进程总是被killed--dmesg简介,【文件索引节点】,使用Java的G1GC的时候,偶尔会发生的bug
https://github.com/portainer/portainer/issues/1961
dmesg简介
dmesg’命令显示linux内核的环形缓冲区信息,我们可以从中获得诸如系统架构、cpu、挂载的硬件,RAM等多个运行级别的大量的系统信息。当计算机启动时,系统内核(操作系统的核心部分)将会被加载到内存中。在加载的过程中会显示很多的信息,在这些信息中我们可以看到内核检测硬件设备。
列出加载到内核中的所有驱动
我们可以使用如‘more’。 ‘tail’, ‘less ’或者‘grep’文字处理工具来处理‘dmesg’命令的输出。由于dmesg日志的输出不适合在一页中完全显示,因此我们使用管道(pipe)将其输出送到more或者less命令单页显示。
dmesg | more dmesg | less
列出所有被检测到的硬件
dmesg | grep sda
注解 ‘sda’表示第一块 SATA硬盘,‘sdb’表示第二块SATA硬盘。若想查看IDE硬盘搜索‘hda’或‘hdb’关键词。
只输出dmesg命令的前20行日志
dmesg | head -20
只输出dmesg命令最后20行日志
在‘dmesg’命令后跟随‘tail’命令(‘ dmesg | tail -20’)来输出‘dmesg’命令的最后20行日志,当你插入可移动设备时它是非常有用的。
dmesg | tail -20
搜索包含特定字符串的被检测到的硬件
由于‘dmesg’命令的输出实在太长了,在其中搜索某个特定的字符串是非常困难的。因此,有必要过滤出一些包含‘usb’ ‘dma’ ‘tty’ ‘memory’等字符串的日志行。grep 命令 的‘-i’选项表示忽略大小写。
dmesg | grep -i usb dmesg | grep -i dma dmesg | grep -i tty dmesg | grep -i memory
我们可以使用如下命令来清空dmesg的日志。该命令会清空dmesg环形缓冲区中的日志。但是你依然可以查看存储在‘/var/log/dmesg’文件中的日志。你连接任何的设备都会产生dmesg日志输出。
dmesg -c
实时监控dmesg日志输出
在某些发行版中可以使用命令‘tail -f /var/log/dmesg’来实时监控dmesg的日志输出。
watch "dmesg | tail -20"
参数说明
total-vm:31354724kB, anon-rss:30636060kB, file-rss:476kB, shmem-rss:0kB
- RSS代表“驻留集大小”,即当前在进程中为RAM分配的内存量。
- anon-rss值为30636060kBkB.
- file-rss是交换文件中对于该系统中所有进程为0KB的内存量。
查看信息:
可以输出最近killed的信息。

dmesg | egrep -i -B100 'killed process' ## 或: egrep -i 'killed process' /var/log/messages egrep -i -r 'killed process' /var/log ## 或: journalctl -xb | egrep -i 'killed process'
时间戳转时间
dmesg -T | head -10
设定kill优先度:
(1)完全关掉oom(不建议):
sysctl vm.overcommit_memory=2 echo “vm.overcommit_memory=2” >> /etc/sysctl.conf
(2)出现 Out of memory之后重启:
sysctl vm.panic_on_oom=1 sysctl kernel.panic=X echo “vm.panic_on_oom=1” >> /etc/sysctl.conf echo “kernel.panic=X” >> /etc/sysctl.conf
(3)优先考虑kill这个进程:
sudo echo 10>/proc/[PID]/oom_adj
(4)尽量不去kill这个进程:
sudo echo -15>/proc/[PID]/oom_adj
(5)不会kill这个进程:
sudo echo -17>/proc/[PID]/oom_adj
oom_adj的值在-16 到 +15之间,值越高被kill的优先度越高。当该值为-17时,系统将不会杀死指定pid的进程,而-16~15则会使得进程的/proc/[pid]/oom_adj值呈指数()形式递增,即它们被杀掉的可能性呈指数递增。针对init(进程号为1)这个进程,无论该值设为多少都不会被杀。
3.若拒绝访问:
命令改为:
bash -c "echo '10' | tee /proc/[PID]/oom_adj" bash -c "echo '-15' | tee /proc/[PID]/oom_adj" bash -c "echo '-17' | tee /proc/[PID]/oom_adj"
centos系统内存 buff/cache 占用过高
情况说明: centos系统,buff/cache占用过高,导致服务器内存居高不下,但是通过top查看系统进程并无过多占用内存
实际情况: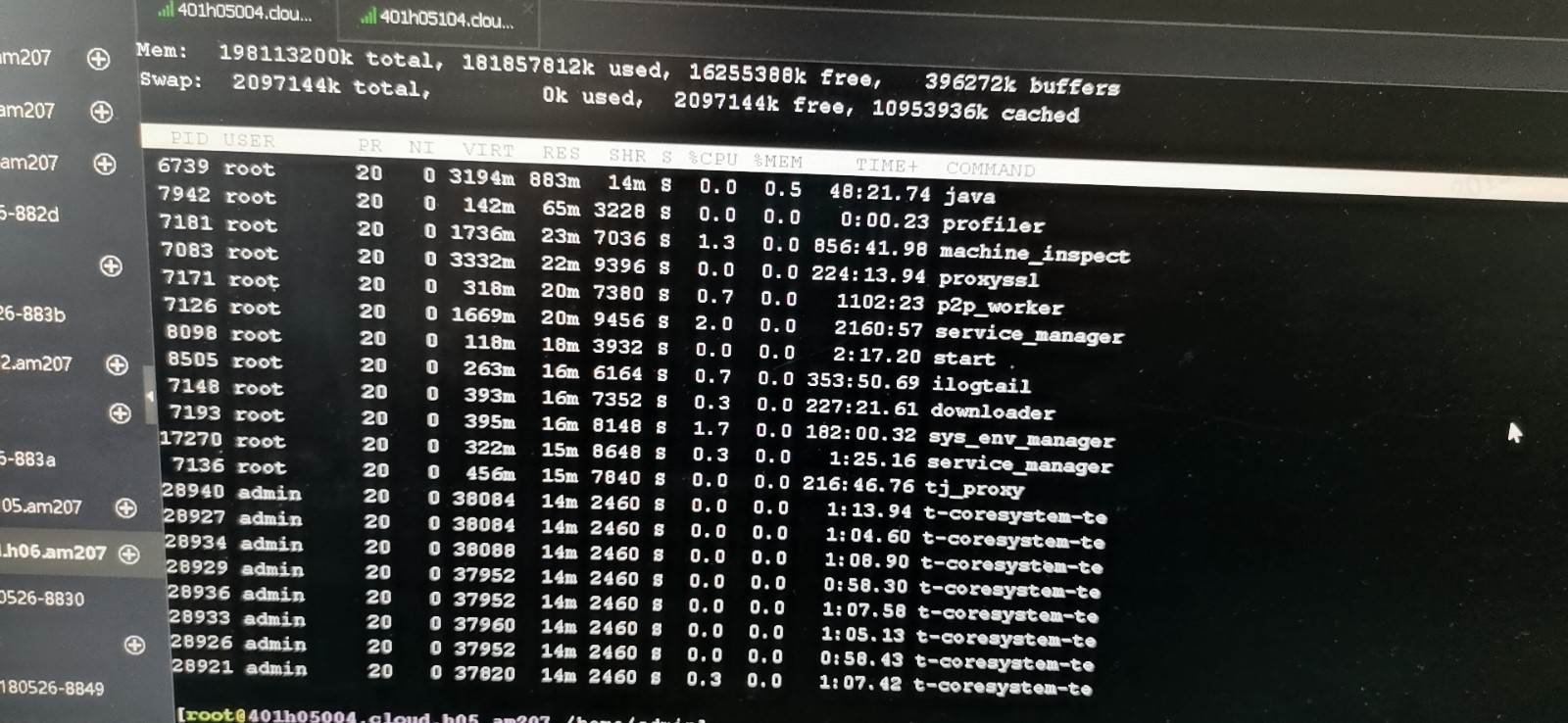
处理步骤:
1.执行sync命令;
sync
2.执行释放内存命令:
echo 3 > /proc/sys/vm/drop_caches
命令解释:
sync 指令会将存于 buffer 中的资料强制写入硬盘中。 echo 1 > /proc/sys/vm/drop_caches:表示清除pagecache。 echo 2 > /proc/sys/vm/drop_caches:表示清除回收slab分配器中的对象(包括目录项缓存和inode缓存)。 echo 3 > /proc/sys/vm/drop_caches:表示清除pagecache和slab分配器中的缓存对象。
原文地址:https://blog.51cto.com/liujingyu/2448135,作者:刘景宇
参考地址:
linux 程序被Killed,查看原因:https://blog.csdn.net/zbzcDZF/article/details/90488442
Linux系统中‘dmesg’命令处理故障和收集系统信息的7种用法: https://linux.cn/article-3587-1.html
Linux文件索引节点相关概念
一. 概念
1. inode(index node)表中包含文件系统所有文件列表
一个节点 (索引节点)是在一个表项,包含有关文件的信息( 元数据 ),包括:
-
文件类型,权限,UID,GID
-
链接数(指向这个文件名路径名称个数)
-
该文件的大小和不同的时间戳
-
指向磁盘上文件的数据块指针
-
有关文件的其他数据
-
inode 索引节点编号
2. inode 表结构

3. inode号
系统中将目录下的文件名和文件inode号之间的映射作为目录的数据存放;人们通过文件名进行操作时,系统会通过对应路径目录的inode号找到目录的inode表数据,进而通过数据指针指向目录的数据,匹配文件名,得到文件的inode号;再到inode表中找到此文件的表项,再由文件数据指针指向真正的文件数据。
i. 系统中同一分区的索引节点编号是唯一的,即在一个分区中,索引编号相同的文件指向的数据是同一个;(硬链接)
ii. 系统中每个分区的索引节点划分是独立的,不同分区的索引节点编号可能相同,但不是同一个文件;
iii. 分区中的索引节点编号是有限的;当分区中索引节点编号用完后,新建文件夹会提示系统内存不足,导致新建失败;但系统中仍有剩余磁盘空间,原因是索引节点编号不足,无法为文件分配节点编号,因而新建失败。
ls -i 查看文件节点编号
df -i 查看分区节点编号使用情况
echo file{1..500000} |xargs touch 批量新建大量文件;参数过多,touch无法直接创建
echo file{1..500000} |xargs rm 批量删除大量文件;参数过多,rm无法直接删除

4. 文件操作与inode的关系
二 . 软连接与硬链接
1. 硬链接
创建方式: ln filename filename2
2. 软连接
1. 创建方式: ln -s file_path file_link file_path :原文件绝对路径或原文件相对与 file_link 的相对路径, 推荐使用相对路径,可移植性强
2. readlink file_link 读取软连接原始文件路径
3. 软连接指向新文件
rm -f file_link 删除原软连接
ln -s newfile_path file_link 创建新软连接
PS:下面的讲解,基于Linux/Unix
索引节点,其英文为 Inode,是 Index Node 的缩写。
存储于文件系统上的任何文件都可以用索引节点来表示。
文件系统主要分为两部分,一部分为元数据(metadata),另一部分为数据本身。元数据,是“包含了与数据有关信息的数据”。索引节点就管理着文件系统中元数据的部分。
文件系统中的任何一个文件或目录都与一个索引节点相对应。每个索引节点都是一个数据结构,存储着目标数据的如下信息:
文件大小(以字节为单位)
( 存放文件的)设备标识符
(文件所有者的)用户标识符
用户组标识符
文件模式(所有者、用户组及其他人对于文件的读取有怎样的权限)
扩展属性(如 ACL)
文件读取或修改的时间戳
链接数量(指向该文件的硬链接数,记住,软链接不计算在内)
指向存储该内容的磁盘区块的指针
文件分类(是普通文件、目录还是特殊区块设备)
文件占用的区块数量
Linux 文件系统从来不存储文件创建时间。
一个典型的索引数据看起来会是像下面这样:
# stat 01
Size:7845633Blocks:1786IO Block:4096regular file
Device:803h/2051dInode:12684895Links:1
Access:(0644/-rw-r--r--)Uid:(0/root)Gid:(0/root)
Access:2017-09-0701:46:54.000000000-0500
Modify:2017-04-2706:22:02.000000000-0500
Change:2017-04-2706:22:02.000000000-0500
索引节点的创建与正在使用的文件系统有关。一些文件系统在创建时就创建了索引节点,故其索引节点的数量有限。而一些如 JFS 和 XFS 等系统也在文件系统创建时创建索引节点,但使用动态节点分配,并按需扩大索引节点的数量,因此可以避免所有索引节点用完的情况。
当用户试图读取文件或与该文件相关的信息时,他会使用文件名称。但是,实质上这个文件名称首先映射为存储于目录表中的索引点节号码。通过该索引节点号码读取到相对应的索引节点。
索引节点号码及相对应的索引节点存放于映射表(Inode table)中。
索引节点只存储元数据信息,其中包括真正的数据存储的区块的信息。
大多数文件系统会以 15个指针的形式来存储数据结构。这 15个指针包括:
直接指向文件数据区块的 12个指针,称为直接指针(direct pointer)。
一个单独非直接指针(singly indirect pointer),指向一个由多个指针构成的区块,后者的指针又指向文件数据区块。
一个双重非直接指针(doubly indirect pointer),指向一个由多个指针构成的区块,后者的指针又指向一个由多个指针构成的区块,这一区块的指针又指向文件数据的区块。
一个三重非直接指针(triply indirect pointer),指向一个由多个指针构成的区块,后者的指针又指向一个由多个指针构成的区块,其指针又指向另一个由多个指针构成的区块,这一区块的指针又指向文件数据的区块。

客户发生的一个问题,正常使用的Tomcat服务,会再突然之前发生Tomcat停止的问题。
发生问题的时候,Tomcat的catalina.out里面,有下面的类似Error Log。
#
# A fatal error has been detected by the Java Runtime Environment:
#
# SIGSEGV (0xb) at pc=0x00007f85942f6e76, pid=1887, tid=0x00007f8592efa700
#
# JRE version: Java(TM) SE Runtime Environment (8.0_181-b13) (build 1.8.0_181-b13)
# Java VM: Java HotSpot(TM) 64-Bit Server VM (25.181-b13 mixed mode linux-amd64 compressed oops)
# Problematic frame:
# V [libjvm.so+0x5cae76] G1ParScanThreadState::copy_to_survivor_space(InCSetState, oopDesc*, markOopDesc*)+0x196
#
# Failed to write core dump. Core dumps have been disabled. To enable core dumping, try "ulimit -c unlimited" before starting Java again
#
# An error report file with more information is saved as:
# /tmp/hs_err_pid1887.log
[thread 140211673609984 also had an error]
#
# If you would like to submit a bug report, please visit:
# http://bugreport.java.com/bugreport/crash.jsp
#我先是调查了一下我们写的代码和log文件,没发现任何问题。
Google了一下,感觉上时Java本身的Bug的可能性很高。
下面时检索到的,一些类似问题,其实很多人登录过,不过都没有解决。(2018/10时点)
- https://bugs.java.com/bugdatabase/view_bug.do?bug_id=8179505
- https://bugs.java.com/bugdatabase/view_bug.do?bug_id=8163536
- https://www.oracle.com/search/results?Ntt=G1ParScanThreadState%3A%3Acopy_to_survivor_space&Dy=1&Nty=1&cat=bugs&Ntk=S3
回答内容简单总结一下,
This kind of issues can be caused by any bug that corrupts heap memory.
It could be an issue with GC, with the compiler, with bad native code,
If you have strong reproducer kindly share with us. We will reproduce at our end and try to fix the issue.继续Google,发现下面的一个博客,貌似跟G1GC有关系。
我们可客户的JVM设定,的确时用了G1GC。
-Xmx6144M -Xms6144M -Xss1024k -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Xloggc:/opt/jakarta-tomcat/logs/gc_%p_%t.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+DisableExplicitGC -XX:+DoEscapeAnalysis -XX:MaxGCPauseMillis=50 -XX:-OptimizeStringConcat -XX:+PrintClassHistogramAfterFullGC -XX:+PrintClassHistogramBeforeFullGC -XX:+UseCompressedOops -XX:+UseG1GC总结来说,出现类似的问题,应该时Java本身Bug的可能性非常高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号