Linux调优
10. vmstat 监视内存使用情况
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可实时动态监视操作系统的虚拟内存、进程、CPU活动。
10.1. vmstat的语法
vmstat [-V] [-n] [delay [count]]
- -V表示打印出版本信息;
- -n表示在周期性循环输出时,输出的头部信息仅显示一次;
- delay是两次输出之间的延迟时间;
- count是指按照这个时间间隔统计的次数。
/root$vmstat 5 5
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
6 0 0 27900472 204216 28188356 0 0 0 9 1 2 11 14 75 0 0
9 0 0 27900380 204228 28188360 0 0 0 13 33312 126221 22 20 58 0 0
2 0 0 27900340 204240 28188364 0 0 0 10 32755 125566 22 20 58 0 010.2. 字段说明
- Procs(进程):
-
- r: 运行队列中进程数量
- b: 等待IO的进程数量
- Memory(内存):
-
- swpd: 使用虚拟内存大小
- free: 可用内存大小
- buff: 用作缓冲的内存大小
- cache: 用作缓存的内存大小
- Swap:
-
- si: 每秒从交换区写到内存的大小
- so: 每秒写入交换区的内存大小
- IO:(现在的Linux版本块的大小为1024bytes)
-
- bi: 每秒读取的块数
- bo: 每秒写入的块数
- system:
-
- in: 每秒中断数,包括时钟中断
- cs: 每秒上下文切换数
- CPU(以百分比表示)
-
- us: 用户进程执行时间(user time)
- sy: 系统进程执行时间(system time)
- id: 空闲时间(包括IO等待时间)
- wa: 等待IO时间
11. iostat 监视I/O子系统
iostat是I/O statistics(输入/输出统计)的缩写,用来动态监视系统的磁盘操作活动。
11.1. 命令格式
iostat[参数][时间][次数]
11.2. 命令功能
通过iostat方便查看CPU、网卡、tty设备、磁盘、CD-ROM 等等设备的活动情况, 负载信息。
11.3. 命令参数
- -C 显示CPU使用情况
- -d 显示磁盘使用情况
- -k 以 KB 为单位显示
- -m 以 M 为单位显示
- -N 显示磁盘阵列(LVM) 信息
- -n 显示NFS 使用情况
- -p[磁盘] 显示磁盘和分区的情况
- -t 显示终端和CPU的信息
- -x 显示详细信息
- -V 显示版本信息
11.4. 工具实例
实例1:显示所有设备负载情况
/root$iostat
Linux 2.6.32-279.el6.x86_64 (colin) 07/16/2014 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
10.81 0.00 14.11 0.18 0.00 74.90
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 1.95 1.48 70.88 9145160 437100644
dm-0 3.08 0.55 24.34 3392770 150087080
dm-1 5.83 0.93 46.49 5714522 286724168
dm-2 0.01 0.00 0.05 23930 289288- cpu属性值说明:
-
- %user:CPU处在用户模式下的时间百分比。
- %nice:CPU处在带NICE值的用户模式下的时间百分比。
- %system:CPU处在系统模式下的时间百分比。
- %iowait:CPU等待输入输出完成时间的百分比。
- %steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
- %idle:CPU空闲时间百分比。
注:如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
- disk属性值说明:
-
- rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
- wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
- r/s: 每秒完成的读 I/O 设备次数。即 rio/s
- w/s: 每秒完成的写 I/O 设备次数。即 wio/s
- rsec/s: 每秒读扇区数。即 rsect/s
- wsec/s: 每秒写扇区数。即 wsect/s
- rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
- wkB/s: 每秒写K字节数。是 wsect/s 的一半。
- avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
- avgqu-sz: 平均I/O队列长度。
- await: 平均每次设备I/O操作的等待时间 (毫秒)。
- svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
- %util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
备注:如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。
实例2:定时显示所有信息
/root$iostat 2 3
Linux 2.6.32-279.el6.x86_64 (colin) 07/16/2014 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
10.81 0.00 14.11 0.18 0.00 74.90
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 1.95 1.48 70.88 9145160 437106156
dm-0 3.08 0.55 24.34 3392770 150088376
dm-1 5.83 0.93 46.49 5714522 286728384
dm-2 0.01 0.00 0.05 23930 289288
avg-cpu: %user %nice %system %iowait %steal %idle
22.62 0.00 19.67 0.26 0.00 57.46
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 2.50 0.00 28.00 0 56
dm-0 0.00 0.00 0.00 0 0
dm-1 3.50 0.00 28.00 0 56
dm-2 0.00 0.00 0.00 0 0
avg-cpu: %user %nice %system %iowait %steal %idle
22.69 0.00 19.62 0.00 0.00 57.69
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
dm-0 0.00 0.00 0.00 0 0
dm-1 0.00 0.00 0.00 0 0
dm-2 0.00 0.00 0.00 0 0说明:每隔 2秒刷新显示,且显示3次
实例3:查看TPS和吞吐量
/root$iostat -d -k 1 1
Linux 2.6.32-279.el6.x86_64 (colin) 07/16/2014 _x86_64_ (4 CPU)
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 1.95 0.74 35.44 4572712 218559410
dm-0 3.08 0.28 12.17 1696513 75045968
dm-1 5.83 0.46 23.25 2857265 143368744
dm-2 0.01 0.00 0.02 11965 144644- tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。
- kB_read/s:每秒从设备(drive expressed)读取的数据量;
- kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
- kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;
这些单位都为Kilobytes。
上面的例子中,我们可以看到磁盘sda以及它的各个分区的统计数据,当时统计的磁盘总TPS是1.95,下面是各个分区的TPS。(因为是瞬间值,所以总TPS并不严格等于各个分区TPS的总和)
实例4:查看设备使用率(%util)和响应时间(await)
/root$iostat -d -x -k 1 1
Linux 2.6.32-279.el6.x86_64 (colin) 07/16/2014 _x86_64_ (4 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.02 7.25 0.04 1.90 0.74 35.47 37.15 0.04 19.13 5.58 1.09
dm-0 0.00 0.00 0.04 3.05 0.28 12.18 8.07 0.65 209.01 1.11 0.34
dm-1 0.00 0.00 0.02 5.82 0.46 23.26 8.13 0.43 74.33 1.30 0.76
dm-2 0.00 0.00 0.00 0.01 0.00 0.02 8.00 0.00 5.41 3.28 0.00- rrqm/s: 每秒进行 merge 的读操作数目.即 delta(rmerge)/s
- wrqm/s: 每秒进行 merge 的写操作数目.即 delta(wmerge)/s
- r/s: 每秒完成的读 I/O 设备次数.即 delta(rio)/s
- w/s: 每秒完成的写 I/O 设备次数.即 delta(wio)/s
- rsec/s: 每秒读扇区数.即 delta(rsect)/s
- wsec/s: 每秒写扇区数.即 delta(wsect)/s
- rkB/s: 每秒读K字节数.是 rsect/s 的一半,因为每扇区大小为512字节.(需要计算)
- wkB/s: 每秒写K字节数.是 wsect/s 的一半.(需要计算)
- avgrq-sz:平均每次设备I/O操作的数据大小 (扇区).delta(rsect+wsect)/delta(rio+wio)
- avgqu-sz:平均I/O队列长度.即 delta(aveq)/s/1000 (因为aveq的单位为毫秒).
- await: 平均每次设备I/O操作的等待时间 (毫秒).即 delta(ruse+wuse)/delta(rio+wio)
- svctm: 平均每次设备I/O操作的服务时间 (毫秒).即 delta(use)/delta(rio+wio)
- %util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的,即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。 idle小于70% IO压力就较大了,一般读取速度有较多的wait。 同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)。
另外 await 的参数也要多和 svctm 来参考。差的过高就一定有 IO 的问题。
avgqu-sz 也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小。如果数据拿的大,才IO 的数据会高。也可以通过 avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s。也就是讲,读定速度是这个来决定的。
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
- 形象的比喻:
-
- r/s+w/s 类似于交款人的总数
- 平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
- 平均服务时间(svctm)类似于收银员的收款速度
- 平均等待时间(await)类似于平均每人的等待时间
- 平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
- I/O 操作率 (%util)类似于收款台前有人排队的时间比例
设备IO操作:总IO(io)/s = r/s(读) +w/s(写)
平均等待时间=单个I/O服务器时间*(1+2+...+请求总数-1)/请求总数
每秒发出的I/0请求很多,但是平均队列就4,表示这些请求比较均匀,大部分处理还是比较及时。
12. sar 找出系统瓶颈的利器
sar是System Activity Reporter(系统活动情况报告)的缩写。sar工具将对系统当前的状态进行取样,然后通过计算数据和比例来表达系统的当前运行状态。它的特点是可以连续对系统取样,获得大量的取样数据;取样数据和分析的结果都可以存入文件,所需的负载很小。sar是目前Linux上最为全面的系统性能分析工具之一,可以从14个大方面对系统的活动进行报告,包括文件的读写情况、系统调用的使用情况、串口、CPU效率、内存使用状况、进程活动及IPC有关的活动等,使用也是较为复杂。
sar是查看操作系统报告指标的各种工具中,最为普遍和方便的;它有两种用法;
- 追溯过去的统计数据(默认)
- 周期性的查看当前数据
12.1. 追溯过去的统计数据
默认情况下,sar从最近的0点0分开始显示数据;如果想继续查看一天前的报告;可以查看保存在/var/log/sysstat/下的sa日志; 使用sar工具查看:
$sar -f /var/log/sysstat/sa28 \| head sar -r -f
/var/log/sysstat/sa28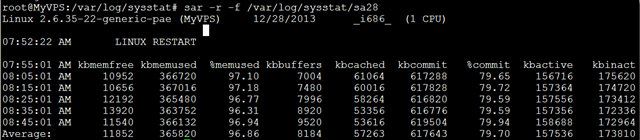
12.2. 查看CPU使用率
sar -u : 默认情况下显示的cpu使用率等信息就是sar -u;

可以看到这台机器使用了虚拟化技术,有相应的时间消耗; 各列的指标分别是:
- %user 用户模式下消耗的CPU时间的比例;
- %nice 通过nice改变了进程调度优先级的进程,在用户模式下消耗的CPU时间的比例
- %system 系统模式下消耗的CPU时间的比例;
- %iowait CPU等待磁盘I/O导致空闲状态消耗的时间比例;
- %steal 利用Xen等操作系统虚拟化技术,等待其它虚拟CPU计算占用的时间比例;
- %idle CPU空闲时间比例;
12.3. 查看平均负载
sar -q: 查看平均负载
指定-q后,就能查看运行队列中的进程数、系统上的进程大小、平均负载等;与其它命令相比,它能查看各项指标随时间变化的情况;
- runq-sz:运行队列的长度(等待运行的进程数)
- plist-sz:进程列表中进程(processes)和线程(threads)的数量
- ldavg-1:最后1分钟的系统平均负载 ldavg-5:过去5分钟的系统平均负载
- ldavg-15:过去15分钟的系统平均负载

12.4. 查看内存使用状况
sar -r: 指定-r之后,可查看物理内存使用状况;
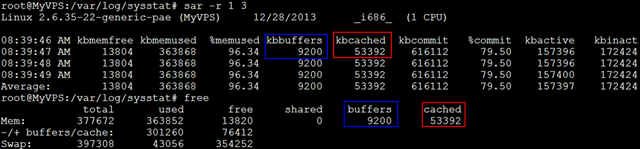
- kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间.
- kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间.
- %memused:物理内存使用率,这个值是kbmemused和内存总量(不包括swap)的一个百分比.
- kbbuffers和kbcached:这两个值就是free命令中的buffer和cache.
- kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
- %commit:这个值是kbcommit与内存总量(包括swap)的一个百分比.
12.5. 查看页面交换发生状况
sar -W:查看页面交换发生状况
页面发生交换时,服务器的吞吐量会大幅下降;服务器状况不良时,如果怀疑因为内存不足而导致了页面交换的发生,可以使用这个命令来确认是否发生了大量的交换;
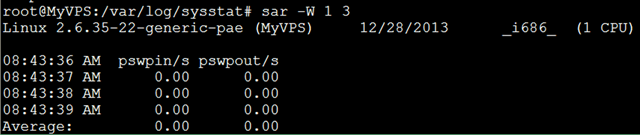
- pswpin/s:每秒系统换入的交换页面(swap page)数量
- pswpout/s:每秒系统换出的交换页面(swap page)数量
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来;
- 怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
- 怀疑内存存在瓶颈,可用sar -B、sar -r 和 sar -W 等来查看
- 怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
12.6. 安装
- 有的linux系统下,默认可能没有安装这个包,使用apt-get install sysstat 来安装;
- 安装完毕,将性能收集工具的开关打开: vi /etc/default/sysstat
设置 ENABLED=”true”
- 启动这个工具来收集系统性能数据: /etc/init.d/sysstat start
12.7. sar参数说明
- -A 汇总所有的报告
- -a 报告文件读写使用情况
- -B 报告附加的缓存的使用情况
- -b 报告缓存的使用情况
- -c 报告系统调用的使用情况
- -d 报告磁盘的使用情况
- -g 报告串口的使用情况
- -h 报告关于buffer使用的统计数据
- -m 报告IPC消息队列和信号量的使用情况
- -n 报告命名cache的使用情况
- -p 报告调页活动的使用情况
- -q 报告运行队列和交换队列的平均长度
- -R 报告进程的活动情况
- -r 报告没有使用的内存页面和硬盘块
- -u 报告CPU的利用率
- -v 报告进程、i节点、文件和锁表状态
- -w 报告系统交换活动状况
- -y 报告TTY设备活动状况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号