log4j2最佳实践
最佳实践
使用 Log4j API 时存在一些普遍存在的不良做法。下面我们将介绍最常见的问题并了解如何解决它们。有关完整列表,请参阅Log4j API 最佳实践页面。
不要使用toString()
-
不要在参数中使用
Object#toString(),它是多余的!/* BAD! */ LOGGER.info("userId: {}", userId.toString()); -
底层消息类型和布局将处理参数:
/* GOOD */ LOGGER.info("userId: {}", userId);
将异常作为最后一个额外参数传递
-
不要调用
Throwable#printStackTrace()!这不仅可以规避日志记录,还可能泄露敏感信息!/* BAD! */ exception.printStackTrace(); -
不要使用
Throwable#getMessage()!这可以防止日志事件因异常而变得丰富。/* BAD! */ LOGGER.info("failed", exception.getMessage()); /* BAD! */ LOGGER.info("failed for user ID `{}`: {}", userId, exception.getMessage()); -
不要同时提供
Throwable#getMessage()和Throwable本身!这会导致日志消息因重复的异常消息而变得臃肿。/* BAD! */ LOGGER.info("failed for user ID `{}`: {}", userId, exception.getMessage(), exception); -
将异常作为最后一个额外参数传递:
/* GOOD */ LOGGER.error("failed", exception); /* GOOD */ LOGGER.error("failed for user ID `{}`", userId, exception);
不要使用字符串连接
如果您在记录时使用String连接,那么您正在做一些非常错误和危险的事情!
-
不要使用
String连接来格式化参数!这避免了按消息类型和布局处理参数。更重要的是,这种方式很容易受到攻击! 想象一下用户提供的userId包含以下内容:placeholders for non-existing args to trigger failure: {} {} {dangerousLookup}/* BAD! */ LOGGER.info("failed for user ID: " + userId); -
/* GOOD */ LOGGER.info("failed for user ID `{}`", userId);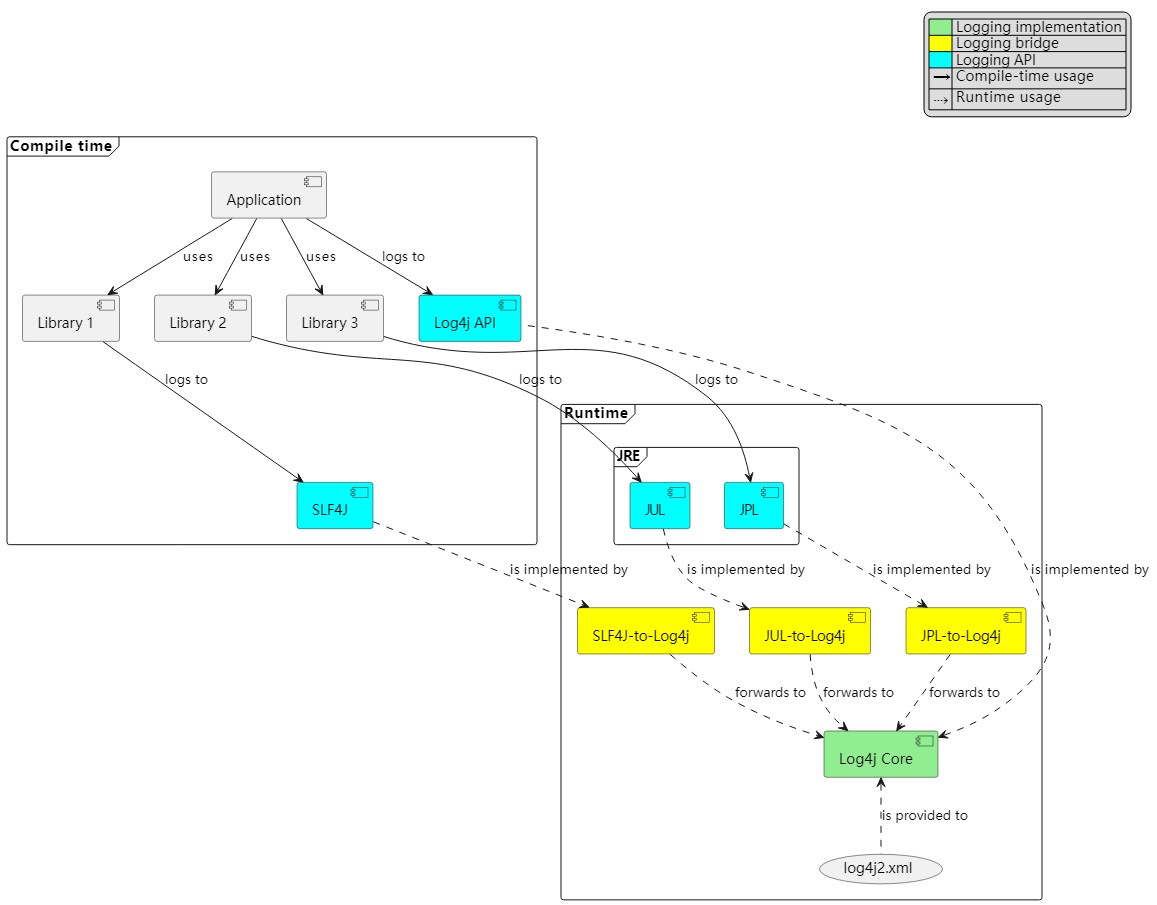
最佳实践
使用 Log4j API 时存在一些普遍存在的不良做法。让我们尝试了解最常见的问题并看看如何解决它们。
不要使用
toString()-
不要在参数中使用
Object#toString(),它是多余的!/* BAD! */ LOGGER.info("userId: {}", userId.toString()); -
底层消息类型和布局将处理参数:
/* GOOD */ LOGGER.info("userId: {}", userId);
将异常作为最后一个额外参数传递
-
不要调用
Throwable#printStackTrace()!这不仅可以规避日志记录,还可能泄露敏感信息!/* BAD! */ exception.printStackTrace(); -
不要使用
Throwable#getMessage()!这可以防止日志事件因异常而变得丰富。/* BAD! */ LOGGER.info("failed", exception.getMessage()); /* BAD! */ LOGGER.info("failed for user ID `{}`: {}", userId, exception.getMessage()); -
不要同时提供
Throwable#getMessage()和Throwable本身!这会导致日志消息因重复的异常消息而变得臃肿。/* BAD! */ LOGGER.info("failed for user ID `{}`: {}", userId, exception.getMessage(), exception); -
将异常作为最后一个额外参数传递:
/* GOOD */ LOGGER.error("failed", exception); /* GOOD */ LOGGER.error("failed for user ID `{}`", userId, exception);
不要使用字符串连接
如果您在记录时使用
String连接,那么您正在做一些非常错误和危险的事情!-
不要使用
String连接来格式化参数!这避免了按消息类型和布局处理参数。更重要的是,这种方式很容易受到攻击! 想象一下用户提供的userId包含以下内容:placeholders for non-existing args to trigger failure: {} {} {dangerousLookup}/* BAD! */ LOGGER.info("failed for user ID: " + userId); -
使用消息参数
/* GOOD */ LOGGER.info("failed for user ID `{}`", userId);
使用
Supplier传递计算成本较高的参数如果日志语句的一个或多个参数在计算上是昂贵的,那么在知道它们的结果可以被丢弃的情况下评估它们是不明智的。考虑以下示例:
/* BAD! */ LOGGER.info("failed for user ID `{}` and role `{}`", userId, db.findUserRoleById(userId));如果创建的日志事件无论如何都会被丢弃,那么数据库查询(即
db.findUserNameById(userId))可能会成为一个严重的瓶颈 - 也许该记录器不接受INFO级别,或者由于某些其他过滤。-
解决这个问题的传统方法是对日志语句进行级别保护:
/* OKAY */ if (LOGGER.isInfoEnabled()) { LOGGER.info(...); }虽然这适用于由于级别不足而可能丢弃消息的情况,但此方法仍然容易出现其他过滤情况;例如,关联的标记可能不被接受。
-
使用
Supplier传递包含计算上昂贵的项目的参数:/* GOOD */ LOGGER.info("failed for user ID `{}` and role `{}`", () -> userId, () -> db.findUserRoleById(userId)); -
使用
Supplier传递包含计算上昂贵的项目的消息及其参数:/* GOOD */ LOGGER.info(() -> new ParameterizedMessage("failed for user ID `{}` and role `{}`", userId, db.findUserRoleById(userId)));
线程上下文
就像Java 的
ThreadLocal一样,线程上下文有助于将信息与执行线程关联起来,并使日志系统的其余部分可以访问该信息。线程上下文同时提供了这两种功能-
映射结构 – 称为线程上下文映射或映射诊断上下文 (MDC)
-
堆栈结构 - 称为线程上下文堆栈或嵌套诊断上下文 (NDC)
贮存:
ThreadContext.put("ipAddress", request.getRemoteAddr()); ThreadContext.put("hostName", request.getServerName()); ThreadContext.put("loginId", session.getAttribute("loginId")); void performWork() { ThreadContext.push("performWork()"); LOGGER.debug("Performing work"); // Perform the work ThreadContext.pop(); } ThreadContext.clear();向线程上下文映射添加属性 将属性推送到线程上下文堆栈 添加的属性稍后可用于过滤日志事件、在布局中提供额外信息等。 从线程上下文堆栈中弹出最后推送的属性 清除线程上下文(对于堆栈和映射!) Configuration properties级别
日志级别用于按严重性对日志事件进行分类并控制日志的详细程度。它们是Log4j API 提供的众多鱼类标记功能之一。使用级别,您可以过滤掉不太重要的日志并专注于最关键的日志。
Log4j 包含以下预定义级别:
表 1. 标准日志级别 姓名 优先事项 0100200300400500600Integer.MAX_VALUEOFF和ALL级别很特殊:它们不应该用于钓鱼标记日志事件。Log4j API 实现(例如 Log4j Core)可以在其配置文件中使用
OFF来禁用所有日志语句,并使用ALL来启用所有日志语句。级别由区分大小写的名称和优先级(类型为
int)组成,用于定义比较两者时的顺序。优先级可以在多种情况下使用来表达过滤能力,例如:-
WARN严重程度低于ERROR -
WARN不如ERROR具体
日志级别的入口点是通过
Level。 Log4j API 集成商可以通过StandardLevel获得预定义级别。创建标记
简单的标记
要创建
Marker,请使用MarkerManager.getMarker()方法在类中创建一个字段:private static final Marker SQL_MARKER = MarkerManager.getMarker("SQL");由于
Marker可以跨多个日志语句重用,因此将其存储在static final字段中使其成为常量。创建后,将其用作日志语句中的第一个参数:LOGGER.debug(SQL_MARKER, "SELECT * FROM {}", table);如果您使用下面的配置示例,可以在控制台上看到以下日志语句:
10:42:30.982 (SQL) SELECT * FROM my_table家长和孩子标记
一个标记可以有零个或多个父标记,从而允许标记的层次结构。要创建这样的层次结构,您必须在创建子标记后对
Marker对象使用addParents()方法。private static final Marker QUERY_MARKER = MarkerManager.getMarker("SQL_QUERY").addParents(SQL_MARKER); private static final Marker UPDATE_MARKER = MarkerManager.getMarker("UPDATE").addParents(SQL_MARKER);子标记与简单标记没有区别;必须将它们作为日志记录调用的第一个参数传递。
LOGGER.debug(QUERY_MARKER, "SELECT * FROM {}", table); LOGGER.debug(UPDATE_MARKER, "UPDATE {} SET {} = {}", table, column, value);用子标记标记的消息的行为就像同时用子标记及其所有父标记标记一样。如果您使用下面的配置示例,您将在控制台上看到以下日志语句:
10:42:30.982 (SQL_QUERY[ SQL ]) SELECT * FROM my_table 10:42:30.982 (SQL_UPDATE[ SQL ]) UPDATE my_table SET column = value线程上下文
一样 Java的
ThreadLocal, 线程上下文有助于将信息与执行线程关联起来,并使日志系统的其余部分可以访问该信息。线程上下文是Log4j API 提供的众多鱼类标记功能之一。用法
将日志记录相关信息与执行线程关联起来的入口点是
ThreadContext。它同时提供-
映射结构 – 称为线程上下文映射或映射诊断上下文 (MDC) Thread Context Map or Mapped Diagnostic Context map-structured
-
堆栈结构 - 称为线程上下文堆栈或嵌套诊断上下文 (NDC) Thread Context Stack or Nested Diagnostic Context stack-structured
贮存:
ThreadContext.put("ipAddress", request.getRemoteAddr()); ThreadContext.put("hostName", request.getServerName()); ThreadContext.put("loginId", session.getAttribute("loginId")); void performWork() { ThreadContext.push("performWork()"); LOGGER.debug("Performing work"); // Perform the work ThreadContext.pop(); } ThreadContext.clear();向线程上下文映射添加属性 将属性推送到线程上下文堆栈 添加的属性稍后可用于过滤日志事件、在布局中提供额外信息等。 从线程上下文堆栈中弹出最后推送的属性 清除线程上下文(对于堆栈和映射!) 自动清除线程上下文
当将项目放置在线程上下文堆栈或映射上时,有必要在适当的时候再次删除它们。 为了帮助做到这一点,您可以使用
CloseableThreadContext(实施AutoCloseable)在 try-with-resources 块中:try (CloseableThreadContext.Instance ignored = CloseableThreadContext .put("ipAddress", request.getRemoteAddr()) .push("performWork()")) { LOGGER.debug("Performing work"); // Perform the work } // ...进行线程上下文更改,该更改仅在 try-with-resources 块的范围内可见 添加的属性稍后可用于过滤日志事件、在布局中提供额外信息等。 在 try-with-resources 块的范围之外,线程上下文的更改将不可见 初始化线程上下文
一个常见的用例是通过线程池将单线程执行扇出到多个线程。在这种情况下,您需要将当前线程的上下文克隆到池中的上下文。为此,您可以使用
ThreadContext和CloseableThreadContext提供的putAll()和pushAll()方法:LOGGER.debug("Starting background thread for user"); Map<String, String> mdc = ThreadContext.getImmutableContext(); List<String> ndc = ThreadContext.getImmutableStack().asList(); executor.submit(() -> { try (CloseableThreadContext.Instance ignored = CloseableThreadContext .putAll(mdc) .pushAll(ndc)) { LOGGER.debug("Processing for user started"); // ... } });获取线程上下文的快照 初始化后台任务的线程上下文 自定义线程上下文数据提供者
ContextDataProvider是一个接口应用程序和库,可用于将其他属性注入到日志事件的上下文数据中。 Log4j 使用java.util.ServiceLoader来定位和加载ContextDataProvider实例。ThreadContextDataProvider是提供的默认实现。您可以提供自定义ContextDataProvider实现,如下所示:-
在类路径中创建以下文件:
META-INF/services/org.apache.logging.log4j.core.util.ContextDataProvider -
编写自定义实现的完全限定类名(例如,
com.mycompany.CustomContextDataProvider) 到上一步中创建的文件
自定义线程上下文映射
可以通过将
log4j2.threadContextMap系统属性设置为扩展自的自定义实现类的完全限定类名来提供自定义线程上下文映射实现ThreadContextMap。在提供自定义线程上下文映射实现时,建议您也从
ReadOnlyThreadContextMap也。 通过这种方式,应用程序可以通过以下方式访问您的自定义线程上下文映射实现ThreadContext.getThreadContextMap()。虽然 Log4j 在内部使用
Message对象,Logger接口提供了各种快捷方法来创建最常用的消息:-
要从
String参数创建SimpleMessage,以下记录器调用是等效的:LOGGER.error("Houston, we have a problem.", exception); LOGGER.error(new SimpleMessage("Houston, we have a problem."), exception); -
要从格式
String和对象参数数组创建ParameterizedMessage,以下记录器调用是等效的:LOGGER.error("Unable process user with ID `{}`", userId, exception); LOGGER.error(new ParameterizedMessage("Unable process user with ID `{}`", userId), exception);
在大多数情况下,这已经足够了。
除了满足基于
String的消息的用例之外,Message接口抽象还允许用户记录自定义对象。这在某些用例中有效地提供了日志记录的便利。例如,想象一个使用域事件来表示身份验证失败的场景:record LoginFailureEvent(String userName, InetSocketAddress remoteAddress) {}当开发人员想要记录报告事件的消息时,我们可以看到字符串构造变得更难以阅读:
LOGGER.info( "Connection closed by authenticating user {} {} port {} [preauth]", event.userName(), event.remoteAddress().getHostName(), event.remoteAddress().getPort());通过扩展
Message接口,开发人员可以简化登录失败的报告:record LoginFailureEvent(String userName, InetSocketAddress remoteAddress) implements Message { @Override public String getFormattedMessage() { return "Connection closed by authenticating user " + userName() + " " + remoteAddress().getHostName() + " port " + remoteAddress().getPort() + " [preauth]"; } // Other methods }领域模型需要实现 Message接口getFormattedMessage()提供要记录的String因此,
LoginFailureEvent实例的日志记录可以简化如下:LOGGER.info(event);LocalizedMessageLocalizedMessage合并了一个ResourceBundle,并允许消息模式参数成为包中消息模式的关键。如果未指定捆绑包,LocalizedMessage将尝试查找具有用于记录事件的Logger名称的捆绑包。从包中检索的消息将使用FormattedMessage进行格式化。LocalizedMessage主要是为了与Log4j 1兼容而提供的。我们建议您在应用程序的表示层(例如客户端 UI)执行日志消息本地化。MapMessageMapMessage是一个Message实现,它使用String类型的键和值对 JavaMap进行建模。 它是传递结构化数据的理想通用消息类型。MapMessage实现了MultiformatMessage以便于以多种格式对其内容进行编码。它支持以下格式:格式 描述 XML格式为 XML
JSON格式为 JSON
JAVA格式为
Map#toString()(默认)JAVA_UNQUOTED格式为
Map#toString(),但不带引号当没有布局时,一些附加程序以不同的方式处理
MapMessage:-
JMS Appender 转换为 JMS
javax.jms.MapMessage -
JDBC Appender转换为
SQL INSERT语句中的值 -
MongoDB NoSQL 提供程序转换为 MongoDB 对象中的字段
JSON 模板布局
JSON 模板布局对
MapMessage进行了专门处理,以将它们正确编码为 JSON 对象。StructuredDataMessageStructuredDataMessage以符合RFC 5424 中描述的 Syslog 消息格式的方式格式化其内容。RFC 5424 布局
StructuredDataMessage主要与RFC 5424 Layout结合使用,后者对StructuredDataMessage进行了专门处理。通过将两者结合起来,用户可以完全控制如何以符合 RFC 5424 的方式对消息进行编码,而 RFC 5424 布局将确保正确注入附加到日志事件的其余信息。JSON 模板布局
由于
StructuredDataMessage扩展自MapMessage,而JSON 模板布局对其进行了专门处理,因此StructuredDataMessage也将由 JSON 模板布局正确编码。<turboFilter class="MarkerFilter"> <Marker>FLOW</Marker> <OnMatch>ACCEPT</OnMatch> </turboFilter> <appender name="CONSOLE_DEFAULT" class="ConsoleAppender"> <filter class="EvaluatorFilter"> <evaluator class="OnMarkerEvaluator"> <marker>ENTER</marker> <marker>EXIT</marker> </evaluator> <onMismatch>ACCEPT</onMismatch> <onMatch>DENY</onMatch> </filter> <encoder class="PatternLayoutEncoder"> <pattern><![CDATA[%d %5p [%t] %c{1} -- %m%n]]></pattern> </encoder> </appender> <appender name="CONSOLE_FLOW_ENTER" class="ConsoleAppender"> <filter class="EvaluatorFilter"> <evaluator class="OnMarkerEvaluator"> <marker>ENTER</marker> </evaluator> <onMismatch>DENY</onMismatch> <onMatch>ACCEPT</onMatch> </filter> <encoder class="PatternLayoutEncoder"> <pattern><![CDATA[%d %5p [%t] %c{1} => %m%n]]></pattern> </encoder> </appender> <appender name="CONSOLE_FLOW_EXIT" class="ConsoleAppender"> <filter class="EvaluatorFilter"> <evaluator class="OnMarkerEvaluator"> <marker>EXIT</marker> </evaluator> <onMismatch>DENY</onMismatch> <onMatch>ACCEPT</onMatch> </filter> <encoder class="PatternLayoutEncoder"> <pattern><![CDATA[%d %5p [%t] %c{1} <= %m%n]]></pattern> </encoder> </appender> <root level="WARN"> <appender-ref ref="CONSOLE_DEFAULT"/> <appender-ref ref="CONSOLE_FLOW_ENTER"/> <appender-ref ref="CONSOLE_FLOW_EXIT"/> </root>接受标有 FLOW日志事件,无论其级别如何在 CONSOLE_DEFAULT附加程序中,排除所有标有ENTER和EXIT日志事件在 CONSOLE_DEFAULT附加程序中,日志事件消息将使用-前缀进行格式化在 CONSOLE_FLOW_ENTER附加程序中,仅接受标有ENTER的日志事件在 CONSOLE_FLOW_ENTER附加程序中,日志事件消息将使用→前缀进行格式化在 CONSOLE_FLOW_EXIT附加程序中,仅接受标有EXIT的日志事件在 CONSOLE_FLOW_EXIT附加程序中,日志事件消息将使用←前缀进行格式化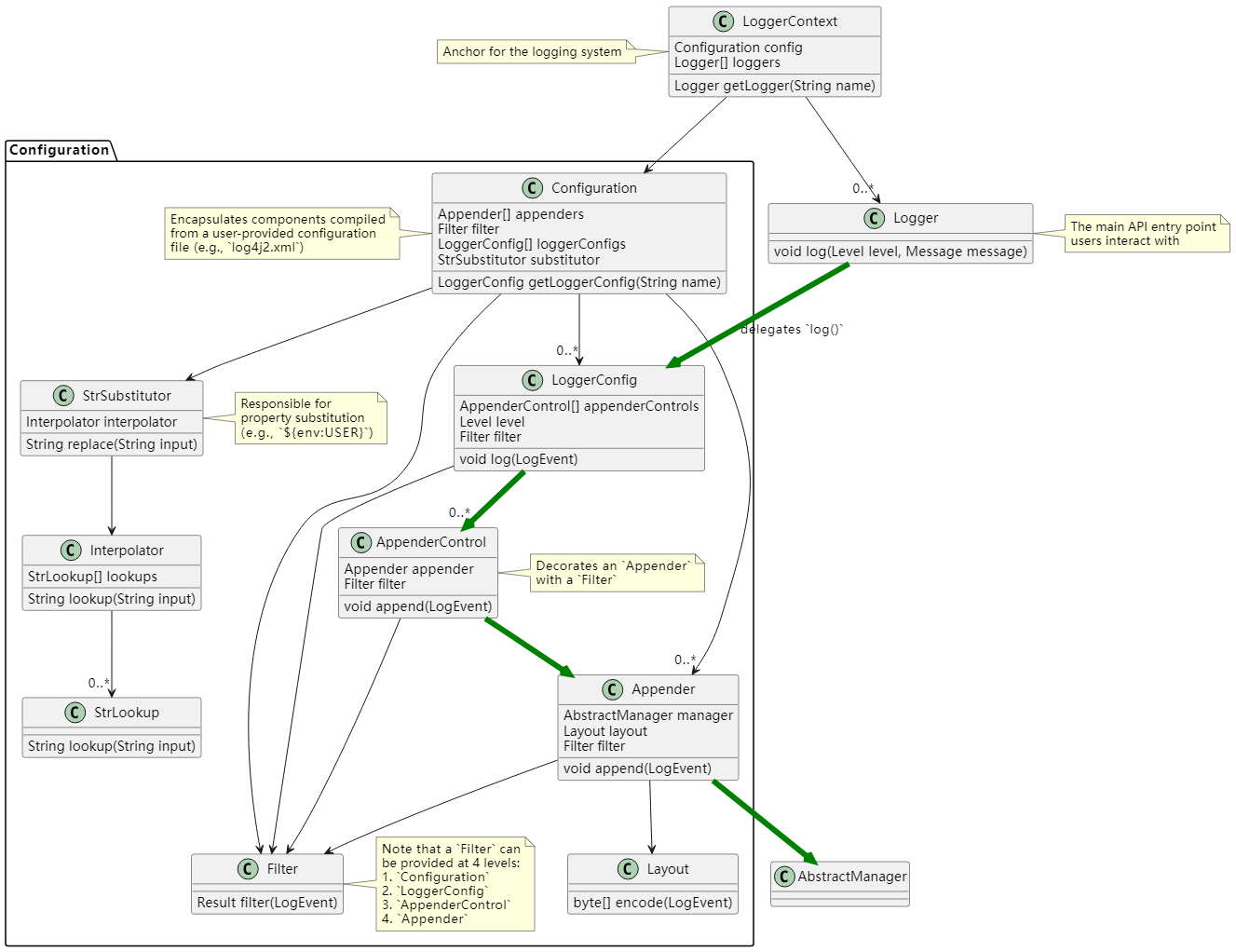
在一个非常高的水平上,
-
LoggerContext(组合锚点)与Configuration结合创建。两者都可以在第一次与 Log4j 交互时直接(即以编程方式)或间接创建。 -
LoggerContext创建用户出于日志记录目的与之交互的Logger。 -
Appender将LogEvent传递到目标(文件、套接字、数据库等),通常使用Layout来编码日志事件,并使用AbstractManager来处理目标资源的生命周期。 -
LoggerConfig封装了Logger的配置,就像Appender的AppenderControl和AppenderRef一样。 -
Configuration配备有StrSubstitutor等。允许String类型值中的属性替换。 -
典型的
log()调用会按顺序通过类Logger、LoggerConfig、AppenderControl、Appender和AbstractManager触发一系列调用 - 这在图 1中使用绿色箭头进行了描述。
以下部分详细研究了这种相互作用。
架构::Apache Log4j --- Architecture :: Apache Log4j
记录器层次结构
Log4j Core 具有
LoggerConfig的分层模型,因此也具有Logger分层模型。如果parent在名称上具有最长的前缀匹配,则称为child的LoggerConfig被认为是parent的父级。此匹配区分大小写,并在通过将名称从 中拆分来标记化名称后执行.(点)字符。对于正向名称匹配,标记必须彻底匹配。有关示例,请参见图 7 。 图 7. 名为
图 7. 名为X、XY、XYZ和X.YZ的记录器的示例层次结构如果
LoggerConfig未提供显式级别,它将从其父级继承。同样,如果用户以编程方式请求一个Logger,其名称没有直接对应的LoggerConfig配置条目及其名称,则将使用父级的LoggerConfig。有关日志级别以及在配置中将其用于过滤目的的更多信息,请参阅级别。
下面我们通过级别继承的方式演示
LoggerConfig层次结构。也就是说,我们将在各种LoggerConfig设置中检查Logger的有效级别。表1. 仅根记录器配置了级别,并且为 DEBUG记录器名称 分配的 LoggerConfig名称配置级别 有效水平 rootrootDEBUGDEBUGXrootDEBUGX.YrootDEBUGX.Y.ZrootDEBUG表 2. 所有记录器都配置有级别 记录器名称 分配的 LoggerConfig配置级别 有效水平 rootrootDEBUGDEBUGXXERRORERRORX.YX.YINFOINFOX.Y.ZX.Y.ZWARNWARN表 3. 除记录器 XY外,所有记录器均配置有级别记录器名称 分配的 LoggerConfig配置级别 有效水平 rootrootDEBUGDEBUGXXERRORERRORX.YXERRORX.Y.ZX.Y.ZWARNWARN表 4. 除记录器 XY和XYZ外,所有记录器均配置有级别记录器名称 分配的 LoggerConfig配置级别 有效水平 rootrootDEBUGDEBUGXXERRORERRORX.YXERRORX.Y.ZXERROR表 5. 除记录器 X.YZ外,所有记录器均配置有级别记录器名称 分配的 LoggerConfig配置级别 有效水平 rootrootDEBUGDEBUGXXERRORERRORX.YX.YINFOINFOX.YZXERROR配置文件位置
在初始化新的记录器上下文(日志记录实现的锚点)时,Log4j Core 会为其分配一个上下文名称,并按以下顺序扫描以下类路径位置以查找配置文件:
-
文件名为
log4j2-test<contextName>.<extension> -
名为
log4j2-test.<extension>的文件 -
文件名为
log4j2<contextName>.<extension> -
名为
log4j2.<extension>的文件
上面的
<contextName>和<extension>占位符具有以下含义- <上下文名称>
-
源自运行时环境的名称:
-
对于独立的 Java SE 应用程序,它是一个随机标识符。
-
对于 Web 应用程序,它是从应用程序描述符派生的标识符。有关详细信息,请参阅Log4j Web 应用程序配置。
-
- <扩展>
-
ConfigurationFactory支持的文件扩展名。首先搜索扩展的顺序取决于关联的ConfigurationFactory的顺序。有关详细信息,请参阅预定义的ConfigurationFactory插件。
如果未找到配置文件,Log4j Core 将使用
DefaultConfiguration,并且状态记录器会打印警告。默认配置将所有不如log4j2.level严重的消息打印到控制台。您可以使用
log4j2.configurationFile系统属性覆盖配置文件的位置。在这种情况下,Log4j Core 将从提供的文件名猜测配置文件格式,或者如果扩展名未知,则使用默认配置工厂。我们强烈建议您在 Log4j 配置中采用某些最佳实践:
-
以
log4j2-test为前缀的文件只能在测试类路径上使用。 -
如果您正在开发应用程序,请勿使用多个具有相同名称但扩展名不同的 Log4j 配置文件。也就是说,不要同时提供
log4j2.xml和log4j2.json文件。 -
如果您正在开发库,只需将配置文件添加到测试类路径中。
预定义的
ConfigurationFactory插件Log4j Core 使用从
ConfigurationFactory扩展的插件来确定支持哪些配置文件扩展、按什么顺序以及如何读取它们。扩展ConfigurationFactory插件中解释了它的内部工作原理以及如何引入自定义实现。表 1. 预定义 ConfigurationFactory插件支持的配置文件格式文件格式 扩大 order XML
xml5
JSON
json, jsn6
YAML
yaml, yml7
特性
properties8
请注意,
ConfigurationFactory插件将按降序使用。也就是说,例如,将最后检查 XML 文件格式,作为后备。-
log4j2.json:runtimeOnly 'com.fasterxml.jackson.core:jackson-databind:2.18.0'
- log4j2.yaml:runtimeOnly 'com.fasterxml.jackson.dataformat:jackson-dataformat-yaml:2.18.0'
示例log4j2.yaml的片段Configuration: Appenders: Console: name: "CONSOLE" PatternLayout: pattern: "%p - %m%n" File: - name: "MAIN" fileName: "logs/main.log" JsonTemplateLayout: {} - name: "DEBUG_LOG" fileName: "logs/debug.log" PatternLayout: pattern: "%d [%t] %p %c - %m%n" Loggers: Root: level: "INFO" AppenderRef: - ref: "CONSOLE" level: "WARN" - ref: "MAIN" Logger: name: "org.example" level: "DEBUG" AppenderRef: ref: "DEBUG_LOG"使用模式布局配置名为 CONSOLE控制台附加程序。使用 JSON 模板布局配置名为 MAIN的文件附加程序。使用模式布局配置名为 DEBUG_LOG的文件附加程序。在 INFO级别配置根记录器并将其连接到CONSOLE和MAIN附加程序。CONSOLE附加程序只会记录至少与WARN一样严重的消息。在 DEBUG级别配置名为"org.example"的记录器并将其连接到DEBUG_LOG附加程序。记录器配置为将消息转发到其父级(根附加器)。使用上述配置,用于每个日志事件的附加程序列表仅取决于事件的级别和记录器的名称,如下表所示:
记录器名称 记录事件级别 附加器 org.example.fooWARNCONSOLE、MAIN、DEBUG_LOGorg.example.fooDEBUGMAIN,DEBUG_LOGorg.example.fooTRACE没有任何
com.exampleWARNCONSOLEMAINcom.exampleINFOMAINcom.exampleDEBUG没有任何
全局配置属性
主要的
Configuration元素有一组属性,可用于调整配置文件的使用方式。下面列出了主要属性。请参阅插件参考以获取完整列表。monitorInterval类型
int默认值
0确定 Log4j 用于检查配置文件更改的轮询间隔。如果检测到配置文件发生更改,Log4j 会自动重新配置记录器上下文。如果设置为
0,则禁用轮询。Loggers
Log4j 2 包含多种类型的记录器配置,可以将其添加到配置的
Loggers元素中:Root-
是接收未定义更具体记录器的所有事件的记录器。
另请参阅插件参考。
AsyncRoot-
是在混合同步和异步模式下使用的根记录器的替代实现。
另请参阅插件参考。
Logger-
最常见的记录器类型,它从自身和所有子记录器收集日志事件,这些子记录器没有显式配置(请参阅记录器层次结构)。
另请参阅插件参考。
AsyncLogger-
相当于
Logger,用于同步异步混合模式。另请参阅插件参考。
每个配置文件中必须至少有一个
Root或AsyncRoot元素。其他记录器配置是可选的。additivity类型
boolean默认值
true适用于
Logger和AsyncLogger如果为
true(默认),则此记录器接收到的所有消息也将传输到其 父记录器)。level类型
默认值
-
log4j2.level,对于Root和AsyncRoot, -
继承自 父 logger ,用于
Logger和AsyncLogger。
它指定必须记录日志事件的级别阈值。比此设置严重程度低的日志事件将被过滤掉。
如果您需要额外的过滤,另请参阅过滤器。
includeLocation类型
boolean默认值
-
false,如果使用异步ContextSelector。 -
否则,
-
对于
Root和Logger来说true, -
对于
AsyncRoot和AsyncLogger为false。
-
看
log4j2.contextSelector了解更多详情。指定是否允许 Log4j 计算位置信息。如果设置为
false,Log4j 将不会尝试推断日志记录调用的位置,除非使用可用的位置之一显式提供了所述位置LogBuilder#withLocation()方法。 -
Appender references
记录器使用附加程序引用来列出用于传递日志事件的附加程序。
Additional context properties
记录器可以发出额外的上下文数据,这些数据将与其他上下文数据源(例如ThreadContext )集成。
个属性的
value都会经历两次属性替换:因此,如果您希望插入随时间变化的值,则必须将
$符号加倍,如下例所示。Root:
Property:
name: "client.address"
value: "$${web:request.remoteAddress}"
Logger:
- name: "org.hibernate"
Property:
name: "subsystem"
value: "Database"
- name: "io.netty"
Property:
name: "subsystem"
value: "Networking"Filters
Appender references
许多 Log4j 组件(例如记录器)使用附加程序引用来指定将使用哪些附加程序来传递其事件。
与 Log4j 1 中的附加程序引用是简单指针不同,在 Log4j 2 中,它们具有额外的过滤功能。
Appender 引用可以具有以下配置属性和元素:
ref类型
String指定要使用的附加程序的名称。
level类型
它指定必须记录日志事件的级别阈值。比此设置严重程度低的日志事件将被过滤掉。
过滤器
有关可应用于记录器配置的其他过滤功能,请参阅过滤器。
财产替代Property substitution
Log4j 提供了一种简单且可扩展的机制,可以使用
${name}表达式重用配置文件中的值,例如 Bash、Ant 或 Maven 中使用的表达式。可以使用Properties组件将可重用的配置值直接添加到配置文件中。
Configuration:
Properties:
Property:
- name: "log.dir"
value: "/var/log"
- name: "log.file"
value: "${log.dir}/app.log"可扩展的查找机制还可以提供可重用的配置值。有关详细信息,请参阅Lookup 。
通过使用以下扩展规则,可以在任何配置属性中使用以这种方式定义的配置值:
${name}-
如果配置文件的
Properties元素具有名为name的属性,则其值将被替换。否则,占位符不会扩展。-
如果
name包含:字符,则会按以下规则展开。 ${lookup:name}-
如果这两个条件都成立:
-
lookup是分配给Lookup 的前缀, -
查找有一个分配给
name的值,
查找的值被替换。否则,
${name}的扩展将被替换。如果
name以连字符-开头(例如-variable),则必须使用反斜杠\(例如\-variable)进行转义。最常见的查找前缀是:
-
上述扩展有一个带有附加
default值的版本,如果查找失败,该默认值将被扩展:${name:-default}-
如果配置文件的
Properties元素具有名为name,则其值将被替换。否则,将替换default扩展。如果
name包含:字符,则会按以下规则展开。${lookup:name:-default}如果这两个条件都成立:
-
lookup是分配给Lookup 的前缀, -
查找有一个分配给
name,
查找的值被替换。否则,将替换
${name:-default}的扩展。为了防止上述表达式之一的扩展,初始
$必须加倍为$$。同样的规则适用于
name参数:如果它包含${序列,则必须将其转义为$${。Properties: Property: - name: "FOO" value: "foo" - name: "BAR" value: "bar"并且OS环境变量
FOO的值为environment,Log4j将计算表达式如下表达 价值 ${FOO}foo${BAZ}${BAZ}${BAR:-${FOO}}bar${BAZ:-${FOO}}foo${env:FOO}environment${env:BAR}bar${env:BAZ}${BAZ}${env:BAR:-${FOO}}bar${env:BAZ:-${FOO}}foo出于安全原因,如果
${…}表达式的扩展包含其他表达式,则这些表达式将不会被扩展。然而,
Properties容器中定义的属性可以相互依赖。例如,如果您的配置包含:-
XML
-
JSON
-
YAML
-
特性
Properties: Property: - name: "logging.file" value: "${logging.dir}/app.log" - name: "logging.dir" value: "${env:APP_BASE}/logs" - name: "APP_BASE" value: "."logging.dir属性将在logging.file属性之前展开,并且展开的值将在${logging.dir}/app.log中替换。因此,logging.file属性的值为:-
./logs/app.log如果环境变量APP_BASE没有定义, -
/var/lib/app/logs/app.log如果环境变量APP_BASE的值为/var/lib/app。
运行时属性替换
对于大多数属性,属性替换仅在配置时执行一次,但此规则也有例外:当发生特定于组件的事件时也会评估某些属性。
在这种情况下:
-
如果您希望在配置时进行属性替换,请使用一个美元符号,例如
${date:HH:mm:ss}。 -
如果您希望在运行时进行属性替换,请使用两个美元符号,例如
$${date:HH:mm:ss}
支持运行时属性替换的属性列表是:
-
记录器配置的嵌套
Property元素的value属性。 -
这 模式布局的
pattern属性。该属性评估当前日志事件上下文中的查找。 -
JSON Template Layout的事件模板属性。请参阅JSON 模板布局中的属性替换 了解更多详情。
-
Appender 中的运行时属性替换中列出的 Appender 属性。
某些查找在运行时扩展时的行为可能会有所不同。有关详细信息,请参阅查找评估上下文。
在
Route组件内,不应使用转义的$${...}表达式,而只能使用未转义的${...}表达式。Routing: name: "ROUTING" Routes: pattern: "$${sd:type}" Route: File: name: "ROUTING-${sd:type}" fileName: "logs/${sd:type}.log" JsonTemplateLayout: EventTemplateAdditionalField: name: "type" value: "${sd:type}"pattern属性在配置时以及每次路由日志事件时进行评估。因此,美元$符号需要转义。Route元素的子元素的所有属性都有延迟评估。因此,他们只需要一个$符号。 -
-
仲裁者Arbiters
虽然属性替换允许在多个部署环境中使用相同的配置文件,但有时更改配置属性的值是不够的。
仲裁器对于配置元素来说就像属性替换对于配置属性一样:它们允许有条件地将配置元素的子树添加到配置文件中。
仲裁器可以出现在配置中允许元素并且可以嵌套的任何位置。 因此,仲裁器可以封装像单个属性声明或一整套附加器、记录器或其他仲裁器一样简单的东西。
对于仲裁器的父元素,仲裁器的子元素必须是有效元素。例如,您可能想在生产和开发环境中使用不同的布局:
Appenders:
File:
name: "MAIN"
fileName: "logs/app.log"
SystemPropertyArbiter:
- propertyName: "env"
propertyValue: "dev"
PatternLayout:
pattern: "%d [%t] %p %c - %m%n"
- propertyName: "env"
propertyValue: "prod"
JsonTemplateLayout: {}如果 Java 系统属性 env的值为dev,则将使用模式布局。如果 Java 系统属性 env的值为prod,则将使用 JSON 模板布局。上面的示例有一个问题:如果 Java 系统属性
env值不同于dev或prod,则追加器将没有布局。在这种情况下,
Select插件很有用:此配置元素包含仲裁器列表和DefaultArbiter元素。如果没有仲裁器匹配,则将使用DefaultArbiter元素中的配置:Select:
SystemPropertyArbiter:
propertyName: "env"
propertyValue: "dev"
PatternLayout: {}
DefaultArbiter:
JsonTemplateLayout: {}如果 Java 系统属性 env的值为dev,则将使用模式布局。否则,将使用 JSON 模板布局。 复合配置CompositeConfiguration
有时可能需要组合多种配置。例如,
-
您有一个应始终存在的通用 Log4j 核心配置,以及一个特定于环境的配置,该配置根据应用程序运行的环境(测试、生产等)扩展通用配置。
-
您开发一个框架,它包含预定义的 Log4j Core 配置。然而您希望允许用户在必要时扩展它。
-
您从多个来源收集 Log4j Core 配置。
您可以在
log4j2.configurationFile配置属性中提供一系列以逗号分隔的文件路径或 URL,其中每个资源将被读入一个Configuration中,然后最终使用CompositeConfiguration合并为一个资源。 -
从 Log4j 2.10 开始,所有属性名称都遵循通用的命名方案:
log4j2.camelCasePropertyName除了环境变量之外,它遵循以下内容:
LOG4J_CAMEL_CASE_PROPERTY_NAME习俗。
|
如果 |
当应用程序的日志记录速度比底层追加器能够跟上足够长的时间来填充队列时,行为由AsyncQueueFullPolicy确定。
log4j2.asyncLoggerConfigWaitStrategy
指定 LMAX Disruptor 使用的WaitStrategy 。
该值必须是预定义常量之一:
- 堵塞Block
-
对等待日志事件的 I/O 线程使用锁和条件变量的策略。当吞吐量和低延迟不像 CPU 资源那么重要时,可以使用块。建议用于资源受限/虚拟化环境。
- 暂停Timeout
-
Block策略的一种变体,它将定期从锁定条件await()调用中唤醒。这确保了如果不知何故错过通知,消费者线程不会被卡住,而是会以较小的延迟延迟恢复(请参阅log4j2.asyncLoggerTimeout) - 睡觉Sleep
-
一种策略,首先旋转,然后使用
Thread.yield(),并最终在 I/O 线程等待日志事件时停放操作系统和 JVM 允许的最小纳秒数(请参阅log4j2.asyncLoggerRetries和log4j2.asyncLoggerSleepTimeNs)。睡眠是性能和 CPU 资源之间的一个很好的折衷方案。此策略对应用程序线程的影响非常小,但会在实际记录消息时产生一些额外的延迟。 - 屈服Yield
-
是一种将使用
100%CPU 的策略,但如果其他线程需要 CPU 资源,则会放弃 CPU。
另请参阅自定义WaitStrategy以了解配置等待策略的替代方法。
如果JANSI库位于应用程序的运行时类路径上,则可以使用以下属性来控制其使用:
log4j2.skipJansi
|
环境。多变的 |
|
|---|---|
|
类型 |
|
|
默认值 |
|
如果满足以下条件:
-
Log4j 在 Windows 上运行,
-
该属性设置为
false,
Log4j 将使用 JANSI 库为控制台附加器的输出着色。
线程上下文
可以使用以下属性微调ThreadContext类的行为。
|
这些配置属性仅由 Log4j API 的 Log4j Core 和Simple Logger实现使用。
|
property-sources
财产来源
Log4j配置属性子系统合并了实现Java接口的多个属性源的内容 PropertySource 。
可以通过以下方式添加其他属性源类:
-
标准 Java SE
ServiceLoader机制, -
以编程方式使用
PropertiesUtil的addPropertySource()和removePropertySource()静态方法。
每个属性源都可以定义自己的属性名称命名约定,尽管大多数属性源都支持该标准:
log4j2.camelCasePropertyName习俗。
属性可以被具有较低数字优先级的源覆盖(例如-100 在100 之前)。
Log4j提供了以下实现:
| 姓名 | 优先事项 | 命名约定 | 模块 | 描述 |
|---|---|---|---|---|
|
|
标准 |
|
将属性解析委托给 Spring |
|
|
|
|
标准 |
|
使用 Java System Properties解析属性。 |
|
|
|
风俗 |
|
使用环境变量解析属性。 警告:此属性源的命名约定与标准命名约定不同。属性名称以 LOG4J_ 为前缀,全部大写,单词均用下划线分隔。 |
|
|
|
标准 |
|
使用类路径上找到的所有名为 |
属性的运行时评估
以下配置属性也在运行时评估,因此可以包含转义的$${...}属性替换表达式。
| 成分 | 范围 | 事件类型 | 评估背景 |
|---|---|---|---|
|
记录事件 |
|||
|
记录事件 |
|||
|
记录事件 |
|||
|
记录事件 |
|||
|
记录事件 |
|||
|
滚下 |
|||
|
滚下 |
有关更多详细信息,请参阅运行时属性替换。
JANSI
如果应用程序在 Windows 上运行并且 詹西图书馆 可用时,控制台附加器将使用 JANSI 来模拟 ANSI 序列支持。 可以通过设置禁用此模式 log4j2.skipJansi 配置属性为true 。
使用 JANSI 需要额外的运行时依赖项:runtimeOnly 'org.fusesource.jansi:jansi:1.18'
| 属性 | 类型 | 默认值 | 描述 | ||
|---|---|---|---|---|---|
|
必需的 |
|||||
|
|
附加器的名称。 |
||||
|
选修的 |
|||||
|
|
尺寸 有关更多详细信息,请参阅缓冲。 |
||||
|
|
|
如果设置为 此设置绕过
|
|||
|
|
|
如果设置为 否则,将使用配置时 |
|||
|
|
|
如果为 记录异常也始终记录到状态记录器 |
|||
|
|
|
如果设置为 有关更多详细信息,请参阅缓冲。 |
|||
|
它指定要使用哪个标准输出流:
|
|||||
生产环境的典型配置可能如下所示
log4j2.xml的片段<Console name="CONSOLE"
direct="true">
<JsonTemplateLayout/>
</Console>
数据库附加程序
附加程序将日志事件直接写入数据库。
- Cassandra 附加器
-
将日志事件发送至 阿帕奇卡桑德拉
- JDBC 附加器
-
将日志事件发送到 JDBC 驱动程序
- JPA 附加器
-
使用 Jakarta Persistence API 将日志事件传送到数据库
- NoSQL 附加程序
-
将日志事件存储到面向文档的数据库
有关详细信息,请参阅数据库附加程序。
网络附加器
这些附加程序使用简单的网络协议将日志事件传输到远程主机。支持的网络协议有:
UDPTCP-
这些由Socket Appender处理。
HTTP-
这是由HTTP Appender处理的。
SMTP-
这是由SMTP Appender处理的。
有关详细信息,请参阅网络附加程序。
消息队列追加器
消息队列附加程序将日志事件转发到消息代理。支持以下系统:
- 水槽附加器
-
将日志事件转发到 Apache Flume服务器。
- ZeroMQ/JeroMQ 附加器
-
将日志事件转发到 ZeroMQ代理。
有关详细信息,请参阅消息队列附加程序。
Servlet 附加程序
Servlet 附加程序允许用户将所有日志记录调用转发到 ServletContext.log() 方法。
|
这 |
Servlet Appender 没有配置属性。
您可以通过在配置文件中声明Servlet类型的附加程序来使用它:
Servlet:
name: "SERVLET"
PatternLayout:
pattern: "%m%n"
alwaysWriteExceptions: false
runtimeOnly 'org.apache.logging.log4j:log4j-jakarta-web'
委派附加程序追加器 :: Apache Log4j --- Appenders :: Apache Log4j
委托附加程序旨在装饰其他附加程序:
- 异步追加器
-
在专用线程上执行所有 I/O
- 故障转移附加程序
-
提供备份附加程序,以防附加程序失败
- 重写appender
-
在将日志事件传送到目标之前对其进行修改
- 路由附加器
-
为每个日志事件动态选择不同的附加程序
有关详细信息,请参阅委派 Appender 。
延伸追加器 :: Apache Log4j --- Appenders :: Apache Log4j
扩展附加器
Log4j Core 提供了三种文件附加器实现:
File-
File附加器使用FileOutputStream访问日志文件。 RandomAccessFile-
RandomAccessFileAppender 使用RandomAccessFile访问日志文件。 MemoryMappedFile-
MemoryMappedFileAppender 将日志文件映射到MappedByteBuffer。该附加程序不需要进行系统调用来写入磁盘,而是可以简单地更改程序的本地内存,这会快几个数量级。
|
两个附加程序,即使来自不同的记录器上下文,也共享一个共同的 共享 |
常用配置
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
必需的 |
|||
|
当前日志文件的路径 如果包含该文件的文件夹不存在,则会创建该文件夹。 |
|||
|
|
附加器的名称。 |
||
|
选修的 |
|||
|
|
尺寸 有关更多详细信息,请参阅缓冲。 |
||
|
|
|
如果为 记录异常也始终记录到状态记录器 |
|
|
|
|
如果设置为 有关更多详细信息,请参阅缓冲。 |
|
File配置
除了常见的配置选项外, File附加器还提供以下配置选项:
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
|
如果 在大多数系统上,这可以保证原子写入到文件末尾,即使该文件是由多个应用程序打开的。 |
|
|
|
|
如果设置为 有关更多详细信息,请参阅缓冲。 |
|
|
布尔值 |
|
附加程序按需创建文件。仅当日志事件通过所有过滤器并路由到此附加程序时,附加程序才会创建文件。默认为 false。 |
|
|
|
如果不为 底层文件系统应支持 POSIX 文件属性视图。 |
||
|
|
|
如果不为 底层文件系统应支持文件 所有者 属性视图。 |
|
|
|
|
如果不为 底层文件系统应支持 POSIX 文件属性视图。 |
|
|
|
|
如果 请注意,此设置的效果取决于操作系统:某些系统(例如大多数 POSIX 操作系统)不提供强制锁定,而仅提供建议文件锁定。 此设置还会降低附加器的性能。 |
RandomAccessFile配置
除了常见的配置选项之外, RandomAccessFile Appender 还提供以下配置选项:
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
|
如果 此设置不提供与 |
与File追加器不同,此追加器始终使用大小为bufferSize的内部缓冲区。
MemoryMappedFile配置
除了常见的配置选项之外, MemoryMappedFile Appender 还提供以下配置选项:
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
|
如果 此设置不提供与 |
|
|
|
|
它指定内存映射日志文件缓冲区的大小(以字节为单位)。 |
与其他文件追加器不同,此追加器始终使用大小为regionLength的内存映射缓冲区作为其内部缓冲区。
滚动文件追加器
Log4j Core 提供了多个附加程序,允许归档当前日志文件并截断它。
|
滚动文件附加器支持许多配置选项。 如果您只对一些配置示例感兴趣,请参阅配置食谱部分。 |
附加器
Log4j Core 提供了两个滚动文件附加器:
RollingFile-
RollingFileAppender 使用FileOutputStream访问日志文件。 RollingRandomAccessFile-
RollingRandomAccessFileAppender 使用RandomAccessFile访问日志文件。
|
两个附加程序,即使来自不同的记录器上下文,也共享一个共同的
共享 |
| 属性 | 类型 | 默认值 | 描述 | ||
|---|---|---|---|---|---|
|
必需的 |
|||||
|
归档日志文件的模式。有关详细信息,请参阅转换模式 如果 |
|||||
|
|
附加器的名称。 |
||||
|
选修的 |
|||||
|
|
尺寸 有关更多详细信息,请参阅缓冲。 |
||||
|
|
|
如果设置为
有关更多详细信息,请参阅缓冲。 |
|||
|
布尔值 |
|
附加程序按需创建文件。仅当日志事件通过所有过滤器并路由到此附加程序时,附加程序才会创建文件。默认为 false。 |
|||
|
|
当前日志文件的路径可以为
|
||||
|
|
如果不为 底层文件系统应支持 POSIX 文件属性视图。 |
||||
|
|
|
如果不为 底层文件系统应支持文件 所有者 属性视图。 |
|||
|
|
|
如果不为 底层文件系统应支持 POSIX 文件属性视图。 |
|||
|
|
|
如果为 记录异常也始终记录到状态记录器 |
|||
|
|
|
如果设置为 有关更多详细信息,请参阅缓冲。 |
|||
| 类型 | 多重性 | 描述 |
|---|---|---|
|
零或一 |
允许在格式化和发送日志事件之前对其进行过滤。 另请参阅附加程序过滤阶段。 |
|
|
零或一 |
格式化日志事件。 有关详细信息,请参阅布局。 |
|
|
一 |
确定何时归档当前日志文件。 有关详细信息,请参阅触发策略。 |
|
|
零或一 |
确定翻转期间执行的操作。 有关详细信息,请参阅展期策略。 |
转换模式
filePattern属性接受以下模式说明符:
-
%d{...}模式,功能上与 同名PatternLayout模式 除非它使用先前滚动的实际或推断时间戳。 -
扩展为存档文件的计算索引的
%i模式。
所有模式还接受格式说明符,例如%03i将索引打印为 3 位数字的零填充数字。
|
将 会将 反而。 |
RollingFile配置
除了常见的配置选项外, RollingFile Appender 还提供以下配置选项:
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
|
如果 在大多数系统上,这可以保证原子写入到文件末尾,即使该文件是由多个应用程序打开的。 |
|
|
|
|
如果 请注意,此设置的效果取决于操作系统:某些系统(例如大多数 POSIX 操作系统)不提供强制锁定,而仅提供建议文件锁定。 此设置还会降低附加器的性能。 |
RollingRandomAccessFile文件配置
除了常见的配置选项外, RollingRandomAccessFile Appender 还提供以下配置选项:
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
|
如果 此设置不提供与 |
触发策略
触发策略是 Log4j 插件,它实现了 TriggeringPolicy 接口并用于决定何时滚动当前日志文件。
常见问题
触发策略通常根据两个参数决定滚动文件:
-
当前文件的大小。
虽然所有 JVM 都可以可靠地检查文件的大小,但 Log4j 仅在启动时和每次翻转时检查文件大小,并根据传递的日志大小推断所有文件大小更改。如果多个管理器写入同一个文件,则大小计算将关闭。
-
当前文件的创建时间戳。
并非所有文件系统都支持创建时间戳。 最值得注意的是,POSIX 没有指定这样的时间戳,因此 Log4j 使用的值可能取决于所使用的文件系统的类型和 JVM。
如果创建时间戳不可用,则使用上次修改时间戳,该时间戳最多可能相差整个滚动周期。看
BasicFileAttributes.creationTime()了解更多详情。第一次翻转后,Log4j 使用翻转的时间戳作为创建时间戳。
OnStartupTriggeringPolicy
OnStartupTriggeringPolicy策略在 JVM 的生命周期内仅导致一次翻转。如果日志文件是在当前 JVM 启动时间之前创建的并且达到或超过最小文件大小,则会发生翻转。
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
|
文件必须滚动的最小大小。 |
|
在 JMX 缺失或禁用的平台上,例如 Android 或 Google App Engine 中, |
CronTriggeringPolicy
CronTriggeringPolicy基于 CRON 表达式触发翻转。
|
这 |
|
该策略由定时器控制,并且在处理日志事件时是异步的,因此上一个或下一个周期的日志事件可能会出现在日志文件的开头或结尾。 |
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
布尔值 |
|
启动时,将根据当前文件的创建时间戳来评估 cron 表达式。如果在该时间和当前时间之间发生翻转,则文件将立即翻转。 |
|
|
|
SizeBasedTriggeringPolicy
一旦文件达到指定大小, SizeBasedTriggeringPolicy就会导致翻转。
大小可以以字节为单位指定,并带有后缀 KB、MB、GB 或 TB,例如20MB 。尺寸。该大小还可以包含小数值,例如1.5 MB 。大小是使用 Java 根区域设置计算的,因此必须始终使用句点作为小数单位。
|
当与基于时间的触发策略相结合时, |
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
当前日志文件的最大文件大小。一旦达到此大小,就会发生翻转。 该属性的语法为: IE:
|
TimeBasedTriggeringPolicy
当filePattern中的最小时间单位更改值时, TimeBasedTriggeringPolicy会导致翻转。因此,展期可以发生在月末、周末、午夜、小时结束时等。
|
这 可以使用多个 |
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
|
根据最后 |
|
|
|
|
如果为 例如,如果轮换频率为每小时,间隔为
仅当 |
|
|
|
|
指示随机延迟翻转的最大秒数。 此设置对于多个应用程序配置为同时滚动日志文件的服务器非常有用,并且可以跨时间分散这样做的负载。 |
|
当滚动频率为每日或更低时,滚动文件追加器将在服务器默认时区的午夜轮换文件。 您可以通过在 |
多项政策
滚动文件追加器仅允许一个嵌套的触发策略元素。如果您希望使用多个策略,则需要将它们包装在Policies元素中。元素本身没有配置属性。
|
同时使用两种基于时间的触发策略( |
例如,以下 XML 片段定义了滚动日志的策略:
-
当 JVM 启动时。
-
当日志大小达到 10 MB 时。
-
当地时间午夜。
-
XML
-
JSON
-
YAML
-
特性
log4j2.xml的片段<RollingFile name="FILE"
fileName="app.log"
filePattern="app.%d{yyyy-MM-dd}.%i.log">
<JsonTemplateLayout/>
<Policies>
<OnStartupTriggeringPolicy/>
<SizeBasedTriggeringPolicy/>
<TimeBasedTriggeringPolicy/>
</Policies>
</RollingFile>展期策略
翻转策略决定如何轮换或删除旧的存档文件以便为新的存档文件腾出位置。翻转期间执行的操作包括:
-
以循环方式重命名文件。有关更多详细信息,请参阅递增文件索引。
-
归档日志文件的压缩。有关更多详细信息,请参阅压缩存档文件。
-
删除旧的存档日志文件。有关更多详细信息,请参阅
Delete操作。 -
更改归档日志文件的 POSIX 权限。有关更多详细信息,请参阅
PosixViewAttribute操作。
有两种不同的现成可用的翻转策略:
DefaultRolloverStrategy-
这是使用的默认策略,如果
fileName名配置属性 已指定。 它将当前日志文件存储在fileName指定的位置,将归档日志文件存储在 fileName 指定的位置filePattern。 DirectWriteRolloverStrategy-
这是使用的默认策略,如果
fileName名配置属性 为null。它将当前日志文件直接存储在filePattern指定的滚动位置中。
|
不鼓励在 |
常用配置
两种翻转策略都支持以下配置参数:
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
|
确定归档日志文件的压缩级别。 有关更多详细信息,请参阅压缩存档文件。 |
|
|
存储压缩文件的临时位置。 有关更多详细信息,请参阅压缩存档文件。 |
|||
|
|
|
如果为 |
| 类型 | 多重性 | 描述 |
|---|---|---|
|
零个或多个 |
除了文件旋转和压缩之外,在翻转时执行的其他操作。 有关更多详细信息,请参阅可选操作。 |
DefaultRolloverStrategy配置
DefaultRolloverStrategy支持控制文件索引增量的附加属性。
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
枚举 |
|
||
|
|
|
|
|
|
|
|
如果 |
DirectWriteRolloverStrategy配置
DirectWriteRolloverStrategy有一组减少的配置选项,用于增加文件索引:
-
最小文件索引始终为
1。 -
递增策略始终为
max。 -
可以使用以下配置属性来配置最大文件索引:
表 12. DirectWriteRolloverStrategy配置属性属性 类型 默认值 描述 int7%i转换模式的最大值。
增加文件索引
在翻转事件期间,当前日志文件将移动到通过评估确定的位置 filePattern ,使用min作为%i转换模式的值。如果旧日志文件已存在于该位置,则滚动文件附加程序:
-
尝试使用
fileIndex配置属性指定的策略来增加%i的值。 -
如果失败,它将删除最旧的日志文件并轮换剩余的日志文件以为新的日志存档腾出位置。
有以下三种策略可供选择:
min-
使用
min策略,最新的日志文件将具有索引min,最旧的日志文件将具有索引max。这是传统 UNIX 工具和 Log4j 1 使用的日志轮转策略。它不是Log4j 2 的默认策略。
假设
min="1"和max="3"日志文件的轮换如下图所示:
max-
使用
max策略,最旧的日志文件将具有索引min,最新的日志文件将具有索引max。这是 Log4j 2 以来的默认策略。
假设
min="1"和max="3"日志文件的轮换如下图所示:
nomax-
使用
nomax策略,不会删除任何文件,并且将从min开始为较新的存档文件分配递增的索引号。
压缩存档文件
当当前日志文件被归档时,滚动文件追加器可以对其进行压缩。根据存档文件名的扩展名激活压缩。可以识别以下扩展名:
| 扩大 | 支持compressionLevel |
描述 |
|---|---|---|
|
✓ |
ZIP 存档使用 放气 算法 |
|
|
✓ |
使用 DEFLATE 算法的GZIP存档 |
|
|
|
✗ |
BZip2算法 |
|
|
✗ |
放气算法 |
|
|
✗ |
Pack200算法 |
|
|
✗ |
XZ算法 |
|
|
✗ |
Z标准算法 |
如果设置了tempCompressedFilePattern属性,则当前日志文件:
-
将被压缩并存储在
tempCompressedFilePattern指定的位置 -
然后它将被移动到
filePattern指定的位置。
- 部门
-
使用这些压缩算法需要额外的依赖项:
-
梅文
-
摇篮
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-compress</artifactId> <version>1.27.1</version> <scope>runtime</scope> </dependency>.xz和.zst扩展名需要额外的依赖项。 看 共享压缩文档 了解更多详情。 -
可选操作
文件的轮换和压缩始终由滚动文件附加程序自动处理。从 Log4j 2.6 开始,可以手动配置其他操作。
Log4j Core 提供了两种开箱即用的操作:
-
滚动更新后删除旧日志文件的
Delete操作, -
PosixViewAttribute操作可更改旧日志文件的 POSIX 权限。
常用动作配置
这两个操作都支持以下配置属性:
| 属性 | 类型 | 默认值 | 描述 | ||
|---|---|---|---|---|---|
|
它设置操作的基目录。该操作将仅限于该目录中的文件,并且所有路径都将相对于该目录。 必需的 |
|||||
|
|
|
如果设置为
|
|||
|
|
|
可访问的最大目录级别数。默认情况下,该操作不会递归到 |
| 类型 | 多重性 | 描述 |
|---|---|---|
|
零个或多个 |
一组路径条件。该操作仅对条件返回 |
Delete操作
Delete操作将删除符合配置条件的旧日志文件。
除了常见的配置选项之外, Delete操作还支持以下选项:
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
|
如果为 |
| 类型 | 多重性 | 描述 |
|---|---|---|
|
零个或多个 |
如果存在,则仅对条件返回 必需的,除非提供了 |
|
|
零或一 |
为 默认实现是 |
|
|
零或一 |
如果存在,则忽略所有嵌套的 |
PosixViewAttribute操作
此操作允许修改存档日志文件的 POSIX 属性(所有者、组和权限)。
|
默认情况下,POSIX 属性继承自当前日志文件。 仅当归档日志文件必须具有不同的属性时才需要执行此操作。 |
除了常见的配置选项之外, PosixViewAttribute Action 还支持以下选项。
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
如果不为 底层文件系统应支持 POSIX 文件属性视图。 |
||
|
|
|
如果不为 底层文件系统应支持文件 所有者 属性视图。 |
|
|
|
|
如果不为 底层文件系统应支持 POSIX 文件属性视图。 |
| 类型 | 多重性 | 描述 |
|---|---|---|
|
一个或多个 |
用于选择要修改的文件的一组条件。 |
路径条件
为了选择文件进行其他操作,Log4j 提供了以下路径条件:
IfAccumulatedFileSize
当对文件列表进行评估时,此条件将每个文件的大小与前面文件的大小相加。对于超过可配置阈值的文件,它返回true 。
|
此条件的结果取决于文件的排序顺序。有关详细信息,请参阅 |
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
条件匹配的阈值大小。 承认与 必需的 |
| 类型 | 多重性 | 描述 |
|---|---|---|
|
零个或多个 |
一组可选的嵌套条件。仅当所有嵌套条件也匹配时,此条件才匹配。 |
IfAccumulatedFileCount
当对文件列表进行评估时,如果文件从 1 开始的索引超过可配置的阈值,则此条件返回true 。
|
此条件的结果取决于文件的排序顺序。有关详细信息,请参阅 |
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
条件匹配的阈值。 必需的 |
| 类型 | 多重性 | 描述 |
|---|---|---|
|
零个或多个 |
一组可选的嵌套条件。仅当所有嵌套条件也匹配时,此条件才匹配。 |
IfFileName
根据文件相对于基目录的路径来匹配文件。
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
细绳 |
使用 看 必需的,除非指定了 |
||
|
使用正则表达式匹配相对于目录的路径。 看 必需的,除非指定了 |
| 类型 | 多重性 | 描述 |
|---|---|---|
|
零个或多个 |
一组可选的嵌套条件。仅当所有嵌套条件也匹配时,此条件才匹配。 |
IfLastModified
根据文件的上次修改时间戳接受文件。
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
该条件接受与指定持续时间一样旧或早于指定持续时间的文件。 必需的 |
| 类型 | 多重性 | 描述 |
|---|---|---|
|
零个或多个 |
一组可选的嵌套条件。仅当所有嵌套条件也匹配时,此条件才匹配。 |
ScriptCondition
ScriptCondition使用 JSR 223 脚本来确定匹配文件的列表。
它的配置由单个嵌套脚本元素组成:
| 类型 | 多重性 | 描述 |
|---|---|---|
|
|
一 |
对要执行的脚本的引用。 有关脚本编写的更多详细信息,请参阅脚本。 |
该脚本必须返回一个列表 PathWithAttributes 对象并支持以下绑定:
| 绑定名称 | 类型 | 描述 |
|---|---|---|
|
基本目录的路径。 |
||
|
|
||
|
基本目录中包含的文件列表。 |
||
|
|
||
|
脚本中的诊断消息使用的状态记录器。 |
||
|
|
|
如果 |
有关ScriptCondition用法的示例,请参阅下面的使用ScriptCondition示例。
配置配方
logrotate等效配置
Logrotate是一种常见的 UNIX 实用程序,用于轮换日志文件。
由于无法通知 Java 应用程序需要重新加载日志文件,因此可以通过其copytruncate选项将logrotate与 Java 应用程序一起使用(请参阅 logrotate(8)手册页)。因此,示例logrotate配置文件可能如下所示:
/var/log/app.log {
copytruncate
compress
rotate 15
daily
maxsize 100k
}这个配置有一个问题, copytruncate选项的文档中有解释:
请注意,复制文件和截断文件之间的时间片非常短,因此可能会丢失一些日志记录数据。
幸运的是,您可以使用滚动文件附加程序来替换logrotate的使用。等效的配置如下所示:
-
XML
-
JSON
-
YAML
-
特性
log4j2.xml的片段<RollingFile name="FILE"
fileName="/var/log/app.log"
filePattern="/var/log/app.log.%i.gz">
<JsonTemplateLayout/>
<DefaultRolloverStrategy max="15"/>
<Policies>
<CronTriggeringPolicy schedule="0 0 0 * * ?"/>
<SizeBasedTriggeringPolicy size="100k"/>
</Policies>
</RollingFile>相当于compress :压缩存档文件。 |
|
相当于rotate 15 :只保留最新的15日志文件。 |
|
相当于daily :日志将在每天的午夜轮换。 |
|
相当于maxsize 100k :如果日志大小超过 100 kB,则日志将被轮换。 |
带时间戳的日志文件名
以下配置每天创建一个日志文件并删除超过 15 天的日志文件。
|
由于我们在配置文件中有一个 |
-
XML
-
JSON
-
YAML
-
特性
log4j2.xml的片段<RollingFile name="FILE"
filePattern="/var/log/app.%d{yyyy-MM-dd}.log.gz">
<JsonTemplateLayout/>
<DirectWriteRolloverStrategy>
<Delete basePath="/var/log">
<IfFileName regex="app\.\d{4}-\d{2}-\d{2}\.log\.gz"/>
<IfLastModified age="P15D"/>
</Delete>
</DirectWriteRolloverStrategy>
<TimeBasedTriggeringPolicy/>
</RollingFile>由于我们使用DirectWriteRolloverStrategy ,因此仅使用filePattern属性。 |
|
提供了显式Delete操作。 |
|
您可以使用正则表达式或更简单的app.*.log.gz glob 模式选择要删除的文件。 |
使用ScriptCondition
如果提供的路径条件不充分,您可以将ScriptCondition与任意脚本一起使用。
上面的示例可以重写为以下 Groovy 脚本:
def limit = FileTime.from(ZonedDateTime.now().minusDays(15).toInstant())
def matcher = FileSystems.getDefault().getPathMatcher('glob:app.*.log.gz')
statusLogger.info("Deleting files older than {}.", limit)
return pathList.stream()
.filter({
def relPath = basePath.relativize(it.path)
def lastModified = it.attributes.lastModifiedTime()
Files.isRegularFile(it.path)
&& lastModified <= limit
&& matcher.matches(relPath)
})
.collect(Collectors.toList())| 在脚本中添加状态记录器调用可能有助于调试它。 | |
PathWithAttributes.getPath() 总是以basePath开头,所以我们需要将其相对化。 |
|
相当于IfLastModified条件。 |
|
相当于IfFileName条件。 |
您可以在配置文件中使用该脚本,如下所示:
-
XML
-
JSON
-
YAML
-
特性
log4j2.xml的片段<RollingFile name="FILE"
filePattern="/var/log/app.%d{yyyy-MM-dd}.log.gz">
<JsonTemplateLayout/>
<DirectWriteRolloverStrategy>
<Delete basePath="/var/log">
<ScriptCondition>
<ScriptFile path="script-condition.groovy"
language="groovy"/>
</ScriptCondition>
</Delete>
</DirectWriteRolloverStrategy>
<TimeBasedTriggeringPolicy/>
</RollingFile>每月单独的文件夹
我们还可以为临时相关的文件创建单独的文件夹。在下面的示例中,我们为每个月创建一个不同的文件夹:
-
XML
-
JSON
-
YAML
-
特性
log4j2.xml的片段<RollingFile name="FILE"
filePattern="/var/log/app/%d{yyyy-MM}/%d{yyyy-MM-dd}.log.gz">
<JsonTemplateLayout/>
<DirectWriteRolloverStrategy>
<Delete basePath="/var/log/app"
maxDepth="2">
<IfLastModified age="P90D"/>
</Delete>
</DirectWriteRolloverStrategy>
<TimeBasedTriggeringPolicy/>
</RollingFile>我们使用两个%d模式来指定文件夹和文件名。 |
|
我们增加了Delete操作的递归深度以扩展到基本目录的子文件夹。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号