C/C++中的.h和.c文件,C语言文件指针偏移的使用(点阵字库txt文件取字)
编译器的工作过程
涉及到的函数、结构体、变量等比较多。通常,编写c/c++项目的方式是,有一个main.c文件,该文件的main函数作为接口,调用其他函数。所有其他函数按功能,分别放在不同的.h文件中,这样的方式在编译和运行上肯定是没有什么问题的。
随着项目编写的深入,结构、逻辑以及变量的日趋复杂,总感觉上述方式的实现仍然不够清晰并且会导致一些冗余。忽然记起,在课堂上,老师提到过,.h文件一般用来存放函数声明和变量名,那么为什么我在.h文件中实现函数不会有问题呢?其他.c文件和main.c文件又有什么关系呢?这些,都使我不得不重新思考.h文件和.c文件的作用和关系。
.h文件的由来和弊端
要理清.h文件的作用,我们不妨看看.h文件的由来:
“在编译器只认识.c(.cpp))文件,而不知道.h是何物的年代,那时的人们写了很多的.c(.cpp)文件,渐渐地,人们发现在很多.c(.cpp)文件中的声明语句就是相同的,但他们却不得不一个字一个字地重复地将这些内容敲入每个.c(.cpp)文件。但更为恐怖的是,当其中一个声明有变更时,就需要检查所有的.c(.cpp)文件。
于是人们将重复的部分提取出来,放在一个新文件里,然后在需要的.c(.cpp)文件中敲入#include XXXX这样的语句。这样即使某个声明发生了变更,也再不需要到处寻找与修改了。因为这个新文件,经常被放在.c(.cpp)文件的头部,所以就给它起名叫做“头文件”,扩展名是.h。
在我们语言的初学阶段,往往我们的程序只有一个.c的文件或这很少的几个,这时我们就很少遇到头文件组织这个头疼的问题,随着我们程序的增加,代码 量到了几千行甚至几万行,文件数也越来越多。这时这些文件的组织就成了一个问题,其实说白了这些文件的组织问题从理论上来说是软件工程中的模块设计等等的问题。”(引自c语言项目中.h文件和.c文件的关系)
由上可以看出,.h文件最初就是用来给变量和函数提供一些全局性的声明,这些声明被其他.c文件共享,方便变量和声明的修改,使得大型代码逻辑更清晰更易于维护。因此.h文件中一般是声明,很少有代码的具体实现。
- h文件在编译原理
那么为什么在.h文件中实现函数也不会出错呢?在.h文件中实现函数与在.c文件中实现函数有什么区别和联系呢?普通的.C文件和包含main函数的c文件有什么区别和联系呢?
要解决上述问题,首先必须弄清编译器的工作原理。编译器的最终目的是将程序员编写的源代码转换成机器能够识别运行的二进制机器码。大体上分,可以分为4个步骤:
1.头文件的预编译,预处理
编译器在编译源代码时,会先编译头文件,保证每个头文件只被编译一次。
在预处理阶段,编译器将c文件中引用的头文件中的内容全部写到c文件中。
2.词法和语法分析(查错)
3.编译(汇编代码,.obj文件)
转化为汇编码,这种文件称为目标文件。后缀为.obj。
4.链接(二进制机器码,.exe文件)
将汇编代码转换为机器码,生成可执行文件。
更详细具体的流程可参考编译器的工作过程
在编译过程中,.h文件中的所有内容会被写到包含它的.c文件中,而所有的.c文件以一个共同的main函数作为可执行程序的入口。
因此,在.h文件中编写函数实现并不会出错,相当于所有.h的内容最后都被写到了main.c文件中。
但是为了逻辑性、易于维护性以及一些其他目的(可参考c语言中.h文件和.c文件的解析),一般在.h文件中写函数的声明,在.c文件中编写函数的实现。
C语言文件指针偏移的使用(点阵字库txt文件取字)
一、导言
C语言中文件读写也是相当重要的一块,在进行二进制文件逐字节读写时,使用C语言会异常好用。文件指针也是个让人抓脑袋的东西,移动文件指针的函数利用好可以有大作用。
二、操作
- 文件
文件结构体定义在 stdio.h 头文件中,使用fopen打开文件后会存储一些相关数据在结构体中。
typedef struct
{
short level;
unsigned flags;
char fd;
unsigned char hold;
short bsize;
unsigned char *buffer;
unsigned ar *curp;
unsigned istemp;
short token;
}FILE;
- 文件指针操作
文件指针操作主要有以下几个函数,在进行地址偏移计算时用得到。
void rewind(FILE *stream); - 设置文件位置为给定流 stream 的文件的开头。
long int ftell(FILE *stream); - 返回给定流 stream 的当前文件位置。
int fseek(FILE *stream, long int offset, int whence); - 设置流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 whence 位置查找的字节数。
三、实战
目标:从点阵字库LiShu56.txt文件中提取某一个汉字。
实现思路:通过汉字的gb2312机内码直接定位到文件中的该汉字起始位置,然后进行循环读写复制。
上图即该文件中的格式,为图方便,我直接使用二进制文件查看器,定义了几个基本的偏移量。
#define OFFSET_BASE 98 // 文件首基准位置
#define OFFSET_WORD 3666 // 这是点阵字库中每个字的整体字节量
#define OFFSET_INNER 13 // 这是单个字内部起始到实际字的数据的位置的偏移量
因为该字库文件中收录的字并不是直接从 a1a1 连续到 f7fe 的,所以不能够直接求偏移量然后直接偏移,否则使用 fseek 偏移超过文件指针允许的范围,程序将会陷入卡死(或死循环)的状态。
以下为算法流程图: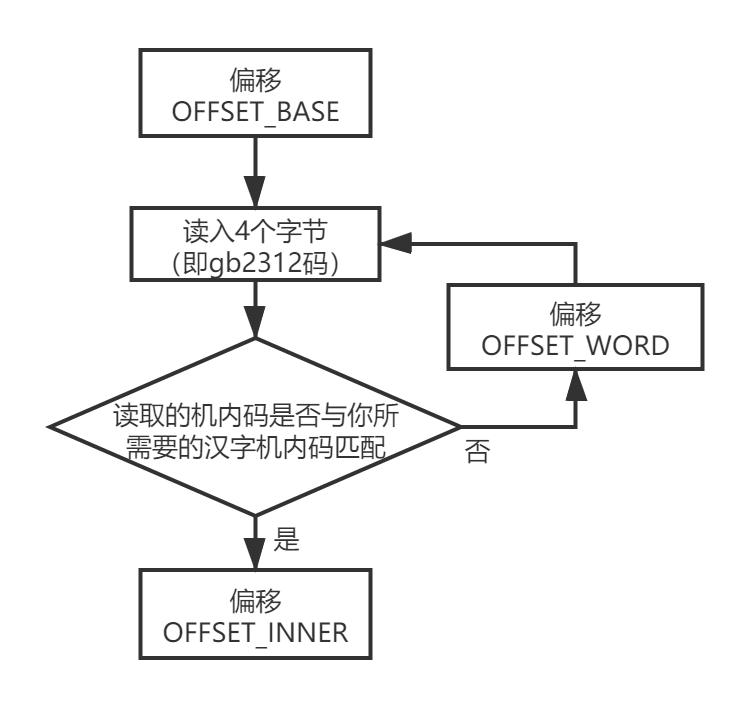
注释:
- OFFSET_BASE 是从文件首到能够读取第一个(CurCode后)gb2312码的位置的偏移量。
- OFFSET_WORD 是读完这一gb2312码后到下一个字能够读取gb2312码的位置的偏移量。
- OFFSET_INNER 是找到该字后,从读完这一gb2312码的位置到能够读取点阵文本的首位置的偏移量。
实现代码:
该文件基于Windows系统,在Windows系统中中文占用为两个字节(char),在Linux系统中为三个字节。
// 给单个字定位到指定位置
FILE* locateChar(char* text, FILE* src)
{
FILE* file = src;
fseek(file, OFFSET_BASE, SEEK_SET); // 设置起始位置
char reader[5];
char gbk[5];
getGBK(gbk, text); // 将汉字 text 的gbk码转为文本存储在gbk字符数组中
reader[4] = 0;
size_t size = sizeof(char);
for (int i = 0; i < 8178; i++) // 该字库收录了8178个简体汉字
{
fread(reader, size, 4, file);
if (strcmp(reader, gbk) == 0)
{
printf("Found char %s\n", reader);
fseek(file, OFFSET_INNER, SEEK_CUR);
break;
}
else
{
fseek(file, OFFSET_WORD, SEEK_CUR);
}
}
return file;
}
定位到汉字所在位置后就可以进行读取复制操作了。
FILE* file = fopen("bitmap.txt", "wb+");
FILE* src = fopen("LiShu56.txt", "rb");
src = locateChar(word, src); // 定位汉字
int tick = 56 * 56, flag; // 该字库点阵尺寸为 56×56,flag用于标记跳出循环
size_t size = sizeof(char);
char reader;
while (tick)
{
flag = 0;
while (fread(&reader, size, 1, src))
{
switch (reader)
{
case '_': case 'X':
fwrite(&reader, size, 1, file);
tick--;
break;
case '\r':
fwrite(&reader, size, 1, file);
break;
case '\n':
fwrite(&reader, size, 1, file);
flag = 1;
break;
default: break;
}
if (flag) break;
}
}
fclose(src);
fclose(file);
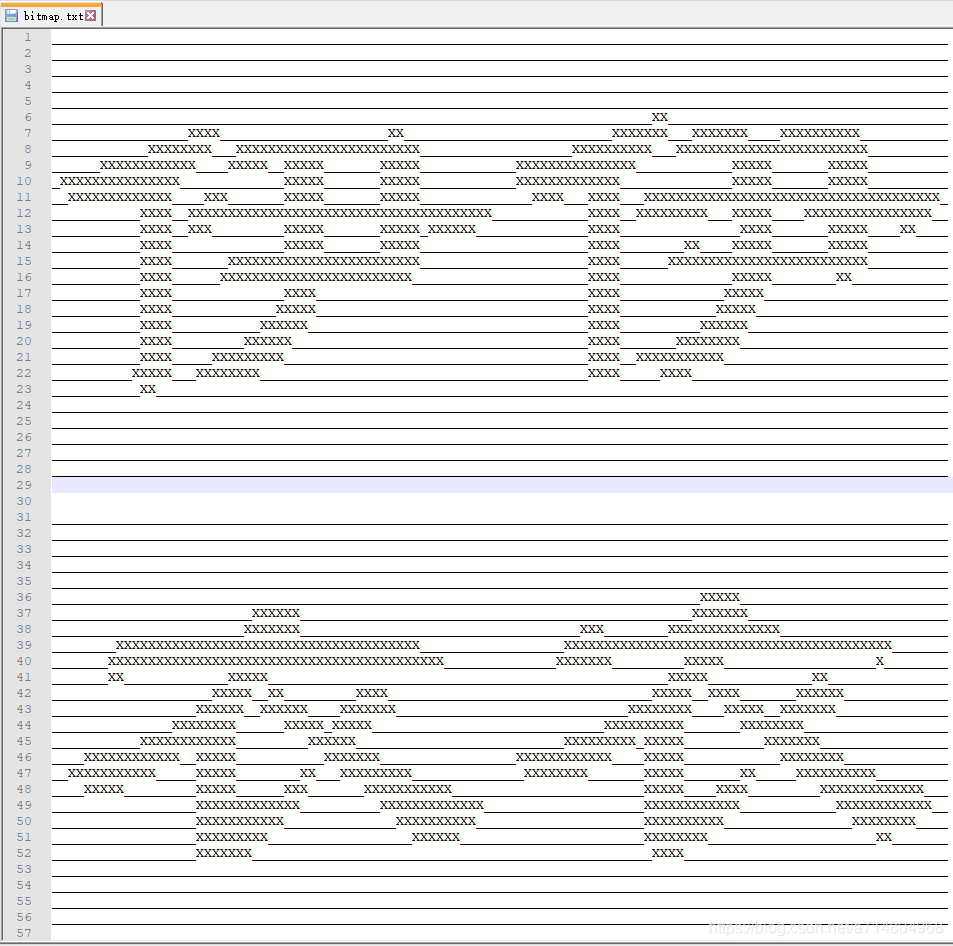
生成输出汉字“洋”示例:
命令窗口输出
Found char d1f3
文件输出
如果要将多个字合成在一个文件中,只需要稍作改动。
不过注意,将 FILE* 赋值给多个变量分别进行 fseek 定位,然后两个指针这里读几个字符,那里读几个字符,最后你会发现每个文件指针指向的都是最后一次调用 fseek 定位的那个字,导致最后是好几个一样的字合在一起。比如我要合成“洋伊”,最后得到的是:
Found char d1f3
Found char d2c1
抽象点说,简而言之,就是指向文件内容位置的文件指针是唯一的。
如果要将多个字合成在一个文本中,可以采用以下思路:
先将要合成的字,每个字存在一个临时文件中,再依次打开这些文件,读取并复制到(合成)同一文件中。
四、附录
示例代码中引用的部分函数代码
// 获得十六进制对应字符
char getX(int value)
{
if (value < 10) return '0' + value;
else return 'a' + (value - 10);
}
// 直接获得文本GBK十六进制机内码
void getGBK(char* dest, char* text)
{
int value = (int)((unsigned char)text[0] * 256) + (int)(unsigned char)text[1];
int index = 3;
while (value)
{
dest[index--] = getX(value % 16);
value /= 16;
}
dest[4] = 0;
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号