HttpClient 连接池最大连接数配置?
在学习连接池时,看到别人分享的资料中提到httpclient设置的最大连接数绝对不能超过tomcat设置的最大连接数, 求解为什么.
https://www.zhihu.com/question/264308371
连接池
我们使用连接来进行系统间的交互,如何管理成千上万的连接呢?
服务器可以快 速创建和断开连接,但对于高并发的后台服务器而言,连接的频繁创建与断开,是非 常重的负担。就好像我们正在紧急处理线上故障,给同事打电话一起定位问题时, 般情况下都不会挂断电话,直到问题解决。在时间极度紧张的情况下,频繁地拨打和 接听电话会降低处理问题的效率。在客户端与服务端之间可以事先创建若干连接并提 前放置在连接池中,需要时可以从连接池直接获取,数据传输完成后,将连接归还至 连接池中,从而减少频繁创建和释放连接所造成的开销。例如,RPC服务集群的注册中心与服务提供方、消费方之间,消息服务集群的缓存服务器和消费者服务器之间, 应用后台服务器和数据库之间,都会使用连接池来提升性能。
重点提一下数据库连接池,连接资源在数据库端是一种非常关键且有限的系统资源。连接过多往往会严重影响数据库性能。数据库连接池负责分配、管理和释放连 接,这是 种以内存空间换取时间的策略,能够明显地提升数据库操作的性能。但如 果数据库连接管理不善,也会影响到整个应用集群的吞吐量。连接池配置错误加上慢 SQL,就像屋漏偏逢连夜雨,可以瞬间让一个系统进入服务超时假死音机状态。
如何合理地创建、管理、断开连接呢? 以 Druid 为例, Druid 是阿里巴巴的一个数据库连接池开源框架,准确来说它不仅仅包括数据库连接池,还提供了强大的监控和扩展功能。当应用启动时,连接池初始化最小连接数( MIN );当外部请求到达时,直接使用空闲连接即可。假如并发数达到最大( MAX ),则需要等待,直到超肘。 如果一直未拿到连接,就会抛出异常。
如果 MIN 过小,可能会出现过多请求排队等待获取连接,如果 MIN 过大,会造成资源浪费。如果 MAX 过小,则峰值情况下仍有很多请求处于等待状态;如果 MAX 过大,可能导致数据库连接被占满,大量请求超时,进而影响其他应用,引发服务器连环雪崩。在实际业务中,假如数据库配置的 MAX 是100, 一个请求10ms, 则最大能够处理 10000QPS。增大连接数,有可能会超过单台服务器的正常负载能力。 另外,连接数的创建是受到服务器操作系统的fd(文件描述符)数量限制的。创建更多的活跃连接,就需要消耗更多的fd,系统默认单个进程可同时拥有 1024个fd,该值虽然可以适当调整,但如果无限制地增加,会导致服务器在fd的维护和切换上消耗过多的精力,从而降低应用吞吐量。
懒惰是人的天性,有时候开发工程师为了图省事还会不依不饶地要求调长 Timeout 时间,如果这个数值过大,对于调用端来说也是不可接受的。如果应用服务器超时,前台已经失败返回,但是后台仍然在没有意义地重试,并且还有新的处理请求不断堆积,最终导致服务器崩溃。这明显是不合理的。所以在双十一的场景里,应用服务器的全链路上不论是连接池的峰值处理,还是应用之间的调用频率,都会有相关的限流措施和降级预案。
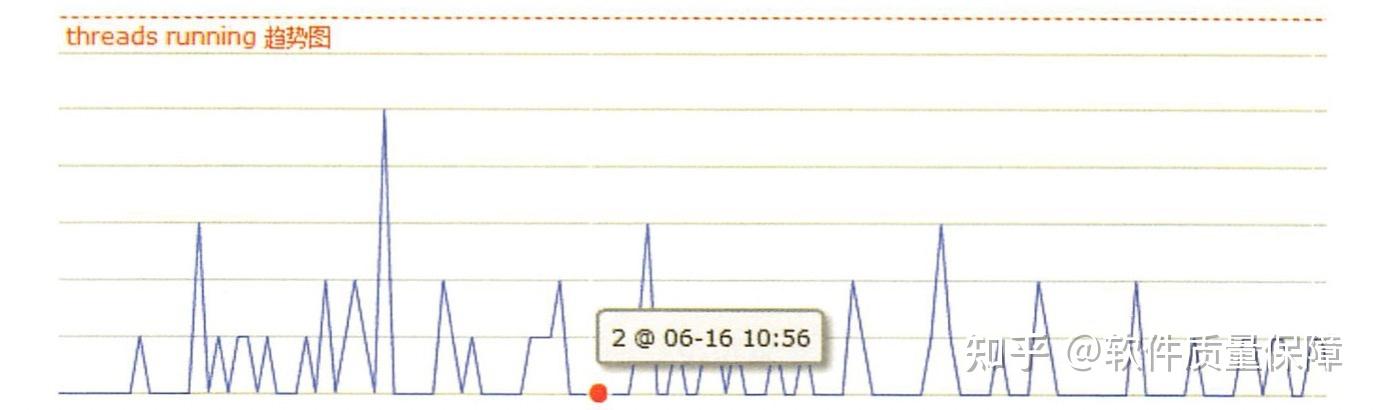
图所示的是某连接池的监控图。图中连接池最小的连接数是 2, 一个线程 就是 个活跃连接。一般可以把连接池的最大连接数设置在 30 个左右 , 理论上还可以设置更大的值,但是 DBA 一般不会允许,因为往往只有出现了慢 SQL, 才需要使用更多的连接数。这时候通常需要优化应用层逻辑或者创建数据库索引,而不是一昧地采用加大连接数这种治标不治本的做法。极端情况下甚至会导致数据库服务不响应,进而影响其他业务。
从经验上来看,在数据库层面的请求应答时间必须在 IOOms 以内,秒级的 SQL
查询通常存在巨大的性能提升空间,有如下应对方案,
( I ) 建主高效且合适的索引。 索引谁都可以建,但要想建好难度极大。因为索引既有数据特征,又有业务特征,数据量的变化会影响索引的选择,业务特点不一样, 索引的优化思路也不一样。通常某个字段平时不用,但是某种触发场景下命中“索引缺失”的字段会导致查询瞬间变慢。所以,要事先明确业务场景,建立合适的索引。
( 2 )排查连接资源未显式关闭的情形。 要特别注意在 ThreadLocal 或流式计算中使用数据库连接的地方。
( 3 )合并短的请求。 根据 CPU 的空间局部性原理,对于相近的数据,CPU 会一起提取到内存中。另外,合并请求也可以有效减少连接的次数。
( 4 )合理拆分多个表join的SQL, 若是超过三个表则禁止join。 如果表结构建 得不合理,应用逻辑处理不当,业务模型抽象有问题 , 那么三表 join 的数据量由于笛卡儿积操作会呈几何级数增加,所以不推荐这样的做法。另外,对于需要 join 的字段, 数据类型应保持绝对一致。多表关联查询时,应确保被关联的字段要有索引。
( 5 ) 使用临时表。 某种情况下,该方法是一种比较好的选择。曾经遇到一个场景不使用临时表需要执行 1 个多小时 ,使用临时表可以降低至 2 分钟以内。因为在不断的嵌套查询中,已经无法很好地利用现有的索引提升查询效率,所以把中间结果保 存到临时表,然后重建索引 ,再通过临时表进行后续的数据操作。
( 6 ) 应用层优化。 包括进行数据结构优化、并发多线程改造等。
( 7 ) 改用其他数据库。 因为不同数据库针对的业务场景是不同的,比如Cassandra、 MongoDB 。
你给的那篇文章已经回答了你的疑问:“否则tomcat的连接就会被httpclient连接池一直占用”。连接池为了解决建立连接过程的开销,本身就是预先占用了资源准备好随时待用,你设置的大它占用的自然就多。
在apacheHttpClient的连接池管理里面有几个概念需要注意:
Keep-Alive这个是连接的期望的长链接的保持时间.- 连接空闲时间 IdleConnectionTime
- 连接过期时间 ExpiredConnections 相关的时间.
有同学可能(不要问我那个同学是谁)会认为Keep-Alive的时间就是连接池里面的连接的最长可用时间. 因为平时我们也这样认为的,KeepAlive时间来控制连接的生命周期.
比如:
httpClient在发起请求时, 添加了请求头 Keep-Alive: 5s ,此时使用的是一个新连接. 下次我传的Keep-Alive: 10s. 那这个连接会被重用到10秒结束吗.
这些概念比较难梳理清楚. 实际在apacheHttpClient中. HttpClient无法直接控制TCP层面的keep-alive的具体行为,它优先遵循HTTP规范。在HTTP 1.1中,默认所有连接都是持久化的,除非有显式声明关闭(如 Connection: close)。Keep-Alive头部字段在HTTP 1.1规范中实际上没有明确定义,它是在HTTP 1.0中对持久连接的一个扩展。
Keep-Alive: 5s 实际上是一个不太标准的用法,通常客户端和服务端都可能忽略它。即使服务端理解并接受了这个header,它也只是表明服务端在处理完请求后,应该在关闭连接前持续等待5秒以期待可能存在的后续请求。这并不代表客户端保留连接的时间,也无关这个连接是否能被重用。
在下一次请求时,如果传递 Keep-Alive: 10s,并不会影响前一个连接。如果前一个连接在这个时候还是可用的(在最近的5秒内没有新请求,服务端选择关闭连接后,那么它就不再可用),那么它可能被重用。不过实际上,连接是否能够被重用,是由很多因素决定的,不仅仅看设置的Keep-Alive值。
Apache HttpClient执行以下步骤来管理和维护连接池中连接的生命周期:
- 请求连接:当一个请求到来时,并且需要建立一个新的连接,PoolingHttpClientConnectionManager会先检查连接池中是否存在闲置的可重用的连接。如果找到匹配的闲置连接,会直接重用。否则,会尝试创建新的连接。
- 释放连接:当一个请求处理完成,连接会被默认保持开放,并被归还到连接池中,以供后续的请求重复使用。如果请求明确指明了不使用
keep-alive(通过设置Connection: close),连接会在请求处理完成后被关闭,并且不会归还给连接池。 - 过时检查:
PoolingHttpClientConnectionManager有一个管理器线程,会周期性地检查连接池中的连接。如果一个连接被标记为stale(陈旧的,可能已经无法再使用的连接),或者空闲时间超过了maxIdleTime设置的值,则会关闭这个连接。 - 连接过期:每个连接都有一个到期时间,即从被创建开始,在一定时间后,它会被认为是过期的。如果一个连接到了过期时间.(由
connTimeToLive),连接管理器线程会关闭它。
此外,Apache HttpClient还会在发起请求时检查目标连接是否被stale或过期,如果是,则会自动新建一个连接。
总结一下: apacheHttpClient有一个专门的连接有效期的设置时间:connTimeToLive 用来管理每一个链接的实际过期时间. 只要连接的存在的时间超过了这个时间就会直接释放掉,不过连接是否真的有效.
如果把KeepAlive理解为有效期可能错误有十万八千里. 一般的代码会设定: evictIdleConnections 来管理空闲在连接池的空闲连接. 而多半大部分可用会误以为这个就是兜底的逻辑. 因为空闲的链接确实在这里进行释放.

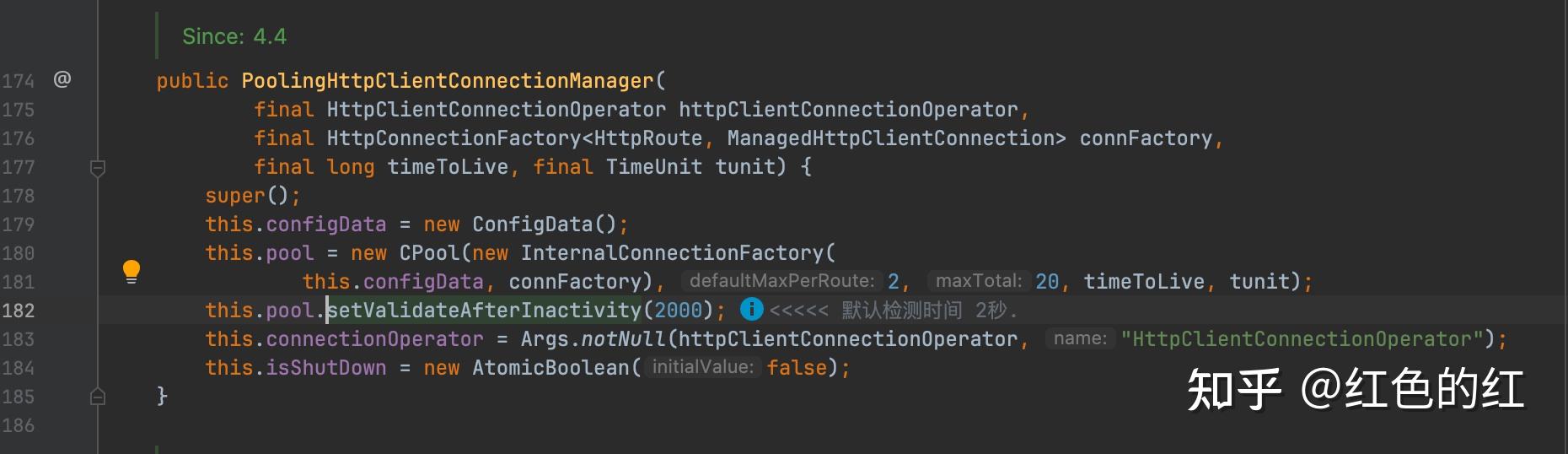
但是, 在版本4.5以后. 每一次请求将不再建议进行连接有效性检验. 也就是以下的这一行代码:

这样,在每一次使用时就有可能连接是无效的. 而这个机制去除后, apacheClient添加了另外一个机制来对连接进行保活探测:

而这个check的配置.如果使用builder来构建httpClient的时候,是没有暴露这参数的配置的. 但是实际内部在初始化的时候是有配置的. 默认时间是2秒.也就是如果一个连接在连接池里面空闲了2秒以上(包含).那在下一次使用的时候就会进行有效性检测.
综合起来, 如果忽略了最长有效时间.那一般可以用:
- maxIdle时间来控制空闲连接的回收.
- 2秒时间的保活探测确保连接是有效的.
但是如果忽略了最长有效期.就会使一个连接最终用到服务端的结束时间. 想象一种场景.一个一直被用的连接.一直被复用. 由于没有最长时间的限制,非常有可能在后期接近或者超过服务端的最长连接时间. 此时服务端就可能会主动断开连接. 而在server端断开,客户端恰好每次使用的时间都低于2秒时. 那就会跳过staleCheck. 最终造成使用一个半连接.(half-close).
所以这个最长有效期的时间非常关键. 如果没有设置会造成client访问的不稳定性.
以下是我的一个完整的配置. 你也可以直接参考(copy)使用:
/**
* 构造默认的构造函数
*
* @param connTimeout 连接超时时间
* @param readTimeout 读超时时间
* @param maxTotal 最大连接数
* @param maxPerRoute 每个路由的最大链接数
* @param openDefinitionExceptionRetry 开启重试的异常;如开启多个异常重试,值是 HttpRequestRetryHandler 中retry常量值的或运算结果
* @param retryCount 重试次数
* @return HttpsClientV2
*/
public static HttpsClientV2 createHttpsClient(int connTimeout,
int readTimeout,
int maxTotal,
int maxPerRoute,
boolean defaultRetry,
int openDefinitionExceptionRetry,
int retryCount,
Integer keepAliveTime) {
ForceKeepAliveStrategy forceKeepAliveStrategy = new ForceKeepAliveStrategy(
keepAliveTime != null ? keepAliveTime : DEFAULT_KEEP_ALIVE_TIME
);
// 参考初始化方式: https://blog.csdn.net/wanghuiqi2008/article/details/55260073
X509TrustManager x509TrustManager = new X509TrustManager() {
@Override
public void checkClientTrusted(X509Certificate[] x509Certificates, String s) throws CertificateException {
}
@Override
public void checkServerTrusted(X509Certificate[] x509Certificates, String s) throws CertificateException {
}
@Override
public X509Certificate[] getAcceptedIssuers() {
return new X509Certificate[0];
}
};
SSLConnectionSocketFactory socketFactory = null;
try {
SSLContext sslContext = SSLContext.getInstance("SSL");
sslContext.init(null, new TrustManager[]{x509TrustManager}, new SecureRandom());
socketFactory = new SSLConnectionSocketFactory(sslContext,
NoopHostnameVerifier.INSTANCE);
} catch (NoSuchAlgorithmException | KeyManagementException e) {
logger.error("初始化出错,无法支持 HTTPS 特殊配置.降级为普通 httpClient.....", e);
}
ConnectionConfig connectionConfig = ConnectionConfig.custom()
//.setBufferSize(8192)
.build();
/**
* 连接池配置: 对于无法进行兜底的 StaleConnectionCheck,可以通过设置 validateAfterInactivity 来进行控制.
* 见: {@link org.apache.http.impl.conn.PoolingHttpClientConnectionManager#setValidateAfterInactivity(int)}
*/
RequestConfig requestConfig = RequestConfig.custom()
.setConnectTimeout(connTimeout) // 连接目标超时connectionTimeout
.setConnectionRequestTimeout(DEFAULT_CONNECTION_REQUEST_TIMEOUT) // 从连接池中获取可用连接超时
.setSocketTimeout(readTimeout) // 等待响应超时(读取数据超时)socketTimeout
//.setStaleConnectionCheckEnabled(true) // 新版本从4.5开始,不推荐使用 stale 检测
.setCookieSpec(CookieSpecs.IGNORE_COOKIES) // 忽略所有 cookie
.build();
// PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
/**
* 过期链接的清理在线程: {@link org.apache.http.impl.client.IdleConnectionEvictor}. 这个除了清理空闲超时的连接外.还会清理过期的连接.
* 文档1: https://blog.csdn.net/u012760435/article/details/124858901
* 文档2: https://www.cnblogs.com/fifty-two-hertz/p/14097822.html
*/
HttpClientBuilder httpClientBuilder = HttpClients
.custom()
.setDefaultConnectionConfig(connectionConfig)
.setDefaultRequestConfig(requestConfig) //
.setUserAgent(DEFAULT_USER_AGENT) // 查看覆盖情况是否影响
.setMaxConnTotal(maxTotal) // can be overridden by the {@link #setConnectionManager
.setMaxConnPerRoute(maxPerRoute)
.setRetryHandler(new HttpRequestRetryHandler(retryCount, false, openDefinitionExceptionRetry))
.setKeepAliveStrategy(forceKeepAliveStrategy) // 长连接保持时间
.evictExpiredConnections() // 探测过期链接清理( 默认是 DEFAULT_KEEP_ALIVE_TIME / 15s )
.setConnectionTimeToLive(DEFAULT_KEEP_ALIVE_TIME, TimeUnit.MILLISECONDS)
.evictIdleConnections(DEFAULT_IDLE_CONNECT_TIME, TimeUnit.SECONDS);// 空闲链接探测时间.3s 不用的链接认为是空闲链接 (这个时间会决定 background 线程的频率)
/* ssl 工厂类构建失败时,不配置独立的工厂类,使用默认的工厂类 **/
if (socketFactory != null) {
httpClientBuilder.setSSLSocketFactory(socketFactory);
}
/* 是否自动重试(默认会自动重试,传 false 会禁用此功能) **/
if (!defaultRetry) {
httpClientBuilder.disableAutomaticRetries();
}
CloseableHttpClient httpClient = httpClientBuilder.build();
try {
// Note: 不做具体的业务信息. 这里打印一下默认的链接池信息. 默认链接在放回到连接池超过2s就会检查连接的有效性.
Field connManagerF = httpClient.getClass().getDeclaredField("connManager");
connManagerF.setAccessible(true);
PoolingHttpClientConnectionManager connectionManager = (PoolingHttpClientConnectionManager) connManagerF.get(httpClient);
logger.info("httpsV2Client.ValidateAfterInactivity {}ms", connectionManager.getValidateAfterInactivity());
} catch (Exception e) {
logger.warn("获取链接池信息失败", e);
// do nothing
}
return new HttpsClientV2(httpClient,requestConfig);
}众所周知,httpclient是java开发中非常常见的一种访问网络资源的方式了。这里不再赘述httpclient强大的功能使用了,比如读取网页(HTTP/HTTPS)内容,以GET或者POST方式向网页提交参数,处理页面重定向,模拟输入用户名和口令进行登录,提交XML格式参数,通过HTTP上传文件,访问启用认证的页面以及httpclient在多线程下的使用.
这里说一下多线程模式下使用httpclient连接池的使用注意事项:
org.apache.http.impl.conn.PoolingClientConnectionManager;
使用这个类就可以使用httpclient连接池的功能了,其可以设置最大连接数和最大路由连接数。
public final static int MAX_TOTAL_CONNECTIONS = 400; public final static int MAX_ROUTE_CONNECTIONS = 200; -
cm = new PoolingClientConnectionManager();
-
cm.setMaxTotal(MAX_TOTAL_CONNECTIONS);
-
cm.setDefaultMaxPerRoute(MAX_ROUTE_CONNECTIONS);
最大连接数就是连接池允许的最大连接数,最大路由连接数就是没有路由站点的最大连接数,比如:
- HttpHostgoogleResearch=newHttpHost("research.google.com",80);
- HttpHostwikipediaEn=newHttpHost("en.wikipedia.org",80);
- cm.setMaxPerRoute(newHttpRoute(googleResearch),30);
- cm.setMaxPerRoute(newHttpRoute(wikipediaEn),50);
并且可以设置httpclient连接等待请求等待时间,相应时间等。
说几个要注意点:
1.首先配置最大连接数和最大路由连接数,如果你要连接的url只有一个,两个必须配置成一样,否则只会取最小值。(这是个坑,默认最大连接是20,每个路由最大连接是2)
2.最好配置httpclient连接等待时间,和相应时间。否则就会一直等待。
-
httpParams = new BasicHttpParams();
-
httpParams.setParameter(CoreConnectionPNames.CONNECTION_TIMEOUT,CONNECT_TIMEOUT);
-
httpParams.setParameter(CoreConnectionPNames.SO_TIMEOUT, READ_TIMEOUT);
3 httpclient必须releaseconnection,但不是abort。因为releaseconnection是归还连接到连接池,而abort是直接抛弃这个连接,而且占用连接池的数目。(一定要注意)
HttpGet httpGet = new HttpGet(searchurl);httpGet.releaseConnection();4 (一定要注意)httpclient设置的最大连接数绝对不能超过tomcat设置的最大连接数,否则tomcat的连接就会被httpclient连接池一直占用,直到系统挂掉。
5 可以使用tomcat的长连接和htppclient连接池和合理使用来增加系统响应速度。
连接池技术作为创建和管理连接的缓冲池技术,目前已广泛用于诸如数据库连接等长连接的维护和管理中,能够有效减少系统的响应时间,节省服务器资源开销。其优势主要有两个:其一是减少创建连接的资源开销,其二是资源的访问控制。连接池管理的对象是长连接,对于HTTP连接是否适用,我们需要首先回顾一下长连接和短连接。
所谓长连接是指客户端与服务器端一旦建立连接以后,可以进行多次数据传输而不需重新建立连接,而短连接则每次数据传输都需要客户端和服务器端建立一次连接。长连接的优势在于省去了每次数据传输连接建立的时间开销,能够大幅度提高数据传输的速度,对于P2P应用十分适合,但是对于诸如Web网站之类的B2C应用,并发请求量大,每一个用户又不需频繁的操作的场景下,维护大量的长连接对服务器无疑是一个巨大的考验。而此时,短连接可能更加适用。但是短连接每次数据传输都需要建立连接,我们知道HTTP协议的传输层协议是TCP协议,TCP连接的建立和释放分别需要进行3次握手和4次握手,频繁的建立连接即增加了时间开销,同时频繁的创建和销毁Socket同样是对服务器端资源的浪费。所以对于需要频繁发送HTTP请求的应用,需要在客户端使用HTTP长连接。
HTTP连接是无状态的,这样很容易给我们造成HTTP连接是短连接的错觉,实际上HTTP1.1默认即是持久连接,HTTP1.0也可以通过在请求头中设置Connection:keep-alive使得连接为长连接。既然HTTP协议支持长连接,我们就有理由相信HTTP连接同样需要连接池技术来管理和维护连接建立和销毁。HTTP Client4.0的ThreadSafeClientConnManager实现了HTTP连接的池化管理,其管理连接的基本单位是Route(路由),每个路由上都会维护一定数量的HTTP连接。这里的Route的概念可以理解为客户端机器到目标机器的一条线路,例如使用HttpClient的实现来分别请求 www.163.com 的资源和 www.sina.com 的资源就会产生两个route。缺省条件下对于每个Route,HttpClient仅维护2个连接,总数不超过20个连接,显然对于大多数应用来讲,都是不够用的,可以通过设置HTTP参数进行调整。
HttpParams params = new BasicHttpParams();
//将每个路由的最大连接数增加到200
ConnManagerParams.setMaxTotalConnections(params,200);
// 将每个路由的默认连接数设置为20
ConnPerRouteBean connPerRoute = new ConnPerRouteBean(20);
// 设置某一个IP的最大连接数
-
HttpHost localhost = new HttpHost("locahost", 80);
-
connPerRoute.setMaxForRoute(new HttpRoute(localhost), 50);
-
ConnManagerParams.setMaxConnectionsPerRoute(params, connPerRoute);
-
SchemeRegistry schemeRegistry = new SchemeRegistry();
-
schemeRegistry.register( new Scheme("http", PlainSocketFactory.getSocketFactory(), 80));
-
schemeRegistry.register( new Scheme("https", SSLSocketFactory.getSocketFactory(), 443));
-
ClientConnectionManager cm = new ThreadSafeClientConnManager(params, schemeRegistry);
-
HttpClient httpClient = new DefaultHttpClient(cm, params);
可以配置的HTTP参数有:
1) http.conn-manager.timeout 当某一线程向连接池请求分配线程时,如果连接池已经没有可以分配的连接时,该线程将会被阻塞,直至http.conn-manager.timeout超时,抛出ConnectionPoolTimeoutException。
2) http.conn-manager.max-per-route 每个路由的最大连接数;
3) http.conn-manager.max-total 总的连接数;
连接的有效性检测是所有连接池都面临的一个通用问题,大部分HTTP服务器为了控制资源开销,并不会
永久的维护一个长连接,而是一段时间就会关闭该连接。放回连接池的连接,如果在服务器端已经关闭,客
户端是无法检测到这个状态变化而及时的关闭Socket的。这就造成了线程从连接池中获取的连接不一定是有效的。这个问题的一个解决方法就是在每次请求之前检查该连接是否已经存在了过长时间,可能已过期。但是这个方法会使得每次请求都增加额外的开销。HTTP Client4.0的ThreadSafeClientConnManager 提供了
closeExpiredConnections()方法和closeIdleConnections()方法来解决该问题。前一个方法是清除连接池中所有过期的连接,至于连接什么时候过期可以设置,设置方法将在下面提到,而后一个方法则是关闭一定时间空闲的连接,可以使用一个单独的线程完成这个工作。
public static class IdleConnectionMonitorThread extends Thread{
private final ClientConnectionManagerconnMgr;
privatevolatilebooleanshutdown;
public IdleConnectionMonitorThread(ClientConnectionManagerconnMgr){
super();
this.connMgr=connMgr;
}
@Override
public void run(){
try{
while(!shutdown){
synchronized(this){
wait(5000);//关闭过期的连接connMgr.closeExpiredConnections();//关闭空闲时间超过30秒的连接connMgr.closeIdleConnections(30,
TimeUnit.SECONDS);
}
}
}catch(InterruptedExceptionex){
//terminate
}
}
public void shutdown(){
shutdown=true;
synchronized(this){
notifyAll();
}
刚才提到,客户端可以设置连接的过期时间,可以通过HttpClient的setKeepAliveStrategy方法设置连接的过期时间,这样就可以配合closeExpiredConnections()方法解决连接池中连接失效的。
DefaultHttpClient httpclient=newDefaultHttpClient();
httpclient.setKeepAliveStrategy(new ConnectionKeepAliveStrategy(){
public long getKeepAliveDuration(HttpResponseresponse,HttpContextcontext){
//Honor'keep-alive'headerHeaderElementIteratorit=newBasicHeaderElementIterator(response.headerIterator(HTTP.CONN_KEEP_ALIVE));while(it.hasNext()){
HeaderElement he=it.nextElement();
String param= he.getName();
String value=he.getValue();
if(value!=null&¶m.equalsIgnoreCase("timeout")){
try{
return Long.parseLong(value)*1000;
}catch(NumberFormatExceptionignore){
}
}
}
HttpHost target=(HttpHost)context.getAttribute(ExecutionContext.HTTP_TARGET_HOST);
if("www.163.com".equalsIgnoreCase(target.getHostName())){
//对于163这个路由的连接,保持5秒return5*1000;
}else{
//其他路由保持30秒return30*1000;
}
}
})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号