通过异星工厂了解 Kafka
前几天玩异星工厂时,我对它与Apache Kafka 的许多相似之处感到震惊。
如果您不熟悉它们:Factorio 是一个开放世界的 RTS,您可以在其中构建和优化供应链,以便发射卫星并恢复与您的家乡星球的通信,而 Kafka 是一个分布式流媒体平台,可以处理异步通信一种持久的方式。
我想知道在异星工厂和卡夫卡之间的类比开始崩溃之前,我们可以将其进行到何种程度。让我们从头开始,通过 Factorio 可视化探索 Kafka 的核心概念,并在此过程中享受一些乐趣。

为什么要费心异步消息传递?
假设我们有三个微服务。一种用于开采铁矿石,一种用于将铁矿石冶炼成铁板,一种用于用这些板生产铁齿轮。我们可以通过同步 HTTP 调用来链接这些服务。
每当我们的采矿钻机有新的铁矿石时,它都会对熔炼炉进行 POST 调用,然后熔炼炉会 POST 到工厂。

这种设置对我们很有用,直到工厂停电。熔炉的 HTTP 调用失败,导致采矿钻机的调用也失败。我们可以实现断路器和重试来防止级联故障和消息丢失,但在某些时候我们将不得不停止尝试,否则我们将耗尽内存。

如果有一种方法可以解耦这些微服务就好了……当然,这就是 Kafka 的用武之地。使用 Kafka,您可以以容错且持久的方式存储记录流。在 Kafka 术语中,这些流称为主题。

通过服务之间的异步主题,消息或记录会在峰值负载期间以及发生中断时进行缓冲。这些缓冲区显然容量有限,所以我们来谈谈可扩展性。
我们可以通过向集群添加 Kafka 服务器来增加存储容量和吞吐量。另一种方法是增加磁盘大小(用于存储)或 CPU 和网络速度(用于吞吐量)。这些选项中哪一个能够为您提供最佳性价比取决于特定的用例,但购买更大的服务器(与购买更多服务器不同)会受到收益递减规律的影响。Kafka 的容量随着每个节点的添加而线性扩展,因此通常就是这样。


为了在多个服务器之间划分主题,我们需要一种将主题拆分为更小的子流的方法。这些子流称为分区。每当服务生成新记录时,该服务就会决定该记录应放置在哪个分区上。
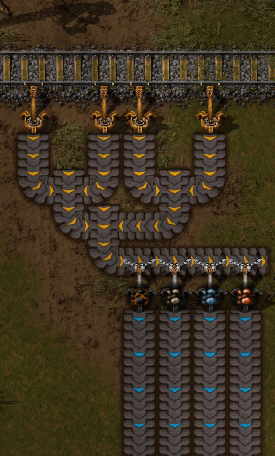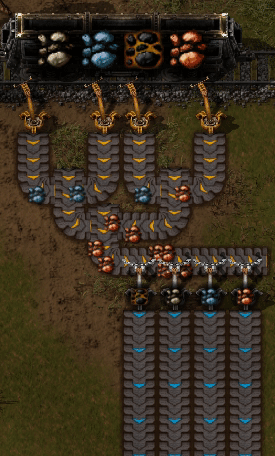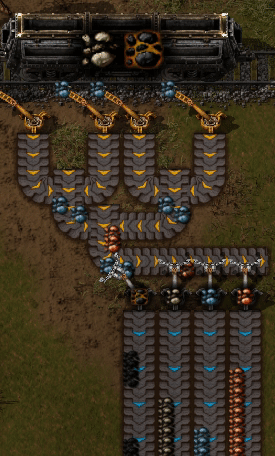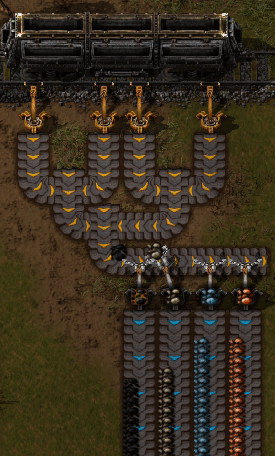
这样,具有相同密钥的消息始终会位于同一分区上。
请注意,仅保证消息在生产者和分区的上下文中有序。来自多个生产者或来自多个分区上的单个生产者的记录可以交错。
现在我们知道了如何将消息放入主题中,让我们看看它们是如何被使用的。当您开始收听某个主题时,默认情况下,所有分区的记录都会路由给您。不过,同时运行多个微服务实例以实现更高的吞吐量或可用性是很常见的。
如果他们都开始侦听该主题,则每个实例都会处理每个记录,这通常不是您想要的。

消费者组允许您在多个消费者之间均匀划分分区。当微服务实例加入消费者组时,Kafka会为其重新分配一些分区。
同样,当实例崩溃或因其他原因离开组时,其分区将分配给其他实例。Kafka 确保分区始终均匀地分配给每个组中的消费者。

如果某个主题的每个分区的记录数存在偏差,那么您可能会遇到麻烦。某个实例可能无法跟上,因为它被分配了包含许多记录的分区,而其他实例则处于空闲状态。
您需要确保不存在比其他分区拥有更多记录的分区。

每个消费者都会跟踪其处理过的记录。由于记录是按顺序处理的,因此简单的偏移量就足够了。每隔一段时间(默认为 5 秒),消费者会将其偏移量提交给 Kafka 。
当消费者离开其组时,其分区将被分配给组中的其他消费者。新的消费者将能够从前一个消费者停止的偏移量开始请求记录。
有可能记录已被处理,但尚未提交。您要么必须从提交的偏移量开始,要么开始处理新消息并跳过所有尚未处理的内容。
这就是为什么Kafka只能保证消息至少投递一次,或者最多投递一次。
当我们开始复制数据时,这个类比就不再有意义了。使用 Kafka,我们可以多次处理单个记录。多个消费者组可以消费相同的记录。为了可靠性,可以使用三的复制因子来存储主题。主题可以有一个保留期,保留期过后记录将被删除。所有这一切都是可能的,因为数据与铁不同,可以轻松复制。
这是结束这篇文章的好地方。我们已经介绍了 Kafka 的所有主要概念,您应该对 Kafka 的工作原理有一个大致的了解。让我们简短回顾一下。
我们学到了什么
Kafka 是一个分布式流媒体平台,通过跨多个服务器复制记录以持久的方式存储记录。主题由分区组成,分区按顺序存储记录。分区器决定哪些记录属于哪些分区。
消费者组是可选的,有助于在消费者之间分配分区以实现可扩展性。当消费者崩溃时,偏移量将作为检查点提交。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号