-
-
# kuboard使用了30080端口,可能会与之前设置的longhorn端口冲突,可以修改一下longhorn的端口为其他
-
# kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3-swr.yaml
安装完成后显示如下:

访问 Kuboard
-
在浏览器中打开链接
http://your-node-ip-address:30080 -
输入初始用户名和密码,并登录
- 用户名:
admin - 密码:
Kuboard123
- 用户名:

导入集群后,安装metrics-scraper就可以查看资源指标了
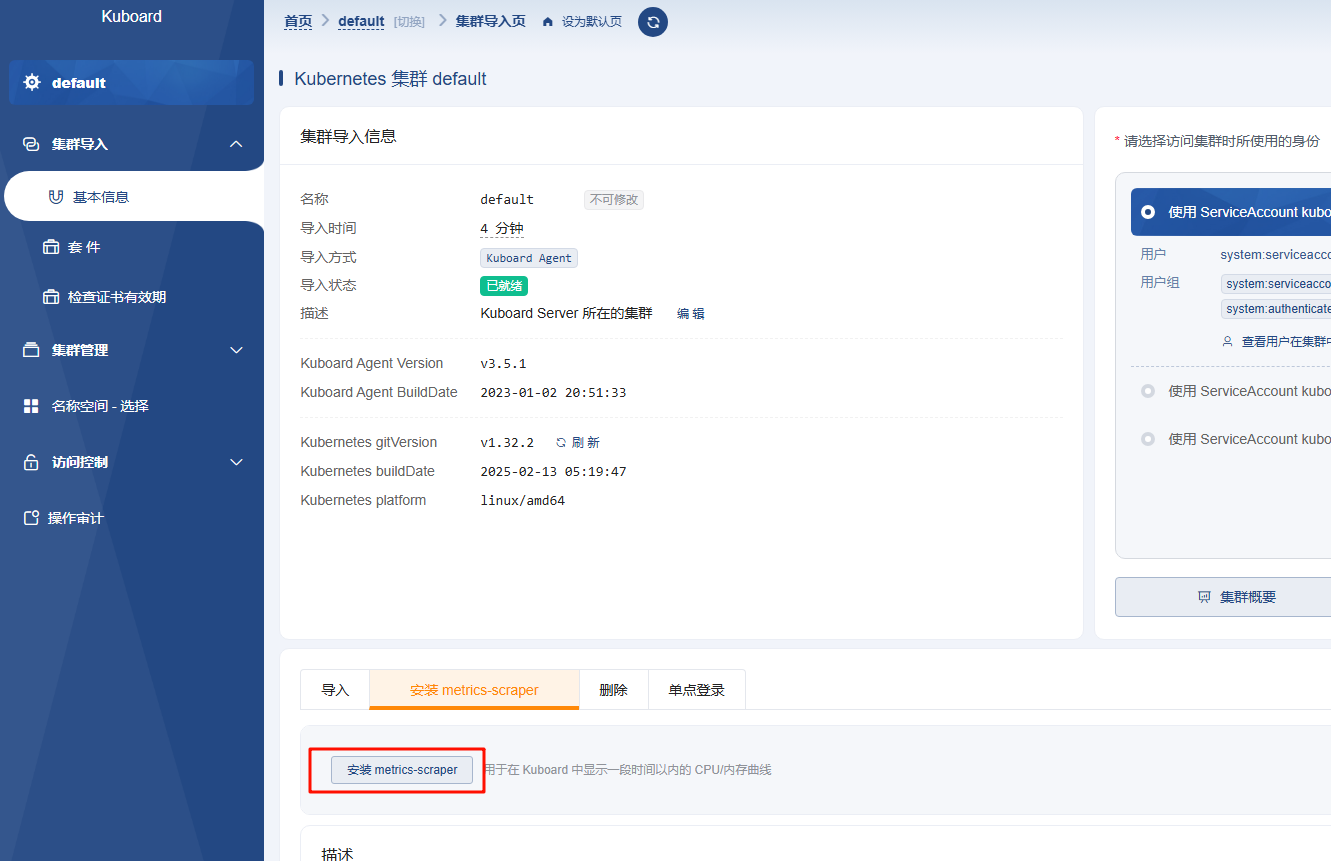
选择国内源
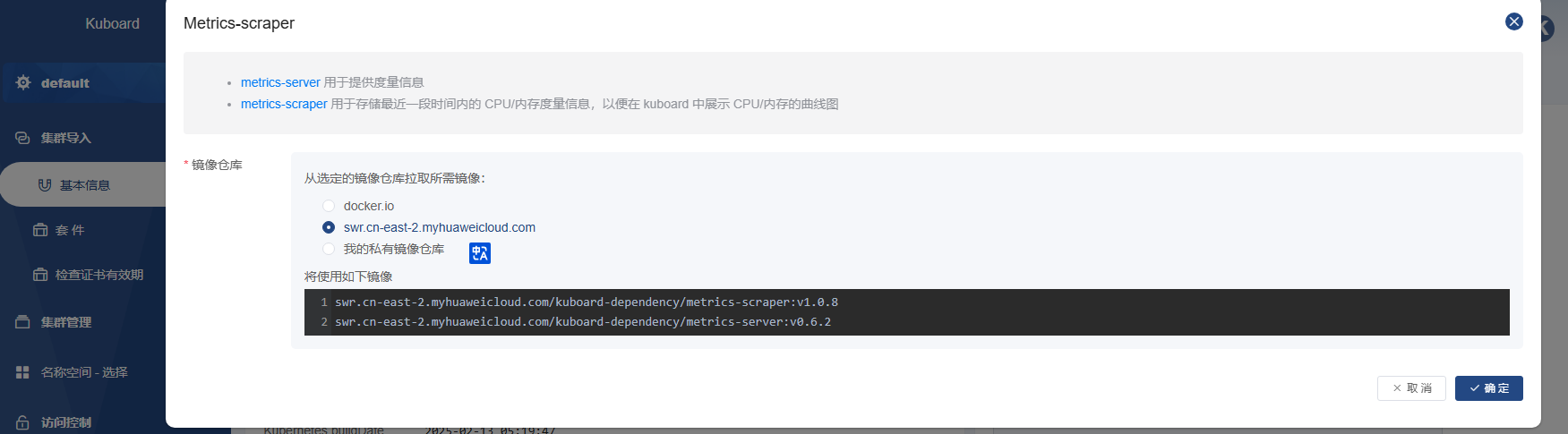
开始安装
查看硬件资质监控指标
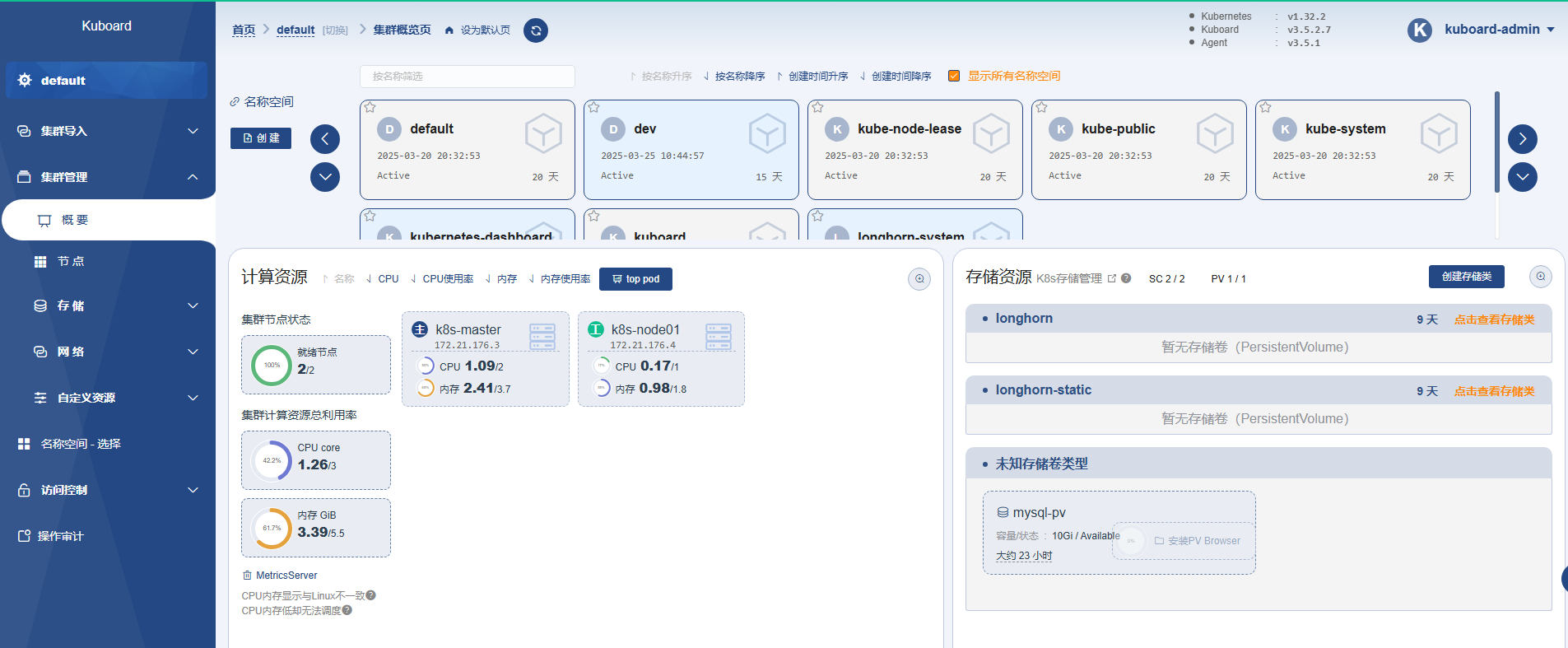
同时安装了metrics-scraper也可以在命令行查看pod或者node的资源占用
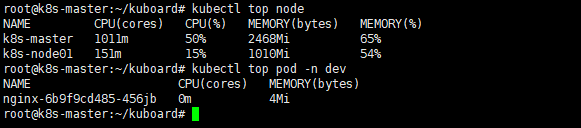
Kuboard 是一款专为 Kubernetes 设计的,强大而免费可视化管理工具,支持多集群管理、资源监控、日志聚合、权限控制等功能。相较于 Kubernetes 官方 Dashboard,Kuboard 提供更直观的界面和更丰富的扩展能力,适用于开发、运维及多团队协作场景。本文只是简单举例了它的安装和操作,更多的用户可以参考官网文档。
2025,每天10分钟,跟我学K8S(四十三)- Prometheus(一)_prometheus版本选择-CSDN博客
前面内容,讲述了很多K8S的知识点,也了解了K8S的基础使用。从本章节开始,我们一起来学习下K8S中的监控系统。作为一名合格的devopser,知道监控是生产环境不可或缺的,我们需要时刻了解系统环境的各种指标,不管是node的指标,还是pod中运行的应用的指标,在他们出现问题时候,能第一时间通过告警的方式通知到我们。
而Prometheus作为和K8S都是云原生计算基金会出品的产品,现在基本是是K8S监控的标配了。从本章开始,我们就一起来学习它。
什么是Prometheus
Prometheus 是一款开源的 时序数据库与监控告警系统,专为云原生和分布式环境设计,其核心功能是通过多维数据模型和灵活的查询语言实现对系统、应用及基础设施的全方位监控。它将所有信息都存储为时间序列数据;因此实现一种Profiling监控方式,实时分析系统运行的状态、执行时间、调用次数等,以找到系统的热点,为性能优化提供依据。
一、核心特性
1.多维数据模型
每个监控指标由 指标名称(Metric Name) 和 标签(Labels) 唯一标识,支持从多维度(如请求方法、状态码、服务实例等)对数据进行分析。例如,http_requests_total{method="GET", status="200"} 可细分统计不同请求的成功率。
2.PromQL 查询语言
提供类似 SQL 的语法,支持复杂的数据聚合、数学运算和实时计算。例如,计算 CPU 使用率:
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)种灵活性使其适用于趋势分析和故障排查。
3.主动拉取(Pull)与推送(Push)结合
- 拉取模式:Prometheus Server 定期从配置的目标(如 Exporter、应用程序端点)主动抓取指标。
- 推送模式:通过 Pushgateway 支持短生命周期任务(如批处理作业)的指标上报。
4.动态服务发现
支持 Kubernetes、Consul 等服务发现机制,自动识别并监控动态变化的服务实例,减少手动配置成本。
5.告警管理
Alertmanager 负责处理告警的去重、分组和路由,支持邮件、Webhook、Slack 等多种通知渠道。
二、核心组件
| 组件 | 功能 | 适用场景 |
|---|---|---|
| Prometheus Server | 核心服务,负责数据采集、存储(TSDB 时序数据库)和查询(PromQL) | 长期运行的监控目标(如服务器、容器) |
| Exporter | 将第三方系统(如 MySQL、Redis)的指标转换为 Prometheus 兼容格式 | 间接监控非原生支持的应用或服务 |
| Pushgateway | 临时存储短生命周期任务的指标数据,供 Server 拉取
|
批处理作业、一次性任务 |
| Alertmanager | 处理告警规则触发后的通知逻辑,支持静默、抑制和路由策略 | 告警分级管理、多级通知渠道整合 |
| Grafana | 可视化工具,提供丰富的仪表盘模板展示 Prometheus 数据 | 数据趋势分析、多维度可视化 |
三、版本选择
目前常用的Prometheus 有3个版本提供选择,Prometheus Operator 、 kube-prometheus、kube-prometheus-stack。其内在核心都是 Prometheus ,由不同的人群在维护。
Prometheus Operator
Prometheus Operator: 在 Kubernetes 上手动一步步搭建,然后管理 Prometheus 集群。该项目的目的是简化和自动化基于 Prometheus 的 Kubernetes 集群监控堆栈的配置。适合定制化方案,但是需要一步步的搭建。
kube-prometheus
基于 Prometheus Operator 的预配置方案,包含 Prometheus、Alertmanager、Grafana、kube-state-metrics 等组件,提供开箱即用的监控规则和仪表盘,并且已经安排了一个名为 prometheus-k8s 的 prometheus,默认带有警报和规则,几乎一键搭建,减少用户的配置,并且带有其他 prometheus 需要的组件,如:
- Grafana
- kube-state-metrics
- prometheus adapter
- node exporter
- ...
kube-prometheus-stack
kube-prometheus的helm版本,由社区维护的 Helm Chart,整合了 kube-prometheus 的功能,并增加兼容性优化和扩展组件(如 Thanos),支持参数化部署和版本管理
四、适用场景
-
云原生与容器监控
与 Kubernetes 深度集成,自动发现 Pod、Service 等资源,监控容器资源使用率(CPU、内存)及微服务性能。 -
微服务架构监控
通过服务发现和标签机制,追踪分布式系统中的请求链路、错误率及延迟。 -
基础设施监控
收集主机(Node Exporter)、网络设备、存储系统的指标,支持容量规划和故障预警。 -
业务指标监控
自定义业务指标(如订单量、用户活跃度),结合 PromQL 实现实时业务分析。
五、优势与局限
-
优势:
- 轻量级:单节点部署,不依赖分布式存储。
- 高扩展性:支持联邦集群(Federation)和远程存储(如 Thanos、Cortex)。
- 社区生态:CNCF 毕业项目,拥有丰富的 Exporter 和集成工具。
-
局限:
- 数据精度:适用于可靠性监控,但不适合需要 100% 准确性的计费场景。
- 长期存储:原生 TSDB 适合短期数据,长期存储需依赖外部方案。
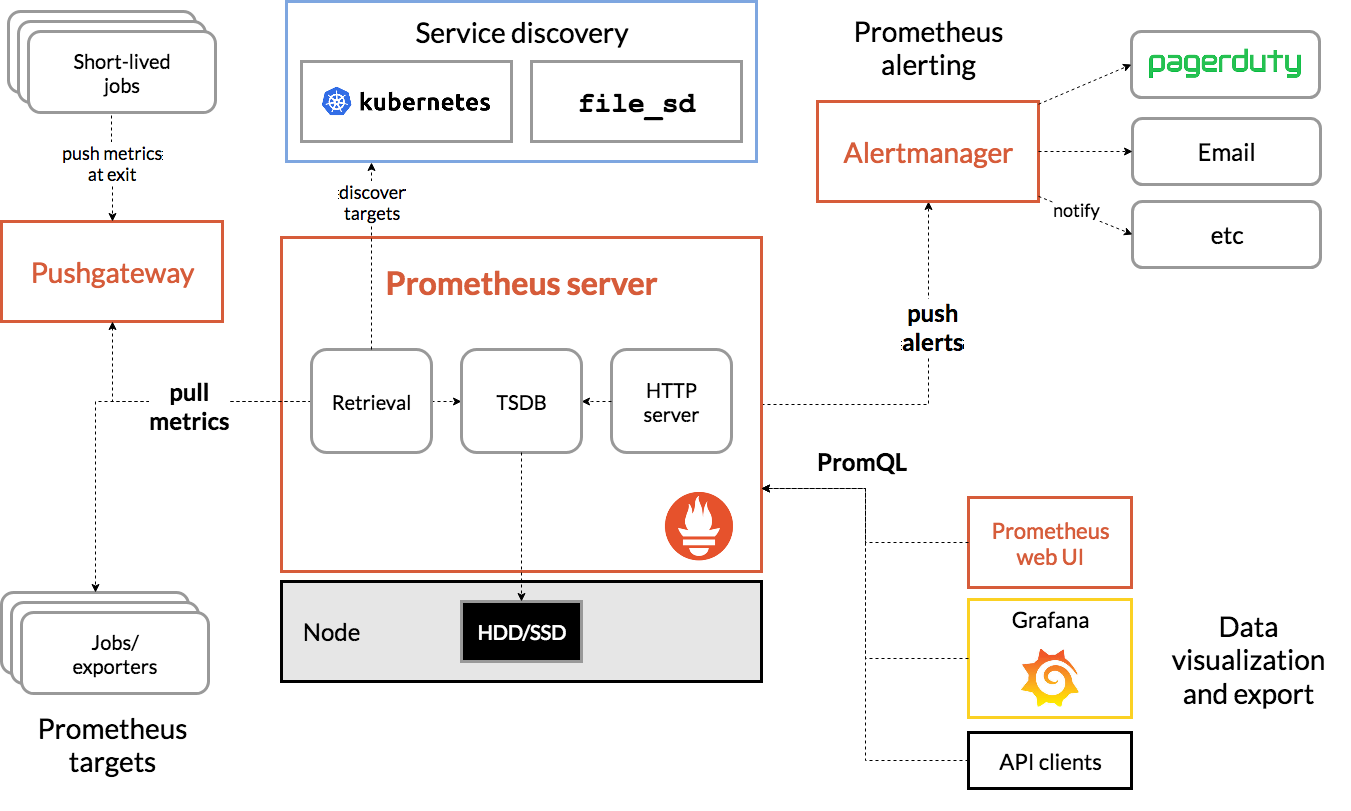
六、典型工作流程示例
- 数据采集:Prometheus Server 定期从 Node Exporter 拉取主机指标。
- 规则评估:根据
alert.rules判断 CPU 使用率是否超阈值。 - 告警触发:触发后 Alertmanager 发送邮件通知运维人员。
- 可视化展示:通过 Grafana 仪表盘实时查看监控趋势。
工作流程图:
前面内容,讲述了很多K8S的知识点,也了解了K8S的基础使用。从本章节开始,我们一起来学习下K8S中的监控系统。作为一名合格的devopser,知道监控是生产环境不可或缺的,我们需要时刻了解系统环境的各种指标,不管是node的指标,还是pod中运行的应用的指标,在他们出现问题时候,能第一时间通过告警的方式通知到我们。
而Prometheus作为和K8S都是云原生计算基金会出品的产品,现在基本是是K8S监控的标配了。从本章开始,我们就一起来学习它。
什么是Prometheus
Prometheus 是一款开源的 时序数据库与监控告警系统,专为云原生和分布式环境设计,其核心功能是通过多维数据模型和灵活的查询语言实现对系统、应用及基础设施的全方位监控。它将所有信息都存储为时间序列数据;因此实现一种Profiling监控方式,实时分析系统运行的状态、执行时间、调用次数等,以找到系统的热点,为性能优化提供依据。
一、核心特性
1.多维数据模型
每个监控指标由 指标名称(Metric Name) 和 标签(Labels) 唯一标识,支持从多维度(如请求方法、状态码、服务实例等)对数据进行分析。例如,http_requests_total{method="GET", status="200"} 可细分统计不同请求的成功率。
2.PromQL 查询语言
提供类似 SQL 的语法,支持复杂的数据聚合、数学运算和实时计算。例如,计算 CPU 使用率:
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)种灵活性使其适用于趋势分析和故障排查。
3.主动拉取(Pull)与推送(Push)结合
- 拉取模式:Prometheus Server 定期从配置的目标(如 Exporter、应用程序端点)主动抓取指标。
- 推送模式:通过 Pushgateway 支持短生命周期任务(如批处理作业)的指标上报。
4.动态服务发现
支持 Kubernetes、Consul 等服务发现机制,自动识别并监控动态变化的服务实例,减少手动配置成本。
5.告警管理
Alertmanager 负责处理告警的去重、分组和路由,支持邮件、Webhook、Slack 等多种通知渠道。
二、核心组件
| 组件 | 功能 | 适用场景 |
|---|---|---|
| Prometheus Server | 核心服务,负责数据采集、存储(TSDB 时序数据库)和查询(PromQL) | 长期运行的监控目标(如服务器、容器) |
| Exporter | 将第三方系统(如 MySQL、Redis)的指标转换为 Prometheus 兼容格式 | 间接监控非原生支持的应用或服务 |
| Pushgateway | 临时存储短生命周期任务的指标数据,供 Server 拉取
|
批处理作业、一次性任务 |
| Alertmanager | 处理告警规则触发后的通知逻辑,支持静默、抑制和路由策略 | 告警分级管理、多级通知渠道整合 |
| Grafana | 可视化工具,提供丰富的仪表盘模板展示 Prometheus 数据 | 数据趋势分析、多维度可视化 |
三、版本选择
目前常用的Prometheus 有3个版本提供选择,Prometheus Operator 、 kube-prometheus、kube-prometheus-stack。其内在核心都是 Prometheus ,由不同的人群在维护。
Prometheus Operator
Prometheus Operator: 在 Kubernetes 上手动一步步搭建,然后管理 Prometheus 集群。该项目的目的是简化和自动化基于 Prometheus 的 Kubernetes 集群监控堆栈的配置。适合定制化方案,但是需要一步步的搭建。
kube-prometheus
基于 Prometheus Operator 的预配置方案,包含 Prometheus、Alertmanager、Grafana、kube-state-metrics 等组件,提供开箱即用的监控规则和仪表盘,并且已经安排了一个名为 prometheus-k8s 的 prometheus,默认带有警报和规则,几乎一键搭建,减少用户的配置,并且带有其他 prometheus 需要的组件,如:
- Grafana
- kube-state-metrics
- prometheus adapter
- node exporter
- ...
kube-prometheus-stack
kube-prometheus的helm版本,由社区维护的 Helm Chart,整合了 kube-prometheus 的功能,并增加兼容性优化和扩展组件(如 Thanos),支持参数化部署和版本管理
四、适用场景
-
云原生与容器监控
与 Kubernetes 深度集成,自动发现 Pod、Service 等资源,监控容器资源使用率(CPU、内存)及微服务性能。 -
微服务架构监控
通过服务发现和标签机制,追踪分布式系统中的请求链路、错误率及延迟。 -
基础设施监控
收集主机(Node Exporter)、网络设备、存储系统的指标,支持容量规划和故障预警。 -
业务指标监控
自定义业务指标(如订单量、用户活跃度),结合 PromQL 实现实时业务分析。
五、优势与局限
-
优势:
- 轻量级:单节点部署,不依赖分布式存储。
- 高扩展性:支持联邦集群(Federation)和远程存储(如 Thanos、Cortex)。
- 社区生态:CNCF 毕业项目,拥有丰富的 Exporter 和集成工具。
-
局限:
- 数据精度:适用于可靠性监控,但不适合需要 100% 准确性的计费场景。
- 长期存储:原生 TSDB 适合短期数据,长期存储需依赖外部方案。
六、典型工作流程示例
- 数据采集:Prometheus Server 定期从 Node Exporter 拉取主机指标。
- 规则评估:根据
alert.rules判断 CPU 使用率是否超阈值。 - 告警触发:触发后 Alertmanager 发送邮件通知运维人员。
- 可视化展示:通过 Grafana 仪表盘实时查看监控趋势。
工作流程图:
在上一章内容,我们了解了Prometheus 的基础知识点,这一章开始,开始正式学习Prometheus 的安装搭建。
考虑到并不是所有环境都有安装helm,所以安装的版本就选择kube-prometheus。
Kube-Prometheus 是基于 Operator 的标准化监控堆栈,适合快速部署。
Kube-Prometheus版本的选择
从github上得知,目前kube-prometheus最新版为0.14,并且只支持到K8S1.31
| kube-prometheus stack | Kubernetes 1.23 | Kubernetes 1.24 | Kubernetes 1.25 | Kubernetes 1.26 | Kubernetes 1.27 | Kubernetes 1.28 | Kubernetes 1.29 | Kubernetes 1.30 | Kubernetes 1.31 |
|---|---|---|---|---|---|---|---|---|---|
| release-0.11 | ✔ | ✔ | ✗ | x | x | x | x | x | x |
| release-0.12 | ✗ | ✔ | ✔ | x | x | x | x | x | x |
| release-0.13 | ✗ | ✗ | x | ✔ | ✔ | ✔ | x | x | x |
| release-0.14 | ✗ | ✗ | x | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| main | ✗ | ✗ | x | x | ✔ | ✔ | ✔ | ✔ | ✔ |
Kube-Prometheus安装教程
1.下载软件
-
root@k8s-master:~# mkdir -vp prometheus
-
root@k8s-master:~# cd prometheus
-
root@k8s-master:~/prometheus# wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.14.0.zip
-
-
root@k8s-master:~/prometheus# unzip v0.14.0.zip
-
root@k8s-master:~/prometheus# cd kube-prometheus-0.14.0/
-
root@k8s-master:~/prometheus/kube-prometheus-0.14.0# tree
-
.
-
├── build.sh
-
├── CHANGELOG.md
-
├── code-of-conduct.md
-
├── CONTRIBUTING.md
-
-
.....
-
-
-
2.镜像替换
-
manifests/blackboxExporter-deployment.yaml: image: quay.io/prometheus/blackbox-exporter:v0.25.0
-
manifests/blackboxExporter-deployment.yaml: image: ghcr.io/jimmidyson/configmap-reload:v0.13.1
-
manifests/blackboxExporter-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/nodeExporter-daemonset.yaml: image: quay.io/prometheus/node-exporter:v1.8.2
-
manifests/nodeExporter-daemonset.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/alertmanager-alertmanager.yaml: image: quay.io/prometheus/alertmanager:v0.27.0
-
manifests/prometheusOperator-deployment.yaml: image: quay.io/prometheus-operator/prometheus-operator:v0.76.2
-
manifests/prometheusOperator-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/kubeStateMetrics-deployment.yaml: image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.13.0
-
manifests/kubeStateMetrics-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/kubeStateMetrics-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/prometheus-prometheus.yaml: image: quay.io/prometheus/prometheus:v2.54.1
-
manifests/grafana-deployment.yaml: image: grafana/grafana:11.2.0
-
manifests/prometheusAdapter-deployment.yaml: image: registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0
-
-
====修改为====
-
manifests/blackboxExporter-deployment.yaml: image: quay.m.daocloud.io/prometheus/blackbox-exporter:v0.25.0
-
manifests/blackboxExporter-deployment.yaml: image: ghcr.m.daocloud.io/jimmidyson/configmap-reload:v0.13.1
-
manifests/blackboxExporter-deployment.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/nodeExporter-daemonset.yaml: image: quay.m.daocloud.io/prometheus/node-exporter:v1.8.2
-
manifests/nodeExporter-daemonset.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/alertmanager-alertmanager.yaml: image: quay.m.daocloud.io/prometheus/alertmanager:v0.27.0
-
manifests/prometheusOperator-deployment.yaml: image: quay.m.daocloud.io/prometheus-operator/prometheus-operator:v0.76.2
-
manifests/prometheusOperator-deployment.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/kubeStateMetrics-deployment.yaml: image: k8s.m.daocloud.io/kube-state-metrics/kube-state-metrics:v2.13.0
-
manifests/kubeStateMetrics-deployment.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/kubeStateMetrics-deployment.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
-
manifests/prometheus-prometheus.yaml: image: quay.m.daocloud.io/prometheus/prometheus:v2.54.1
-
manifests/grafana-deployment.yaml: image: m.daocloud.io/docker.io/grafana/grafana:11.2.0
-
manifests/prometheusAdapter-deployment.yaml: image: k8s.m.daocloud.io/prometheus-adapter/prometheus-adapter:v0.12.0
3 Prometheus持久化准备
由于默认情况下prometheus的数据是存储在pod里面,当pod重启后,数据就丢失了,这不利于我们分析长期数据,所以需要将数据存储到之前搭建的longhorn中。
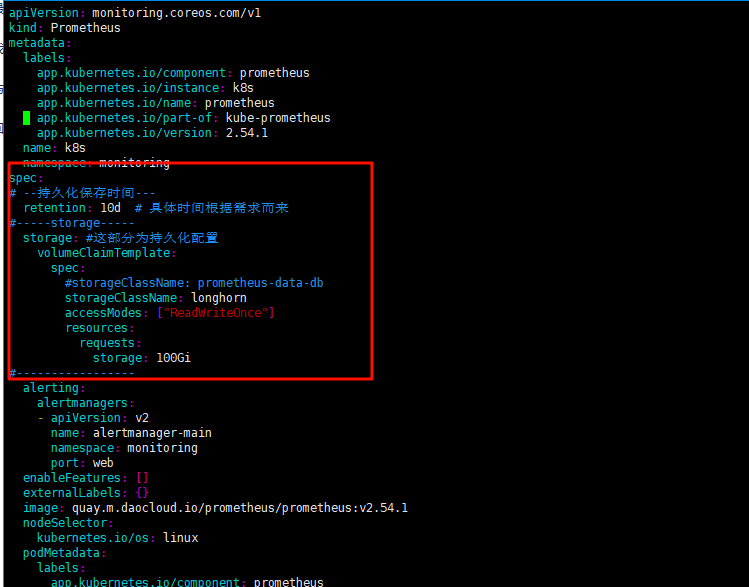
3.1 编辑manifests/prometheus-prometheus.yaml
新增如下内容:
-
vim manifests/prometheus-prometheus.yaml
-
# --持久化保存时间---
-
retention: 3d # 具体时间根据需求而来,默认1天
-
#-----storage-----
-
storage: #这部分为持久化配置
-
volumeClaimTemplate:
-
spec:
-
#storageClassName: prometheus-data-db
-
storageClassName: longhorn
-
accessModes: ["ReadWriteOnce"]
-
resources:
-
requests:
-
storage: 10Gi # 存储硬盘大小按照需求来,存储时间场,就调整大点
-
#-----------------
红色方框内为新增内容
3.2 grafana持久化准备
如果Grafana不做数据持久化、那么服务重启以后,Grafana里面配置的Dashboard、账号密码等信息将会丢失;所以Grafana做数据持久化也是很有必要的。原始的数据是以 emptyDir 形式存放在pod里面,生命周期与pod相同;出现问题时,容器重启,在Grafana里面设置的数据就全部消失了。
a.创建manifests/grafana-pvc.yaml
-
manifests/grafana-pvc.yaml
-
apiVersion: v1
-
kind: PersistentVolumeClaim
-
metadata:
-
name: grafana-pvc
-
namespace: monitoring
-
spec:
-
accessModes:
-
- ReadWriteOnce
-
resources:
-
requests:
-
storage: 20Gi
-
storageClassName: longhorn
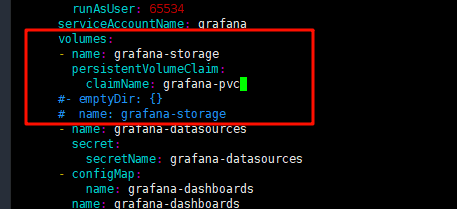
b.修改deployment.yaml文件
vim manifests/grafana-deployment.yaml
-
volumes:
-
- name: grafana-storage
-
persistentVolumeClaim:
-
claimName: grafana-pvc
-
#- emptyDir: {}
-
# name: grafana-storage
修改如下
3.3 暴露prometheus和grafana的端口
grafana 和 prometheus 默认都创建了一个类型为 ClusterIP 的 Service,我们需要暴露端口,以便外部访问,有多种方式选择:
- ingress方式
- NodePort .
此处我们通过NodePort方式实现
3.3.1 修改prometheus 的service文件
-
vim manifests/prometheus-service.yaml
-
-
type: NodePort
-
ports:
-
- name: web
-
port: 9090
-
targetPort: web
-
nodePort: 32090
-
- name: reloader-web
-
port: 8080
-
targetPort: reloader-web
-
nodePort: 32080
修改如下:
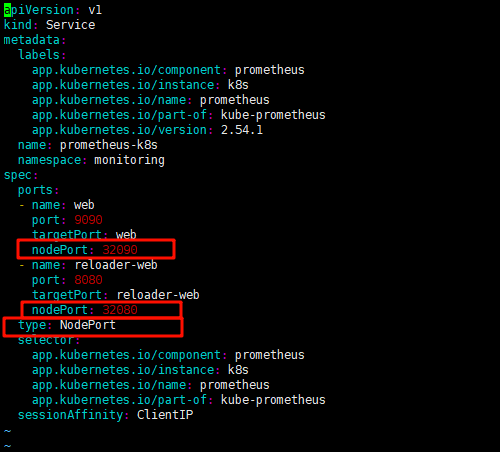
3.3.2 修改grafana的service文件
-
vim manifests/grafana-service.yaml
-
-
type: NodePort
-
ports:
-
- name: http
-
port: 3000
-
targetPort: http
-
nodePort: 32000
-
type: NodePort
修改如下:
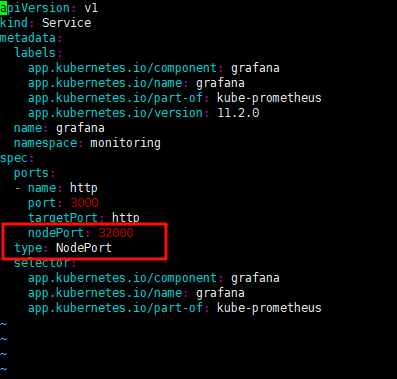
4. 安装部署
这里我们直接依次执行下面的命令即可完成安装:
-
# kubectl create -f manifests/setup
-
# kubectl create -f manifests
5. 检查
部署完成后,会创建一个名为monitoring的 namespace,所以资源对象对将部署在改命名空间下面,此外 Operator 会自动创建6个 CRD 资源对象
# kubectl get ns monitoring # kubectl get crd
我们可以在 monitoring 命名空间下面查看所有的 Pod和SVC资源,其中 alertmanager 和 prometheus 是用 StatefulSet 控制器管理的,其中还有一个比较核心的 prometheus-operator 的 Pod,用来控制其他资源对象和监听对象变化的。
-
kubectl get pod -n monitoring -o wide
-
kubectl get svc -n monitoring -o wide
查看pod:
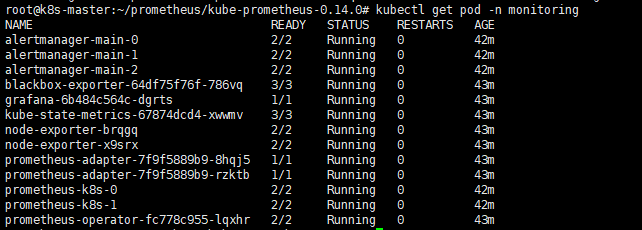
查看svc:
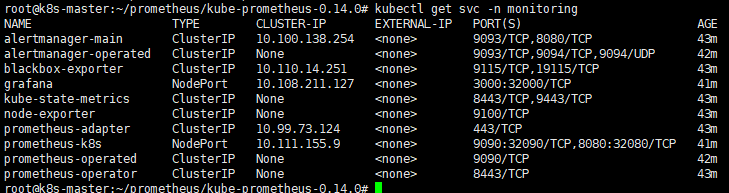
虽然pod和svc已经全部启动成功,但现在还无法访问grafan、prometheus以及alertmanger,因为prometheus operator内部默认配置了NetworkPolicy,需要删除其对应的资源,才可以通过外网访问:
-
kubectl delete -f manifests/prometheus-networkPolicy.yaml
-
kubectl delete -f manifests/grafana-networkPolicy.yaml
-
kubectl delete -f manifests/alertmanager-networkPolicy.yaml
页面检查
grafana界面:
默认密码 admin/admin,输入密码后会提示让用户重新设置一个管理员密码。重复输入2次即可。
但是需要注意的是,由于此时是通过nodeport的形式对外,所以任何人都可以访问这个地址,请设置相关的安全策略保证数据的安全,也包括其他的web页面。
Prometheus界面:
6.其他补充
默认grafana的时区不是北京时间,所以也需要调整后重新apply
修正grafana组件自带dashboard的默认时区
-
grep -i timezone manifests/grafana-dashboardDefinitions.yaml
-
sed -i 's/UTC/UTC+8/g' manifests/grafana-dashboardDefinitions.yaml
-
sed -i 's/utc/utc+8/g' manifests/grafana-dashboardDefinitions.yaml
-
kubectl apply -f manifests/grafana-dashboardDefinitions.yaml
2025,每天10分钟,跟我学K8S(四十五)- Prometheus(三)添加系统监控项_prometheus 监控 io-CSDN博客
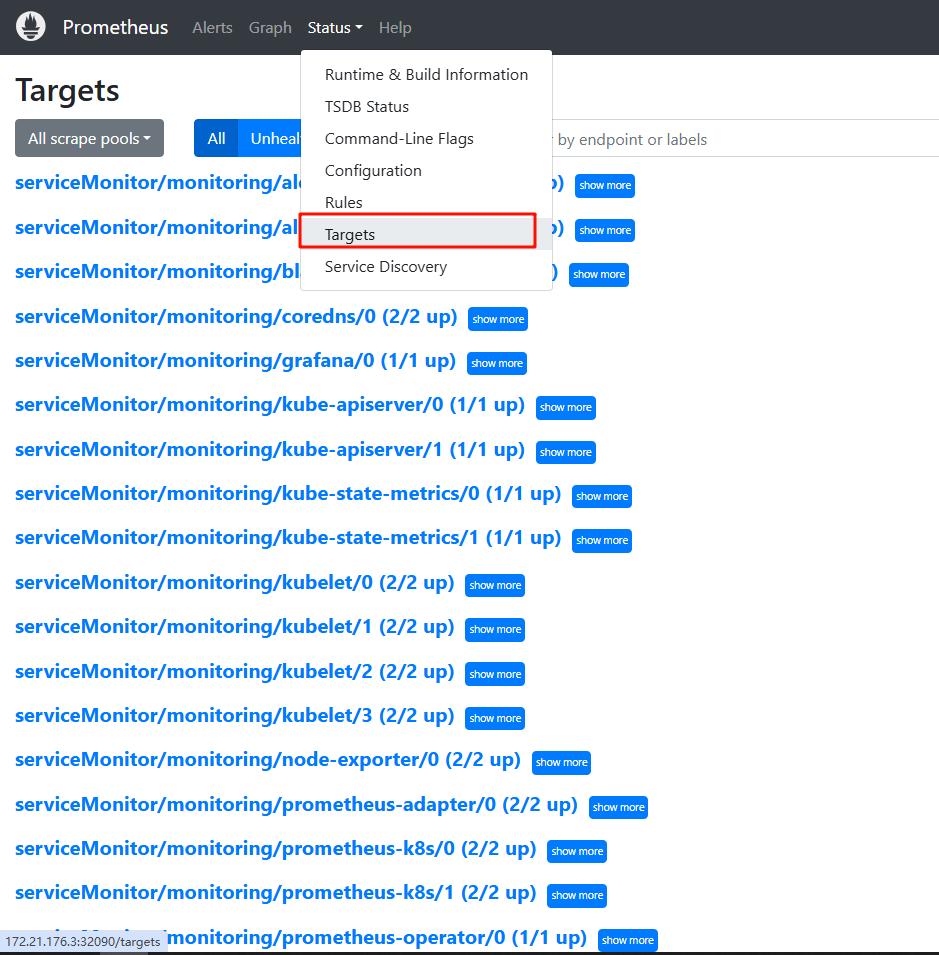
在上一章节,我们完成了Prometheus的安装,也可以在prometheus的targets管理页面看到了现在已经有一些系统应用指标被监控到了,例如 kube-apiserver,kubelet。但是任然有一些系统应用指标还缺失,例如 kube-scheduler、kube-controller-manager、kube-proxy 这三个系统组件就还没被监控。
如下图所示:
本节内容,我们来一起学习下 Prometheus中系统监控项的添加方式。
配置kube-scheduler监控
1.首先修改 /etc/kubernetes/manifests/kube-scheduler.yaml 文件中的bind IP
-
spec:
-
containers:
-
- command:
-
- kube-scheduler
-
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
-
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
-
- --bind-address=127.0.0.1
-
====修改为====
-
spec:
-
containers:
-
- command:
-
- kube-scheduler
-
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
-
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
-
- --bind-address=0.0.0.0 #修改这里
2.再来查看一下manifests/kubernetesControlPlane-serviceMonitorKubeScheduler.yaml这个文件,这里给它添加上了注释。
-
apiVersion: monitoring.coreos.com/v1 # 定义 CRD 资源类型为 ServiceMonitor
-
kind: ServiceMonitor
-
metadata:
-
labels:
-
app.kubernetes.io/name: kube-scheduler # 标识监控目标为 kube-scheduler
-
app.kubernetes.io/part-of: kube-prometheus # 标记属于 kube-prometheus 生态
-
name: kube-scheduler # ServiceMonitor 资源名称
-
namespace: monitoring # 部署在 monitoring 命名空间
-
spec:
-
endpoints:
-
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token # 使用 ServiceAccount Token 认证
-
interval: 30s # 抓取间隔 30 秒
-
port: https-metrics # 关联 Service 的端口名称
-
scheme: https # 使用 HTTPS 协议(需配合 TLS 配置)
-
tlsConfig:
-
insecureSkipVerify: true # 跳过 HTTPS 证书验证(生产环境建议配置合法证书)[1](@ref)
-
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
-
interval: 5s # 更高频率的抓取间隔(适用于实时性指标)
-
metricRelabelings:
-
- action: drop # 指标重标记:过滤特定指标
-
regex: process_start_time_seconds # 正则匹配需要丢弃的指标名称
-
sourceLabels:
-
- __name__ # 作用于指标名称字段
-
path: /metrics/slis # 自定义指标路径(服务级别指标)
-
port: https-metrics
-
scheme: https
-
tlsConfig:
-
insecureSkipVerify: true
-
jobLabel: app.kubernetes.io/name # 使用标签值作为 Prometheus Job 名称
-
namespaceSelector:
-
matchNames:
-
- kube-system # 仅在 kube-system 命名空间发现目标服务
-
selector:
-
matchLabels:
-
app.kubernetes.io/name: kube-scheduler # 匹配 Service 的标签选择器
3.发现最后的matchLabels,表名需要选择标签为 app.kubernetes.io/name: kube-scheduler 的 Service,但是通过kubectl get svc -n kube-system 发现并没有这个svc。
-
root@k8s-master:~/prometheus/kube-prometheus-0.14.0/manifests# kubectl get svc -n kube-system
-
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
-
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 21d
-
kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 24h
-
metrics-server ClusterIP 10.105.177.80 <none> 443/TCP 2d
那我们就创建一个svc,并且绑定对应的标签
-
# kube-scheduler-service.yaml
-
apiVersion: v1
-
kind: Service
-
metadata:
-
name: kube-scheduler
-
namespace: kube-system
-
labels:
-
k8s-app: kube-scheduler
-
app.kubernetes.io/name: kube-scheduler
-
spec:
-
clusterIP: None # Headless Service
-
ports:
-
- name: https-metrics
-
port: 10259
-
targetPort: 10259
-
protocol: TCP
-
selector:
-
component: kube-scheduler # 必须与 Pod 的标签匹配
-
-
-
-
-
# 应用这个yaml文件
-
root@k8s-master:~/prometheus/kube-prometheus-0.14.0/manifests# kubectl apply -f kube-scheduler-service.yaml
-
service/kube-scheduler created
-
-
-
# 再次查看svc
-
root@k8s-master:~/prometheus/kube-prometheus-0.14.0/manifests# kubectl get svc -n kube-system
-
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
-
kube-scheduler ClusterIP None <none> 10259/TCP 67s
-
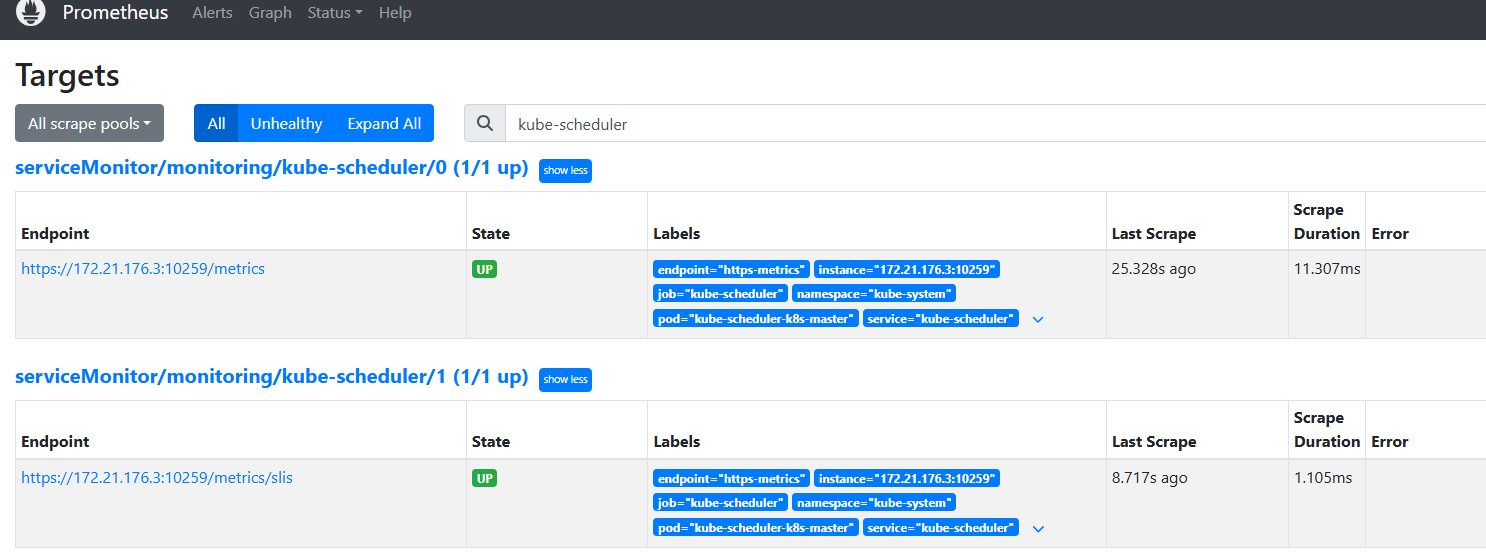
4.过一会回到页面,即可发现现在已经有了这个监控项
配置kube-controller-manager监控
1.首先修改 /etc/kubernetes/manifests/kube-controller-manager.yaml 的bind IP
-
spec:
-
containers:
-
- command:
-
- kube-controller-manager
-
- --allocate-node-cidrs=true
-
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
-
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
-
- --bind-address=127.0.0.1
-
====修改为====
-
spec:
-
containers:
-
- command:
-
- kube-controller-manager
-
- --allocate-node-cidrs=true
-
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
-
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
-
- --bind-address=0.0.0.0
2.查看kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml 文件最后的标签,这里只看最后的matchLabels 是app.kubernetes.io/name: kube-controller-manager
-
# vim manifests/kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml
-
-
apiVersion: monitoring.coreos.com/v1
-
kind: ServiceMonitor
-
metadata:
-
labels:
-
app.kubernetes.io/name: kube-controller-manager
-
app.kubernetes.io/part-of: kube-prometheus
-
name: kube-controller-manager
-
namespace: monitoring
-
spec:
-
-
....
-
selector:
-
matchLabels:
-
app.kubernetes.io/name: kube-controller-manager
3. 发现最后的matchLabels,表名需要选择标签为 app.kubernetes.io/name: kube-controller-manager 的 Service,但是通过kubectl get svc -n kube-system 发现并没有这个svc。这里直接创建一个对应的svc yaml文件,需要对应标签为 app.kubernetes.io/name: kube-controller-manager,并且指定了endpoint
-
# kube-controller-manager-service.yaml
-
-
apiVersion: v1
-
kind: Service
-
metadata:
-
name: kube-controller-manager
-
namespace: kube-system
-
labels:
-
app.kubernetes.io/name: kube-controller-manager # 必须与 ServiceMonitor 的标签匹配
-
spec:
-
clusterIP: None
-
ports:
-
- name: https-metrics
-
port: 10257
-
targetPort: 10257
-
protocol: TCP
-
selector:
-
component: kube-controller-manager
-
---
-
apiVersion: v1
-
kind: Endpoints
-
metadata:
-
name: kube-controller-manager
-
namespace: kube-system
-
subsets:
-
- addresses:
-
- ip: 172.21.176.3 # 替换为 Controller Manager 实际 IP
-
ports:
-
- name: https-metrics
-
port: 10257
-
4.过一会回到页面,即可发现现在已经有了这个监控项
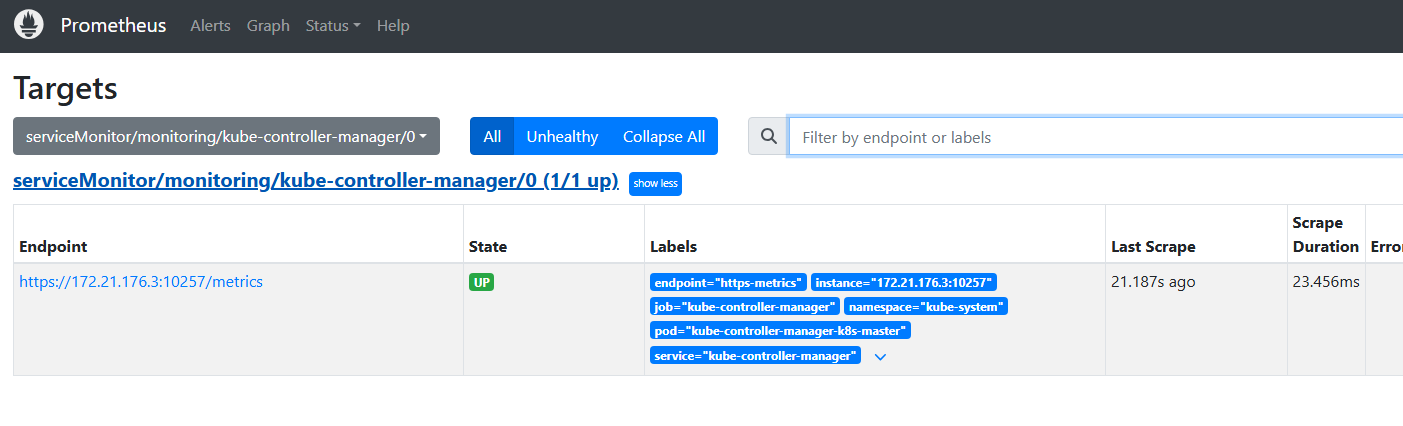
配置kube-proxy
其实在有了上面2个例子,我们就已经弄明白了,系统服务的监控总共分3个步骤
- 修改配置文件监听的端口
- 查看或创建ServiceMonitor 文件,用于 Prometheus 添加监控项
- 查看或创建Service和endpoint文件,对象可以正确获取到 metrics 数据
有了这个共识,继续来监控kube-proxy。
1.修改配置文件监听端口
kube-proxy是以pod的形式运行的,并没有单独的配置文件
使用命令 kubectl -n kube-system get configmap kube-proxy -o yaml | grep metricsBindAddress获取端口,确保输出为 metricsBindAddress: "0.0.0.0:10249",若127.0.0.1 或 空 需修改 ConfigMap
-
kubectl -n kube-system get configmap kube-proxy -o yaml | grep metricsBindAddress
-
-
# 使用edit 来修改
-
kubectl -n kube-system edit configmap kube-proxy
-
-
metricsBindAddress: ""
-
====修改为====
-
metricsBindAddress: "0.0.0.0:10249"
-
-
-
#重启kube-proxy
-
kubectl -n kube-system rollout restart daemonset/kube-proxy
2. 创建ServiceMonitor 文件
说明:无需 TLS 配置,因 kube-proxy 默认使用 HTTP 协议
-
# vim manifests/kubernetesControlPlane-serviceMonitorKube-Proxy.yaml
-
-
apiVersion: monitoring.coreos.com/v1
-
kind: ServiceMonitor
-
metadata:
-
name: kube-proxy
-
namespace: monitoring
-
spec:
-
endpoints:
-
- interval: 30s
-
port: http-metrics # 与 Service 端口名称一致
-
scheme: http # 协议为 HTTP
-
selector:
-
matchLabels:
-
k8s-app: kube-proxy
-
namespaceSelector:
-
matchNames: [kube-system]
3.创建Service文件
-
# vim manifests/kube-proxy-service.yaml
-
-
apiVersion: monitoring.coreos.com/v1
-
kind: ServiceMonitor
-
metadata:
-
name: kube-proxy
-
namespace: monitoring
-
spec:
-
endpoints:
-
- interval: 30s
-
port: http-metrics # 与 Service 端口名称一致
-
scheme: http # 协议为 HTTP
-
selector:
-
matchLabels:
-
k8s-app: kube-proxy
-
namespaceSelector:
-
matchNames: [kube-system]
-
---
-
apiVersion: v1
-
kind: Endpoints
-
metadata:
-
name: kube-proxy
-
namespace: kube-system
-
subsets:
-
- addresses:
-
- ip: 172.21.176.3 # 替换为实际节点 IP
-
ports:
-
- name: http-metrics
-
port: 10249
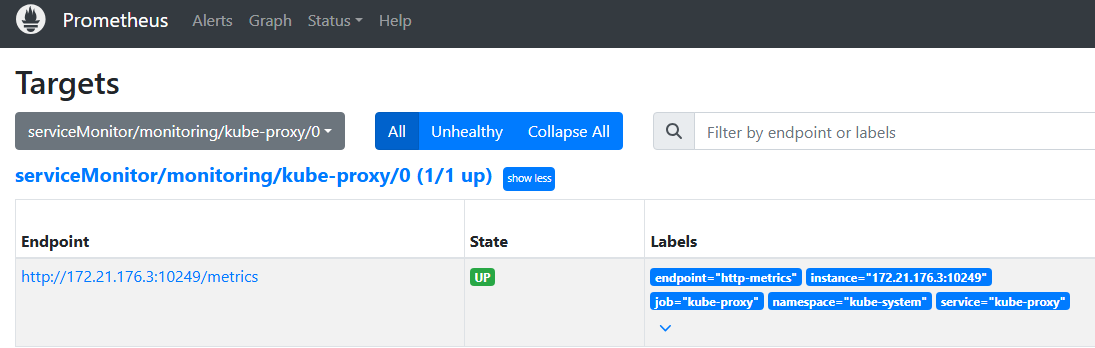
4.应用并查看
-
root@k8s-master:~/prometheus/kube-prometheus-0.14.0# kubectl apply -f manifests/kubernetesControlPlane-serviceMonitorKube-Proxy.yaml
-
servicemonitor.monitoring.coreos.com/kube-proxy created
-
root@k8s-master:~/prometheus/kube-prometheus-0.14.0# kubectl apply -f manifests/kube-proxy-service.yaml
-
service/kube-proxy created
-
2025,每天10分钟,跟我学K8S(四十六)- Prometheus(三)添加自定义监控项_prometheus自定义监控项-CSDN博客
上一章,我们学习了Prometheus添加系统监控项,那如何添加自定义监控项呢?例如etcd或者其他自己运行的pod?
这一章节就来讲解这个问题。
Prometheus监控ETCD
1.编辑监听端口
这里由于是kubeadm创建的,所以默认监听了本地内网IP,这里不做修改
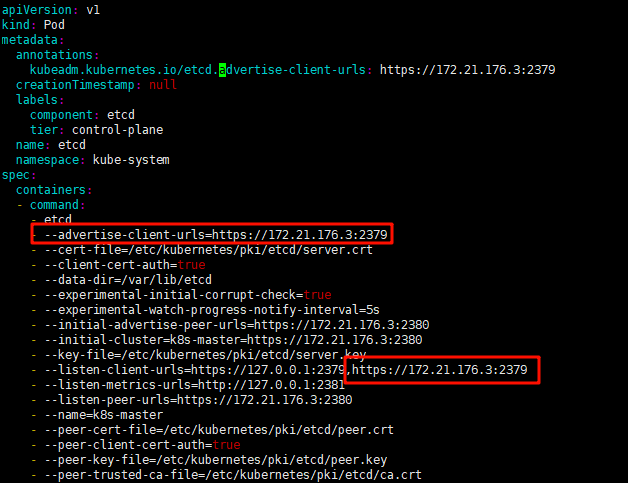
2.创建Service 和 Endpoints
-
# vim manifests/etcd-Service.yaml
-
-
# Service 定义
-
apiVersion: v1
-
kind: Service
-
metadata:
-
name: etcd
-
namespace: kube-system
-
labels:
-
k8s-app: etcd
-
spec:
-
clusterIP: None # Headless Service
-
ports:
-
- name: https-metrics
-
port: 2379
-
protocol: TCP # 协议类型需与 Endpoints 一致
-
-
---
-
# Endpoints 定义
-
apiVersion: v1
-
kind: Endpoints
-
metadata:
-
name: etcd
-
namespace: kube-system
-
subsets: # 直接定义 subsets,无需嵌套在 spec 下
-
- addresses:
-
- ip: 172.21.176.3 # 替换为实际 ETCD 节点 IP 有几台就写几个
-
ports:
-
- name: https-metrics # 端口名称需与 Service 一致
-
port: 2379
-
protocol: TCP # 必须明确协议类型
3.创建ServiceMonitor
etcd默认是有证书的,所以需要提前将etcd的证书创建成secret,并且挂载到prometheus的pod中去。
3.1 证书挂载
创建包含 ETCD 证书的 Secret,供 Prometheus 使用
-
kubectl -n monitoring create secret generic etcd-certs \
-
--from-file=/etc/kubernetes/pki/etcd/ca.crt \
-
--from-file=/etc/kubernetes/pki/etcd/server.crt \
-
--from-file=/etc/kubernetes/pki/etcd/server.key
更新 Prometheus 新增配置以挂载证书:
-
# 修改 manifests/prometheus-prometheus.yaml
-
spec:
-
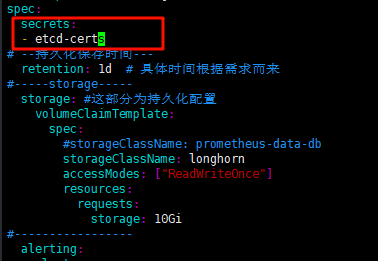
secrets:
-
- etcd-certs
-
-
-
# 应用
-
root@k8s-master:~/prometheus/kube-prometheus-0.14.0# kubectl apply -f /opt/prometheus/kube-prometheus/manifests/prometheus-prometheus.yaml
-
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
-
prometheus.monitoring.coreos.com/k8s configured
-
-
更新完毕后,我们就可以在Prometheus Pod中查看到对象的目录,这一步需要的时间比较长,需要等待一会才会复制进去
-
root@k8s-master:~/prometheus/kube-prometheus-0.14.0# kubectl exec -it -n monitoring prometheus-k8s-0 -- /bin/sh
-
/prometheus $
-
/prometheus $ ls /etc/prometheus/secrets/etcd-certs/
-
ca.crt server.crt server.key
3.2 ServiceMonitor 配置
定义 HTTPS 抓取规则,引用证书路径
-
# vim manifests/etcd-ServiceMonitor.yaml
-
-
apiVersion: monitoring.coreos.com/v1
-
kind: ServiceMonitor
-
metadata:
-
name: etcd
-
namespace: monitoring
-
spec:
-
endpoints:
-
- interval: 30s
-
port: https-metrics
-
scheme: https
-
tlsConfig:
-
caFile: /etc/prometheus/secrets/etcd-certs/ca.crt
-
certFile: /etc/prometheus/secrets/etcd-certs/server.crt
-
keyFile: /etc/prometheus/secrets/etcd-certs/server.key
-
selector:
-
matchLabels:
-
k8s-app: etcd
-
namespaceSelector:
-
matchNames: [kube-system]
4.应用yaml文件
-
kubectl apply -f manifests/etcd-Service.yaml
-
service/etcd created
-
-
-
kubectl apply -f manifests/etcd-ServiceMonitor.yaml
-
servicemonitor.monitoring.coreos.com/etcd created
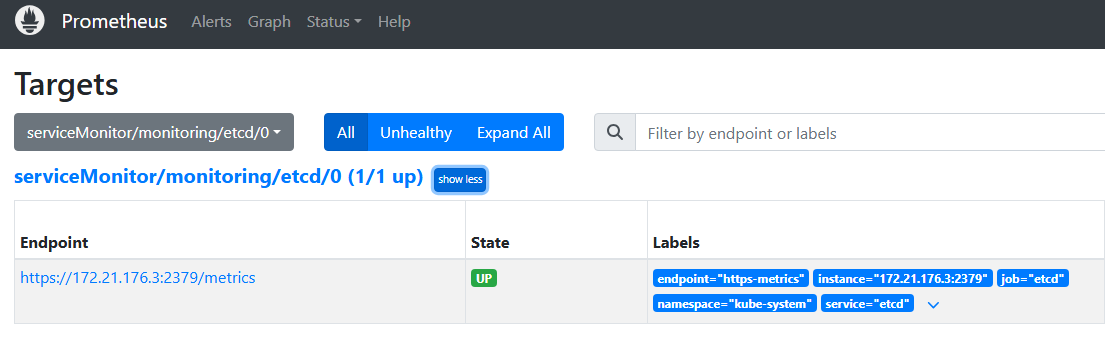
5.配置报警规则
上面etcd的监控项已经出现了,但是只监控,不设置预警显然是不合理的。
创建 manifests/etcd-serviceMonitorRule.yaml 预警规则
这里参考:https://github.com/samber/awesome-prometheus-alerts, 这里有各种应用的监控报警规则。
-
# vim manifests/etcd-serviceMonitorRule.yaml
-
-
apiVersion: monitoring.coreos.com/v1
-
kind: PrometheusRule
-
metadata:
-
labels:
-
prometheus: k8s
-
role: alert-rules
-
name: prometheus-k8s-etcd-rules
-
namespace: monitoring
-
spec:
-
groups:
-
- name: etcd
-
rules:
-
- alert: EtcdInsufficientMembers
-
expr: count(etcd_server_id) % 2 == 0
-
for: 5m
-
labels:
-
severity: critical
-
annotations:
-
summary: "Etcd insufficient Members (instance {{ $labels.instance }})"
-
description: "Etcd cluster should have an odd number of members\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdNoLeader
-
expr: etcd_server_has_leader == 0
-
for: 5m
-
labels:
-
severity: critical
-
annotations:
-
summary: "Etcd no Leader (instance {{ $labels.instance }})"
-
description: "Etcd cluster have no leader\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdHighNumberOfLeaderChanges
-
expr: increase(etcd_server_leader_changes_seen_total[1h]) > 3
-
for: 5m
-
labels:
-
severity: warning
-
annotations:
-
summary: "Etcd high number of leader changes (instance {{ $labels.instance }})"
-
description: "Etcd leader changed more than 3 times during last hour\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdHighNumberOfFailedGrpcRequests
-
expr: sum(rate(grpc_server_handled_total{grpc_code!="OK",grpc_method !="Watch"}[5m])) BY (grpc_service, grpc_method) / sum(rate(grpc_server_handled_total[5m])) BY (grpc_service, grpc_method) > 0.01
-
for: 5m
-
labels:
-
severity: warning
-
annotations:
-
summary: "Etcd high number of failed GRPC requests (instance {{ $labels.instance }})"
-
description: "More than 1% GRPC request failure detected in Etcd for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdHighNumberOfFailedGrpcRequests
-
expr: sum(rate(grpc_server_handled_total{grpc_code!="OK",grpc_method !="Watch"}[5m])) BY (grpc_service, grpc_method) / sum(rate(grpc_server_handled_total[5m])) BY (grpc_service, grpc_method) > 0.05
-
for: 5m
-
labels:
-
severity: critical
-
annotations:
-
summary: "Etcd high number of failed GRPC requests (instance {{ $labels.instance }})"
-
description: "More than 5% GRPC request failure detected in Etcd for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdGrpcRequestsSlow
-
expr: histogram_quantile(0.99, sum(rate(grpc_server_handling_seconds_bucket{grpc_type="unary"}[5m])) by (grpc_service, grpc_method, le)) > 0.15
-
for: 5m
-
labels:
-
severity: warning
-
annotations:
-
summary: "Etcd GRPC requests slow (instance {{ $labels.instance }})"
-
description: "GRPC requests slowing down, 99th percentil is over 0.15s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
-
- alert: EtcdHighNumberOfFailedHttpRequests
-
expr: sum(rate(etcd_http_failed_total[5m])) BY (method) / sum(rate(etcd_http_received_total[5m])) BY (method) > 0.01
-
for: 5m
-
labels:
-
severity: warning
-
annotations:
-
summary: "Etcd high number of failed HTTP requests (instance {{ $labels.instance }})"
-
description: "More than 1% HTTP failure detected in Etcd for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdHighNumberOfFailedHttpRequests
-
expr: sum(rate(etcd_http_failed_total[5m])) BY (method) / sum(rate(etcd_http_received_total[5m])) BY (method) > 0.05
-
for: 5m
-
labels:
-
severity: critical
-
annotations:
-
summary: "Etcd high number of failed HTTP requests (instance {{ $labels.instance }})"
-
description: "More than 5% HTTP failure detected in Etcd for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdHttpRequestsSlow
-
expr: histogram_quantile(0.99, rate(etcd_http_successful_duration_seconds_bucket[5m])) > 0.15
-
for: 5m
-
labels:
-
severity: warning
-
annotations:
-
summary: "Etcd HTTP requests slow (instance {{ $labels.instance }})"
-
description: "HTTP requests slowing down, 99th percentil is over 0.15s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdMemberCommunicationSlow
-
expr: histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.15
-
for: 5m
-
labels:
-
severity: warning
-
annotations:
-
summary: "Etcd member communication slow (instance {{ $labels.instance }})"
-
description: "Etcd member communication slowing down, 99th percentil is over 0.15s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdHighNumberOfFailedProposals
-
expr: increase(etcd_server_proposals_failed_total[1h]) > 5
-
for: 5m
-
labels:
-
severity: warning
-
annotations:
-
summary: "Etcd high number of failed proposals (instance {{ $labels.instance }})"
-
description: "Etcd server got more than 5 failed proposals past hour\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdHighFsyncDurations
-
expr: histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m])) > 0.5
-
for: 5m
-
labels:
-
severity: warning
-
annotations:
-
summary: "Etcd high fsync durations (instance {{ $labels.instance }})"
-
description: "Etcd WAL fsync duration increasing, 99th percentil is over 0.5s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
- alert: EtcdHighCommitDurations
-
expr: histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket[5m])) > 0.25
-
for: 5m
-
labels:
-
severity: warning
-
annotations:
-
summary: "Etcd high commit durations (instance {{ $labels.instance }})"
-
description: "Etcd commit duration increasing, 99th percentil is over 0.25s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
-
-
#apply 应用
-
kubectl apply -f manifests/etcd-serviceMonitorRule.yaml
-
prometheusrule.monitoring.coreos.com/prometheus-k8s-etcd-rules created
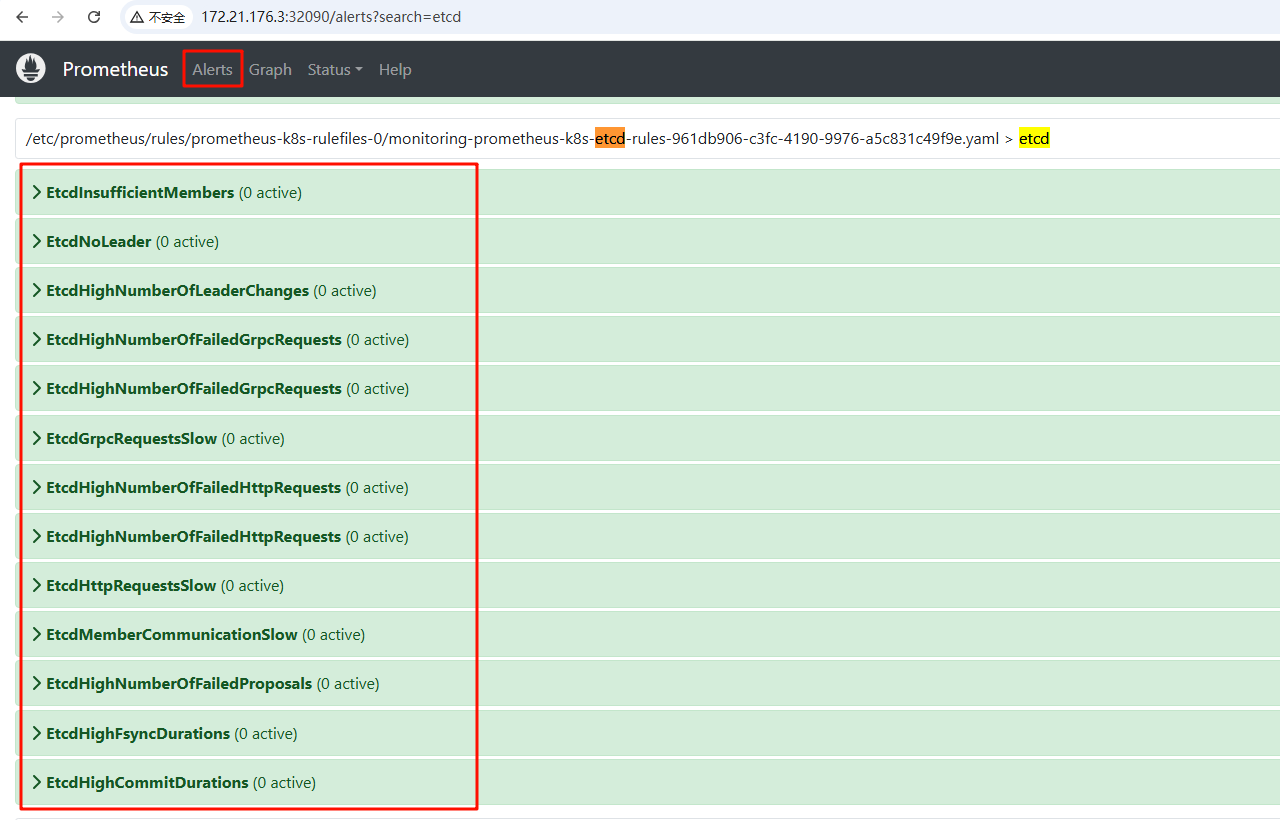
web页面点击alerts 查看刚才配置的报警规则是否生效
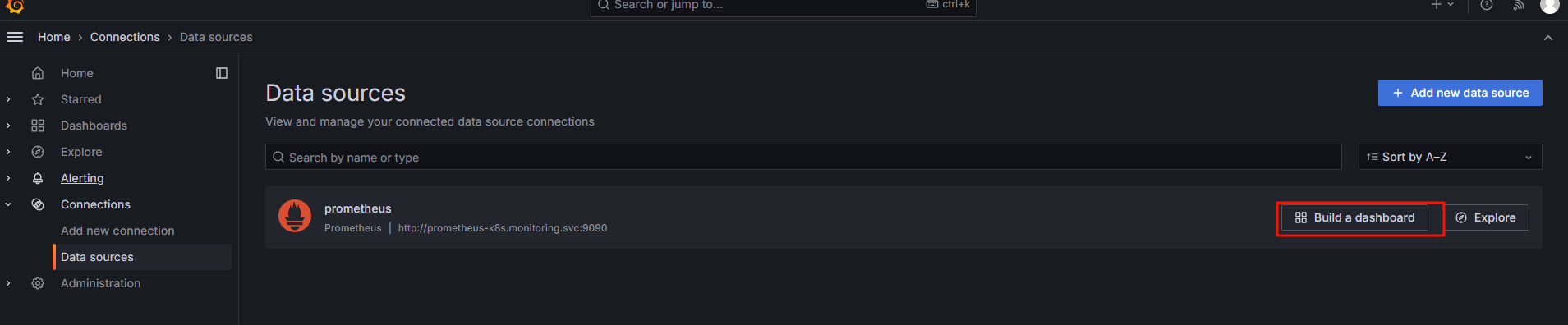
6.通过grafana查看图表
Grafana 是一款开源的数据可视化与监控平台,支持 30+ 数据源(如 Prometheus、InfluxDB、MySQL、Elasticsearch 等),可动态展示实时数据并生成交互式仪表盘。最重要的是,导入数据源后,网上有很多大神做好的模板可以开箱即用。下面的etcd就直接采用网上的模板直接拿来用。
6.1选择 构建一个新的表盘
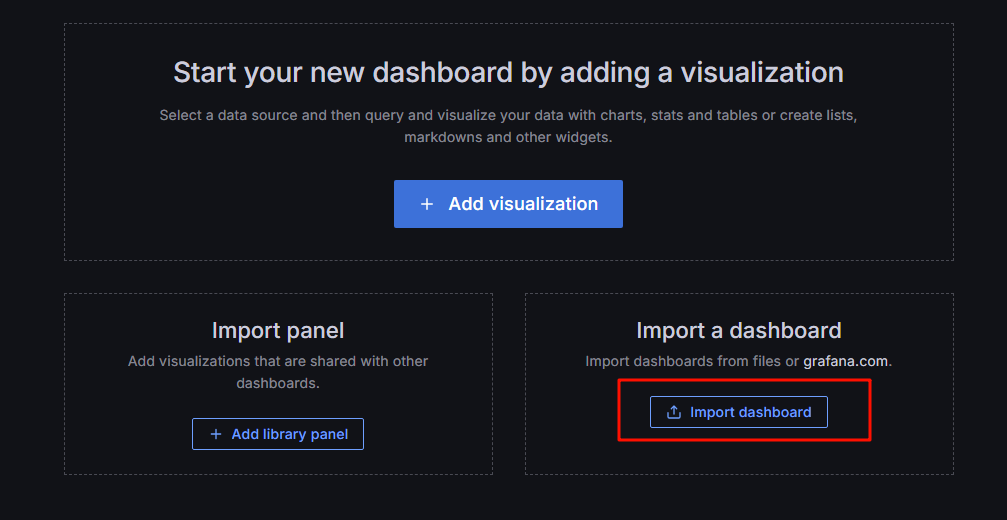
6.2导入表盘
6.3 个人监控etcd喜欢用3070这个别人做好的表盘,点击右侧导入
6.4取名后导入
6.5查看数据
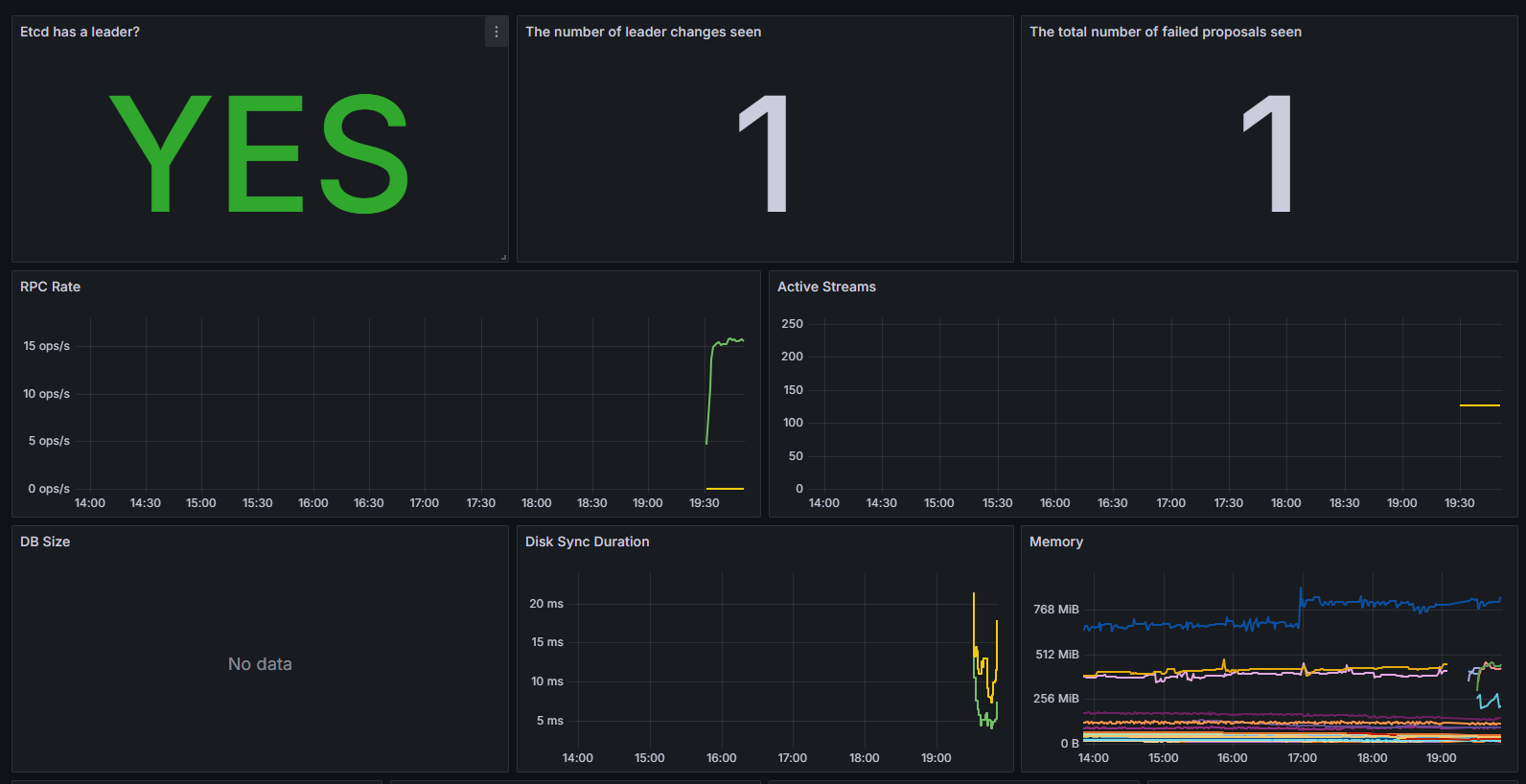
至此,一个完整的ETCD的监控预警就完成了。我们来梳理一下流程
1.创建对应的 service和endpoint
2.创建对应的 ServiceMonitor 对象来进行监控
3.创建对应的rule规则来进行设置阈值,这个可以去上面给的github地址里面搜索,常见的基本都有
4.设置grafana的图表,这个可以参考网上的模板
看起来真麻烦,如果我有几百个pod,不是要创建几百个ServiceMonitor 对象来进行监控?有没有简单的方法?甚至能不能让他做到通过一些规则自动来监控?下一章节我们一起来学习prometheus的自动发现规则。
前面我们学习了K8S中Prometheus 的各种监控配置,但是有了这些告警,怎么让监控人员及时发现并处理,总不能让监控人员一直盯着prometheus的页面吧,如何将告警内容发布出来,这就是接下来要学习的。
前面的课程中我们知道我们可以通过 AlertManager 的配置文件去配置各种报警接收器,那应该怎样去修改配置呢?
查看 AlertManager Dashboard 的 status页面下的config,发现这里的值和kube-prometheus/manifests/alertmanager-secret.yaml 下面的内容一样,我们这边采用钉钉报警,钉钉在2020年7月进行升级了。需要配置sign才可以发送消息
一、部署核心组件
1. 创建钉钉机器人
自动2020年钉钉机器人改版后,现在的机器人只选择「加签」或「自定义关键词」安全验证方式。
1.1、在钉钉群中创建自定义机器人,选择「加签」或「自定义关键词」安全验证方式。
选择加签模式,并且记录好这里的加签内容
SEC8b2e7abdb0f5243d04f527d2a3a66d7e53e1a66462936ef84c1aeb3978e96df5
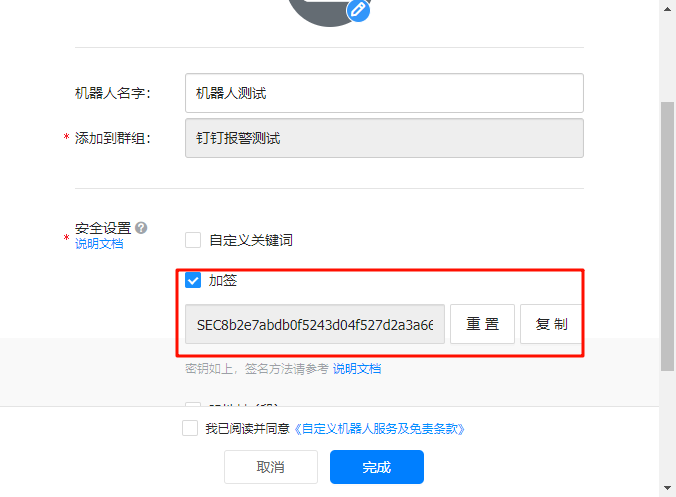
1.2、记录生成的 Webhook URL(如 https://oapi.dingtalk.com/robot/send?access_token=xxx)和加签密钥(如有)。
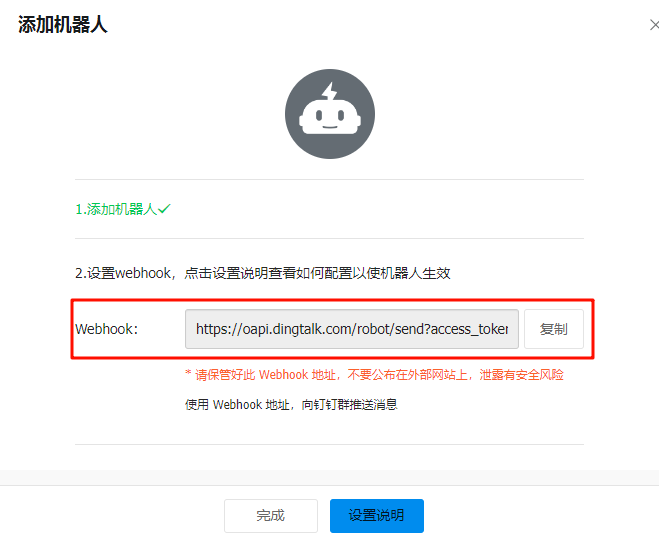
2. 部署钉钉 Webhook 插件
使用 Kubernetes YAML 部署 prometheus-webhook-dingtalk(推荐官方镜像 timonwong/prometheus-webhook-dingtalk:v2.1.0):
-
# cat dingtalk-webhook-deploy.yaml
-
-
apiVersion: v1
-
kind: Service
-
metadata:
-
name: dingtalk
-
namespace: monitoring
-
labels:
-
app: dingtalk
-
spec:
-
selector:
-
app: dingtalk
-
ports:
-
- name: dingtalk
-
port: 8060
-
protocol: TCP
-
targetPort: 8060
-
-
---
-
apiVersion: apps/v1
-
kind: Deployment
-
metadata:
-
name: dingtalk
-
namespace: monitoring
-
spec:
-
replicas: 2
-
selector:
-
matchLabels:
-
app: dingtalk
-
template:
-
metadata:
-
name: dingtalk
-
labels:
-
app: dingtalk
-
spec:
-
containers:
-
- name: dingtalk
-
image: docker.1ms.run/timonwong/prometheus-webhook-dingtalk:v2.1.0
-
imagePullPolicy: IfNotPresent
-
args:
-
- --web.listen-address=:8060
-
- --config.file=/etc/prometheus-webhook-dingtalk/config.yml
-
ports:
-
- containerPort: 8060
-
volumeMounts:
-
- name: config
-
mountPath: /etc/prometheus-webhook-dingtalk
-
volumes:
-
- name: config
-
configMap:
-
name: prometheus-webhook-dingtalk-config
3. 配置钉钉插件
创建 dingtalk-configmap.yaml 和 自定义告警模板
记得替换这里的access_token和secret
-
# cat dingtalk-configmap.yaml
-
apiVersion: v1
-
kind: ConfigMap
-
metadata:
-
name: prometheus-webhook-dingtalk-config
-
namespace: monitoring
-
data:
-
config.yml: |-
-
templates:
-
- /etc/prometheus-webhook-dingtalk/default.tmpl
-
targets:
-
webhook1:
-
url: https://oapi.dingtalk.com/robot/send?access_token=3037cf6879c4749684e2a99b916a749fcfeb6fde835151bd84758636f5fbb04b #修改为钉钉机器人的webhook
-
secret: SEC8b2e7abdb0f5243d04f527d2a3a66d7e53e1a66462936ef84c1aeb3978e96df5 #修改钉钉机器人的加签
-
mention:
-
all: true
-
message:
-
text: '{{ template "default.tmpl" . }}'
-
-
default.tmpl: |
-
{{ define "default.tmpl" }}
-
-
{{- if gt (len .Alerts.Firing) 0 -}}
-
{{- range $index, $alert := .Alerts -}}
-
-
============ = **<font color='#FF0000'>告警</font>** = ============= #红色字体
-
-
**告警名称:** {{ $alert.Labels.alertname }}
-
**告警级别:** {{ $alert.Labels.severity }} 级
-
**告警状态:** {{ .Status }}
-
**告警实例:** {{ $alert.Labels.instance }} {{ $alert.Labels.device }}
-
**告警概要:** {{ .Annotations.summary }}
-
**告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}
-
**故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
-
============ = end = =============
-
{{- end }}
-
{{- end }}
-
-
{{- if gt (len .Alerts.Resolved) 0 -}}
-
{{- range $index, $alert := .Alerts -}}
-
-
============ = <font color='#00FF00'>恢复</font> = ============= #绿色字体
-
-
**告警实例:** {{ .Labels.instance }}
-
**告警名称:** {{ .Labels.alertname }}
-
**告警级别:** {{ $alert.Labels.severity }} 级
-
**告警状态:** {{ .Status }}
-
**告警概要:** {{ $alert.Annotations.summary }}
-
**告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}
-
**故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
-
**恢复时间:** {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
-
-
============ = **end** = =============
-
{{- end }}
-
{{- end }}
-
{{- end }}
二、配置 Alertmanager
1. 修改 Alertmanager 配置
-
# cat alertmanager.yaml
-
-
global:
-
resolve_timeout: 15s
-
inhibit_rules: ##静默规则:当同一个job内,出现多个告警时,只将高级别告警发送出来
-
- source_match: ##发送的告警标签
-
severity: 'critical'
-
target_match: ##被抑制的告警标签
-
severity: 'warning'
-
equal: ['alertname','namespace'] ##匹配的标签,即当同一个job出现多个告警的时候,会优先发出级别为critical的告警
-
-
route: ##顶级路由,可以通过制定不同的路由,将不同的告警信息发送给不同的人,这里顶级路由需要匹配所有的告警
-
group_by: ['alertname','namespace'] ##分组,需要匹配所有的告警,所以这里可以用监控namespace分组
-
group_wait: 30s ## 分组等待的时间
-
group_interval: 5m ## 上下两组发送告警的间隔时间
-
repeat_interval: 1h ## 重复发送告警时间。默认1h
-
receiver: webhook ## 默认的发送人 这里选择webhook,即钉钉
-
routes: ## 子路由
-
- match:
-
alertname: warning ## 将warning的告警发送给webhook工作组
-
receiver: webhook
-
receivers: #定义谁来通知报警
-
- name: 'webhook' ##钉钉样式
-
webhook_configs:
-
#- url: 'http://webhook-dingtalk:8060/dingtalk/webhook1/send'
-
- url: 'http://dingtalk.monitoring.svc.cluster.local:8060/dingtalk/webhook1/send'
-
send_resolved: true
2. 应用配置
- 更新 Alertmanager 配置后重启服务:
-
# 删除旧secret
-
kubectl delete secret alertmanager-main -n monitoring
-
-
# 创建新secret
-
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring
三、配置 Prometheus 告警规则
1. 定义告警规则
在manifests/alertmanager-prometheusRule.yaml 中新增一下自定义规则
规则内容为当pod重启3次后报警
-
# vim alertmanager-prometheusRule.yaml
-
-
- name: pod-alerts
-
rules:
-
- alert: PodCrashLooping
-
expr: kube_pod_container_status_restarts_total > 3
-
for: 5m
-
labels:
-
severity: critical
-
annotations:
-
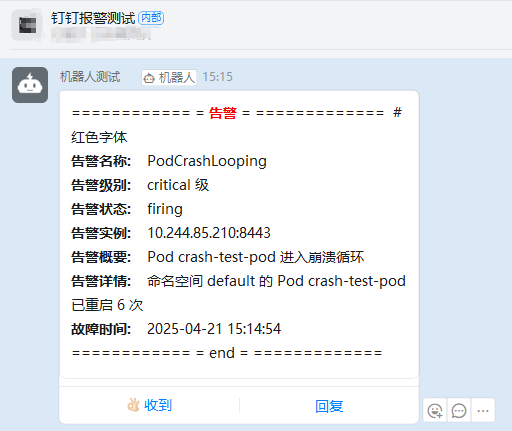
summary: "Pod {{ $labels.pod }} 进入崩溃循环"
-
description: "命名空间 {{ $labels.namespace }} 的 Pod {{ $labels.pod }} 已重启 {{ $value }} 次"
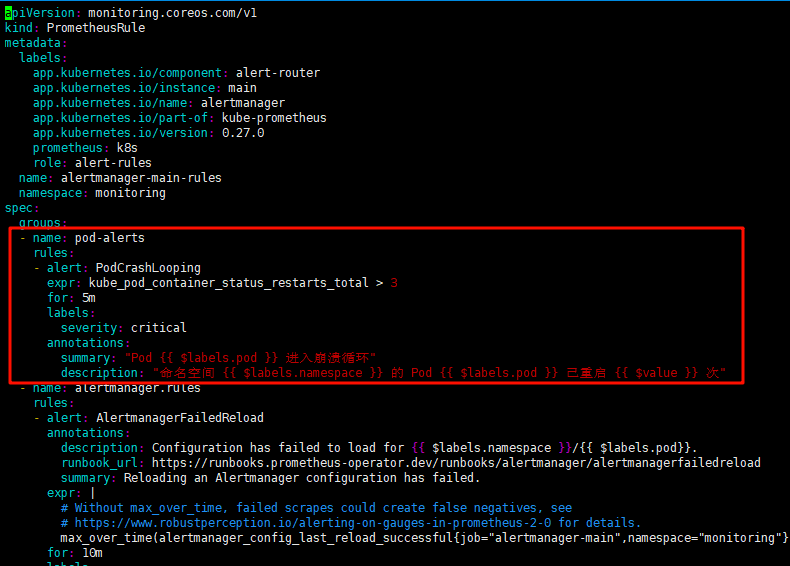
2. 触发测试加载规则
curl -X POST http://<SVC下prometheus-k8s的IP>:9090/-/reload # 热加载配置
四、验证
默认告警
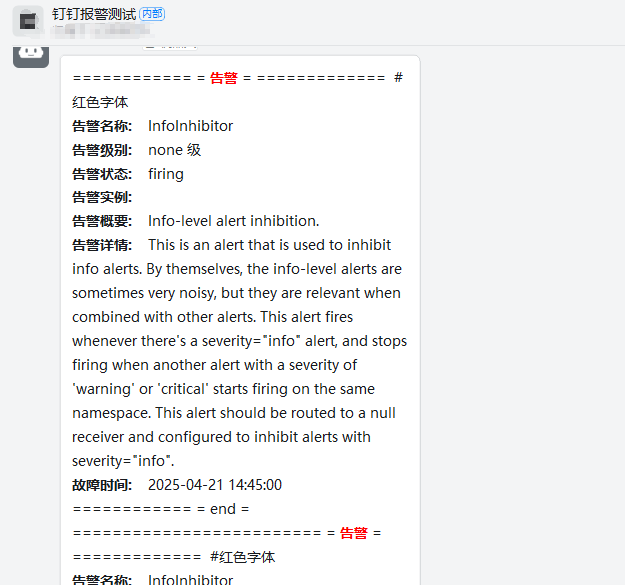
自定义告警
由于我们自定义的警告是一个pod重启3次即告警,那创建一个不停重启的pod就可以了.
记得修改镜像地址,不然去默认地址拉取的话会一直卡在初始化拉取镜像
-
# vim crash_pod.yaml
-
-
apiVersion: v1
-
kind: Pod
-
metadata:
-
name: crash-test-pod
-
spec:
-
containers:
-
- name: crash-container
-
image: m.daocloud.io/docker.io/library/busybox:latest
-
command: ["sh", "-c", "exit 1"] # 容器启动后立即退出
-
restartPolicy: OnFailure # 退出后自动重启
-
-
-
# kubectl apply -f crash_pod.yaml
通过Prometheus的web页面去查询重启次数大于3次的

再去钉钉查看报警
五、他人写好的告警规则
很多其他的自定义规则报警,可以参考之前提到的github中的内容
https://github.com/samber/awesome-prometheus-alerts
2025,每天10分钟,跟我学K8S(四十九)- 日志收集-CSDN博客
在日常k8s的使用中,由于应用都是运行在pod中的,所以日志文件也一般都会存储在pod中,那如何收集这一块的日志内容?K8S官方给了以下三种方案。
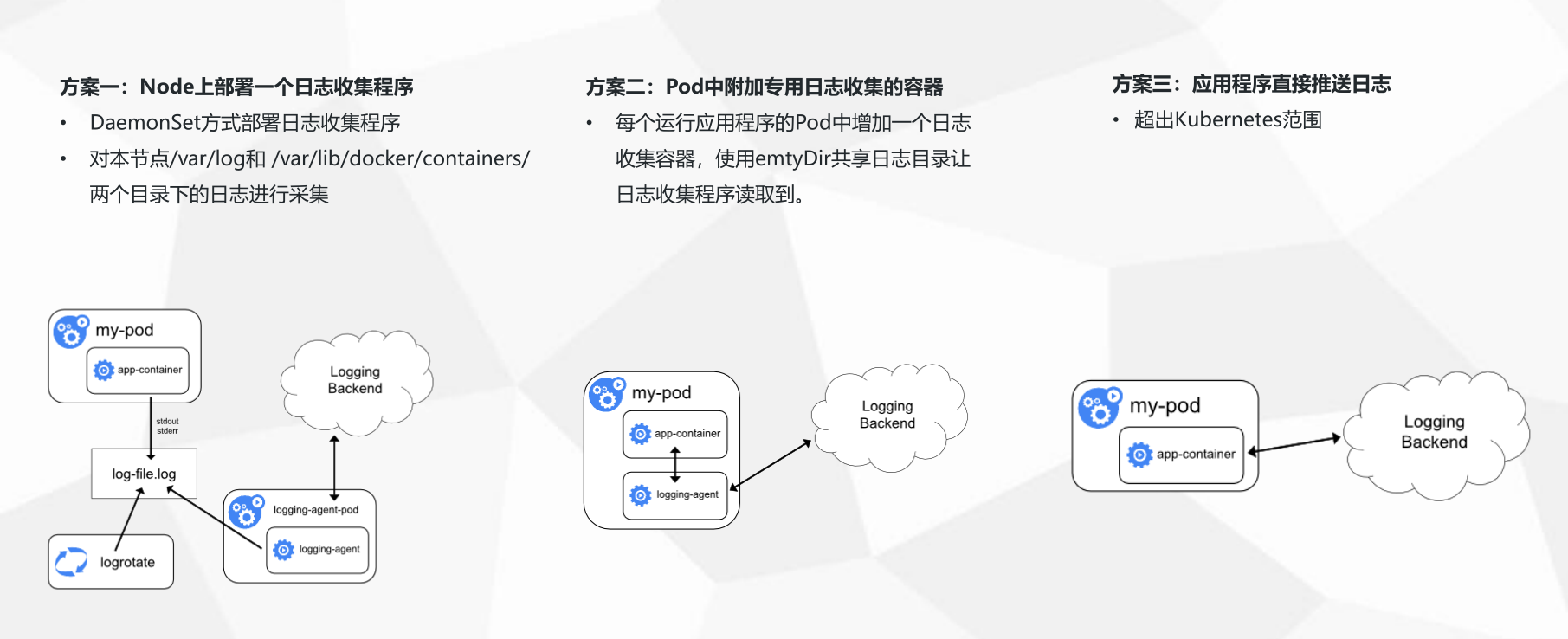
三种收集方案的优缺点:

三种方案各有自己的优缺点,但是综合比较下来,一般都是建议使用第二种方案,也是官方推荐的一种。
在同一个pod中运行2个容器,第一个容器运行业务程序,第二个容器运行日志收集程序,两个容器共享一个日志目录,当第一个业务程序将日志写入到日志目录后,日志收集程序将共享目录中的日志源文件进行收集并上传。
本章内容,就来一起了解下这种方案的具体操作过程。市面上日志收集处理的工具有很多,本文采用filebeat + elasticsearch的组合。大部分情况可以在filebeat 后面增加一个redis/kafka+logstash,来缓存数据和处理数据,得到想要的数据类型再进行上传到es中。这种后面有机会的话再来单章分析。
1.部署elasticsearch
创建es.yaml文件,用来创建es后端服务
-
root@k8s-master:~/tmp/root/elk# cat es.yaml
-
-
#pvc create longhorn pvc
-
apiVersion: v1
-
kind: PersistentVolumeClaim
-
metadata:
-
name: es-pv-claim
-
labels:
-
type: longhorn
-
app: es
-
spec:
-
storageClassName: longhorn
-
accessModes:
-
- ReadWriteOnce
-
resources:
-
requests:
-
storage: 10Gi
-
---
-
#ConfigMap create es config
-
apiVersion: v1
-
kind: ConfigMap
-
metadata:
-
name: es
-
data:
-
elasticsearch.yml: |
-
cluster.name: my-cluster
-
node.name: node-1
-
node.max_local_storage_nodes: 3
-
network.host: 0.0.0.0
-
http.port: 9200
-
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
-
cluster.initial_master_nodes: ["node-1"]
-
http.cors.enabled: true
-
http.cors.allow-origin: /.*/
-
---
-
#Deployment create es pod
-
apiVersion: apps/v1
-
kind: Deployment
-
metadata:
-
name: elasticsearch
-
spec:
-
selector:
-
matchLabels:
-
name: elasticsearch
-
replicas: 1
-
template:
-
metadata:
-
labels:
-
name: elasticsearch
-
spec:
-
securityContext:
-
fsGroup: 1000 # 关键:适配 Elasticsearch 用户组
-
initContainers:
-
- name: init-sysctl
-
image: m.daocloud.io/docker.io/busybox:latest
-
command:
-
- sysctl
-
- -w
-
- vm.max_map_count=262144
-
securityContext:
-
privileged: true
-
containers:
-
- name: elasticsearch
-
image: m.daocloud.io/docker.io/elasticsearch:7.6.2
-
imagePullPolicy: IfNotPresent
-
resources:
-
limits:
-
cpu: 1000m
-
memory: 2Gi
-
requests:
-
cpu: 100m
-
memory: 1Gi
-
env:
-
- name: ES_JAVA_OPTS
-
value: -Xms512m -Xmx512m
-
ports:
-
- containerPort: 9200
-
- containerPort: 9300
-
volumeMounts:
-
- name: elasticsearch-data
-
mountPath: /usr/share/elasticsearch/data/
-
- name: es-config
-
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
-
subPath: elasticsearch.yml
-
volumes:
-
- name: elasticsearch-data
-
persistentVolumeClaim:
-
claimName: es-pv-claim
-
- name: es-config
-
configMap:
-
name: es
-
---
-
#Service create es Service
-
apiVersion: v1
-
kind: Service
-
metadata:
-
name: elasticsearch
-
labels:
-
name: elasticsearch
-
spec:
-
type: NodePort
-
ports:
-
- name: web-9200
-
port: 9200
-
targetPort: 9200
-
protocol: TCP
-
nodePort: 30105
-
- name: web-9300
-
port: 9300
-
targetPort: 9300
-
protocol: TCP
-
nodePort: 30106
-
selector:
-
name: elasticsearch
-
-
-
-
-
# kubectl apply -f es.yaml
-
persistentvolumeclaim/es-pv-claim created
-
configmap/es created
-
deployment.apps/elasticsearch created
-
service/elasticsearch created
2.创建一个nginx的pod
同一个pod中运行2个容器,第一个容器运行业务程序,第二个容器运行日志收集程序,两个容器共享一个日志目录,当第一个业务程序将日志写入到日志目录后,日志收集程序将共享目录中的日志源文件进行收集并上传。
2.1 创建config
-
# cat nginx_test_configmap.yaml
-
---
-
# Filebeat 配置文件 ConfigMap
-
apiVersion: v1
-
kind: ConfigMap
-
metadata:
-
name: filebeat-config
-
data:
-
filebeat.yml: |
-
filebeat.inputs:
-
- type: log
-
enabled: true
-
paths:
-
- /var/log/nginx/access.log
-
- /var/log/nginx/error.log
-
fields:
-
app: nginx
-
fields_under_root: true
-
-
processors:
-
- add_kubernetes_metadata:
-
matchers:
-
- logs_path:
-
logs_path: "/var/log/containers/"
-
-
output.elasticsearch:
-
hosts: ["elasticsearch.default.svc.cluster.local:9200"]
-
indices:
-
- index: "nginx-logs-%{+yyyy.MM.dd}"
2.2 创建rbac
这里是由于默认的filebeat容器是使用非root用户,所以需要给对应的容器创建sa用户,赋予权限
-
# cat nginx_test_rbac.yaml
-
---
-
apiVersion: v1
-
kind: ServiceAccount
-
metadata:
-
name: filebeat-sa
-
---
-
apiVersion: rbac.authorization.k8s.io/v1
-
kind: ClusterRoleBinding
-
metadata:
-
name: filebeat-role-binding
-
subjects:
-
- kind: ServiceAccount
-
name: filebeat-sa
-
namespace: default
-
roleRef:
-
kind: ClusterRole
-
name: view
-
apiGroup: rbac.authorization.k8s.io
2.3 创建deployment和service
这里是关键步骤,一个deployment下面运行了两个containers,一个是nginx,用于模拟后台;一个是filebeat,用于收集日志。 两个containers共享了nginx-logs 这个存储卷,所以filebeat才能访问到nginx的日志
-
# cat nginx_test_deploy.yaml
-
apiVersion: apps/v1
-
kind: Deployment
-
metadata:
-
name: nginx-with-filebeat
-
spec:
-
replicas: 1
-
selector:
-
matchLabels:
-
app: nginx-with-filebeat
-
template:
-
metadata:
-
labels:
-
app: nginx-with-filebeat
-
spec:
-
# 使用上面rbac创建的sa用户来作为容器中的用户
-
serviceAccountName: filebeat-sa
-
containers:
-
# Nginx 主容器
-
- name: nginx
-
image: m.daocloud.io/docker.io/nginx:latest
-
ports:
-
- containerPort: 80
-
volumeMounts:
-
- name: nginx-logs
-
mountPath: /var/log/nginx
-
# Filebeat 日志采集 Sidecar 容器
-
- name: filebeat
-
image: docker.elastic.co/beats/filebeat:7.6.2
-
args: ["-c", "/etc/filebeat.yml", "-e"]
-
volumeMounts:
-
- name: nginx-logs
-
mountPath: /var/log/nginx
-
- name: filebeat-config
-
mountPath: /etc/filebeat.yml
-
subPath: filebeat.yml
-
securityContext:
-
runAsUser: 0 # 以 root 运行(避免日志文件权限问题)
-
-
# 共享存储卷定义
-
volumes:
-
- name: nginx-logs
-
emptyDir: {} # 日志存储(可根据需求改为 PVC,但是上传到了es就没必要再存在pv了)
-
- name: filebeat-config
-
configMap:
-
name: filebeat-config
3.部署kibana查看数据
-
# cat kibana.yaml
-
# Kibana Deployment
-
apiVersion: apps/v1
-
kind: Deployment
-
metadata:
-
name: kibana
-
namespace: default
-
spec:
-
replicas: 1
-
selector:
-
matchLabels:
-
app: kibana
-
template:
-
metadata:
-
labels:
-
app: kibana
-
spec:
-
containers:
-
- name: kibana
-
image: docker.elastic.co/kibana/kibana:7.6.2 # 版本需与 Elasticsearch 一致
-
env:
-
- name: ELASTICSEARCH_HOSTS # 关键配置:指向 Elasticsearch 地址
-
value: "http://elasticsearch.default.svc.cluster.local:9200"
-
ports:
-
- containerPort: 5601
-
resources:
-
limits:
-
memory: 1Gi
-
cpu: "1"
-
requests:
-
memory: 512Mi
-
cpu: "0.5"
-
---
-
# Kibana Service
-
apiVersion: v1
-
kind: Service
-
metadata:
-
name: kibana
-
namespace: default
-
spec:
-
type: NodePort # 生产环境建议使用 Ingress
-
ports:
-
- port: 5601
-
targetPort: 5601
-
nodePort: 30601 # 自定义端口范围(30000-32767)
-
selector:
-
app: kibana
4.应用
-
kubectl apply -f es.yaml
-
-
kubectl apply -f nginx_test_configmap.yaml
-
kubectl apply -f nginx_test_deploy.yaml
-
kubectl apply -f nginx_test_rbac.yaml
-
-
kubectl apply -f kibana.yaml
5.验证日志数据
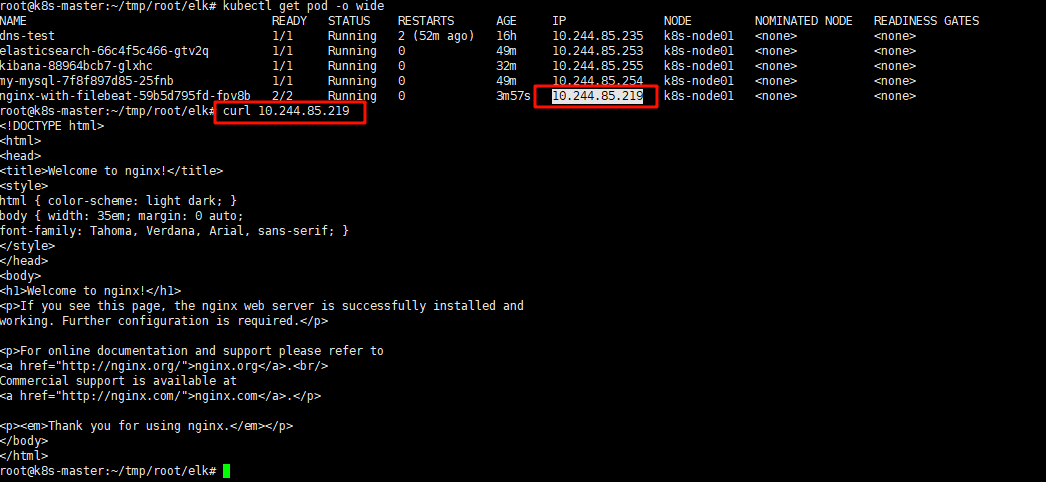
5.1 手动创造日志
获取nginx的IP,通过curl请求模拟一次访问,创建一条日志
-
# kubectl get pod -o wide
-
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
-
elasticsearch-66c4f5c466-gtv2q 1/1 Running 0 49m 10.244.85.253 k8s-node01 <none> <none>
-
kibana-88964bcb7-glxhc 1/1 Running 0 32m 1/1 Running 0 49m 10.244.85.254 k8s-node01 <none> <none>
-
nginx-with-filebeat-59b5d795fd-fpv8b 2/2 Running 0 3m57s 10.244.85.219 k8s-node01 <none> <none>
-
-
-
# curl 10.244.85.219
-
<!DOCTYPE html>
-
<html>
-
<head>
-
<title>Welcome to nginx!</title>
-
<style>
-
....
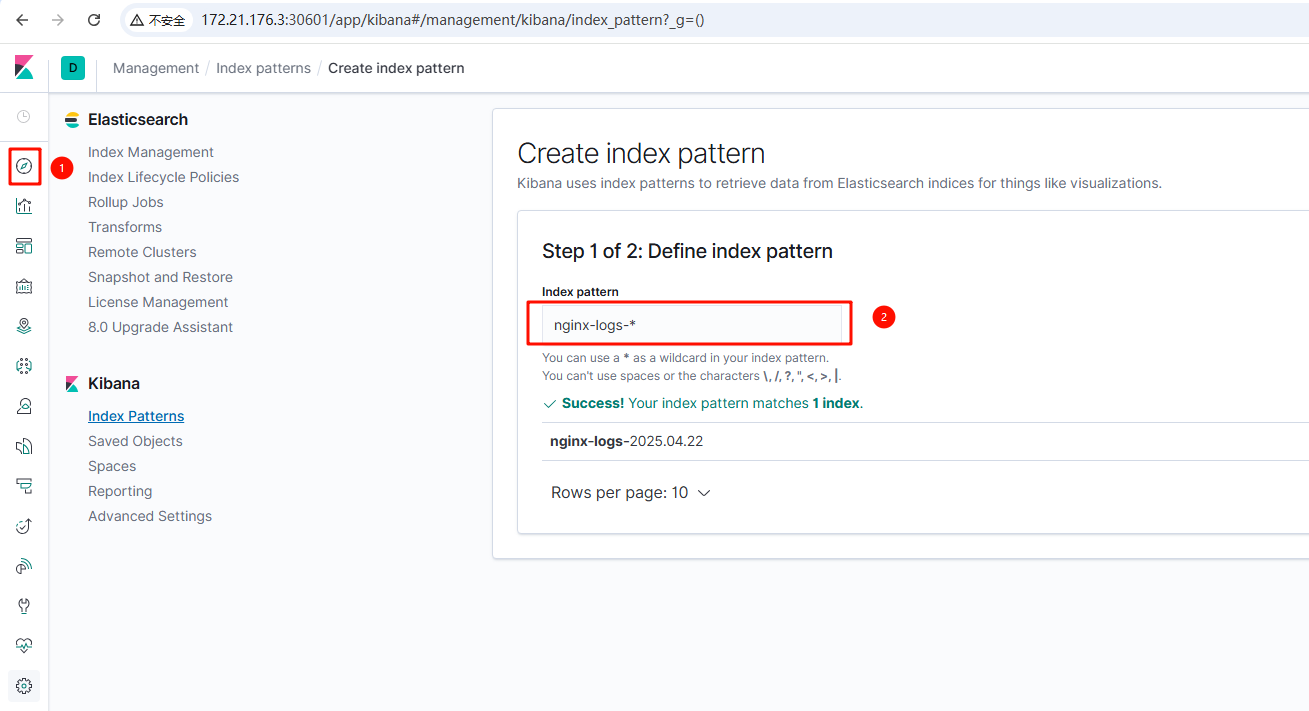
5.2 验证日志
1. 登录kibana,点击左上角的discover,出来的页面右侧创建索引模式,输入nginx-logs-*,这样可以匹配所有以nginx-logs- 开头的日志
2.下一步后添加一个时间字段,完成创建
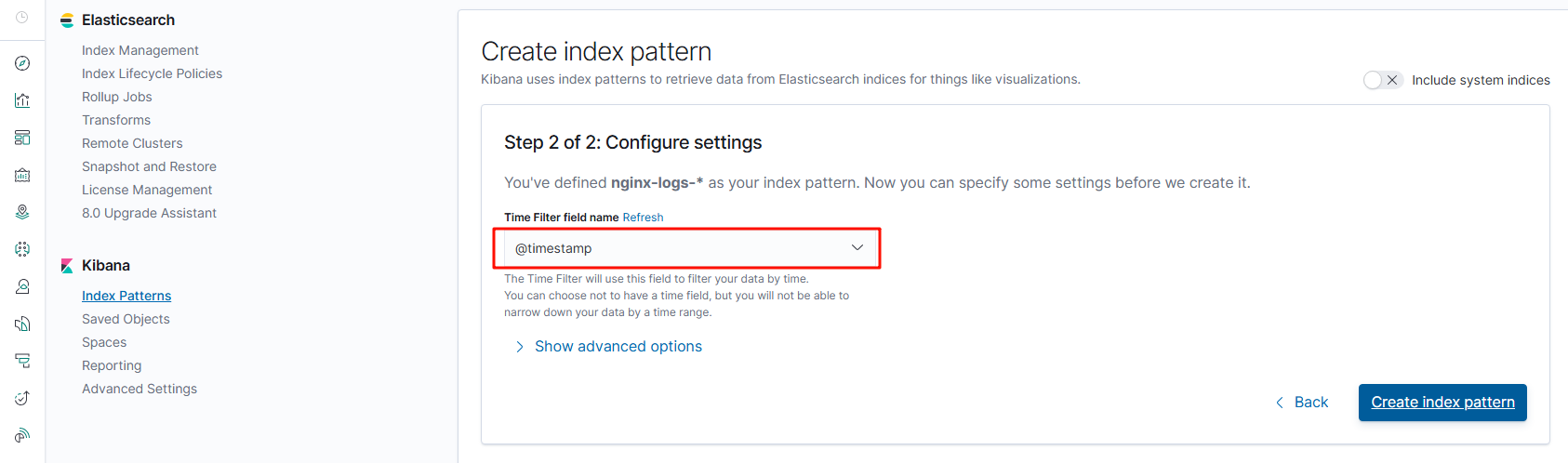
3. 再次点击左上角discover 即可看到nginx的日志
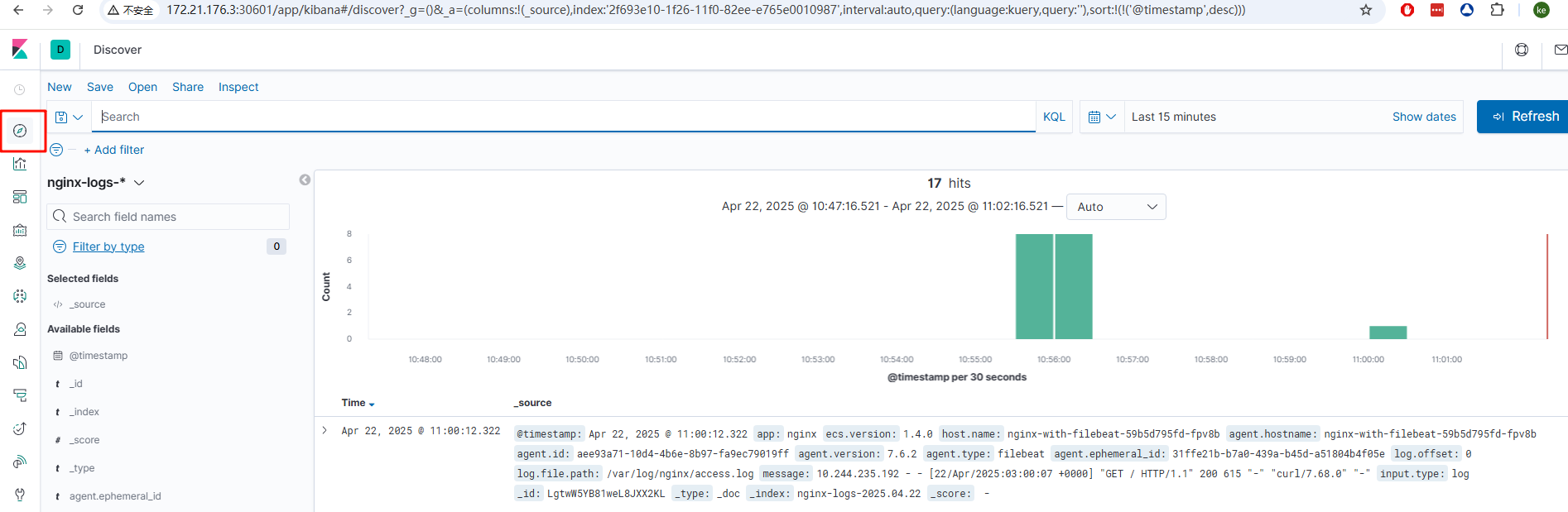

 浙公网安备 33010602011771号
浙公网安备 33010602011771号