Java OOM 原理篇 : 什么是 Java OOM,CPU使用率超过100%的原因
导语
金三银四跳槽季将至,估计小伙伴们都在备战,来问问题的也多了起来,尤其是问OOM与JVM调优相关的问题。只能感叹,大家都太不容易了。明明只是小白、明明只想找份工作、明明没有机会接触到OOM与调优……却被现实逼着要去搞懂JVM、OOM、调优……本篇文章是结合大厂与小厂的同学们问的问题,结合我的工作经历整理总结而来。看懂、理解、背下来,当面试官再问你OOM与调优,一定被你征服。
看完这篇文章,大家能获得的知识:
1、什么是OOM
2、为什么会发生OOM
3、哪些区域会发生OOM
4、JVM进程挂了,会有哪些可能性
5、生产环境的JVM无响应了,如何快速定位问题
6、子牙老师给你的一些成熟的调优建议
正文
什么是OOM
OOM是Out Of Memory的缩写。即内存溢出。
为什么会发生OOM
如果面试官问这个问题,我知道每个人都能说一大堆,但是我希望大家就回答下面三句话,言简意赅:
-
业务正常运行起来就需要比较多的内存,而给JVM设置的内存过小。具体表现就是程序跑不起来,或者跑一会就挂了。
-
GC回收内存的速度赶不上程序运行消耗内存的速度。出现这种情况一般就是往list、map中填充大量数据,内存紧张时JVM拆东墙补西墙补不过来了。所以查询记得分页啊!不需要的字段,尤其是数据量大的字段,就不要返回了!比如文章的内容。
-
存在内存泄漏情况,久而久之也会造成OOM。哪些情况会造成内存泄漏呢?比如打开文件不释放、创建网络连接不关闭、不再使用的对象未断开引用关系、使用静态变量持有大对象引用……
哪些区域会发生OOM
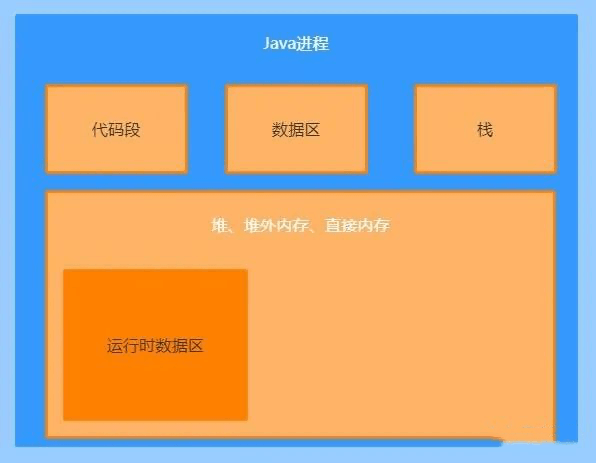
JVM运行时数据区五个区域中,除了程序计数器不会发生OOM,其他区域都有可能。
除了元空间、本地方法栈、虚拟机栈、堆外,还有一块区域大家容易忽略,即直接内存。
不知道什么是直接内存?看这张图
模拟这五个区域的OOM,可能有些小伙伴不知道程序怎么写,我已经给大家写好测好了,后台回复领取:OOM
可能有些小伙伴又要说了:搞挂JVM,我有无数的办法,可怎么让它一直活着或活得更久更好呢?之前写过调优相关的文章 传送门
JVM挂了有哪些可能性
从Windows系统角度说,JVM进程如果不是你手动关闭的,那就是OOM导致的。但是在Linux下就不一定了,因为Linux系统有一种保护机制:OOM Killer。这个机制如果展开来说又能说一堆,这里我就大概说下吧,这个机制是Unix内核独有的,它的出现是为了保证系统在可用内存较少的情况下依旧能够运行,会选择杀掉一些分值较高的进程来回收内存。这个分值是Unix内核根据一些参数动态计算出来的,当然,我们也可以改变,感兴趣的小伙伴百度学习吧。作为Java程序员,了解到这个程度基本够用了,再底层的话,很多面试官也不知道,也不会问。
除了OOM Killer,剩下的就是OOM导致JVM进程挂了。
生产环境如何快速定位问题
如果面试官问你这个问题;如果你们公司的生产环境出现过这样的问题;如果你想解决却束手无策……照着这个流程去说去做即可。
前面说了,算上直接内存,共有五个区域会发生OOM:直接内存、元空间、本地方法栈、虚拟机栈、元空间。
本地方法栈与虚拟机栈的OOM咱们可以不用管,为什么呢?因为这两个区域的OOM你在开发阶段或在测试阶段就能发现。GET到了吗?小伙伴们。所以这两个区域的OOM是不会生成dump文件的。
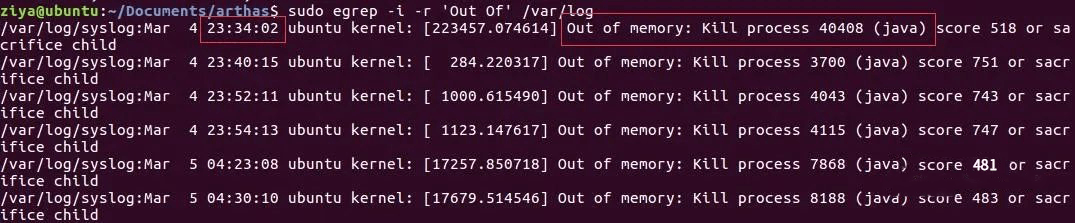
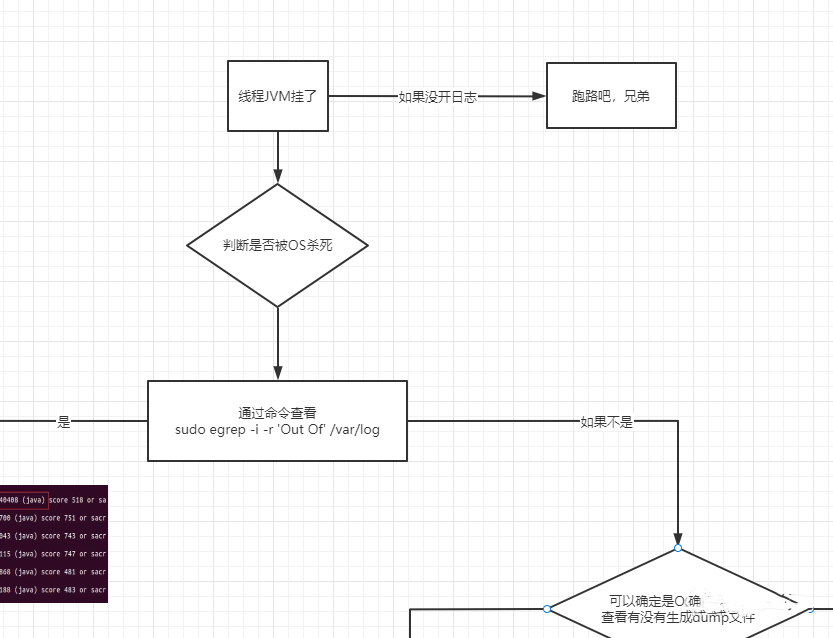
好,开始正题。如果生产环境JVM挂了,这时候不要慌,有节奏的来分析来排除。首先排除是不是被Linux杀死了,怎么看呢?通过命令[sudo egrep -i -r 'Out Of' /var/log]查看,如果是,关闭一些服务,或者把一些服务移走,腾出点内存。
如果不是,这时候就可以确定是OOM导致的,那具体是哪个OOM导致的呢?看有没有生成dump文件。如果生成了,要么是堆OOM,要么是元空间OOM;如果没生成,直接可以确定是直接内存导致的OOM。怎么解决呢?调优呗。
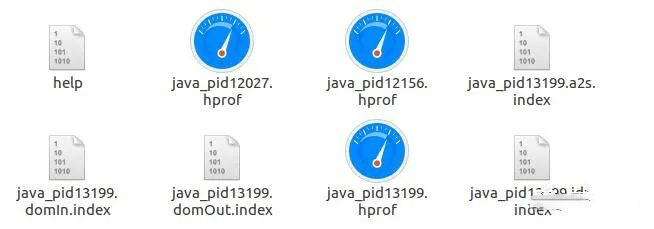
我这边是生成了的,所以需要进一步排查,是堆OOM还是元空间OOM。这时候需要把dump文件从服务器上下载下来,用visualvm分析。当前其他工具如MAT、JProfiler都可以,我习惯用visualvm。很多小伙伴不会看dump日志哈,子牙老师教给你诀窍,学会了,受益无穷。

如果你发现发生OOM的位置是创建对象,调用构造方法之类的代码,那一定是堆OOM。<init>就是构造方法的字节码格式。所以学点JVM底层知识还是有必要的啊。
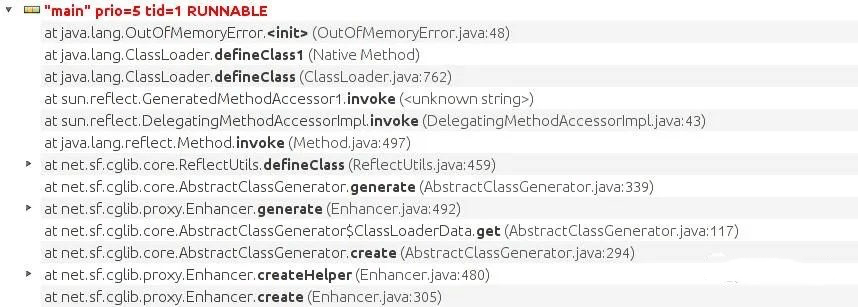
如果你发现发生OOM的位置是类加载器那些方法,那一定是元空间OOM。
怎么样,学会了吗?
如果发生OOM让JVM自动dump内存的设置你没开,那你可以跑路了,老板正在赶来的路上,手上拿着大刀!
一些成熟的建议
接下来才是重点,我来给你一些实战经验,让你在面试中或工作中更加自信:
-
调优参数务必加上-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=,发生OOM让JVM自动dump出内存,方便后续分析问题解决问题
-
堆内存不要设置的特别大,因为你设置的特别大,发生OOM时生成的dump文件就特别大,不好分析。建议不超过8G。
-
想主动dump出JVM的内存,有挺多方式,但不管哪种方式,主动dump内存会引发STW,请择时操作。即通过arthas提供的命令heapdump主动dump出JVM的内存,这个操作会引发FGC,背后是STW,操作时请选择好时机,不然老板可能提刀来见。
-
我提供的代码务必拉下来跑跑,找下感觉。最好是自己也去写一份与我提供的不同的,加深理解,加深印象。
Java OOM优化专题大纲目录
第四篇:Java OOM 基础篇:常见的OutOfMemoryError 场景三: PermGen space 永久空间问题详解
第五篇:Java OOM 基础篇:常见的OutOfMemoryError 场景四: Permgen size 元空间问题详解
第六篇:Java OOM 实战篇:应用故障之Java heap space 堆溢出实战
第七篇:Java OOM 高级篇:体验了一把线上CPU100%及应用OOM的排查和解决过程
第八篇:Java OOM 高级篇:线上Docker 上Springboot程序OOM问题的排查分享
导语
此文来自于plumbr官网,plumbr作为一个常用的JVM 监测工具相信大家也有接触,本篇主要解读的是造成Java heap space的原因和解决方法,本篇不涉及实战优化案列,有较多的干货知识和优化思路,希望看完本篇内容的小伙伴能有所收获。
正文
第一篇:java.lang.OutOfMemoryError:Java heap space
Java 应用程序只允许使用有限的内存量。此限制是在应用程序启动期间指定的。为了让事情变得更复杂,Java 内存被分成两个不同的区域。这些区域称为堆空间和 Permgen(用于永久代):

这些区域的大小是在 Java 虚拟机 (JVM) 启动期间设置的,可以通过指定 JVM 参数-Xmx和-XX:MaxPermSize进行自定义。如果您没有明确设置大小,将使用特定于平台的默认值。
该java.lang.OutOfMemoryError:Java堆空间时,应用程序错误将被触发尝试添加更多的数据放入堆空间区域,但没有足够的空间供它。
请注意,可能有足够的物理内存可用,但是只要 JVM 达到堆大小限制,就会抛出java.lang.OutOfMemoryError: Java heap space错误。
1,是什么原因造成的?
java.lang.OutOfMemoryError 的最常见原因很简单:您尝试将 XXL 应用程序放入 S 大小的 Java 堆空间中。也就是说 - 应用程序只需要比正常运行可用的更多的 Java 堆空间。此 OutOfMemoryError 消息的其他原因更为复杂,并且是由编程错误引起的:
- 使用量/数据量激增。该应用程序旨在处理一定数量的用户或一定数量的数据。当用户数或数据量突然激增并超过预期阈值时,在峰值之前正常运行的操作停止运行并触发java.lang.OutOfMemoryError: Java heap space错误。
- 内存泄漏。特定类型的编程错误会导致您的应用程序不断消耗更多内存。每次使用应用程序的泄漏功能时,都会将一些对象留在 Java 堆空间中。随着时间的推移,泄漏的对象会消耗所有可用的 Java 堆空间并触发已经熟悉的java.lang.OutOfMemoryError: Java heap space错误。
2,举个例子
第一个例子非常简单——下面的 Java 代码尝试分配一个 2M 整数的数组。当您编译它并使用 12MB 的 Java 堆空间 ( java -Xmx12m OOM ) 启动时,它会失败并显示java.lang.OutOfMemoryError: Java heap space消息。使用 13MB Java 堆空间,程序运行得很好。
class OOM {
static final int SIZE=2*1024*1024;
public static void main(String[] a) {
int[] i = new int[SIZE];
}
}内存泄漏示例
第二个也是更现实的例子是内存泄漏。在 Java 中,当开发人员创建和使用新对象(例如 new Integer(5) )时,他们不必自己分配内存——这由 Java 虚拟机 (JVM) 负责。在应用程序的生命周期中,JVM 会定期检查内存中的哪些对象仍在使用,哪些尚未使用。可以丢弃未使用的对象,回收内存并再次使用。这个过程称为垃圾收集。JVM 中负责收集的相应模块称为垃圾收集器 (GC)。
Java 的自动内存管理依赖于GC定期查找未使用的对象并删除它们。稍微简化一下,我们可以说Java中的内存泄漏是应用程序不再使用某些对象但垃圾收集无法识别它的情况。结果,这些未使用的对象无限期地保留在 Java 堆空间中。这种堆积最终会触发java.lang.OutOfMemoryError: Java heap space错误。
构造一个满足内存泄漏定义的 Java 程序相当容易:
class KeylessEntry {
static class Key {
Integer id;
Key(Integer id) {
this.id = id;
}
@Override
public int hashCode() {
return id.hashCode();
}
}
public static void main(String[] args) {
Map m = new HashMap();
while (true)
for (int i = 0; i < 10000; i++)
if (!m.containsKey(new Key(i)))
m.put(new Key(i), "Number:" + i);
}
}当您执行上面的代码时,您可能希望它永远运行而不会出现任何问题,假设朴素的缓存解决方案仅将底层 Map 扩展到 10,000 个元素,因为除此之外,所有键都已经存在于 HashMap 中。然而,实际上这些元素将继续添加,因为 Key 类在其hashCode()旁边不包含适当的equals()实现。
结果,随着时间的推移,随着不断使用泄漏代码,“缓存”结果最终会消耗大量 Java 堆空间。当泄漏的内存填满堆区域中的所有可用内存并且垃圾收集无法清除它时,会抛出java.lang.OutOfMemoryError:Java 堆空间。
解决方案很简单——添加类似于下面的equals()方法的实现,你会很高兴。但在你找到原因之前,你肯定会失去一些宝贵的脑细胞。
@Override
public boolean equals(Object o) {
boolean response = false;
if (o instanceof Key) {
response = (((Key)o).id).equals(this.id);
}
return response;
}3,解决办法是什么?
在某些情况下,分配给 JVM 的堆数量不足以满足在该 JVM 上运行的应用程序的需求。在这种情况下,你应该只分配更多的堆——请参阅本章末尾以了解如何实现这一点。
然而,在许多情况下,提供更多的 Java 堆空间并不能解决问题。例如,如果您的应用程序包含内存泄漏,添加更多堆只会推迟java.lang.OutOfMemoryError: Java heap space错误。此外,增加 Java 堆空间量也往往会增加GC 暂停的长度,影响应用程序的吞吐量或延迟。
如果您希望解决 Java 堆空间的潜在问题而不是掩盖症状,您需要弄清楚代码的哪一部分负责分配最多的内存。换句话说,您需要回答以下问题:
- 哪些对象占据堆的大部分
- 在源代码中分配这些对象的位置
此时,请确保在您的日历中清除几天(或 – 请参阅项目符号列表下方的自动方式)。以下是一个粗略的流程大纲,可以帮助您回答上述问题:
- 获得安全许可,以便从 JVM 执行堆转储。“转储”基本上是您可以分析的堆内容的快照。因此,这些快照可能包含机密信息,例如密码、信用卡号等,因此出于安全原因,甚至可能无法获取此类转储。
- 在适当的时候获取转储。准备好进行一些转储,因为在错误的时间进行时,堆转储包含大量噪音,实际上可能毫无用处。另一方面,每次堆转储都会完全“冻结”JVM,因此不要使用太多堆转储,否则您的最终用户会开始面临性能问题。
- 找到一台可以加载转储的机器。当您的 JVM-to-troubleshoot 使用例如 8GB 的堆时,您需要一台超过 8GB 的机器来分析堆内容。启动转储分析软件(我们推荐Eclipse MAT,但也有同样好的替代品)。
- 检测到最大堆消耗者的 GC 根的路径。我们已经覆盖在一个单独的后这一活动在这里。对于初学者来说尤其困难,但练习会让您了解结构和导航机制。
- 接下来,您需要弄清楚在源代码中的何处分配了具有潜在危险的大量对象。如果您非常了解应用程序的源代码,则可以通过几次搜索来完成此操作。
或者,我们建议Plumbr,这是唯一具有自动根本原因检测功能的 Java 监控解决方案。在其他性能问题中,它捕获所有java.lang.OutOfMemoryError并自动为您提供有关最需要内存的数据结构的信息。
Plumbr 负责在幕后收集必要的数据——这包括有关堆使用情况的相关数据(只有对象布局图,没有实际数据),以及一些您甚至在堆转储中都找不到的数据。它还会为您进行必要的数据处理——在 JVM 遇到java.lang.OutOfMemoryError 时立即进行。这是来自 Plumbr 的java.lang.OutOfMemoryError事件警报示例:
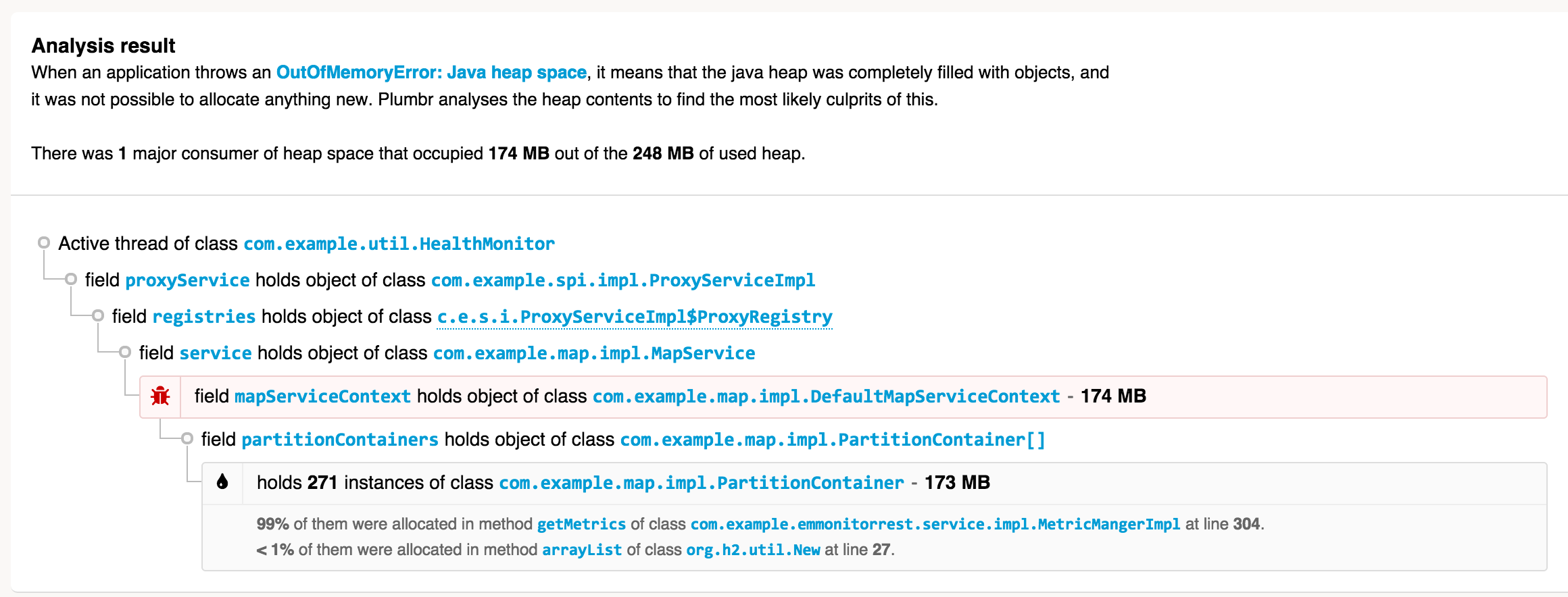
无需任何额外的工具或分析,您就可以看到:
- 哪些对象消耗的内存最多(271 个com.example.map.impl.PartitionContainer实例消耗了 248MB 总堆中的 173MB)
- 这些对象的分配位置(大部分分配在MetricManagerImpl类中,第 304 行)
- 当前引用这些对象的是什么(直到 GC 根的完整引用链)
有了这些信息,您就可以放大潜在的根本原因,并确保将数据结构修剪到适合您的内存池的级别。
但是,当您从内存分析或阅读 Plumbr 报告得出的结论是内存使用是合法的并且源代码中没有任何更改时,您需要让您的 JVM 有更多的 Java 堆空间才能正常运行。在这种情况下,更改您的 JVM 启动配置并添加(或增加值,如果存在)以下内容:
-Xmx1024m
上述配置将为应用程序提供 1024MB 的 Java 堆空间。您可以对 GB 使用 g 或 G,对 MB 使用 m 或 M,对 KB 使用 k 或 K。例如,以下所有内容都相当于说最大的 Java 堆空间为 1GB:
java -Xmx1073741824 com.mycompany.MyClass
java -Xmx1048576k com.mycompany.MyClass
java -Xmx1024m com.mycompany.MyClass
java -Xmx1g com.mycompany.MyClass原文链接:https://plumbr.io/outofmemoryerror/java-heap-space
导语
此文来自于plumbr官网,plumbr作为一个常用的JVM 监测工具,官网有完整的oom和gc文章,本篇主要介绍了GC产生的原因以及解决办法,希望对大家有所帮助。
正文
第一篇:java.lang.OutOfMemoryError:Java heap space
第二篇:Java.lang.OutOfMemoryError: GC overhead limit exceeded
Java 运行时环境包含一个内置的垃圾回收 (GC)进程。在许多其他编程语言中,开发人员需要手动分配和释放内存区域,以便可以重用释放的内存。
另一方面,Java 应用程序只需要分配内存。每当内存中的特定空间不再使用时,称为垃圾收集的单独进程会为它们清除内存。垃圾收集手册中更详细地解释了 GC 如何检测内存的特定部分,但您可以相信 GC 能很好地完成它的工作。
在GC开销超过极限:java.lang.OutOfMemoryError时显示错误您的应用程序已经耗尽了几乎所有的可用内存和GC一再未能清除它。
1,是什么原因造成的?
该java.lang.OutOfMemoryError:GC开销超过极限误差信号,你的应用程序花费太多的时间做垃圾收集太少的结果JVM的方式。默认情况下,如果 JVM 花费超过98% 的总时间进行 GC 并且在 GC 之后仅回收不到 2% 的堆,则JVM 被配置为抛出此错误。

如果这个 GC 开销限制不存在,会发生什么?请注意java.lang.OutOfMemoryError: GC 开销限制超出错误仅在几次GC 循环后释放 2% 的内存时才会抛出。这意味着 GC 能够清理的少量堆可能会再次被快速填满,从而迫使 GC 再次重新启动清理过程。这形成了一个恶性循环,CPU 100% 忙于 GC,无法完成任何实际工作。应用程序的最终用户面临极端的减速——通常在几毫秒内完成的操作需要几分钟才能完成。
因此,“ java.lang.OutOfMemoryError: GC 开销限制超出”消息是快速失败原则的一个很好的例子。
2,举个例子
在以下示例中,我们通过初始化 Map 并在未终止的循环中将键值对添加到映射中来创建“超出 GC 开销限制”错误:
class Wrapper {
public static void main(String args[]) throws Exception {
Map map = System.getProperties();
Random r = new Random();
while (true) {
map.put(r.nextInt(), "value");
}
}正如您可能猜到的那样,这不会有好的结局。事实上,当我们启动上述程序时:
java -Xmx100m -XX:+UseParallelGC Wrapper我们很快就会遇到java.lang.OutOfMemoryError: GC 开销限制超出消息。但是上面的例子很棘手。当使用不同的 Java 堆大小或不同的GC 算法启动时,我的 Mac OS X 10.9.2 和 Hotspot 1.7.0_45 将选择不同的死亡。例如,当我以较小的 Java 堆大小运行程序时,如下所示:
java -Xmx10m -XX:+UseParallelGC Wrapper应用程序将因更常见的java.lang.OutOfMemoryError: Java heap space消息而死亡,该消息在 Map resize 时抛出。当我使用除ParallelGC之外的其他垃圾收集算法运行它时,例如-XX:+UseConcMarkSweepGC或-XX:+UseG1GC,错误被默认异常处理程序捕获并且没有堆栈跟踪,因为堆已经耗尽到甚至无法在异常创建时填充堆栈跟踪。
这些变化确实是很好的例子,表明在资源受限的情况下,您无法预测应用程序的死亡方式,因此不要将您的期望建立在要完成的特定操作序列上。
3,解决办法是什么?
作为一个诙谐的解决方案,如果您只是想摆脱“ java.lang.OutOfMemoryError:GC开销限制超出”消息,将以下内容添加到您的启动脚本中即可实现:
-XX:-UseGCOverheadLimit我强烈建议不要使用这个选项——而不是解决问题,你只是推迟不可避免的问题:应用程序内存不足,需要修复。指定此选项只会用更熟悉的消息java.lang.OutOfMemoryError: Java heap space掩盖原始java.lang.OutOfMemoryError: GC 开销限制超出错误。
更严重的一点是 - 有时会触发 GC 开销限制错误,因为您分配给 JVM 的堆数量不足以满足在该 JVM 上运行的应用程序的需求。在这种情况下,你应该只分配更多的堆——请参阅本章末尾以了解如何实现这一点。
然而,在许多情况下,提供更多的 Java 堆空间并不能解决问题。例如,如果您的应用程序包含内存泄漏,添加更多堆只会推迟java.lang.OutOfMemoryError: Java heap space错误。此外,增加 Java 堆空间量也往往会增加影响应用程序吞吐量或延迟的GC 暂停时间。
如果您希望解决 Java 堆空间的潜在问题而不是掩盖症状,您需要弄清楚代码的哪一部分负责分配最多的内存。换句话说,您需要回答以下问题:
- 哪些对象占据堆的大部分
- 在源代码中分配这些对象的位置
此时,请确保在您的日历中清除几天(或 – 请参阅项目符号列表下方的自动方式)。以下是一个粗略的流程大纲,可以帮助您回答上述问题:
- 从您的 JVM-to-troubleshoot 获取获取堆转储的许可。“转储”基本上是您可以分析的堆内容的快照,并包含应用程序在转储时保留在内存中的所有内容。包括密码、信用卡号等。
- 指示您的 JVM 将其堆内存的内容转储到一个文件中。准备好进行一些转储,因为在错误的时间进行时,堆转储包含大量噪音,实际上可能毫无用处。另一方面,每个堆转储都会完全“冻结”JVM,所以不要太多,否则你的最终用户会开始发誓。
- 找到一台可以加载转储的机器。当您的 JVM-to-troubleshoot 使用例如 8GB 的堆时,您需要一台超过 8GB 的机器来分析堆内容。启动转储分析软件(我们推荐Eclipse MAT,但也有同样好的替代品)。
- 检测到最大堆消耗者的 GC 根的路径。我们已经覆盖在一个单独的后这一活动在这里。不用担心,一开始会觉得很麻烦,但经过几天的挖掘,你会好起来的。
- 接下来,您需要弄清楚在源代码中的何处分配了具有潜在危险的大量对象。如果您对应用程序的源代码有很好的了解,则希望通过几次搜索就能做到这一点。当您运气不佳时,您将需要一些能量饮料来辅助。
或者,我们建议Plumbr,这是唯一具有自动根本原因检测功能的 Java 监控解决方案。在其他性能问题中,它捕获所有java.lang.OutOfMemoryError并自动为您提供有关最需要内存的数据结构的信息。它负责在幕后收集必要的数据——这包括有关堆使用情况的相关数据(只有对象布局图,没有实际数据),以及一些您甚至在堆转储中都找不到的数据。它还会为您进行必要的数据处理——在 JVM 遇到java.lang.OutOfMemoryError 时立即进行。这是来自 Plumbr 的java.lang.OutOfMemoryError事件警报示例:
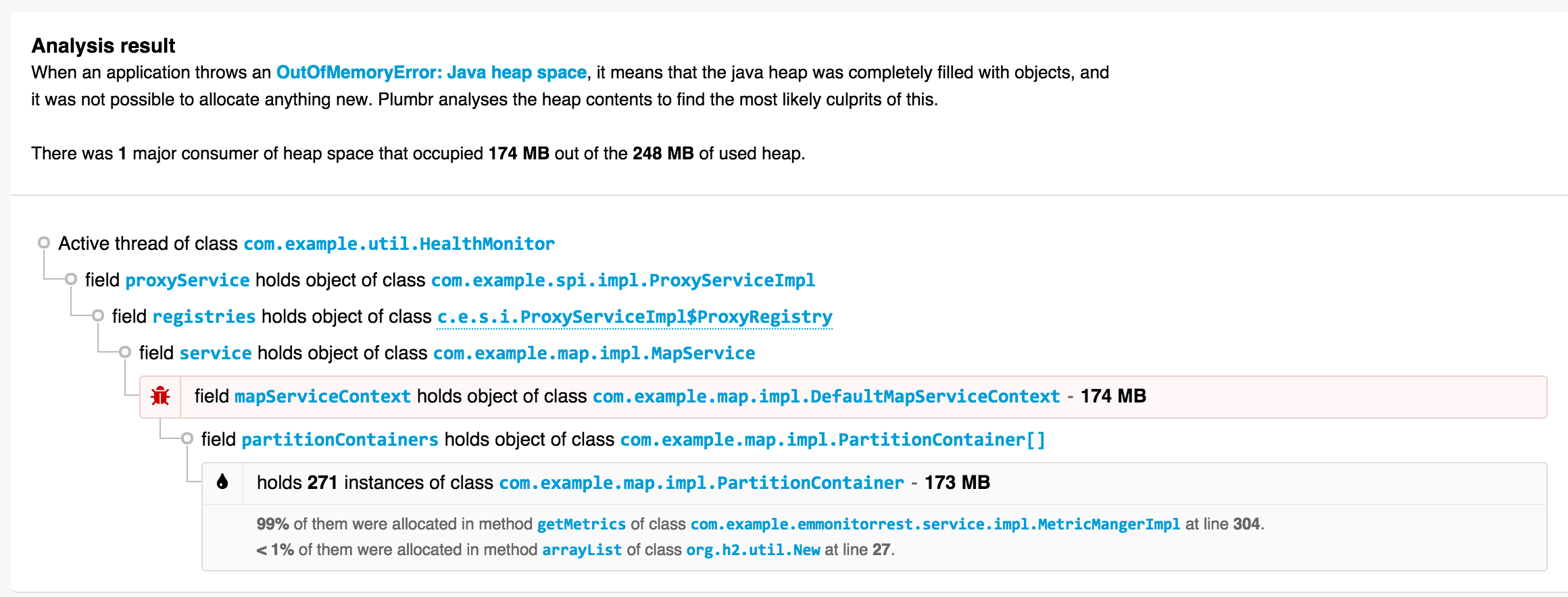
无需任何额外的工具或分析,您就可以看到:
- 哪些对象消耗的内存最多(271 个com.example.map.impl.PartitionContainer实例消耗了 248MB 总堆中的 173MB)
- 这些对象的分配位置(大部分分配在MetricManagerImpl类中,第 304 行)
- 当前引用这些对象的是什么(直到 GC 根的完整引用链)
有了这些信息,您就可以放大潜在的根本原因,并确保将数据结构修剪到适合您的内存池的级别。
但是,当您从内存分析或阅读 Plumbr 报告得出的结论是内存使用是合法的并且源代码中没有任何更改时,您需要让您的 JVM 有更多的 Java 堆空间才能正常运行。在这种情况下,更改您的 JVM 启动配置并在您的启动脚本中添加(或增加值,如果存在)仅一个参数:
java -Xmx1024m com.yourcompany.YourClass在上面的例子中,Java 进程被分配了 1GB 的堆。修改最适合您的 JVM 的值。但是,如果结果是您的 JVM 仍然因 OutOfMemoryError 而死亡,您可能仍然无法避免上述手动或 Plumbr 辅助分析。
原文链接:https://plumbr.io/outofmemoryerror/gc-overhead-limit-exceeded
导语
此文来自于plumbr官网,plumbr作为一个常用的JVM 监测工具,官网有完整的oom和gc文章,准备慢慢全部翻译过来:
第一篇:java.lang.OutOfMemoryError:Java heap space
第二篇:Java.lang.OutOfMemoryError: GC overhead limit exceeded
第三篇:java.lang.OutOfMemoryError: 永久空间
本文解读了永久空间问题,是什么造成了永久空间问题,3个解决永久空间问题的方法,大家可以查缺补漏,希望本文能对你有所帮助。
正文:
Java 应用程序只允许使用有限的内存量。您的特定应用程序可以使用的确切内存量是在应用程序启动期间指定的。为了让事情变得更复杂,Java 内存被分成不同的区域,如下图所示:

所有这些区域的大小,包括 permgen 区域,都是在 JVM 启动期间设置的。如果您不自己设置大小,将使用特定于平台的默认值。
该java.lang.OutOfMemoryError:PermGen space的消息表明永久代的内存区域被耗尽。
1,什么原因造成的?
要了解java.lang.OutOfMemoryError: PermGen space 的原因,我们需要了解此特定内存区域的用途。
出于实际目的,永久代主要由加载并存储到 PermGen 中的类声明组成。这包括类的名称和字段、带有方法字节码的方法、常量池信息、与类关联的对象数组和类型数组以及即时编译器优化。
从上面的定义中,您可以推断出永久代的大小要求取决于加载的类的数量以及此类声明的大小。因此,我们可以说java.lang.OutOfMemoryError: PermGen space 的主要原因是加载到永久代的类太多或类太大。
2,举个例子
如上所述,永久代空间的使用与加载到 JVM 中的类数量密切相关。下面的代码是最直接
导入 javassist.ClassPool;
public class MicroGenerator {
public static void main(String[] args) 抛出异常 {
for (int i = 0; i < 100_000_000; i++) {
generate("eu.plumbr.demo.Generated" + i);
}
}
public static Class generate(String name) throws Exception {
ClassPool pool = ClassPool.getDefault();
返回 pool.makeClass(name).toClass();
}
}在这个例子中,源代码遍历一个循环并在运行时生成类。javassist库负责处理类生成的复杂性。
启动上面的代码将继续生成新类并将它们的定义加载到永久空间中,直到空间被完全利用并抛出java.lang.OutOfMemoryError: Permgen 空间。
重新部署时间示例
对于更复杂和更现实的示例,让我们带您了解在应用程序重新部署期间发生的java.lang.OutOfMemoryError: Permgen space错误。当您重新部署应用程序时,您会期望垃圾回收将摆脱引用所有先前加载的类的先前类加载器,并将其替换为加载类的新版本的类加载器。
不幸的是,许多 3rd 方库和对资源(例如线程、JDBC 驱动程序或文件系统句柄)的处理不当使得无法卸载以前使用的类加载器。这反过来意味着在每次重新部署期间,您的类的所有先前版本仍将驻留在 PermGen 中,在每次重新部署期间生成数十兆字节的垃圾。
让我们想象一个使用 JDBC 驱动程序连接到关系数据库的示例应用程序。当应用程序启动时,初始化代码加载 JDBC 驱动程序以连接到数据库。对应于规范,JDBC 驱动程序使用java.sql.DriverManager注册自己。此注册包括在DriverManager的静态字段中存储对驱动程序实例的引用。
现在,当应用程序从应用程序服务器中卸载时,java.sql.DriverManager仍将保留该引用。我们最终获得了对驱动程序类的实时引用,该类又包含对用于加载应用程序的java.lang.Classloader实例的引用。这反过来意味着垃圾收集算法无法回收空间。
并且java.lang.ClassLoader 的那个实例仍然引用应用程序的所有类,通常在 PermGen 中占用数十兆字节。这意味着只需重新部署几次即可填充通常大小的 PermGen 并在日志中获取java.lang.OutOfMemoryError: PermGen space错误消息。
3,解决办法是什么?
1.解决初始化时OutOfMemoryError
当应用程序启动时触发由于 PermGen 耗尽导致的 OutOfMemoryError 时,解决方案很简单。应用程序只需要更多空间将所有类加载到 PermGen 区域,所以我们只需要增加它的大小。为此,请更改您的应用程序启动配置并添加(或增加(如果存在))类似于以下示例的-XX:MaxPermSize参数:
java -XX:MaxPermSize=512m com.yourcompany.YourClass上述配置将告诉 JVM,允许 PermGen 增长到 512MB,然后才能开始以 OutOfMemoryError 的形式抱怨。
2.解决重新部署时OutOfMemoryError
对于那些不能使用 Plumbr 或决定不使用的人,也可以使用替代方法。为此,您应该继续进行堆转储分析 - 在重新部署后使用类似于以下命令的命令进行堆转储:
jmap -dump:format=b,file=dump.hprof <process-id>然后使用您最喜欢的堆转储分析器打开转储(Eclipse MAT 是一个很好的工具)。在分析器中,您可以查找重复的类,尤其是那些加载应用程序类的类。从那里,您需要进入所有类加载器以找到当前活动的类加载器。
对于不活动的类加载器,您需要通过从不活动的类加载器获取到GC 根的最短路径来确定阻止它们被垃圾收集的引用。有了这些信息,您就会找到根本原因。如果根本原因在 3rd 方库中,您可以继续访问 Google/StackOverflow 以查看这是否是获取补丁/解决方法的已知问题。如果这是您自己的代码,则需要删除违规引用。
3.解决运行时OutOfMemoryError
对于那些再次无法使用 Plumbr 的人,也可以使用另一种方法。在这种情况下,第一步是检查是否允许 GC 从 PermGen 卸载类。标准的 JVM 在这方面相当保守——类天生就是为了永生。所以一旦加载,即使没有代码再使用它们,类也会留在内存中。当应用程序动态创建大量类并且长时间不需要生成的类时,这可能会成为一个问题。在这种情况下,允许 JVM 卸载类定义会很有帮助。这可以通过向启动脚本添加一个配置参数来实现:
-XX:+CMSClassUnloadingEnabled默认情况下,它设置为 false,因此要启用它,您需要在 Java 选项中显式设置以下选项。如果您启用CMSClassUnloadingEnabled,GC 也会清除PermGen 并删除不再使用的类。请记住,此选项仅在使用以下选项启用UseConcMarkSweepGC时才有效。因此,当运行ParallelGC或,上帝保佑,Serial GC 时,请确保您已通过指定将 GC 设置为CMS:
-XX:+UseConcMarkSweepGC在确保可以卸载类并且问题仍然存在后,您应该继续进行堆转储分析 - 使用类似于以下的命令进行堆转储:
jmap -dump:file=dump.hprof,format=b <process-id>然后使用您最喜欢的堆转储分析器(例如 Eclipse MAT)打开转储,并根据加载的类数量继续查找最昂贵的类加载器。从这样的类加载器中,您可以继续提取加载的类并按实例对此类类进行排序,以获得可疑的顶部列表。
对于每个嫌疑人,您需要手动将根本原因追溯到生成此类类的应用程序代码。
原文链接:https://plumbr.io/outofmemoryerror/permgen-space
导语
此文来自于plumbr官网,plumbr作为一个常用的JVM 监测工具,官网有完整的oom和gc文章,准备慢慢全部翻译过来:
Java OOM 基础篇:常见的OutOfMemoryError 场景一:Java heap space 堆溢出问题详解
Java OOM 基础篇:常见的OutOfMemoryError 场景二 : GC overhead limit exceeded 问题详解
Java OOM 基础篇:常见的OutOfMemoryError 场景三: PermGen space 永久空间问题详解
本篇详细的介绍了java下Permgen size 元空间问题以及如何解决这个问题,希望能对大家有所帮助。
正文:
Java 对程序可以分配的最大数组大小有限制。确切的限制是特定于平台的,但通常在 1 到 21 亿个元素之间。

当您遇到java.lang.OutOfMemoryError: Requested array size exceeded VM limit 时,这意味着因错误而崩溃的应用程序正在尝试分配大于 Java 虚拟机可以支持的数组。
1,造成的原因是什么?
该错误是由 JVM 中的本机代码引发的。当 JVM 执行特定于平台的检查时,它发生在为数组分配内存之前:分配的数据结构在此平台中是否可寻址。此错误并不像您最初想象的那么常见。
您很少遇到此错误的原因是 Java 数组由 int 索引。Java 中最大的正整数是 2^31 – 1 = 2,147,483,647。特定于平台的限制可能非常接近这个数字——例如,在我的 Java 1.7 上的 64 位 MB Pro 上,我可以愉快地初始化最多 2,147,483,645 或Integer.MAX_VALUE-2元素的数组。
将数组的长度增加 1 到 Integer.MAX_VALUE-1 会导致熟悉的OutOfMemoryError:
Exception in thread "main" java.lang.OutOfMemoryError: Requested array size exceeds VM limit
但是限制可能不会那么高——在带有 OpenJDK 6 的 32 位 Linux 上,当分配一个包含约 11 亿个元素的数组时,你会遇到“ java.lang.OutOfMemoryError:请求的数组大小超过 VM 限制”。要了解特定环境的限制,请运行下一章中描述的小测试程序。
2,举个例子
尝试重新创建java.lang.OutOfMemoryError: Requested array size exceeded VM limit错误时,我们看下面的代码:
for (int i = 3; i >= 0; i--) { try { int[] arr = new int[Integer.MAX_VALUE-i]; System.out.format("Successfully initialized an array with %,d elements.\n", Integer.MAX_VALUE-i); } catch (Throwable t) { t.printStackTrace(); } }
该示例迭代四次并在每一轮初始化一个长基元数组。此程序尝试初始化的数组大小随着每次迭代增加 1,最终达到 Integer.MAX_VALUE。现在,在使用 Hotspot 7 的 64 位 Mac OS X 上启动代码片段时,您应该获得类似于以下内容的输出:
java.lang.OutOfMemoryError: Java heap space at eu.plumbr.demo.ArraySize.main(ArraySize.java:8) java.lang.OutOfMemoryError: Java heap space at eu.plumbr.demo.ArraySize.main(ArraySize.java:8) java.lang.OutOfMemoryError: Requested array size exceeds VM limit at eu.plumbr.demo.ArraySize.main(ArraySize.java:8) java.lang.OutOfMemoryError: Requested array size exceeds VM limit at eu.plumbr.demo.ArraySize.main(ArraySize.java:8
请注意,在面对java.lang.OutOfMemoryError: 请求的数组大小在最后两次尝试中超出 VM 限制之前,分配失败并出现了很多更熟悉的java.lang.OutOfMemoryError: Java heap space消息。发生这种情况是因为您试图为 2^31-1 int 原语腾出空间需要 8G 内存,这小于 JVM 使用的默认值。
这个例子也说明了为什么这个错误如此罕见——为了看到 VM 对数组大小的限制被命中,你需要分配一个大小正好在平台限制和 Integer.MAX_INT 之间的数组。当我们的示例在带有 Hotspot 7 的 64 位 Mac OS X 上运行时,只有两个这样的数组长度:Integer.MAX_INT-1 和 Integer.MAX_INT。
3,解决办法是什么?
所述java.lang.OutOfMemoryError:请求阵列大小超过限制VM可以表现为任一下列情况的结果:
- 您的数组变得太大,最终大小介于平台限制和Integer.MAX_INT 之间
- 您故意尝试分配大于 2^31-1 个元素的数组来试验限制。
在第一种情况下,检查您的代码库,看看您是否真的需要那么大的数组。也许你可以减少数组的大小并完成它。或者将阵列分成更小的块,并批量加载您需要处理的数据以适应您的平台限制。
在第二种情况下——记住 Java 数组是由 int 索引的。因此,在平台内使用标准数据结构时,数组中的元素不能超过 2^31-1。实际上,在这种情况下,您已经被编译器在编译期间宣布“错误:整数太大”所阻止。
但是,如果您真的使用真正的大型数据集,则需要重新考虑您的选择。您可以小批量加载您需要处理的数据,并且仍然使用标准 Java 工具,或者您可以超越标准实用程序。实现此目的的一种方法是查看sun.misc.Unsafe类。这允许您像在 C 中一样直接分配内存。
原文链接:https://plumbr.io/outofmemoryerror/requested-array-size-exceeds-vm-limit
导语
堆溢出是应该是我们后端工程师日常经常遇到的问题,本篇用相对比较简单的过程写了一次堆溢出从测试发现到解决的过程,希望阅读本篇能对你有所帮助。
正文
以下是用于测试OOM的测试代码:
- public class HeapMemUseTest {
- public static void main(String[] args) {
- StringBuilder sb = new StringBuilder();
- while(true) {
- sb.append(System.currentTimeMillis());
- }
- }
- }
这段代码非常简单,其目的就是为了模拟OOM,将其编译后,通过以下命令运行:
- java -Xmx10m -Xms10m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./oom.out HeapMemUseTest
其中的参数代表的意义为:
-Xmx和-Xms分别是用于指定该Java进程初使化的最小堆内存以及可以使用的最大堆内存的,这里设置为10M
-XX:+HeapDumpOnOutOfMemoryError和-XX:HeapDumpPath参数分别用于指定发生OOM是否要导出堆以及导出堆的文件路径
该命令一执行,立即就会发生OOM,并打印如下的日志:
- fenglibin-HP:~/eclipse_neon_workspace/Test/bin$ java -Xmx10m -Xms10m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./oom.out HeapMemUseTest
- java.lang.OutOfMemoryError: Java heap space
- Dumping heap to ./oom.out ...
- Heap dump file created [5513523 bytes in 0.027 secs]
- Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
- at java.util.Arrays.copyOf(Arrays.java:3332)
- at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:124)
- at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:700)
- at java.lang.StringBuilder.append(StringBuilder.java:214)
- at HeapMemUseTest.main(HeapMemUseTest.java:13)
查看当前路径,oom.out文件已经生成了,该文件就是应用在发生OOM异常时自动导出的堆文件。那我们此时需要对该文件进行分析,因为其中记录了是什么对象导出了应用程OOM的发生。
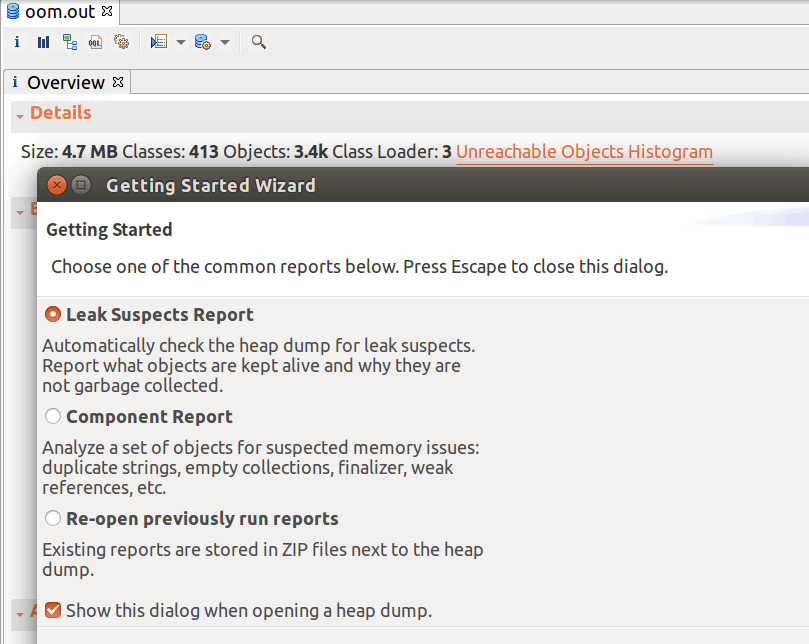
分析OOM的工具推荐使用MAT,在配置好Java环境的电脑中,直接打开即可,不需要安装,然后通过MAT打开已经生成的OOM文件oom.out,出现如下提示,选择“Leak Suspects Report”执行内存泄漏检查分析:
点击Finish按钮后,MAT会将可疑的内存泄漏的对象都展现出来:
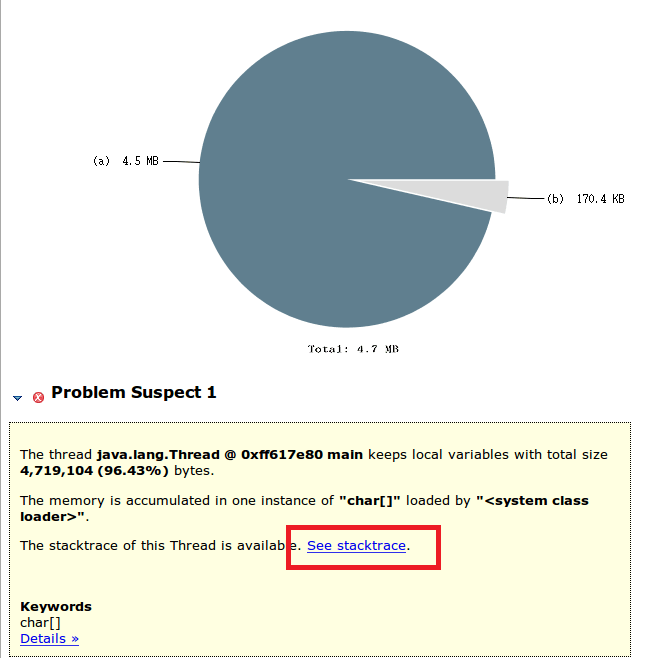
可以看到线程java.lang.Thread @ 0xff617e80 的main方法中,有一个本地变量占用了96.43%的堆内存,实际内存占用的是char[]数组,因而被检测出来为OOM可疑的元凶。点击红色框中的“See stacktrace”,可以直接看到该对象所在线程的堆栈信息:
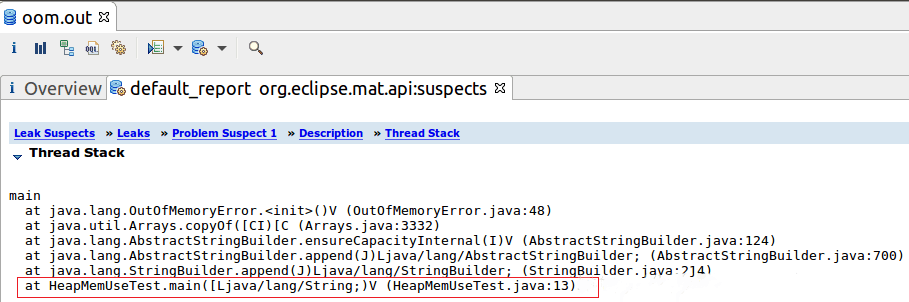
直接定位到了发生OOM的代码所在位置,至此该示例分析完成,MAT工具本身还有其它许多的功能,这里就不一一细说了。
导语
本篇是Java OOM的高级篇,文章从问题现象、问题排查、问题分析道原因探索都写的非常详细,很适合初中级后端工程师阅读,也很贴心的附上了排查代码,阅读完本篇相信大家对JAVA OOM的排查和解决能有质的跨越!
正文
问题现象
【告警通知-应用异常告警】

简单看下告警的信息:拒绝连接,反正就是服务有问题了,请不要太在意马赛克。
环境说明
Spring Cloud F版。
项目中默认使用 spring-cloud-sleuth-zipkin 依赖得到 zipkin-reporter。分析的版本发现是 zipkin-reporter版本是 2.7.3 。
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-sleuth-zipkin</artifactId>
- </dependency>
版本:2.0.0.RELEASE
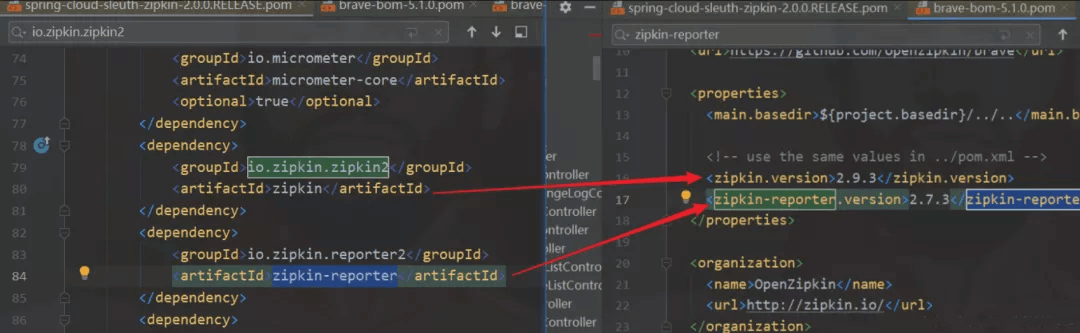
问题排查
通过告警信息,知道是哪一台服务器的哪个服务出现问题。首先登录服务器进行检查。
1、检查服务状态和验证健康检查URL是否ok
“这一步可忽略/跳过,与实际公司的的健康检查相关,不具有通用性。
- 查看服务的进程是否存在。
ps -ef | grep 服务名 ps -aux | grep 服务名
- 查看对应服务健康检查的地址是否正常,检查 ip port 是否正确
“是不是告警服务检查的url配置错了,一般这个不会出现问题
- 验证健康检查地址
“这个健康检查地址如:http://192.168.1.110:20606/serviceCheck 检查 IP 和 Port 是否正确。
- # 服务正常返回结果
- curl http://192.168.1.110:20606/serviceCheck
- {"appName":"test-app","status":"UP"}
- # 服务异常,服务挂掉
- curl http://192.168.1.110:20606/serviceCheck
- curl: (7) couldn't connect to host
2、查看服务的日志
查看服务的日志是否还在打印,是否有请求进来。查看发现服务OOM了。

tips:java.lang.OutOfMemoryError GC overhead limit exceeded
oracle官方给出了这个错误产生的原因和解决方法:Exception in thread thread_name: java.lang.OutOfMemoryError: GC Overhead limit exceeded Cause: The detail message “GC overhead limit exceeded” indicates that the garbage collector is running all the time and Java program is making very slow progress. After a garbage collection, if the Java process is spending more than approximately 98% of its time doing garbage collection and if it is recovering less than 2% of the heap and has been doing so far the last 5 (compile time constant) consecutive garbage collections, then a java.lang.OutOfMemoryError is thrown. This exception is typically thrown because the amount of live data barely fits into the Java heap having little free space for new allocations. Action: Increase the heap size. The java.lang.OutOfMemoryError exception for GC Overhead limit exceeded can be turned off with the command line flag -XX:-UseGCOverheadLimit.
原因:大概意思就是说,JVM花费了98%的时间进行垃圾回收,而只得到2%可用的内存,频繁的进行内存回收(最起码已经进行了5次连续的垃圾回收),JVM就会曝出ava.lang.OutOfMemoryError: GC overhead limit exceeded错误。

上面tips来源:java.lang.OutOfMemoryError GC overhead limit exceeded原因分析及解决方案
3、检查服务器资源占用状况
查询系统中各个进程的资源占用状况,使用 top 命令。查看出有一个进程为 11441 的进程 CPU 使用率达到300%,如下截图:

然后 查询这个进程下所有线程的CPU使用情况:
“top -H -p pid 保存文件:top -H -n 1 -p pid > /tmp/pid_top.txt
- # top -H -p 11441
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 11447 test 20 0 4776m 1.6g 13m R 92.4 20.3 74:54.19 java
- 11444 test 20 0 4776m 1.6g 13m R 91.8 20.3 74:52.53 java
- 11445 test 20 0 4776m 1.6g 13m R 91.8 20.3 74:50.14 java
- 11446 test 20 0 4776m 1.6g 13m R 91.4 20.3 74:53.97 java
- ....
查看 PID:11441 下面的线程,发现有几个线程占用cpu较高。
4、保存堆栈数据
- 打印系统负载快照
- top -b -n 2 > /tmp/top.txt
- top -H -n 1 -p pid > /tmp/pid_top.txt
- cpu升序打印进程对应线程列表
- ps -mp-o THREAD,tid,time | sort -k2r > /tmp/进程号_threads.txt
- 看tcp连接数 (最好多次采样)
- lsof -p 进程号 > /tmp/进程号_lsof.txt
- lsof -p 进程号 > /tmp/进程号_lsof2.txt
- 查看线程信息 (最好多次采样)
- jstack -l 进程号 > /tmp/进程号_jstack.txt
- jstack -l 进程号 > /tmp/进程号_jstack2.txt
- jstack -l 进程号 > /tmp/进程号_jstack3.txt
- 查看堆内存占用概况
- jmap -heap 进程号 > /tmp/进程号_jmap_heap.txt
- 查看堆中对象的统计信息
- jmap -histo 进程号 | head -n 100 > /tmp/进程号_jmap_histo.txt
- 查看GC统计信息
- jstat -gcutil 进程号 > /tmp/进程号_jstat_gc.txt
- 生产对堆快照Heap dump
- jmap -dump:format=b,file=/tmp/进程号_jmap_dump.hprof 进程号
堆的全部数据,生成的文件较大。
jmap -dump:live,format=b,file=/tmp/进程号_live_jmap_dump.hprof 进程号
dump:live,这个参数表示我们需要抓取目前在生命周期内的内存对象,也就是说GC收不走的对象,一般用这个就行。
拿到出现问题的快照数据,然后重启服务。
问题分析
根据上述的操作,已经获取了出现问题的服务的GC信息、线程堆栈、堆快照等数据。下面就进行分析,看问题到底出在哪里。
1、分析cpu占用100%的线程
转换线程ID
从jstack生成的线程堆栈进程分析。
将 上面线程ID 为
11447 :0x2cb7
11444 :0x2cb4
11445 :0x2cb5
11446 :0x2cb6
转为 16进制(jstack命令输出文件记录的线程ID是16进制)。
第一种转换方法 :
- $ printf “0x%x” 11447
- “0x2cb7”
第二种转换方法 : 在转换的结果加上 0x即可。
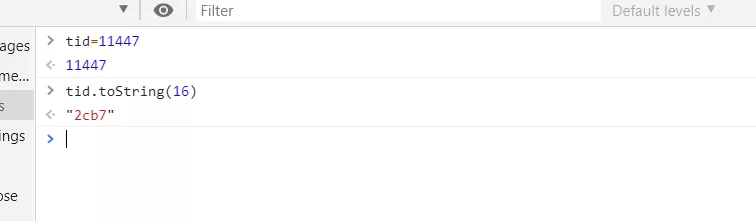
查找线程堆栈
- $ cat 11441_jstack.txt | grep "GC task thread"
- "GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007f971401e000 nid=0x2cb4 runnable
- "GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007f9714020000 nid=0x2cb5 runnable
- "GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007f9714022000 nid=0x2cb6 runnable
- "GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007f9714023800 nid=0x2cb7 runnable
发现这些线程都是在做GC操作。
2、分析生成的GC文件
- S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
- 0.00 0.00 100.00 99.94 90.56 87.86 875 9.307 3223 5313.139 5322.446
S0:幸存1区当前使用比例
S1:幸存2区当前使用比例
E:Eden Space(伊甸园)区使用比例
O:Old Gen(老年代)使用比例
M:元数据区使用比例
CCS:压缩使用比例
YGC:年轻代垃圾回收次数
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
FGC 十分频繁。
3、分析生成的堆快照
使用 Eclipse Memory Analyzer 工具。
分析的结果:
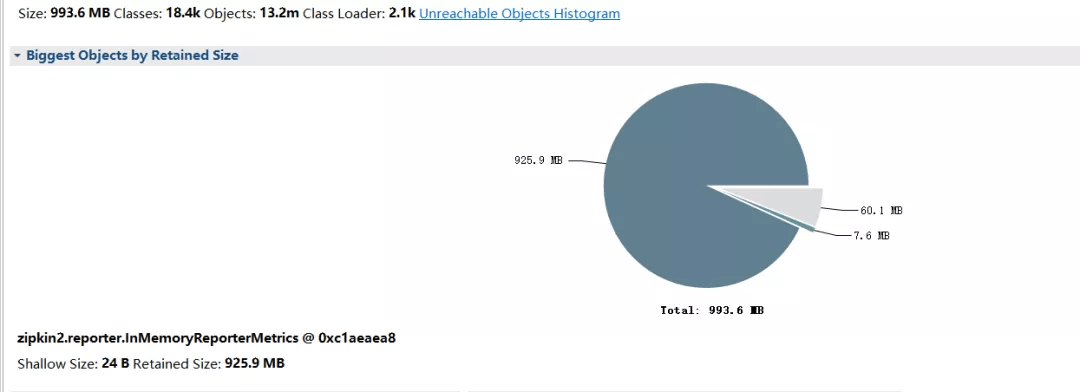
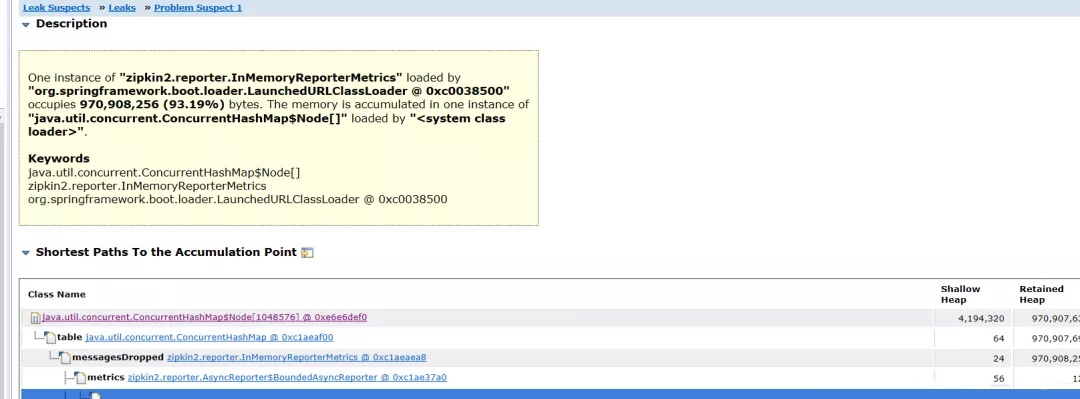
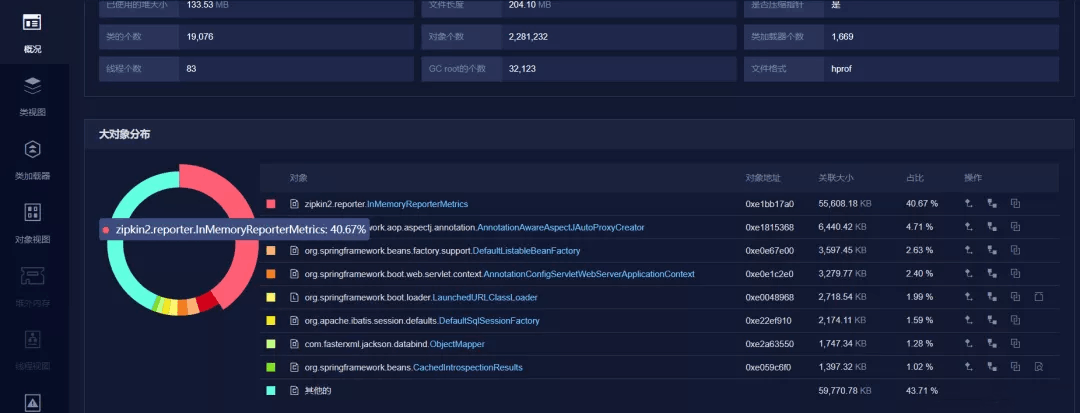
看到堆积的大对象的具体内容:
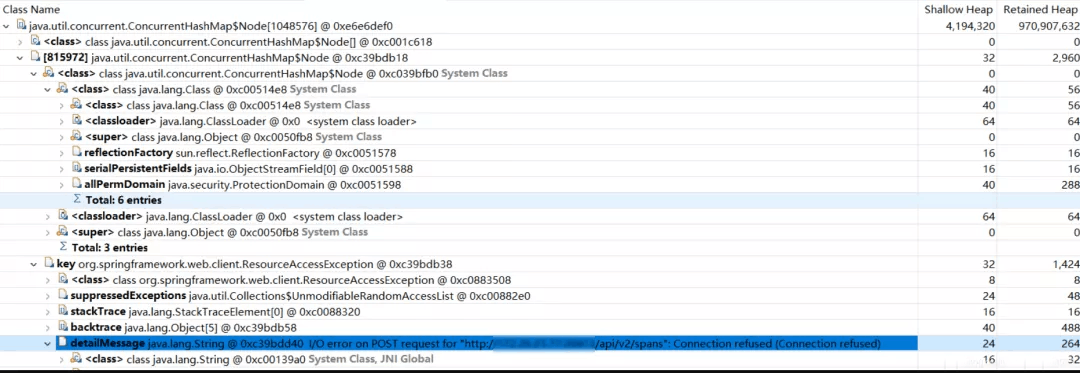
问题大致原因,InMemoryReporterMetrics 引起的OOM。
zipkin2.reporter.InMemoryReporterMetrics @ 0xc1aeaea8
Shallow Size: 24 B Retained Size: 925.9 MB
也可以使用:Java内存分析进行分析,如下截图。
4、原因分析和验证
因为出现了这个问题,查看出现问题的这个服务 zipkin的配置,和其他服务没有区别。发现配置都一样。
然后看在试着对应的 zipkin 的jar包,发现出现问题的这个服务依赖的 zipkin版本较低。
有问题的服务的 zipkin-reporter-2.7.3.jar
其他没有问题的服务 依赖的包 :zipkin-reporter-2.8.4.jar
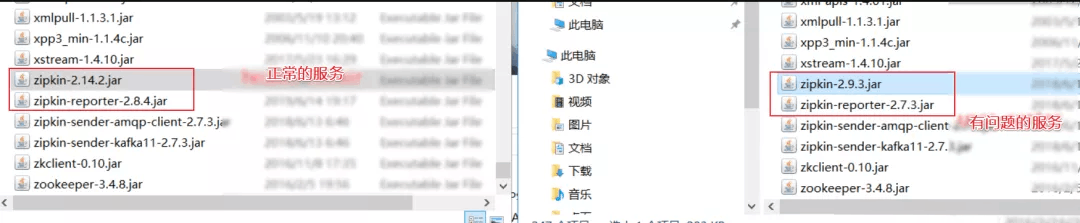
将有问题的服务依赖的包版本升级,在测试环境进行验证,查看堆栈快照发现没有此问题了。
原因探索
查 zipkin-reporter的 github:搜索 相应的资料
找到此 下面这个issues
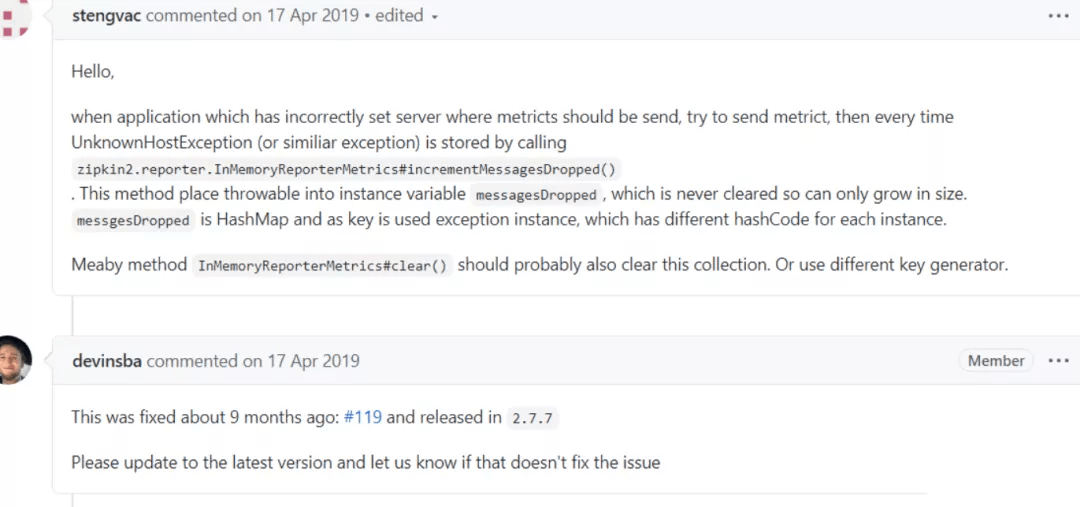
修复代码和验证代码
对比两个版本代码的差异:
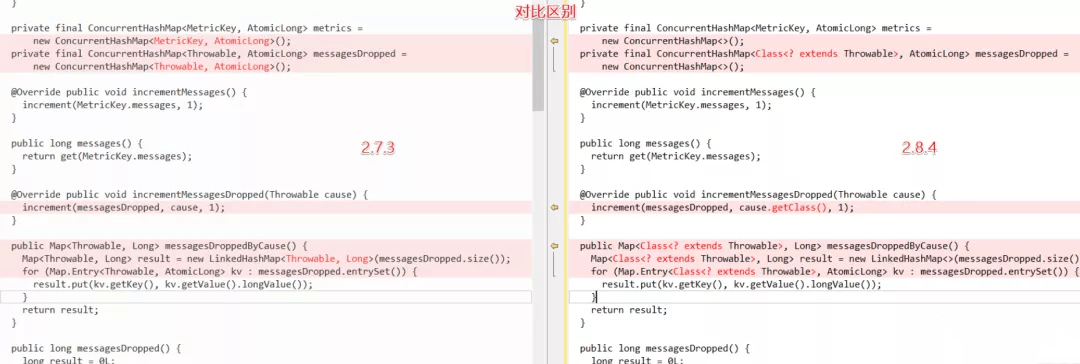
简单的DEMO验证:
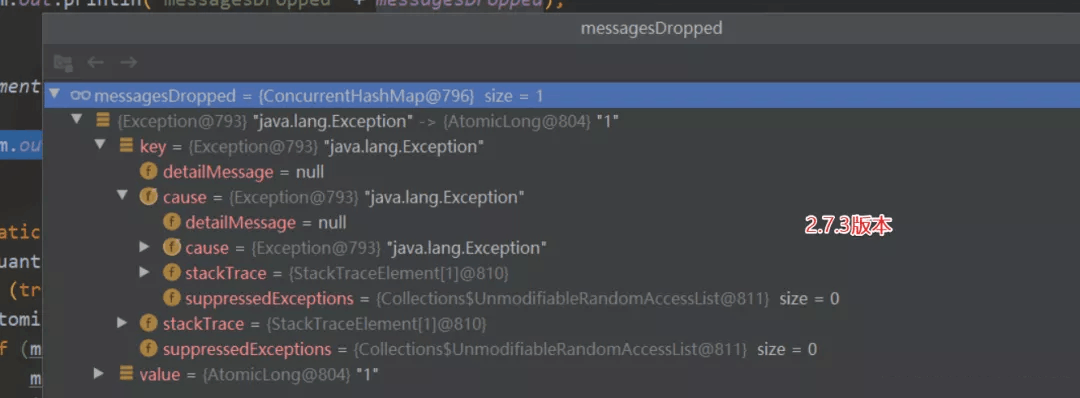
// 修复前的代码:
- private final ConcurrentHashMap<Throwable, AtomicLong> messagesDropped =
- new ConcurrentHashMap<Throwable, AtomicLong>();
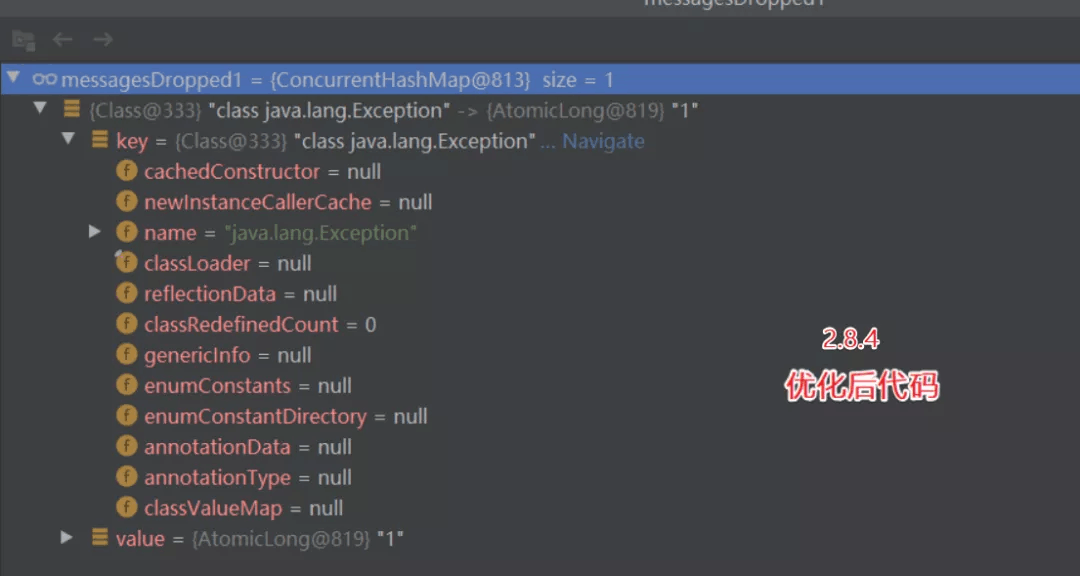
// 修复后的代码:
- private final ConcurrentHashMap<Class<? extends Throwable>, AtomicLong> messagesDropped =
- new ConcurrentHashMap<>();
修复后使用 这个key :Class<? extends Throwable> 替换 Throwable。
简单验证:
解决方案
将zipkin-reporter 版本进行升级即可。使用下面依赖配置,引入的 zipkin-reporter版本为 2.8.4 。
- <!-- zipkin 依赖包 -->
- <dependency>
- <groupId>io.zipkin.brave</groupId>
- <artifactId>brave</artifactId>
- <version>5.6.4</version>
- </dependency>
小建议:配置JVM参数的时候还是加上下面参数,设置内存溢出的时候输出堆栈快照.
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:HeapDumpPath=path/filename.hprof
导语
运维人员反馈一个容器化的java程序每跑一段时间就会出现OOM问题,重启后,间隔大概两天后复现。本篇就线上Docker上Springboot程序OOM问题来做一次详细的性能排查和性能优化,文章写的非常详细是一次非常优化的性能优化文章,希望能帮助到大家。
正文
问题调查
一、查日志
由于是容器化部署的程序,登上主机后使用docker logs ContainerId查看输出日志,并没有发现任何异常输出。使用docker stats查看容器使用的资源情况,分配了2G大小,目前使用率较低,也没有发现异常。

二、缺失的工具
打算进入容器内部一探究竟,先使用docker ps 找到java程序的ContainerId
,再执行docker exec -it ContainerId /bin/bash进入容器。进入后,本想着使用jmap、jstack 等JVM分析命令来诊断,结果发现命令都不存在,显示如下:
- bash: jstack: command not found
- bash: jmap: command not found
- bash: jps: command not found
- bash: jstat: command not found
突然意识到,可能打镜像的时候使用的是精简版的JDK,并没有这些jVM分析工具,但是这仍然不能阻止我们分析问题的脚步,此时docker cp命令就派上用场了,它的作用是:在容器和宿主机之间拷贝文件。这里使用的思路是:拷贝一个新的jdk到容器内部,目的是为了执行JVM分析命令,参照用法如下:
- Usage: docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH|-
- docker cp [OPTIONS] SRC_PATH|- CONTAINER:DEST_PATH [flags]
有了JVM工具,我们就可以开始分析咯。
三、查GC情况
通过jstat查看gc情况
- bin/jstat -gcutil 1 1s

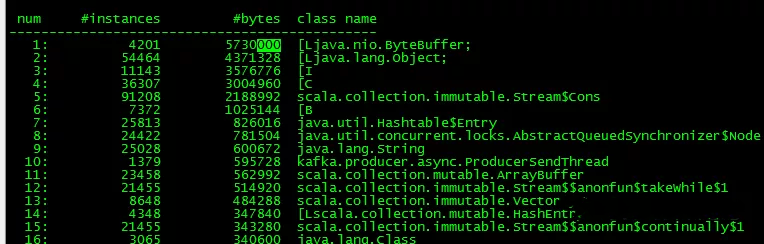
看样子没有什么问题,full gc也少。再看一下对象的占用情况,由于是容器内部,进程号为1,执行如下命令:
- bin/jmap -histo 1 |more
发现ByteBuffer对象占用最高,这是异常点一。
四、查线程快照情况
通过jstack查看线程快照情况。
- bin/jstack -l 1 > thread.txt
下载快照,这里推荐一个在线的线程快照分析网站。
- https://gceasy.io
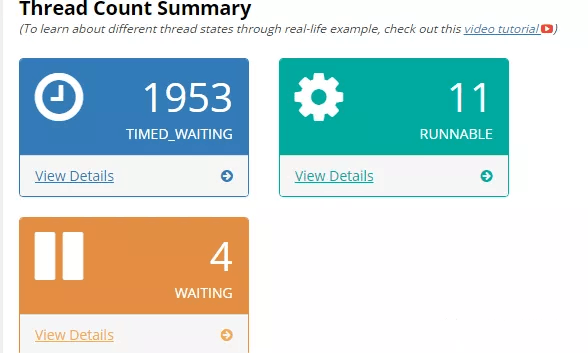
上传后,发现创建的线程近2000个,且大多是TIMED_WAITING状态。感觉逐渐接近真相了。点击详情发现有大量的kafka-producer-network-thread | producer-X 线程。如果是低版本则是大量的ProducerSendThread线程。(后续验证得知),可以看出这个是kafka生产者创建的线程,如下是生产者发送模型:
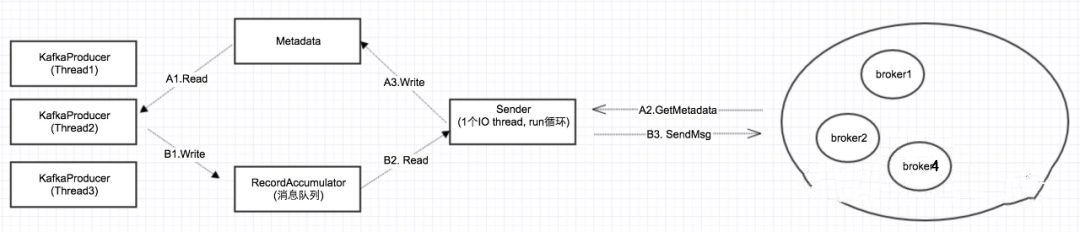
据生产者的发送模型,我们知道,这个sender线程主要做两个事,一是获取kafka集群的Metadata共享给多个生产者,二是把生产者送到本地消息队列中的数据,发送至远端集群。而本地消息队列底层的数据结构就是java NIO的ByteBuffer。
这里发现了异常点二:创建过多kafka生产者。
由于没有业务代码,决定写一个Demo程序来验证这个想法,定时2秒创建一个生产者对象,发送当前时间到kafka中,为了更好的观察,启动时指定jmx端口,使用jconsole来观察线程和内存情况,代码如下:
- nohup java -jar -Djava.rmi.server.hostname=ip
- -Dcom.sun.management.jmxremote.port=18099
- -Dcom.sun.management.jmxremote.rmi.port=18099
- -Dcom.sun.management.jmxremote.ssl=false
- -Dcom.sun.management.jmxremote.authenticate=false -jar
- com.hyq.kafkaMultipleProducer-1.0.0.jar 2>&1 &
连接jconsole后观察,发现线程数一直增长,使用内存也在逐渐增加,具体情况如下图:

故障原因回顾
分析到这里,基本确定了,应该是业务代码中循环创建Producer对象导致的。在kafka生产者发送模型中封装了 Java NIO中的 ByteBuffer 用来保存消息数据,ByteBuffer的创建是非常消耗资源的,尽管设计了BufferPool来复用,但也经不住每一条消息就创建一个buffer对象,这也就是为什么jmap显示ByteBuffer占用内存最多的原因。
总结
在日常的故障定位中,多多使用JDK自带的工具,来帮助我们辅助定位问题。一些其他的知识点:jmap -histo显示的对象含义:
[C 代表 char[]
[S 代表 short[]
[I 代表 int[]
[B 代表 byte[]
[[I 代表 int[][]如果导出的dump文件过大,可以将MAT上传至服务器,分析完毕后,下载分析报告查看,命令为:
- ./mat/ParseHeapDump.sh active.dump org.eclipse.mat.api:suspects
- org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
可能尽快触发Full GC的几种方式:
- System.gc();或者Runtime.getRuntime().gc();
- jmap -histo:live或者jmap -dump:live。
这个命令执行,JVM会先触发gc,然后再统计信息。 - 老生代内存不足的时候
Linux CPU使用率超过100%的原因
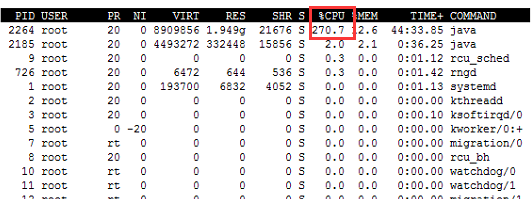
今天在服务器上部署流媒体做推流的时候使用top命令发现CPU占用率竟高达270%
在top模式下按1可看见CPU的数量是4
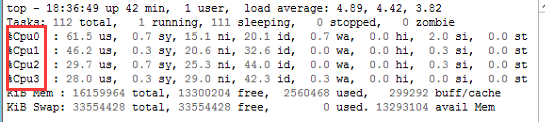
百度了一番发现原来top命令是按CPU总使用率来显示的,4核理论上最高可达400%
原文:https://www.cnblogs.com/duhuo/p/6065921.html
今天跑了一个非常耗时的批量插入操作。。通过top命令查看cpu以及内存的使用的时候,cpu的时候查过了120%。。以前没注意。。通过在top的情况下按大键盘的1,查看的cpu的核数为4核。

通过网上查找,发现top命令显示的是你的程序占用的cpu的总数,也就是说如果你是4核cpu那么cpu最高占用率可达400%,top里显示的是把所有使用率加起来。
这里我们也可以查看一下CPU信息:在命令行里输入:cat /proc/cpuinfo
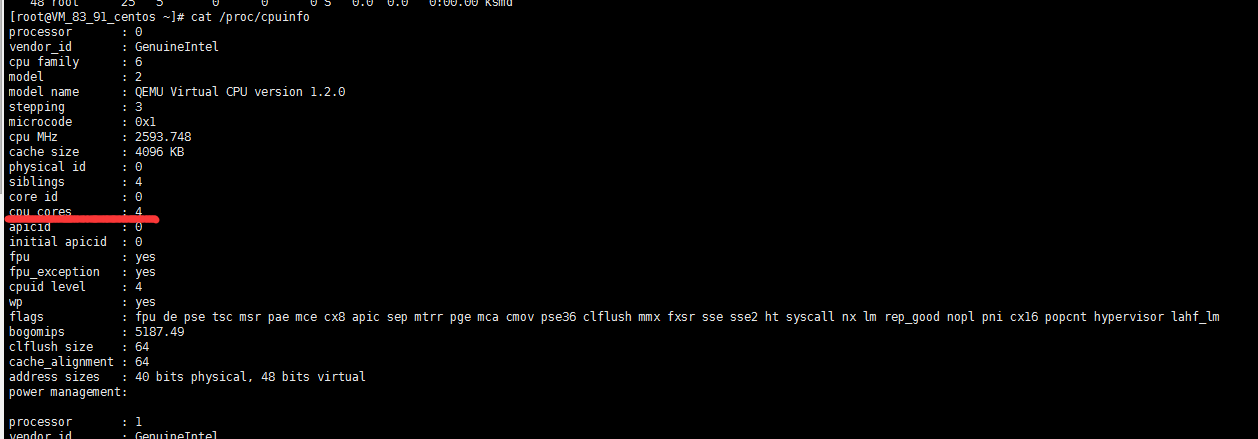
这里可以看到cpu cores : 4
转自:https://blog.csdn.net/guotao15285007494/article/details/84135713
https://www.cnblogs.com/duhuo/p/6065921.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号