OOM专题 - 如何使用JdbcTemplate查询百万行超大结果,以及其他JdbcTemplate 其他冷门实用技能_jdbctemplate查询大批量数据-CSDN博客
问题 :当一次性查询 百万行的数据,返回给前端的时候,很容易就会导致OOM。全网搜索,没有满意的解决方案,因此自己研究了 几番 JdbcTemplate 源码,手动编码解决。
原因 :JDBC 一次性封装成了 百万个 对象,而且都不能被回收。如此大规模的快速生成对象,会立刻把JVM 盛满,而且都是不可回收对象,导致GC频繁,触发FullGC, 但是没什么实际效果。机器变得卡顿,OOM随之发生。
思路 :自己手动控制 ResultSet 对象的生成过程,及时 将大对象 改变成小对象,临时保存为 磁盘的File ,立刻释放内存的占用,让GC及时回收垃圾。最终将文件流封装进 response 的输出流中,返回给前端。
核心思想:此时的 ResultSet 仅仅是 数据库的一个游标指针(cursor ),并不是真实的全部数据,所以并不会占据内存空间。理解这一点非常重要 !!!我当年研究了 很多资料才得到这一看似简单的真知灼见。
避坑指南:千万不能使用 SqlRowSet,因为 该对象是 真实的全部数据,并不是游标指针,所以会占据很多的内存空间。请看:
SqlRowSet queryForRowSet (String sql, Object... args) throws DataAccessException;
protected SqlRowSet createSqlRowSet (ResultSet rs) throws SQLException {
CachedRowSet rowSet = newCachedRowSet();
return new ResultSetWrappingSqlRowSet (rowSet);
解决以上问题的思路,最核心的示例代码如下: 每隔5w行,写一次磁盘,并且清空一次当前的大对象,让 GC 来 work ,收走 garbage
File file = new File ("临时文件全路径" )
Object query = getJdbcTemplate().query(sql.toString(), new ResultSetExtractor <Object>() {
public Object extractData (ResultSet rs) throws SQLException, DataAccessException {
processRow(columnCount, rs, sb);
IOUtils.write(sb, new FileOutputStream (file,true ), "UTF-8" );
sb.delete(0 , sb.length());
完整代码如下: 可以直接CP到你的项目中使用
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.IOUtils;
import org.springframework.dao.DataAccessException;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.ResultSetExtractor;
import org.springframework.jdbc.support.JdbcUtils;
import java.io.FileOutputStream;
import java.io.IOException;
import java.sql.ResultSet;
import java.sql.SQLException;
public File queryBigResult (CharSequence sql,Object... o) {
final StringBuilder sb = new StringBuilder (5000000 * 2 );
final File file = new File (SystemUtils.getJavaIoTmpDir() + File.separator + "临时大文件存储,可以删除" .concat(System.currentTimeMillis() + "" ).concat(".csv" ));
Object query = getJdbcTemplate().query(sql.toString(), new ResultSetExtractor <Object>() {
public Object extractData (ResultSet rs) throws SQLException, DataAccessException {
ResultSetMetaInfo info = new ResultSetMetaInfo (rs);
String[] columnNames = info.getColumnNames();
int columnCount = info.getColumnCount(), line = 0 ;
for (int i = 0 ; i < columnCount; i++) {
sb.append(columnNames[i]).append("," );
sb.deleteCharAt(sb.length() - 1 ).append("\n" );
processRow(columnCount, rs, sb);
IOUtils.write(sb, new FileOutputStream (file,true ), "UTF-8" );
} catch (IOException e) {
log.error("正在写盘 [{}] 行时出错:{}" , line, Utils.logMessage(e));
sb.delete(0 , sb.length());
IOUtils.write(sb, new FileOutputStream (file,true ), "UTF-8" );
} catch (IOException e) {
log.error("最后写盘 [{}] 行时出错:{}" , line, Utils.logMessage(e));
sb.delete(0 , sb.length());
private static void processRow (int columnCount, ResultSet rs, StringBuilder sb) throws SQLException {
for (int i = 1 ; i <= columnCount; i++) {
Object value = JdbcUtils.getResultSetValue(rs, i);
sb.append(value).append("," );
sb.deleteCharAt(result.length() - 1 ).append("\n" );
ResultSetMetaInfo: 为了缓存 ResultSet 指针的元数据信息,避免 在while 循环中 反复get 调用导致 的效率降低。
import lombok.SneakyThrows;
import lombok.AllArgsConstructor;
import lombok.NoArgsConstructor;
import org.springframework.jdbc.support.JdbcUtils;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
public class ResultSetMetaInfo {
private int [] columnTypes;
private String[] columnNames;
public ResultSetMetaInfo (ResultSet rs) {
ResultSetMetaData rsmd = rs.getMetaData();
this .columnCount = rsmd.getColumnCount();
this .columnTypes = new int [columnCount];
this .columnNames = new String [columnCount];
for (int i = 0 ; i < columnCount; i++) {
columnTypes[i] = rsmd.getColumnType(i + 1 );
columnNames[i] = JdbcUtils.lookupColumnName(rsmd, i + 1 );
mysql ,请注意 ,官网MySQL :: MySQL Connector/J 8.0 Developer Guide :: 6.4 JDBC API Implementation Notes
进行如下设置 ,共有1种可用设置,推荐第2种设置 fetchSize =100 。
如果按照设置1 ,那么 resultset 每次取回的就是 1行 数据;单条取回,速度肯定较慢
stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY,
java.sql.ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(Integer.MIN_VALUE);
如果按照设置2 ,那么 resultset 每次取回的就是 fetchsize的那几行 数据;比第1种肯定快很多,推荐
conn = DriverManager.getConnection("jdbc:mysql://localhost/?useCursorFetch=true" , "user" , "s3cr3t" );
stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT * FROM your_table_here" );
此时,虽然避免了 由于mysql数据库 本身的 resultset 过大而导致的 oom ,但是,依然需要按照本文一开始的代码那样,不要一次性生成百万或者千万java对象,而是要及时将内存落地为写磁盘,避免超大java对象成的 oom 。
JdbcTemplate-API大全参考
SpringBoot高级篇JdbcTemplate之数据查询上篇 讲了如何使用JdbcTemplate进行简单的查询操作,主要介绍了三种方法的调用姿势 queryForMap, queryForList, queryForObject 本篇则继续介绍剩下的两种方法使用说明
I. 环境准备
环境依然借助前面一篇的配置,链接如: 190407-SpringBoot高级篇JdbcTemplate之数据插入使用姿势详解
或者直接查看项目源码: https://github.com/liuyueyi/spring-boot-demo/blob/master/spring-boot/101-jdbctemplate
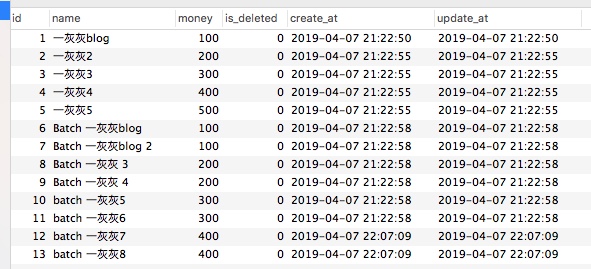
我们查询所用数据,正是前面一篇插入的结果,如下图
data
II. 查询使用说明
1. queryForRowSet
查询上篇中介绍的三种方法,返回的记录对应的结构要么是map,要么是通过RowMapper进行结果封装;而queryForRowSet方法的调用,返回的则是SqlRowSet对象,这是一个集合,也就是说,可以查询多条记录
使用姿势也比较简单,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public void queryForRowSet() {
String sql = "select * from money where id > 1 limit 2";
SqlRowSet result = jdbcTemplate.queryForRowSet(sql);
while (result.next()) {
MoneyPO moneyPO = new MoneyPO();
moneyPO.setId(result.getInt("id"));
moneyPO.setName(result.getString("name"));
moneyPO.setMoney(result.getInt("money"));
moneyPO.setDeleted(result.getBoolean("is_deleted"));
moneyPO.setCreated(result.getDate("create_at").getTime());
moneyPO.setUpdated(result.getDate("update_at").getTime());
System.out.println("QueryForRowSet by DirectSql: " + moneyPO);
}
}
对于使用姿势而言与之前的区别不大,还有一种就是sql也支持使用占位方式,如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 采用占位符方式查询
sql = "select * from money where id > ? limit ?";
result = jdbcTemplate.queryForRowSet(sql, 1, 2);
while (result.next()) {
MoneyPO moneyPO = new MoneyPO();
moneyPO.setId(result.getInt("id"));
moneyPO.setName(result.getString("name"));
moneyPO.setMoney(result.getInt("money"));
moneyPO.setDeleted(result.getBoolean("is_deleted"));
moneyPO.setCreated(result.getDate("create_at").getTime());
moneyPO.setUpdated(result.getDate("update_at").getTime());
System.out.println("QueryForRowSet by ? sql: " + moneyPO);
}
重点关注下结果的处理,需要通过迭代器的方式进行数据遍历,获取每一列记录的值的方式和前面一样,可以通过序号的方式获取(序号从1开始),也可以通过制定列名方式(db列名)
2. query
对于query方法的使用,从不同的结果处理方式来看,划分了四种,下面逐一说明
a. 回调方式 queryByCallBack
这种回调方式,query方法不返回结果,但是需要传入一个回调对象,查询到结果之后,会自动调用
1
2
3
4
5
6
7
8
9
10
11
private void queryByCallBack() {
String sql = "select * from money where id > 1 limit 2";
// 这个是回调方式,不返回结果;一条记录回调一次
jdbcTemplate.query(sql, new RowCallbackHandler() {
@Override
public void processRow(ResultSet rs) throws SQLException {
MoneyPO moneyPO = result2po(rs);
System.out.println("queryByCallBack: " + moneyPO);
}
});
}
上面的实例代码中,可以看到回调方法中传入一个ResultSet对象,简单封装一个转换为PO的方法
1
2
3
4
5
6
7
8
9
10
private MoneyPO result2po(ResultSet result) throws SQLException {
MoneyPO moneyPO = new MoneyPO();
moneyPO.setId(result.getInt("id"));
moneyPO.setName(result.getString("name"));
moneyPO.setMoney(result.getInt("money"));
moneyPO.setDeleted(result.getBoolean("is_deleted"));
moneyPO.setCreated(result.getDate("create_at").getTime());
moneyPO.setUpdated(result.getDate("update_at").getTime());
return moneyPO;
}
在后面的测试中,会看到上面会输出两行数据,也就是说
返回结果中每一条记录都执行一次上面的回调方法,即返回n条数据,上面回调执行n次
前面回调方式主要针对的是不关系返回结果,这里的则是将返回的结果,封装成我们预期的对象,然后返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
private void queryByResultSet() {
String sql = "select * from money where id > 1 limit 2";
// extractData 接收的是批量的结果,因此可以理解为一次对所有的结果进行转换,可以和 RowMapper 方式进行对比
List<MoneyPO> result = jdbcTemplate.query(sql, new ResultSetExtractor<List<MoneyPO>>() {
@Override
public List<MoneyPO> extractData(ResultSet rs) throws SQLException, DataAccessException {
List<MoneyPO> list = new ArrayList<>();
while (rs.next()) {
list.add(result2po(rs));
}
return list;
}
});
System.out.println("queryByResultSet: " + result);
}
额外注意下上面你的使用,如果返回的是多条数据,注意泛型参数类型为List<?>, 简单来说这是一个对结果进行批量转换的使用场景
因此在上面的extractData方法调用时,传入的是多条数据,需要自己进行迭代遍历,而不能像第一种那样使用
c. 结果单行处理 RowMapper
既然前面有批量处理,那当然也就有单行的转换方式了,如下
1
2
3
4
5
6
7
8
9
10
11
private void queryByRowMapper() {
String sql = "select * from money where id > 1 limit 2";
// 如果返回的是多条数据,会逐一的调用 mapRow方法,因此可以理解为单个记录的转换
List<MoneyPO> result = jdbcTemplate.query(sql, new RowMapper<MoneyPO>() {
@Override
public MoneyPO mapRow(ResultSet rs, int rowNum) throws SQLException {
return result2po(rs);
}
});
System.out.println("queryByRowMapper: " + result);
}
在实际使用中,只需要记住RowMapper方式传入的是单条记录,n次调用;而ResultSetExtractor方式传入的全部的记录,1次调用
d. 占位sql
前面介绍的几种都是直接写sql,这当然不是推荐的写法,更常见的是占位sql,通过传参替换,这类的使用前一篇博文介绍得比较多了,这里给出一个简单的演示
1
2
3
4
5
6
7
8
9
10
11
private void queryByPlaceHolder() {
String sql = "select * from money where id > ? limit ?";
// 占位方式,在最后面加上实际的sql参数,第二个参数也可以换成 ResultSetExtractor
List<MoneyPO> result = jdbcTemplate.query(sql, new RowMapper<MoneyPO>() {
@Override
public MoneyPO mapRow(ResultSet rs, int rowNum) throws SQLException {
return result2po(rs);
}
}, 1, 2);
System.out.println("queryByPlaceHolder: " + result);
}
e. PreparedStatement 方式
在插入记录的时候,PreparedStatement这个我们用得很多,特别是在要求返回主键id时,离不开它了, 在实际的查询中,也是可以这么用的,特别是在使用PreparedStatementCreator,我们可以设置查询的db连接参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private void queryByPreparedStatement() {
// 使用 PreparedStatementCreator查询,主要是可以设置连接相关参数, 如设置为只读
List<MoneyPO> result = jdbcTemplate.query(new PreparedStatementCreator() {
@Override
public PreparedStatement createPreparedStatement(Connection con) throws SQLException {
con.setReadOnly(true);
PreparedStatement statement = con.prepareStatement("select * from money where id > ? limit ?");
// 表示 id > 1
statement.setInt(1, 1);
// 表示 limit 2
statement.setInt(2, 2);
return statement;
}
}, new RowMapper<MoneyPO>() {
@Override
public MoneyPO mapRow(ResultSet rs, int rowNum) throws SQLException {
return result2po(rs);
}
});
System.out.println("queryByPreparedStatement: " + result);
}
上面是一个典型的使用case,当然在实际使用JdbcTemplate时,基本不这么玩
f. 查不到数据场景
前面一篇查询中,在单个查询中如果没有结果命中sql,会抛出异常,那么这里呢?
1
2
3
4
5
6
7
8
9
10
11
12
private void queryNoRecord() {
// 没有命中的情况下,会怎样
List<MoneyPO> result = jdbcTemplate
.query("select * from money where id > ? limit ?", new Object[]{100, 2}, new RowMapper<MoneyPO>() {
@Override
public MoneyPO mapRow(ResultSet rs, int rowNum) throws SQLException {
return result2po(rs);
}
});
System.out.println("queryNoRecord: " + result);
}
从后面的输出结果会看出,没有记录命中时,并没有什么关系,上面会返回一个空集合
III. 测试&小结
1. 测试
接下来测试下上面的输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
package com.git.hui.boot.jdbc;
import com.git.hui.boot.jdbc.insert.InsertService;
import com.git.hui.boot.jdbc.query.QueryService;
import com.git.hui.boot.jdbc.query.QueryServiceV2;
import com.git.hui.boot.jdbc.update.UpdateService;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* Created by @author yihui in 11:04 19/4/4.
*/
@SpringBootApplication
public class Application {
private QueryServiceV2 queryServiceV2;
public Application(QueryServiceV2 queryServiceV2) {
this.queryServiceV2 = queryServiceV2;
queryTest2();
}
public void queryTest2() {
// 第三个调用
queryServiceV2.queryForRowSet();
queryServiceV2.query();
}
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
上面执行输出结果如下
test output
2. 小结
本文主要介绍了另外两种查询姿势, queryForRowSet 与 query
queryForRowSet
返回SqlRowSet对象,需要遍历获取所有的结果
query
提供三种结果处理方式
不返回结果的回调姿势
对结果批量处理的方式 ResultSetExtractor
对结果单个迭代处理方式 RowMapper
可以返回>=0条数据
如果需要对查询的连接参数进行设置,使用PreparedStatementCreator来创建PreparedStatement方式处理
IV. 其他
相关博文
0. 项目
前面一篇介绍如何使用JdbcTemplate实现插入数据,接下来进入实际业务中,最常见的查询篇。由于查询的姿势实在太多,对内容进行了拆分,本篇主要介绍几个基本的使用姿势
queryForMap
queryForList
queryForObject
I. 环境准备
环境依然借助前面一篇的配置,链接如: 190407-SpringBoot高级篇JdbcTemplate之数据插入使用姿势详解
或者直接查看项目源码: https://github.com/liuyueyi/spring-boot-demo/blob/master/spring-boot/101-jdbctemplate
我们查询所用数据,正是前面一篇插入的结果,如下图
db mysql
II. 查询使用说明
queryForMap,一般用于查询单条数据,然后将db中查询的字段,填充到map中,key为列名,value为值
a. 基本使用姿势
最基本的使用姿势,就是直接写完整的sql,执行
1
2
3
String sql = "select * from money where id=1";
Map<String, Object> map = jdbcTemplate.queryForMap(sql);
System.out.println("QueryForMap by direct sql ans: " + map);
这种用法的好处是简单,直观;但是有个非常致命的缺点,如果你提供了一个接口为
1
2
3
4
public Map<String, Object> query(String condition) {
String sql = "select * from money where name=" + condition;
return jdbcTemplate.queryForMap(sql);
}
直接看上面代码,会发现问题么???
有经验的小伙伴,可能一下子就发现了sql注入的问题,如果传入的参数是 '一灰灰blog' or 1=1 order by id desc limit 1, 这样输出和我们预期的一致么?
b. 占位符替换
正是因为直接拼sql,可能到只sql注入的问题,所以更推荐的写法是通过占位符 + 传参的方式
1
2
3
4
5
6
7
8
9
// 使用占位符替换方式查询
sql = "select * from money where id=?";
map = jdbcTemplate.queryForMap(sql, new Object[]{1});
System.out.println("QueryForMap by ? ans: " + map);
// 指定传参类型, 通过传参来填充sql中的占位
sql = "select * from money where id =?";
map = jdbcTemplate.queryForMap(sql, 1);
System.out.println("QueryForMap by ? ans: " + map);
从上面的例子中也可以看出,占位符的使用很简单,用问好(?)来代替具体的取值,然后传参
传参有两种姿势,一个是传入Object[]数组;另外一个是借助java的不定长参数方式进行传参;两个的占位替换都是根据顺序来的,也就是如果你有一个值想替换多个占位符,那就得血多次
如:
1
2
sql = "select * from money where (name=? and id=?) or (name=? and id=?)";
map = jdbcTemplate.queryForMap(sql, "一灰灰blog", 1, "一灰灰blog", 2);
c. 查不到的case
使用queryForMap有个不得不注意的事项,就是如果查不到数据时,会抛一个异常出来,所以需要针对这种场景进行额外处理
1
2
3
4
5
6
7
8
// 查不到数据的情况
try {
sql = "select * from money where id =?";
map = jdbcTemplate.queryForMap(sql, 100);
System.out.println("QueryForMap by ? ans: " + map);
} catch (EmptyResultDataAccessException e) {
e.printStackTrace();
}
查询不到异常
2. queryForList
前面针对的主要是单个查询,如果有多个查询的场景,可能就需要用到queryForList了,它的使用姿势和上面其实差别不大;
a. 基本使用姿势
最基本的使用姿势当然是直接写sql执行了
1
2
3
4
5
6
7
System.out.println("============ query for List! ==============");
String sql =
"select id, `name`, money, is_deleted as isDeleted, unix_timestamp(create_at) as created, unix_timestamp(update_at) as updated from money limit 3;";
// 默认返回 List<Map<String, Object>> 类型数据,如果一条数据都没有,则返回一个空的集合
List<Map<String, Object>> res = jdbcTemplate.queryForList(sql);
System.out.println("basicQueryForList: " + res);
注意返回的结果是List<Map<String, Object>>, 如果一条都没有命中,会返回一个空集合, 和 QueryForMap 抛异常是不一样的
b. 占位符替换
直接使用sql的查询方式,依然和前面一样,可能有注入问题,当然优先推荐的使用通过占位来传参方式
1
2
3
4
String sql2 = "select id, `name`, money, is_deleted as isDeleted, unix_timestamp(create_at) as created, " +
"unix_timestamp(update_at) as updated from money where id=? or name=?;";
res = jdbcTemplate.queryForList(sql2, 2, "一灰灰2");
System.out.println("queryForList by template: " + res);
3. queryForObject
如果是简单查询,直接用上面两个也就够了,但是对于使用过mybatis,Hibernate的同学来说,每次返回Map<String, Object>,就真的有点蛋疼了, 对于mysql这种数据库,表的结构基本不变,完全可以和POJO进行关联,对于业务开发者而言,当然是操作具体的POJO比Map要简单直观多了
下面将介绍下,如何使用 queryForObject 来达到我们的目标
a. 原始使用姿势
首先介绍下利用 RowMapper 来演示下,最原始的使用姿势
第一步是定义对应的POJO类
1
2
3
4
5
6
7
8
9
10
@Data
public static class MoneyPO implements Serializable {
private static final long serialVersionUID = -5423883314375017670L;
private Integer id;
private String name;
private Integer money;
private boolean isDeleted;
private Long created;
private Long updated;
}
然后就是使用姿势
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// sql + 指定返回类型方式访问
// 使用这种sql的有点就是方便使用反射方式,实现PO的赋值
String sql =
"select id, `name`, money, is_deleted as isDeleted, unix_timestamp(create_at) as created, unix_timestamp(update_at) as updated from money limit 1;";
// 需要注意,下标以1开始
MoneyPO moneyPO = jdbcTemplate.queryForObject(sql, new RowMapper<MoneyPO>() {
@Override
public MoneyPO mapRow(ResultSet rs, int rowNum) throws SQLException {
MoneyPO po = new MoneyPO();
po.setId(rs.getInt(1));
po.setName(rs.getString(2));
po.setMoney(rs.getInt(3));
po.setDeleted(rs.getBoolean(4));
po.setCreated(rs.getLong(5));
po.setUpdated(rs.getLong(6));
return po;
}
});
System.out.println("queryFroObject by RowMapper: " + moneyPO);
从使用姿势上看,RowMapper 就是一个sql执行之后的回调,实现结果封装,这里需要注意的就是 ResultSet 封装了完整的返回结果,可以通过下标方式指定,下标是从1开始,而不是我们常见的0,需要额外注意
这个下标从1开始,感觉有点蛋疼,总容易记错,所以更推荐的方法是直接通过列名获取数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 直接使用columnName来获取对应的值,这里就可以考虑使用反射方式来赋值,减少getter/setter
moneyPO = jdbcTemplate.queryForObject(sql, new RowMapper<MoneyPO>() {
@Override
public MoneyPO mapRow(ResultSet rs, int rowNum) throws SQLException {
MoneyPO po = new MoneyPO();
po.setId(rs.getInt("id"));
po.setName(rs.getString("name"));
po.setMoney(rs.getInt("money"));
po.setDeleted(rs.getBoolean("isDeleted"));
po.setCreated(rs.getLong("created"));
po.setUpdated(rs.getLong("updated"));
return po;
}
});
System.out.println("queryFroObject by RowMapper: " + moneyPO);
b. 高级使用
当sql返回的列名和POJO的属性名可以完全匹配上的话,上面的这种写法就显得非常冗余和麻烦了,我需要更优雅简洁的使用姿势,最好就是直接传入POJO类型,自动实现转换
如果希望得到这个效果,你需要的就是下面这个了: BeanPropertyRowMapper
1
2
3
// 更简单的方式,直接通过BeanPropertyRowMapper来实现属性的赋值,前提是sql返回的列名能正确匹配
moneyPO = jdbcTemplate.queryForObject(sql, new BeanPropertyRowMapper<>(MoneyPO.class));
System.out.println("queryForObject by BeanPropertyRowMapper: " + moneyPO);
c. 易错使用姿势
查看JdbcTemplate提供的接口时,可以看到下面这个接口
1
2
3
4
@Override
public <T> T queryForObject(String sql, Class<T> requiredType, @Nullable Object... args) throws DataAccessException {
return queryForObject(sql, args, getSingleColumnRowMapper(requiredType));
}
自然而然的想到,直接传入POJO的类型进去,是不是就可以得到我们预期的结果了?
1
2
3
4
5
6
7
8
String sql =
"select id, `name`, money, is_deleted as isDeleted, unix_timestamp(create_at) as created, unix_timestamp(update_at) as updated from money limit 1;";
try {
MoneyPO po = jdbcTemplate.queryForObject(sql, MoneyPO.class);
System.out.println("queryForObject by requireType return: " + po);
} catch (Exception e) {
e.printStackTrace();
}
执行上面的代码,抛出异常
从上面的源码也可以看到,上面的使用姿势,适用于sql只返回一列数据的场景,即下面的case
1
2
3
4
5
// 下面开始测试下 org.springframework.jdbc.core.JdbcTemplate.queryForObject(java.lang.String, java.lang.Class<T>, java.lang.Object...)
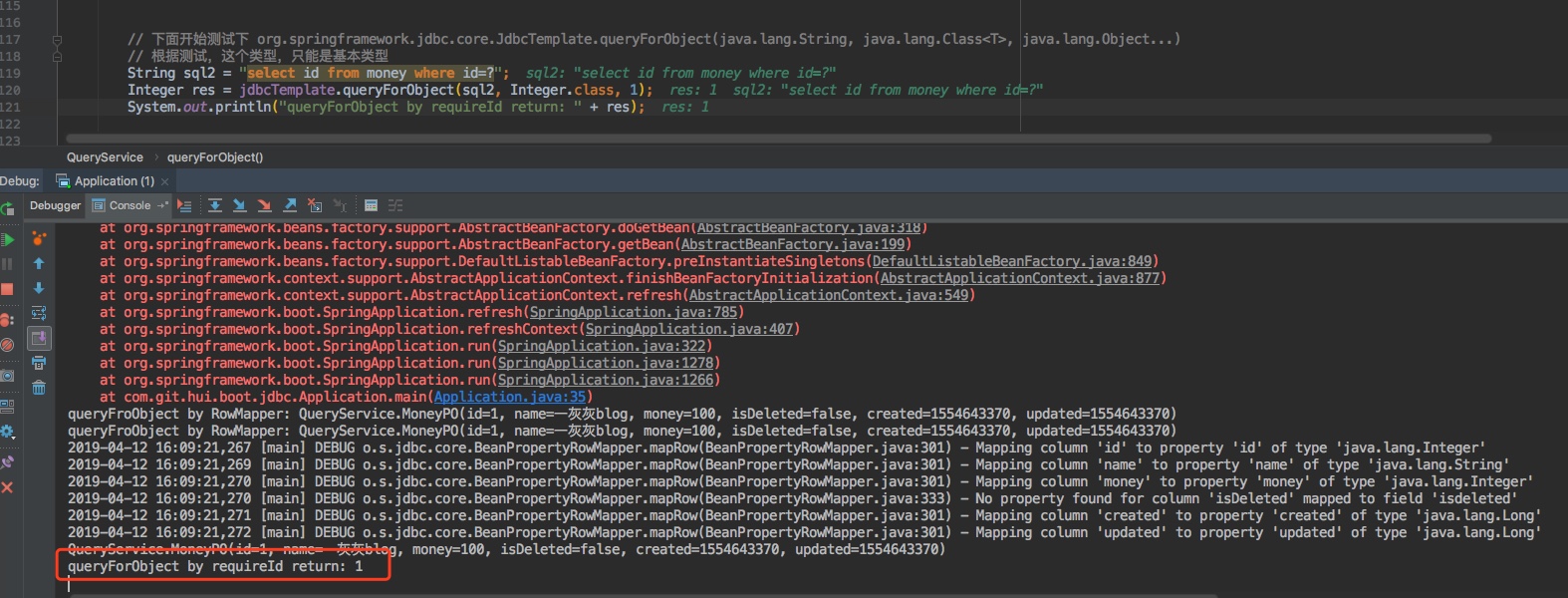
// 根据测试,这个类型,只能是基本类型
String sql2 = "select id from money where id=?";
Integer res = jdbcTemplate.queryForObject(sql2, Integer.class, 1);
System.out.println("queryForObject by requireId return: " + res);
show
4. 测试
上面所有代码可以查看: https://github.com/liuyueyi/spring-boot-demo/blob/master/spring-boot/101-jdbctemplate/src/main/java/com/git/hui/boot/jdbc/query/QueryService.java
简单的继承调用下上面的所有方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@SpringBootApplication
public class Application {
private QueryService queryService;
public Application(QueryService queryService) {
this.queryService = queryService;
queryTest();
}
public void queryTest() {
queryService.queryForMap();
queryService.queryForObject();
queryService.queryForList();
}
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
输出结果如下
result
III. 小结
本篇博文主要介绍了JdbcTemplate查询的简单使用姿势,主要是queryForMap, queryForList, queryForObject三种方法的调用
1. 根据返回结果数量
单条记录查询
queryForMap : 返回一条记录,返回的结果塞入Map<String, Object>, key为固定的String对应查询的列名;value为实际值queryForObject :同样返回一条数据,与上面的区别在于可以借助RowMapper来实现返回结果转换为对应的POJO
需要注意的是,上面的查询,必须有一条记录返回,如果查不到,则抛异常
批量查询
queryForList :一次查询>=0条数据,返回类型为 List<Map<String, Object>>
2. 根据sql类型
有两种sql传参方式
一个是写完整的sql语句,就和我们普通的sql查询一样;问题是存在注入的风险
其次是使用占位符(?), 实际的值通过参数方式传入
IV. 其他
0. 项目
【DB系列】JdbcTemplate之数据更新与删除
前面介绍了JdbcTemplate的插入数据和查询数据,占用CURD中的两项,本文则将主要介绍数据更新和删除。从基本使用上来看,姿势和前面的没啥两样
I. 环境准备
环境依然借助前面一篇的配置,链接如: 190407-SpringBoot高级篇JdbcTemplate之数据插入使用姿势详解
或者直接查看项目源码: https://github.com/liuyueyi/spring-boot-demo/blob/master/spring-boot/101-jdbctemplate
我们查询所用数据,正是前面一篇插入的结果,如下图
data
II. 更新使用说明
对于数据更新,这里会分为两种进行说明,单个和批量;这个单个并不是指只能一条记录,主要针对的是sql的数量而言
1. update 方式
看过第一篇数据插入的童鞋,应该也能发现,新增数据也是用的这个方法,下面会介绍三种不同的使用姿势
先提供一个数据查询的转换方法,用于对比数据更新前后的结果
1
2
3
4
5
6
private MoneyPO queryById(int id) {
return jdbcTemplate.queryForObject(
"select id, `name`, money, is_deleted as isDeleted, unix_timestamp(create_at) as " +
"created, unix_timestamp(update_at) as updated from money where id=?",
new BeanPropertyRowMapper<>(MoneyPO.class), id);
}
a. 纯sql更新
这个属于最基本的方式了,前面几篇博文中大量使用了,传入一条完整的sql,执行即可
1
2
3
4
5
6
int id = 10;
// 最基本的sql更新
String sql = "update money set money=money + 999 where id =" + id;
int ans = jdbcTemplate.update(sql);
System.out.println("basic update: " + ans + " | db: " + queryById(id));
b. 占位sql
问好占位,实际内容通过参数传递方式
1
2
3
4
// 占位方式
sql = "update money set money=money + ? where id = ?";
ans = jdbcTemplate.update(sql, 888, id);
System.out.println("placeholder update: " + ans + " | db: " + queryById(id));
c. statement
从前面的几篇文章中可以看出,使用statement的方式,最大的好处有几点
可以点对点的设置填充参数
PreparedStatementCreator 方式可以获取db连接,主动设置各种参数
下面给出两个常见的使用方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// 通过 PreparedStatementCreator 方式更新
ans = jdbcTemplate.update(new PreparedStatementCreator() {
@Override
public PreparedStatement createPreparedStatement(Connection connection) throws SQLException {
// 设置自动提交,设置100ms的超时,这种方式最大的好处是可以控制db连接的参数
try {
connection.setAutoCommit(true);
connection.setNetworkTimeout(Executors.newSingleThreadExecutor(), 10);
PreparedStatement statement =
connection.prepareStatement("update money set money=money + ? where id " + "= ?");
statement.setInt(1, 777);
statement.setInt(2, id);
return statement;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
});
System.out.println("statementCreator update: " + ans + " | db: " + queryById(id));
// 通过 PreparedStatementSetter 来设置占位参数值
ans = jdbcTemplate.update(sql, new PreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement) throws SQLException {
preparedStatement.setInt(1, 666);
preparedStatement.setInt(2, id);
}
});
System.out.println("statementSetter update: " + ans + " | db: " + queryById(id));
注意下第一种调用中,设置了超时时间,下面给出一个动图,演示超时的使用姿势
show
在上图中,
首先是一个开启一个事物,并修改了一条记录,这个时候这条记录会加上写锁
然后JdbcTemplate中修改上面的这条记录,尝试加写锁,但是会失败,所以一直阻塞,当超时之后,抛出异常
2. batchUpdate 方式
批量方式,执行多个sql,从使用上看和前面没有太大的区别,先给出一个查询的通用方法
1
2
3
4
5
6
7
8
9
private List<MoneyPO> queryByIds(List<Integer> ids) {
StringBuilder strIds = new StringBuilder();
for (Integer id : ids) {
strIds.append(id).append(",");
}
return jdbcTemplate.query("select id, `name`, money, is_deleted as isDeleted, unix_timestamp(create_at) as " +
"created, unix_timestamp(update_at) as updated from money where id in (" +
strIds.substring(0, strIds.length() - 1) + ")", new BeanPropertyRowMapper<>(MoneyPO.class));
}
a. 纯sql更新
1
2
3
4
5
6
// 批量修改,
// 执行多条sql的场景
int[] ans = jdbcTemplate
.batchUpdate("update money set money=1300 where id =10", "update money set money=1300 where id = 11");
System.out.println(
"batch update by sql ans: " + Arrays.asList(ans) + " | db: " + queryByIds(Arrays.asList(10, 11)));
b. 占位sql
1
2
3
4
5
// 占位替换方式
ans = jdbcTemplate.batchUpdate("update money set money=money + ? where id = ?",
Arrays.asList(new Object[]{99, 10}, new Object[]{99, 11}));
System.out.println("batch update by placeHolder ans: " + Arrays.asList(ans) + " | db: " +
queryByIds(Arrays.asList(10, 11)));
c. statement
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// 通过 statement
ans = jdbcTemplate
.batchUpdate("update money set money=money + ? where id = ?", new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException {
preparedStatement.setInt(1, 99);
preparedStatement.setInt(2, i + 10);
}
@Override
public int getBatchSize() {
return 2;
}
});
System.out.println(
"batch update by statement ans: " + Arrays.asList(ans) + " | db: " + queryByIds(Arrays.asList(10, 11)));
注意下上面的方法中,getBatchSize返回实际的sql条数,setValues中的i从0开始
3. 测试
原始数据中,money都是300,通过一系列的修改,输出如下
test result
III. 数据删除
删除的操作姿势和上面基本一样,也就是sql的写法不同罢了,因此没有太大的必要重新写一篇,下面给出一个简单的demo
1
2
3
4
5
6
7
8
9
10
@Component
public class DeleteService {
@Autowired
private JdbcTemplate jdbcTemplate;
public void delete() {
int ans = jdbcTemplate.update("delete from money where id = 13");
System.out.println("delete: " + ans);
}
}
IV. 其他
相关博文
0. 项目
【DB系列】JdbcTemplate之数据插入使用姿势详解
db操作可以说是java后端的必备技能了,实际项目中,直接使用JdbcTemplate的机会并不多,大多是mybatis,hibernate,jpa或者是jooq,然后前几天写一个项目,因为db操作非常简单,就直接使用JdbcTemplate,然而悲催的发现,对他的操作并没有预期中的那么顺畅,所以有必要好好的学一下JdbcTemplate的CURD;本文为第一篇,插入数据
I. 环境
1. 配置相关
使用SpringBoot进行db操作引入几个依赖,就可以愉快的玩耍了,这里的db使用mysql,对应的pom依赖如
1
2
3
4
5
6
7
8
9
10
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
</dependencies>
接着就是db的配置信息,下面是连接我本机的数据库配置
1
2
3
4
5
## DataSource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/story?useUnicode=true&characterEncoding=UTF-8&useSSL=false
spring.datasource.driver-class-name= com.mysql.jdbc.Driver
spring.datasource.username=root
spring.datasource.password=
2. 测试db
创建一个测试db
1
2
3
4
5
6
7
8
9
10
CREATE TABLE `money` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL DEFAULT '' COMMENT '用户名',
`money` int(26) NOT NULL DEFAULT '0' COMMENT '钱',
`is_deleted` tinyint(1) NOT NULL DEFAULT '0',
`create_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
II. 使用姿势
直接引入jdbcTemplate,注入即可,不需要其他的操作
1
2
@Autowired
private JdbcTemplate jdbcTemplate;
1. sql直接插入一条数据
直接写完整的插入sql,这种方式比较简单粗暴
1
2
3
4
5
private boolean insertBySql() {
// 简单的sql执行
String sql = "INSERT INTO `money` (`name`, `money`, `is_deleted`) VALUES ('一灰灰blog', 100, 0);";
return jdbcTemplate.update(sql) > 0;
}
2. 参数替换方式插入
这种插入方式中,sql使用占位符?,然后插入值通过参数传入即可
1
2
3
4
private boolean insertBySqlParams() {
String sql = "INSERT INTO `money` (`name`, `money`, `is_deleted`) VALUES (?, ?, ?);";
return jdbcTemplate.update(sql, "一灰灰2", 200, 0) > 0;
}
3. 通过Statement方式插入
通过Statement可以指定参数类型,这种插入方式更加安全,有两种常见的方式,注意设置参数时,起始值为1,而不是通常说的0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
private boolean insertByStatement() {
String sql = "INSERT INTO `money` (`name`, `money`, `is_deleted`) VALUES (?, ?, ?);";
return jdbcTemplate.update(sql, new PreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement) throws SQLException {
preparedStatement.setString(1, "一灰灰3");
preparedStatement.setInt(2, 300);
byte b = 0;
preparedStatement.setByte(3, b);
}
}) > 0;
}
private boolean insertByStatement2() {
String sql = "INSERT INTO `money` (`name`, `money`, `is_deleted`) VALUES (?, ?, ?);";
return jdbcTemplate.update(new PreparedStatementCreator() {
@Override
public PreparedStatement createPreparedStatement(Connection connection) throws SQLException {
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1, "一灰灰4");
preparedStatement.setInt(2, 400);
byte b = 0;
preparedStatement.setByte(3, b);
return preparedStatement;
}
}) > 0;
}
4. 插入并返回主键id
这个属于比较常见的需求了,我希望获取插入数据的主键id,用于后续的业务使用; 这时就需要用KeyHolder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
/**
* 新增数据,并返回主键id
*
* @return
*/
private int insertAndReturnId() {
String sql = "INSERT INTO `money` (`name`, `money`, `is_deleted`) VALUES (?, ?, ?);";
KeyHolder keyHolder = new GeneratedKeyHolder();
jdbcTemplate.update(new PreparedStatementCreator() {
@Override
public PreparedStatement createPreparedStatement(Connection connection) throws SQLException {
// 指定主键
PreparedStatement preparedStatement = connection.prepareStatement(sql, new String[]{"id"});
preparedStatement.setString(1, "一灰灰5");
preparedStatement.setInt(2, 500);
byte b = 0;
preparedStatement.setByte(3, b);
return preparedStatement;
}
}, keyHolder);
return keyHolder.getKey().intValue();
}
看上面的实现,和前面差不多,但是有一行需要额外注意, 在获取Statement时,需要制定主键,否则会报错
1
2
// 指定主键
PreparedStatement preparedStatement = connection.prepareStatement(sql, new String[]{"id"});
5. 批量插入
基本插入看完之后,再看批量插入,会发现和前面的姿势没有太大的区别,无非是传入一个数组罢了,如下面的几种使用姿势
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
private void batchInsertBySql() {
String sql = "INSERT INTO `money` (`name`, `money`, `is_deleted`) VALUES " +
"('Batch 一灰灰blog', 100, 0), ('Batch 一灰灰blog 2', 100, 0);";
int[] ans = jdbcTemplate.batchUpdate(sql);
System.out.println("batch insert by sql: " + JSON.toJSONString(ans));
}
private void batchInsertByParams() {
String sql = "INSERT INTO `money` (`name`, `money`, `is_deleted`) VALUES (?, ?, ?);";
Object[] param1 = new Object[]{"Batch 一灰灰 3", 200, 0};
Object[] param2 = new Object[]{"Batch 一灰灰 4", 200, 0};
int[] ans = jdbcTemplate.batchUpdate(sql, Arrays.asList(param1, param2));
System.out.println("batch insert by params: " + JSON.toJSONString(ans));
}
private void batchInsertByStatement() {
String sql = "INSERT INTO `money` (`name`, `money`, `is_deleted`) VALUES (?, ?, ?);";
int[] ans = jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException {
if (i == 0) {
preparedStatement.setString(1, "batch 一灰灰5");
} else {
preparedStatement.setString(1, "batch 一灰灰6");
}
preparedStatement.setInt(2, 300);
byte b = 0;
preparedStatement.setByte(3, b);
}
@Override
public int getBatchSize() {
return 2;
}
});
System.out.println("batch insert by statement: " + JSON.toJSONString(ans));
}
6. 测试
接下来我们测试下上面的代码执行情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
@Component
public class InsertService {
/**
* 简单的新增一条数据
*/
public void basicInsert() {
System.out.println("basic insert: " + insertBySql());
System.out.println("insertBySqlParams: " + insertBySqlParams());
System.out.println("insertByStatement: " + insertByStatement());
System.out.println("insertByStatement2: " + insertByStatement2());
System.out.println("insertAndReturn: " + insertAndReturnId());
List<Map<String, Object>> result = jdbcTemplate.queryForList("select * from money");
System.out.println("after insert, the records:\n" + result);
}
/**
* 批量插入数据
*/
public void batchInsert() {
batchInsertBySql();
batchInsertByParams();
batchInsertByStatement();
}
}
@SpringBootApplication
public class Application {
public Application(InsertService insertService) {
insertService.basicInsert();
insertService.batchInsert();
}
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
输出结果如
1
2
3
4
5
6
7
8
9
10
basic insert: true
insertBySqlParams: true
insertByStatement: true
insertByStatement2: true
insertAndReturn: 5
after insert, the records:
[{id=1, name=一灰灰blog, money=100, is_deleted=false, create_at=2019-04-08 10:22:50.0, update_at=2019-04-08 10:22:50.0}, {id=2, name=一灰灰2, money=200, is_deleted=false, create_at=2019-04-08 10:22:55.0, update_at=2019-04-08 10:22:55.0}, {id=3, name=一灰灰3, money=300, is_deleted=false, create_at=2019-04-08 10:22:55.0, update_at=2019-04-08 10:22:55.0}, {id=4, name=一灰灰4, money=400, is_deleted=false, create_at=2019-04-08 10:22:55.0, update_at=2019-04-08 10:22:55.0}, {id=5, name=一灰灰5, money=500, is_deleted=false, create_at=2019-04-08 10:22:55.0, update_at=2019-04-08 10:22:55.0}]
batch insert by sql: [2]
batch insert by params: [1,1]
batch insert by statement: [1,1]
执行结果
II. 扩展
1. 批量插入并返回主键id
上面还漏了一个批量插入时,也需要返回主键id,改怎么办?
直接看JdbcTemplate的接口,并没有发现类似单个插入获取主键的方式,是不是意味着没法实现呢?
当然不是了,既然没有提供,我们完全可以依葫芦画瓢,自己实现一个 ExtendJdbcTemplate, 首先看先单个插入返回id的实现如
源码
接下来,我们自己的实现可以如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
public class ExtendJdbcTemplate extends JdbcTemplate {
public ExtendJdbcTemplate(DataSource dataSource) {
super(dataSource);
}
public int[] batchUpdate(final String sql, final BatchPreparedStatementSetter pss,
final KeyHolder generatedKeyHolder) throws DataAccessException {
return execute(new PreparedStatementCreator() {
@Override
public PreparedStatement createPreparedStatement(Connection conn) throws SQLException {
return conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
}
}, ps -> {
try {
int batchSize = pss.getBatchSize();
int totalRowsAffected = 0;
int[] rowsAffected = new int[batchSize];
List generatedKeys = generatedKeyHolder.getKeyList();
generatedKeys.clear();
ResultSet keys = null;
for (int i = 0; i < batchSize; i++) {
pss.setValues(ps, i);
rowsAffected[i] = ps.executeUpdate();
totalRowsAffected += rowsAffected[i];
try {
keys = ps.getGeneratedKeys();
if (keys != null) {
RowMapper rowMapper = new ColumnMapRowMapper();
RowMapperResultSetExtractor rse = new RowMapperResultSetExtractor(rowMapper, 1);
generatedKeys.addAll(rse.extractData(keys));
}
} finally {
JdbcUtils.closeResultSet(keys);
}
}
if (logger.isDebugEnabled()) {
logger.debug("SQL batch update affected " + totalRowsAffected + " rows and returned " +
generatedKeys.size() + " keys");
}
return rowsAffected;
} finally {
if (pss instanceof ParameterDisposer) {
((ParameterDisposer) pss).cleanupParameters();
}
}
});
}
}
封装完毕之后,我们的使用姿势可以为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
@Autowired
private ExtendJdbcTemplate extendJdbcTemplate;
private void batchInsertAndReturnId() {
String sql = "INSERT INTO `money` (`name`, `money`, `is_deleted`) VALUES (?, ?, ?);";
GeneratedKeyHolder generatedKeyHolder = new GeneratedKeyHolder();
extendJdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException {
if (i == 0) {
preparedStatement.setString(1, "batch 一灰灰7");
} else {
preparedStatement.setString(1, "batch 一灰灰8");
}
preparedStatement.setInt(2, 400);
byte b = 0;
preparedStatement.setByte(3, b);
}
@Override
public int getBatchSize() {
return 2;
}
}, generatedKeyHolder);
System.out.println("batch insert and return id ");
List<Map<String, Object>> objectMap = generatedKeyHolder.getKeyList();
for (Map<String, Object> map : objectMap) {
System.out.println(map.get("GENERATED_KEY"));
}
}
然后测试执行,输出结果如下
批量插入返回id
2. 小结
本篇主要介绍使用JdbcTemplate插入数据的几种常用姿势,分别从单个插入和批量插入进行了实例演示,包括以下几种常见姿势
update(sql)update(sql, param1, param2...)update(sql, new PreparedStatementCreator(){})update(new PreparedStatementSetter(){})update(new PreparedStatementCreator(){}, new GeneratedKeyHolder())
批量插入姿势和上面差不多,唯一需要注意的是,如果你想使用批量插入,并获取主键id,目前我没有找到可以直接使用的接口,如果有这方面的需求,可以参考下我上面的使用姿势
IV. 其他
0. 项目

 data
data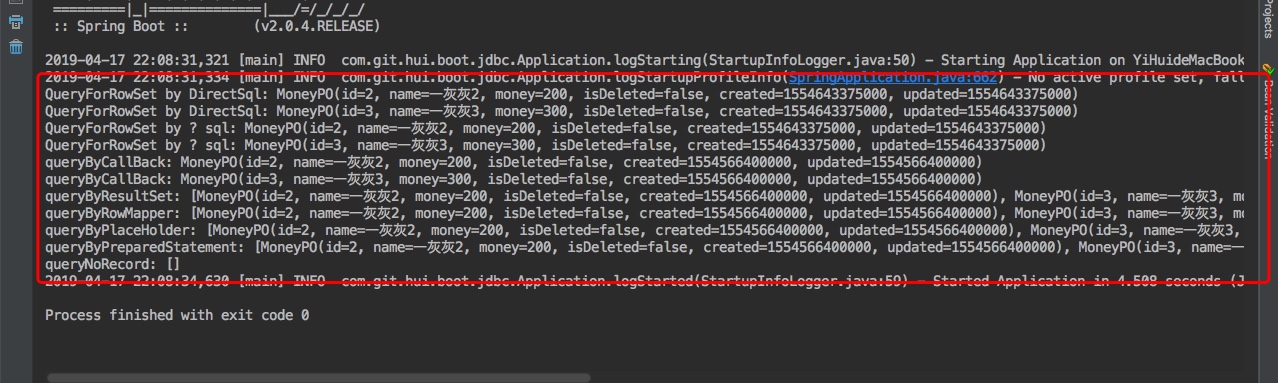 test output
test output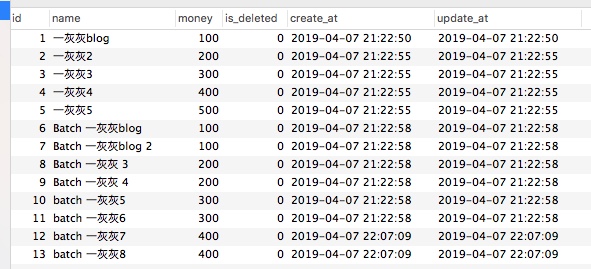 db mysql
db mysql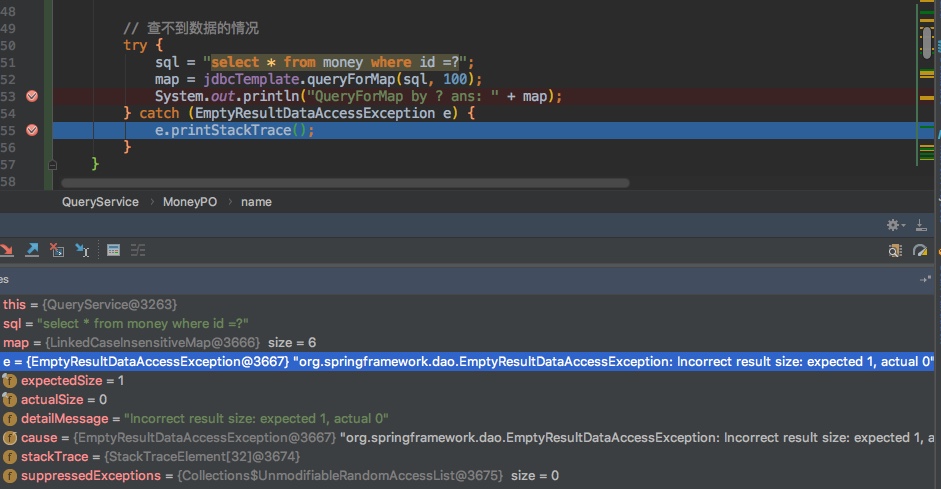 查询不到异常
查询不到异常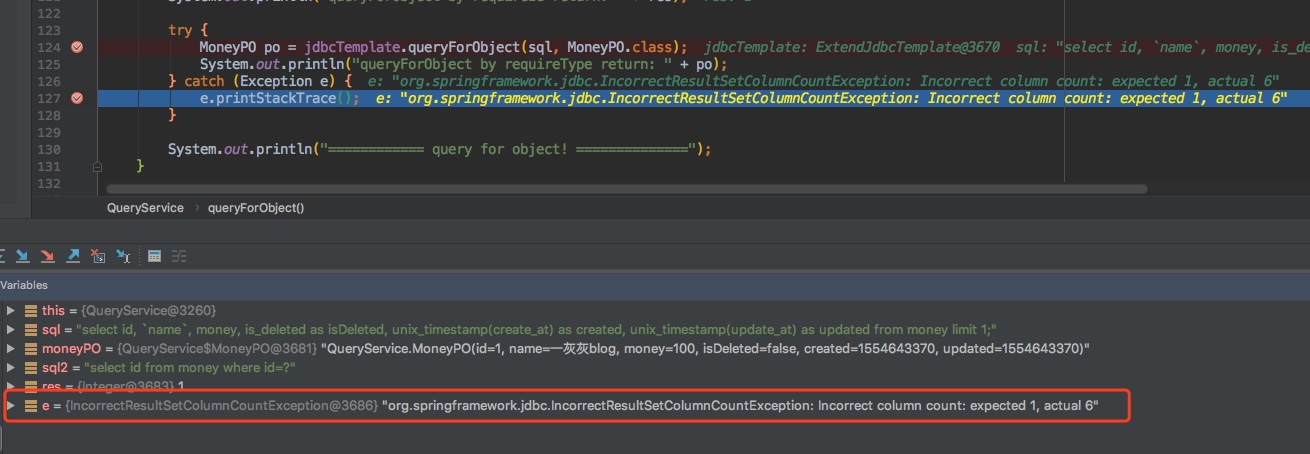
 show
show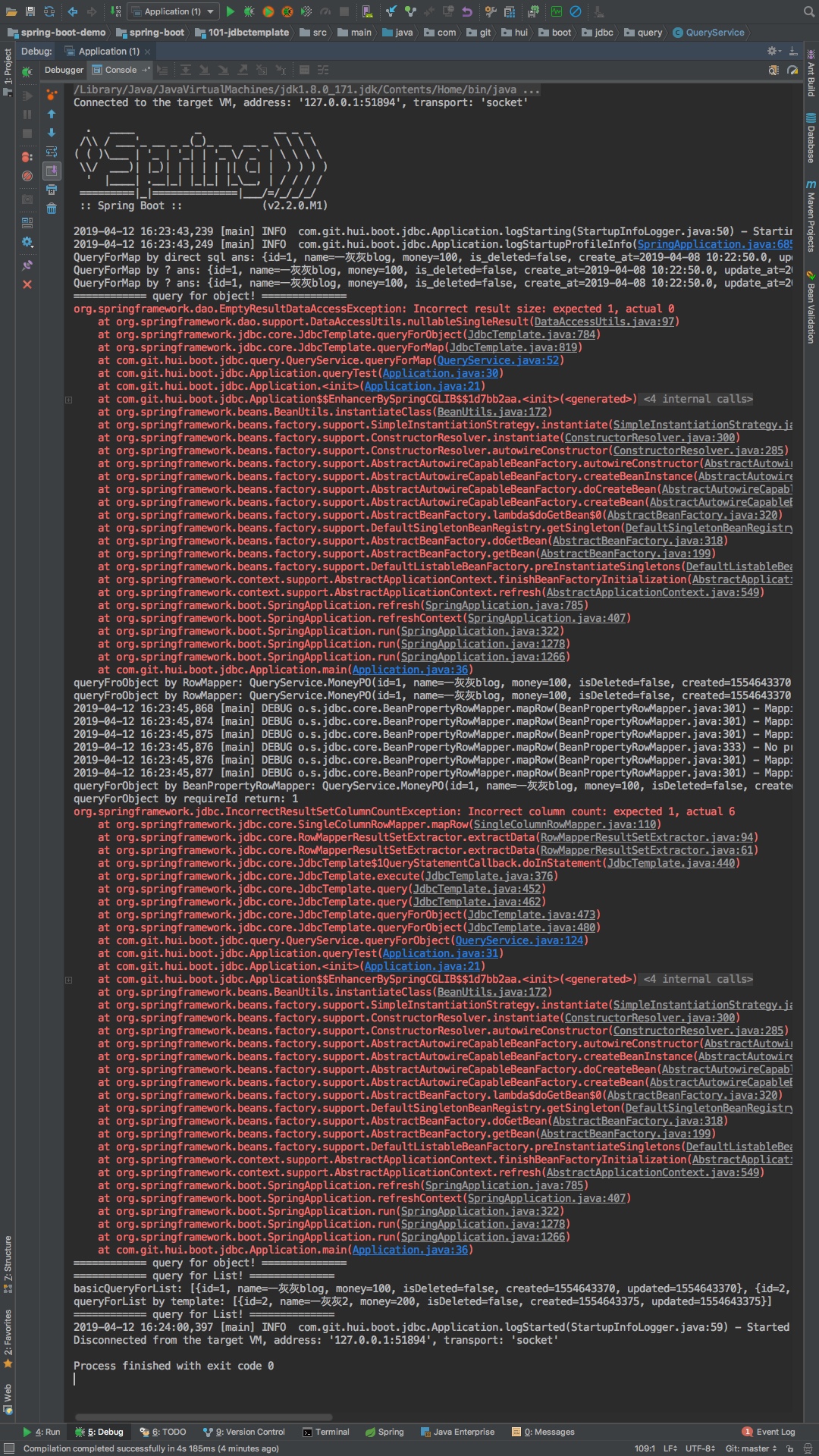 result
result data
data show
show test result
test result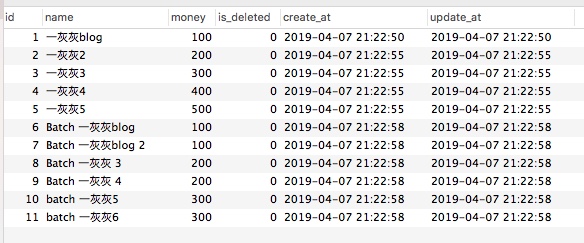 执行结果
执行结果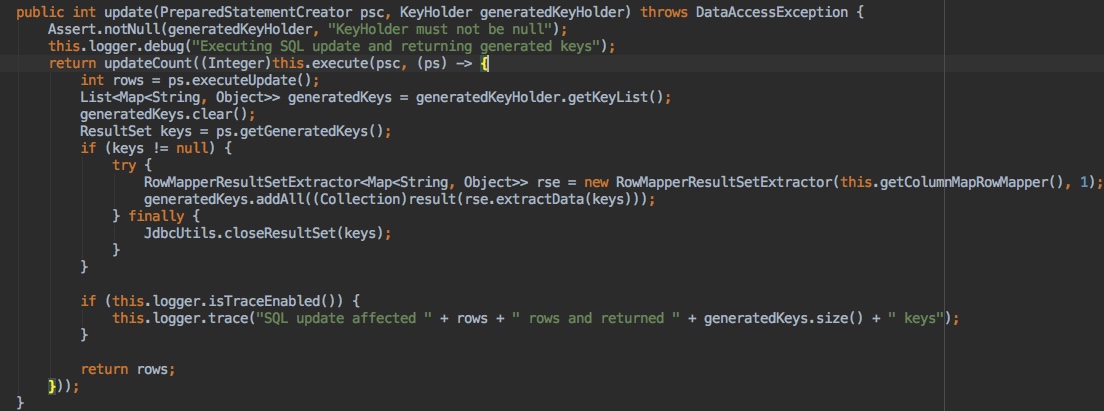 源码
源码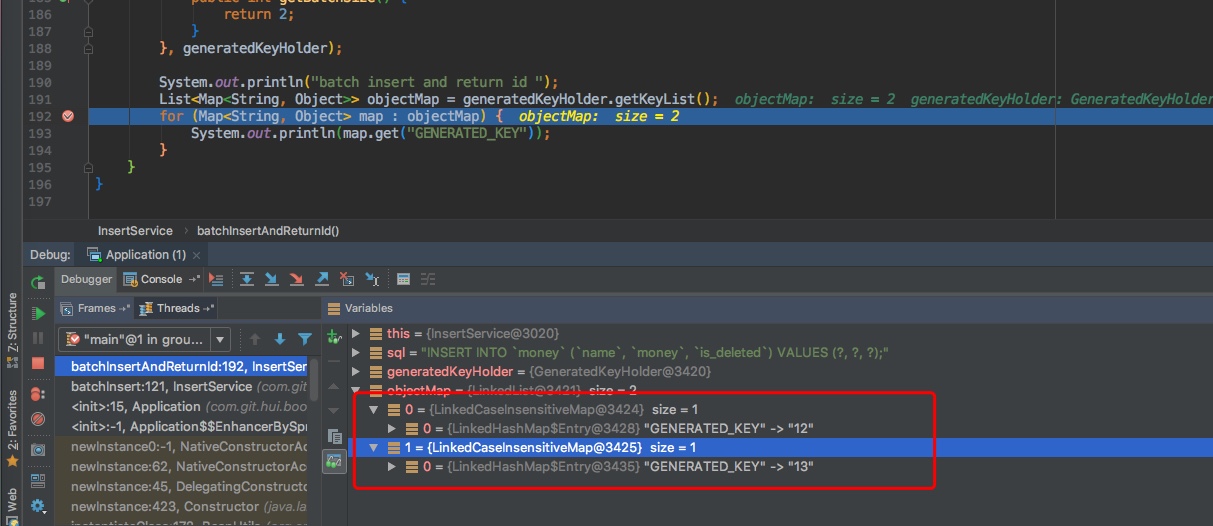 批量插入返回id
批量插入返回id
 浙公网安备 33010602011771号
浙公网安备 33010602011771号