深入理解 Tomcat
深入理解 Tomcat(三)Tomcat 底层实现原理_ignore-CSDN博客_tomcat底层原理
本文将介绍 Java Web 服务器是如何运行的, Web 服务器也称为超文本传输协议( HyperText Transfer Protocol, HTTP)服务器, 因为它使用 Http 与其客户端(通常是 Web 浏览器)进行通信, 基于 Java 的 Web 服务器会使用两个重要的类: java.net.Socket 类和 java.net.ServerSocket 类, 并通过发送 Http 消息进行通信. 我们先花一些篇幅介绍 Http 协议(如果同学们熟悉HTTP协议可直接跳过)和这两个类, 然后写一个简单的 Web 服务器.
HTTP
Http : Http 允许 Web 服务器和浏览器通过 Internet 发送并接受数据, 是一种基于”请求—响应”的协议, 客户端请求一个文件, 服务器端对该请求进行响应. Http 使用可靠的 tcp 连接, tcp 协议默认使用 tcp 80端口, http协议的第一个版本是 http/0.9, 后来被 http/1.0取代, 随后 http/1.0又被http/1.1取代, http/1.1 定义域 RFC(Request for Comment, 请求注解)2616中.
如果各位对 Http1.1 有更多兴趣, 请阅读 RFC 2616.
在 Http 中, 总是由客户端通过建立连接并发送 http 请求来初始化一个事务的. Web 服务器端并不负责联系客户端或建立一个到客户端的回调连接.客户端或服务器端可提前关闭连接, 例如, 当使用 Web 浏览器浏览网页时, 可以单击浏览器上的 stop 按钮来停止下载文件, 这样就有效的关闭了一个 Web 服务器的 http 连接.
HTTP 请求
一个 HTTP 请求包含以下三部分:
* 请求方法—-统一资源标识符(Uniform Resource Identifier, URI)——协议/版本
* 请求头
* 实体
下面是一个 HTTP 请求的例子:
POST /examples/default.jsp HTTP/1.1
Accept: text/plain; text/html
Accept-Language: en-gb
Connection: Keep-Alive
Host: localhost
User-Agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows 98)
Content-Length: 33 Content-Type: application/x-www-form-urlencoded Accept-Encoding: gzip, deflate
lastName=Franks&firstName=Michael 方法—统一资源标识符(URI)—协议/版本出现在请求的第一行。POST /examples/default.jsp HTTP/1.1
这里 POST 是请求方法,/examples/default.jsp 是 URI,而 HTTP/1.1 是协议/版本部分。 每个 HTTP 请求可以使用 HTTP 标准里边提到的多种方法之一。HTTP 1.1 支持 7 种类型的请 求:GET, POST, HEAD, OPTIONS, PUT, DELETE 和 TRACE。GET 和 POST 在互联网应用里边最普遍使用的。
URI 完全指明了一个互联网资源。URI 通常是相对服务器的根目录解释的。因此,始终一斜 线/开头。统一资源定位器(URL)其实是一种 URI(查看 http://www.ietf.org/rfc/rfc2396.txt)
来的。该协议版本代表了正在使用的 HTTP 协议的版本。
请求的头部包含了关于客户端环境和请求的主体内容的有用信息。例如它可能包括浏览器设 置的语言,主体内容的长度等等。每个头部通过一个回车换行符(CRLF)来分隔的。
对于 HTTP 请求格式来说,头部和主体内容之间有一个回车换行符(CRLF)是相当重要的。CRLF 告诉HTTP服务器主体内容是在什么地方开始的。在一些互联网编程书籍中,CRLF还被认为是HTTP 请求的第四部分。
在前面一个 HTTP 请求中,主体内容只不过是下面一行:
lastName=Franks&firstName=Michael
实体内容在一个典型的 HTTP 请求中可以很容易的变得更长。
HTTP 响应
类似于 HTTP 请求,一个 HTTP 响应也包括三个组成部分:
* 方法—统一资源标识符(URI)—协议/版本
* 响应的头部
* 主体内容
下面是一个 HTTP 响应的例子:
HTTP/1.1 200 OK
Server: Microsoft-IIS/4.0
Date: Mon, 5 Jan 2004 13:13:33 GMT
Content-Type: text/html
Last-Modified: Mon, 5 Jan 2004 13:13:12 GMT
Content-Length: 112
<html>
<head>
<title>HTTP Response Example</title>
</head>
<body>
Welcome to Brainy Software
</body>
</html> 响应头部的第一行类似于请求头部的第一行。第一行告诉你该协议使用 HTTP 1.1,请求成 功(200=成功),表示一切都运行良好。
响应头部和请求头部类似,也包括很多有用的信息。响应的主体内容是响应本身的 HTML 内 容。头部和主体内容通过 CRLF 分隔开来。
Socket 类
套接字是网络连接的一个端点。套接字使得一个应用可以从网络中读取和写入数据。放在两 个不同计算机上的两个应用可以通过连接发送和接受字节流。为了从你的应用发送一条信息到另 一个应用,你需要知道另一个应用的 IP 地址和套接字端口。在 Java 里边,套接字指的是java.net.Socket类。
要创建一个套接字,你可以使用 Socket 类众多构造方法中的一个。其中一个接收主机名称 和端口号:
public Socket (java.lang.String host, int port)在这里主机是指远程机器名称或者 IP 地址,端口是指远程应用的端口号。例如,要连接 yahoo.com 的 80 端口,你需要构造以下的 Socket 对象:
new Socket ("yahoo.com", 80);一旦你成功创建了一个 Socket 类的实例,你可以使用它来发送和接受字节流。要发送字节 流,你首先必须调用Socket类的getOutputStream方法来获取一个java.io.OutputStream对象。 要 发 送 文 本 到 一 个 远 程 应 用 , 你 经 常 要 从 返 回 的 OutputStream 对 象 中 构 造 一 个 java.io.PrintWriter 对象。要从连接的另一端接受字节流,你可以调用 Socket 类的 getInputStream 方法用来返回一个 java.io.InputStream 对象。
ServerSocket 类
Socket 类代表一个客户端套接字,即任何时候你想连接到一个远程服务器应用的时候你构 造的套接字,现在,假如你想实施一个服务器应用,例如一个 HTTP 服务器或者 FTP 服务器,你 需要一种不同的做法。这是因为你的服务器必须随时待命,因为它不知道一个客户端应用什么时 候会尝试去连接它。为了让你的应用能随时待命,你需要使用 java.net.ServerSocket 类。这是 服务器套接字的实现。
ServerSocket 和 Socket 不同,服务器套接字的角色是等待来自客户端的连接请求。一旦服 务器套接字获得一个连接请求,它创建一个 Socket 实例来与客户端进行通信。
要创建一个服务器套接字,你需要使用 ServerSocket 类提供的四个构造方法中的一个。你 需要指定 IP 地址和服务器套接字将要进行监听的端口号。通常,IP 地址将会是 127.0.0.1,也 就是说,服务器套接字将会监听本地机器。服务器套接字正在监听的 IP 地址被称为是绑定地址。 服务器套接字的另一个重要的属性是 backlog,这是服务器套接字开始拒绝传入的请求之前,传 入的连接请求的最大队列长度。
其中一个 ServerSocket 类的构造方法如下所示:
java
public ServerSocket(int port, int backLog, InetAddress bindingAddress);
应用程序
如果同学们下载过我们在第一篇文章提供的源码(How Tomcat Works)的话, 我们可以看一看我们的目录:

我们的 web 服务器应用程序放在 cxs01.pyrmont(编译的时候因为错误改名字了,也就懒得改回来了) 包里边,由三个类组成:
* HttpServer
* Request
* Response
这个应用程序的入口点(静态 main 方法)可以在 HttpServer 类里边找到。main 方法创建了 一个 HttpServer 的实例并调用了它的 await 方法。await 方法,顾名思义就是在一个指定的端 口上等待 HTTP 请求,处理它们并发送响应返回客户端。它一直等待直至接收到 shutdown 命令。
应用程序不能做什么,除了发送静态资源,例如放在一个特定目录的 HTML 文件和图像文件。 它也在控制台上显示传入的 HTTP 请求的字节流。不过,它不给浏览器发送任何的头部例如日期 或者 cookies。
下面我们来看看我们今天的重点,这三个类,也就是tomcat的雏形代码
HttpServer 类
HttpServer 类代表一个 web 服务器,也就是程序的入口,看代码:
public class HttpServer {
public static final String WEB_ROOT =
System.getProperty("user.dir") + File.separator + "webroot";
// 关闭命令
private static final String SHUTDOWN_COMMAND = "/SHUTDOWN";
// 是否关闭
private boolean shutdown = false;
public static void main(String[] args) {
HttpServer server = new HttpServer();
server.await();
}main 方法中创建了一个HttpServer对象,并调用了该对象的await方法。看名字,该方法应该是等待http请求之类的东东。我们来看看方法内部:
public void await() {
ServerSocket serverSocket = null;
int port = 8080;
try {
// 创建一个socket服务器
serverSocket = new ServerSocket(port, 1, InetAddress.getByName("127.0.0.1"));
}
catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
// 循环等待http请求
while (!shutdown) {
Socket socket = null;
InputStream input = null;
OutputStream output = null;
try {
// 阻塞等待http请求
socket = serverSocket.accept();
input = socket.getInputStream();
output = socket.getOutputStream();
// 创建一个Request对象用于解析http请求内容
Request request = new Request(input);
request.parse();
// 创建一个Response 对象,用于发送静态文本
Response response = new Response(output);
response.setRequest(request);
response.sendStaticResource();
// 关闭流
socket.close();
//检查URI中是否有关闭命令
shutdown = request.getUri().equals(SHUTDOWN_COMMAND);
}
catch (Exception e) {
e.printStackTrace();
continue;
}
}
}我们看到,该方法创建了一个Socket服务器,并循环阻塞监听http请求,当有http请求到来时, 该方法便创建一个Request对象,构造参数是socket获取的输入流对象, 用于读取客户端请求的数据并解析。 然后再创建一个Response对象,构造参数是socket的输出流对象, 并含有一个Request对象的成员变量。Response对象用于将静态页面发送给浏览器或者是其他的客户端。最后, 该方法校验请求中是否含有关闭命令的字符串,如果有,就停止服务器的运行。
这就是一个简单的服务器, 当我第一次看到的时候,心想: 真TMD简单啊。原来没那么复杂嘛。我想同学们心里想的跟我也一样吧。so, 不论多么庞大的代码,底层原理都是很简单的,只要我们学好了基础,学习起来就会轻松很多。
废话不多说,我们继续看看Request 是如何解析Http请求的吧。
Request 类
类结构图如下:
Request 类代表一个 HTTP 请求。从负责与客户端通信的 Socket 中传递过来 InputStream 对象来构造这个类的一个实例。你调用 InputStream 对象其中一个 read 方法来获 取 HTTP 请求的原始数据。其中最主要的方法就是parse 和 parseUri ,他们用于逐个解析每个从客户端传递过来的字节,我们先看parse方法:
public void parse() {
// Read a set of characters from the socket
StringBuffer request = new StringBuffer(2048);
int i;
byte[] buffer = new byte[2048];
try {
// 读取流中内容
i = input.read(buffer);
}
catch (IOException e) {
e.printStackTrace();
i = -1;
}
for (int j=0; j<i; j++) {
// 将每个字节转换为字符
request.append((char) buffer[j]);
}
// 打印字符串
System.out.print(request.toString());
// 根据转换出来的字符解析URI
uri = parseUri(request.toString());
}我们也看到该方法是十分的简单, 创建一个StringBuffer 对象,然后从流中读取字节,然后循环将字节转成字符写入到Stringbuffer对象中。最后传入到parseUri方法中进行解析。
我们再看看parseUri方法, 这个方法中,我们前面学习的关于HTTP的知识会起作用:
private String parseUri(String requestString) {
int index1, index2;
// 找到第一个空格
index1 = requestString.indexOf(' ');
if (index1 != -1) {
// 找到第二个空格
index2 = requestString.indexOf(' ', index1 + 1);
if (index2 > index1)
// 截取第一个空格到第二个空格之间的内容
return requestString.substring(index1 + 1, index2);
}
return null;
}该方法从请求行里边获得 URI。parseUri 方法搜索请求里边的第一个和第二个空格并从中获取 URI。
为什么是第一个空格和第二个空格之间的内容呢?我们看看前面的Http请求的例子:
POST /examples/default.jsp HTTP/1.1
Accept: text/plain; text/html
Accept-Language: en-gb
Connection: Keep-Alive
Host: localhost
User-Agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows 98)
Content-Length: 33 Content-Type: application/x-www-form-urlencoded Accept-Encoding: gzip, deflate
lastName=Franks&firstName=Michael 我们看第一行:
POST 和 HTTP/1.1之间的就是我们需要的URI。so, 我们只需要将中间那段字符串截取就OK了。
我们总结一下Request类,这个类其实就是解析HTTP 消息头内容的,先将流中数据转成字节,然后将转成字符,最后将字符解析,得到自己感兴趣的内容。奏是这么简单。好了,我们再看看Response类。看看他是怎么实现的。
Response类
我们先看看这个类的结构图:
Response 代表了Http请求中的一个响应。我们关注其中的 sendStaticResource 方法,看名字,该方法应该是发送静态资源给客户端。我们看看代码:
public void sendStaticResource() throws IOException {
byte[] bytes = new byte[BUFFER_SIZE];
FileInputStream fis = null;
try {
File file = new File(HttpServer.WEB_ROOT, request.getUri());
if (file.exists()) {
// 文件存在则从输出流中输出
fis = new FileInputStream(file);
int ch = fis.read(bytes, 0, BUFFER_SIZE);
while (ch!=-1) {
output.write(bytes, 0, ch);
ch = fis.read(bytes, 0, BUFFER_SIZE);
}
}
else {
// 没有文件返回404
String errorMessage = "HTTP/1.1 404 File Not Found\r\n" +
"Content-Type: text/html\r\n" +
"Content-Length: 23\r\n" +
"\r\n" +
"<h1>File Not Found</h1>";
output.write(errorMessage.getBytes());
}
}
catch (Exception e) {
// thrown if cannot instantiate a File object
System.out.println(e.toString() );
}
finally {
if (fis!=null)
fis.close();
}
}可以看到,该方法也非常的简单, sendStaticResource 方法是用来发送一个静态资源,例如一个 HTML 文件。它首先通过传递 上一级目录的路径和子路径给 File 累的构造方法来实例化 java.io.File 类。
然后它检查该文件是否存在。假如存在的话,通过传递 File 对象让 sendStaticResource 构造一个 java.io.FileInputStream 对象。然后,它调用 FileInputStream 的 read 方法并把字 节数组写入 OutputStream 对象。请注意,这种情况下,静态资源是作为原始数据发送给浏览器 的。
假如文件并不存在,sendStaticResource 方法发送一个错误信息到浏览器
运行程序,启动HttpServer mian方法,使用Edge浏览器在地址栏敲入:http://localhost:8080/index.html
返回:
表示文件存在, 再看看我们的后台控制台:
如期打印了http请求头中的内容。并且下面还请求了一张图片。
总结
至此,我们已经知道了一个简单的Web服务器是如何工作的。破除了我们之前的疑惑,实际上tomcat底层就是这么实现的,可能关于阻塞IO和非阻塞NIO会有区别,但总体上还是这个思路,然后其余的组件都是针对优化性能,提高扩展性来设计新的架构。所以,我们明白了底层设计,再去学习他的设计,就不会那么迷茫。从而感到泄气。毕竟每个夜晚,我们孤独的学习,不想徒劳无功。
深入理解 Tomcat(四)Tomcat 类加载器之为何违背双亲委派模型_ignore-CSDN博客_tomcat类加载器
这是我们研究Tomcat的第四篇文章,前三篇文章我们搭建了源码框架,了解了tomcat的大致的设计架构, 还写了一个简单的服务器。按照我们最初订的计划,今天,我们要开始研究tomcat的几个主要组件(组件太多,无法一一解析,解析几个核心),包括核心的类加载器,连接器和容器,还有生命周期,还有pipeline 和 valve。一个一个来,今天来研究类加载器。
我们分为4个部分来探讨:
1. 什么是类加载机制?
2. 什么是双亲委任模型?
3. 如何破坏双亲委任模型?
4. Tomcat 的类加载器是怎么设计的?我想,在研究tomcat 类加载之前,我们复习一下或者说巩固一下java 默认的类加载器。楼主以前对类加载也是懵懵懂懂,借此机会,也好好复习一下。
楼主翻开了神书《深入理解Java虚拟机》第二版,p227, 关于类加载器的部分。请看:
1. 什么是类加载机制?
代码编译的结果从本地机器码转变成字节码,是存储格式的一小步,却是编程语言发展的一大步。
Java虚拟机把描述类的数据从Class文件加载进内存,并对数据进行校验,转换解析和初始化,最终形成可以呗虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
虚拟机设计团队把类加载阶段中的“通过一个类的全限定名来获取描述此类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需要的类。实现这动作的代码模块成为“类加载器”。
类与类加载器的关系
类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远远不限于类加载阶段。对于任意一个类,都需要由加载他的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类命名空间。这句话可以表达的更通俗一些:比较两个类是否“相等”,
只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来自同一个Class文件,被同一个虚拟机加载,只要加载他们的类加载器不同,那这个两个类就必定不相等。
2. 什么是双亲委任模型
-
从Java虚拟机的角度来说,只存在两种不同类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现(只限HotSpot),是虚拟机自身的一部分;另一种就是所有其他的类加载器,这些类加载器都由Java语言实现,独立于虚拟机外部,并且全都继承自抽象类
java.lang.ClassLoader. -
从Java开发人员的角度来看,类加载还可以划分的更细致一些,绝大部分Java程序员都会使用以下3种系统提供的类加载器:
- 启动类加载器(Bootstrap ClassLoader):这个类加载器复杂将存放在 JAVA_HOME/lib 目录中的,或者被-Xbootclasspath 参数所指定的路径种的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录下也不会重载)。
- 扩展类加载器(Extension ClassLoader):这个类加载器由sun.misc.Launcher$ExtClassLoader实现,它负责夹杂JAVA_HOME/lib/ext 目录下的,或者被java.ext.dirs 系统变量所指定的路径种的所有类库。开发者可以直接使用扩展类加载器。
- 应用程序类加载器(Application ClassLoader):这个类加载器由sun.misc.Launcher$AppClassLoader 实现。由于这个类加载器是ClassLoader 种的getSystemClassLoader方法的返回值,所以也成为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库。开发者可以直接使用这个类加载器,如果应用中没有定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
这些类加载器之间的关系一般如下图所示:
图中各个类加载器之间的关系成为 类加载器的双亲委派模型(Parents Dlegation Mode)。双亲委派模型要求除了顶层的启动类加载器之外,其余的类加载器都应当由自己的父类加载器加载,这里类加载器之间的父子关系一般不会以继承的关系来实现,而是都使用组合关系来复用父加载器的代码。
类加载器的双亲委派模型在JDK1.2 期间被引入并被广泛应用于之后的所有Java程序中,但他并不是个强制性的约束模型,而是Java设计者推荐给开发者的一种类加载器实现方式。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,他首先不会自己去尝试加载这个类,而是把这个请求委派父类加载器去完成。每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个请求(他的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
为什么要这么做呢?
如果没有使用双亲委派模型,由各个类加载器自行加载的话,如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,那系统将会出现多个不同的Object类, Java类型体系中最基础的行为就无法保证。应用程序也将会变得一片混乱。
双亲委任模型时如何实现的?
非常简单:所有的代码都在java.lang.ClassLoader中的loadClass方法之中,代码如下:

逻辑清晰易懂:先检查是否已经被加载过,若没有加载则调用父加载器的loadClass方法, 如父加载器为空则默认使用启动类加载器作为父加载器。如果父类加载失败,抛出ClassNotFoundException 异常后,再调用自己的findClass方法进行加载。
3. 如何破坏双亲委任模型?
刚刚我们说过,双亲委任模型不是一个强制性的约束模型,而是一个建议型的类加载器实现方式。在Java的世界中大部分的类加载器都遵循者模型,但也有例外,到目前为止,双亲委派模型有过3次大规模的“被破坏”的情况。
第一次:在双亲委派模型出现之前—–即JDK1.2发布之前。
第二次:是这个模型自身的缺陷导致的。我们说,双亲委派模型很好的解决了各个类加载器的基础类的统一问题(越基础的类由越上层的加载器进行加载),基础类之所以称为“基础”,是因为它们总是作为被用户代码调用的API, 但没有绝对,如果基础类调用会用户的代码怎么办呢?
这不是没有可能的。一个典型的例子就是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器去加载(在JDK1.3时就放进去的rt.jar),但它需要调用由独立厂商实现并部署在应用程序的ClassPath下的JNDI接口提供者(SPI, Service Provider Interface)的代码,但启动类加载器不可能“认识“这些代码啊。因为这些类不在rt.jar中,但是启动类加载器又需要加载。怎么办呢?
为了解决这个问题,Java设计团队只好引入了一个不太优雅的设计:线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader方法进行设置。如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过多的话,那这个类加载器默认即使应用程序类加载器。
嘿嘿,有了线程上下文加载器,JNDI服务使用这个线程上下文加载器去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作,这种行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则。但这无可奈何,Java中所有涉及SPI的加载动作基本胜都采用这种方式。例如JNDI,JDBC,JCE,JAXB,JBI等。
第三次:为了实现热插拔,热部署,模块化,意思是添加一个功能或减去一个功能不用重启,只需要把这模块连同类加载器一起换掉就实现了代码的热替换。
书中还说到:
Java 程序中基本有一个共识:OSGI对类加载器的使用时值得学习的,弄懂了OSGI的实现,就可以算是掌握了类加载器的精髓。
牛逼啊!!!
现在,我们已经基本明白了Java默认的类加载的作用了原理,也知道双亲委派模型。说了这么多,差点把我们的tomcat给忘了,我们的题目是Tomcat 加载器为何违背双亲委派模型?下面就好好说说我们的tomcat的类加载器。
4. Tomcat 的类加载器是怎么设计的?
首先,我们来问个问题:
Tomcat 如果使用默认的类加载机制行不行?
我们思考一下:Tomcat是个web容器, 那么它要解决什么问题:
1. 一个web容器可能需要部署两个应用程序,不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求同一个类库在同一个服务器只有一份,因此要保证每个应用程序的类库都是独立的,保证相互隔离。
2. 部署在同一个web容器中相同的类库相同的版本可以共享。否则,如果服务器有10个应用程序,那么要有10份相同的类库加载进虚拟机,这是扯淡的。
3. web容器也有自己依赖的类库,不能于应用程序的类库混淆。基于安全考虑,应该让容器的类库和程序的类库隔离开来。
4. web容器要支持jsp的修改,我们知道,jsp 文件最终也是要编译成class文件才能在虚拟机中运行,但程序运行后修改jsp已经是司空见惯的事情,否则要你何用? 所以,web容器需要支持 jsp 修改后不用重启。
再看看我们的问题:Tomcat 如果使用默认的类加载机制行不行?
答案是不行的。为什么?我们看,第一个问题,如果使用默认的类加载器机制,那么是无法加载两个相同类库的不同版本的,默认的累加器是不管你是什么版本的,只在乎你的全限定类名,并且只有一份。第二个问题,默认的类加载器是能够实现的,因为他的职责就是保证唯一性。第三个问题和第一个问题一样。我们再看第四个问题,我们想我们要怎么实现jsp文件的热修改(楼主起的名字),jsp 文件其实也就是class文件,那么如果修改了,但类名还是一样,类加载器会直接取方法区中已经存在的,修改后的jsp是不会重新加载的。那么怎么办呢?我们可以直接卸载掉这jsp文件的类加载器,所以你应该想到了,每个jsp文件对应一个唯一的类加载器,当一个jsp文件修改了,就直接卸载这个jsp类加载器。重新创建类加载器,重新加载jsp文件。
Tomcat 如何实现自己独特的类加载机制?
所以,Tomcat 是怎么实现的呢?牛逼的Tomcat团队已经设计好了。我们看看他们的设计图:

我们看到,前面3个类加载和默认的一致,CommonClassLoader、CatalinaClassLoader、SharedClassLoader和WebappClassLoader则是Tomcat自己定义的类加载器,它们分别加载/common/*、/server/*、/shared/*(在tomcat 6之后已经合并到根目录下的lib目录下)和/WebApp/WEB-INF/*中的Java类库。其中WebApp类加载器和Jsp类加载器通常会存在多个实例,每一个Web应用程序对应一个WebApp类加载器,每一个JSP文件对应一个Jsp类加载器。
- commonLoader:Tomcat最基本的类加载器,加载路径中的class可以被Tomcat容器本身以及各个Webapp访问;
- catalinaLoader:Tomcat容器私有的类加载器,加载路径中的class对于Webapp不可见;
- sharedLoader:各个Webapp共享的类加载器,加载路径中的class对于所有Webapp可见,但是对于Tomcat容器不可见;
- WebappClassLoader:各个Webapp私有的类加载器,加载路径中的class只对当前Webapp可见;
从图中的委派关系中可以看出:
CommonClassLoader能加载的类都可以被Catalina ClassLoader和SharedClassLoader使用,从而实现了公有类库的共用,而CatalinaClassLoader和Shared ClassLoader自己能加载的类则与对方相互隔离。
WebAppClassLoader可以使用SharedClassLoader加载到的类,但各个WebAppClassLoader实例之间相互隔离。
而JasperLoader的加载范围仅仅是这个JSP文件所编译出来的那一个.Class文件,它出现的目的就是为了被丢弃:当Web容器检测到JSP文件被修改时,会替换掉目前的JasperLoader的实例,并通过再建立一个新的Jsp类加载器来实现JSP文件的HotSwap功能。
好了,至此,我们已经知道了tomcat为什么要这么设计,以及是如何设计的,那么,tomcat 违背了java 推荐的双亲委派模型了吗?答案是:违背了。 我们前面说过:
双亲委派模型要求除了顶层的启动类加载器之外,其余的类加载器都应当由自己的父类加载器加载。
很显然,tomcat 不是这样实现,tomcat 为了实现隔离性,没有遵守这个约定,每个webappClassLoader加载自己的目录下的class文件,不会传递给父类加载器。
我们扩展出一个问题:如果tomcat 的 Common ClassLoader 想加载 WebApp ClassLoader 中的类,该怎么办?
看了前面的关于破坏双亲委派模型的内容,我们心里有数了,我们可以使用线程上下文类加载器实现,使用线程上下文加载器,可以让父类加载器请求子类加载器去完成类加载的动作。牛逼吧。
总结
好了,终于,我们明白了Tomcat 为何违背双亲委派模型,也知道了tomcat的类加载器是如何设计的。顺便复习了一下 Java 默认的类加载器机制,也知道了如何破坏Java的类加载机制。这一次收获不小哦!!! 嘿嘿。
深入理解 Tomcat(五)源码剖析Tomcat 启动过程----类加载过程_ignore-CSDN博客_tomcat类加载器流程
这是我们深入理解tomcat的第五篇文章,按照我们的思路,这次我们本应该区分析tomcat的连接器组件,但楼主思前想后,觉得连接器组件不能只是纸上谈兵,需要深入源码,但楼主本能的认为我们应该先分析tomcat的启动过程,以能够和我们上一篇文章深入理解 Tomcat(四)Tomcat 类加载器之为何违背双亲委派模型相衔接。因为启动类加载器的核心代码就在启动过程中,所以,我决定先分析tomcat的启动过程,结合源码了解tomcat的类加载器如何实现,以彻底了解tomcat的类加载器。
因为Tomcat 的启动过程非常复杂,因此楼主将启动过程拆开分析,不能像之前说的按照启动过程分析了,否则,文章篇幅过长,条理也会变得不清晰,Tomcat的启动过程包括了初始化容器的生命周期,还涉及到JMX的管理,还有我们现在分析的类加载器,因此,我们必须换个维度分析。
再一个,因为连接器和容器紧紧关联,连接器的作用就是分析http请求,所以,楼主觉得我们之前的计划可能需要变更一下,我们将在分析完生命周期和类加载器之后将结合源码分析连接器和容器,以了解tomcat的核心组件在接受HTTP请求后如何运行。
所以,今天,我们的任务就是debug tomcat 源码,分析tomcat启动过程的每一步操作。在看这篇文章之前希望同学们看看我们的第四篇分析tomcat的文章以了解tomcat的类加载器。
下面是这篇文章的目录结构:
1. 启动tomcat,进入main方法
2. 进入 init 方法
3. 进入 setCatalinaHome 方法
4. 进入 setCatalinaBase 方法
5. 接下来则是类加载器大显身手的时候了. 进入 intiClassLoaders 方法
6. 进入 createClassLoader 方法
7. 我们回到 initClassLoaders 方法中来
8. 再回到 init 方法中, 类加载器初始化结束, 接下来干嘛?
9. 设置完线程上下文类加载器之后做什么呢? 进入 securityClassLoad 方法
10. 进入 loadCorePackage 方法
11. 回到 init 方法
12. 寻找 WebAppClassLoader, 进入 startInternal 方法
13. 进入 createClassLoader 方法
14. tomcat 类加载结构体系创建完毕1. 启动tomcat,进入main方法
我们打开我们之前clone下的Tomcat-Source-Code 源码,找到Bootstrap 类,找到main方法,在451行打上断点,启动main方法,开始我们的调试:
可以看到楼主已经写了很多的注释,因为楼主已经debug过了.
我们看代码,首先判断”守护“对象是否为null,肯定为null了,然后进入if 块, 创建一个默认构造器的Bootstrap对象,有一行注释// Don't set daemon until init() has completed, 说不要在init方法完成之前设置daemon 变量,因为后面的很多步骤都依赖该变量,所以必须初始化结束后才能设置值,再继续看,进入init方法:
2. 进入 init 方法

该方法注释:Initialize daemon.表明要初始化该守护程序,也就是这个变量Bootstrap:

我们看看该方法,首先setCatalinaHome()方法,也就是我们启动虚拟机的时候设置的 VM 参数:
我们进入该方法看看
3. 进入 setCatalinaHome 方法

很明显,我们设置过 Catalina.home , 所以获取classpath下的catalina.home 的值不为null,所以直接return, 如果不为null,则从项目根目录下获取boostrap的jar包。如果存在,则设置上一级目录为 catalina.home, 如果不存在,则设置项目根目录为 catalina.home.这就是 setCatalinaHome 方法的逻辑.
4. 进入 setCatalinaBase 方法
下一步是执行 setCatalinaBase 方法, 也是一样能获取catalina.base, 直接 return,如果不存在, 则设置catalina.home为catalina.base, 如果catalina.home也是空,那么则设置项目根目录为catatlina.base.

5. 接下来则是类加载器大显身手的时候了. 进入 intiClassLoaders 方法

intiClassLoaders(), 初始化多个类加载器. 我们进入该方法查看具体逻辑:

首先,创建一个 common 类加载器, 父类加载器为 null, 注意: 如果是 java 推荐的类加载器机制, 父类加载器应该是系统类加载器或者是扩展类加载器, 所以这明显违背了类加载器的双亲委派模型. 好, 我们继续看 tomcat, 我们进入 creatClassLoader 方法, 看看是如何实现的(该方法很长, 我们关注重要的逻辑):
6. 进入 createClassLoader 方法
private ClassLoader createClassLoader(String name, ClassLoader parent)
throws Exception {
// 从/org/apache/catalina/startup/catalina.properties 中获取该 key 的配置
// common.loader 对应的 Value=${catalina.base}/lib,${catalina.base}/lib/*.jar,${catalina.home}/lib,${catalina.home}/lib/*.jar
String value = CatalinaProperties.getProperty(name + ".loader");
// 如果不存在(默认存在), 返回 null
if ((value == null) || (value.equals(""))){
return parent;
}
// 使用环境变量对应的目录替换字符串
value = replace(value);
//Repository是ClassLoaderFactory 中的一个静态内部类, 有2个属性, location, type, 表示某个位置的某种类型的文件
List<Repository> repositories = new ArrayList<Repository>();
/*
省略部分代码, 此部分代码是处理value 变量并获取文件位置和类型
*/
// 根据给定的路径数组前去加载给定的 class 文件,
// StandardClassLoader 继承了 java.net.URLClassLoader ,使用URLClassLoader的构造器构造类加载器.
// 根据父类加载器是否为 null, URLClassLoader将启用不同的构造器.
// 总之, common 类加载器没有指定父类加载器,违背双亲委派模型
ClassLoader classLoader = ClassLoaderFactory.createClassLoader// 创建类加载器, 如果parent 是0,则
(repositories, parent);
// Retrieving MBean server // 注册到 JMX 中管理 bean, 这个我们后面说
MBeanServer mBeanServer = null;
if (MBeanServerFactory.findMBeanServer(null).size() > 0) {
mBeanServer = MBeanServerFactory.findMBeanServer(null).get(0);
} else {
mBeanServer = ManagementFactory.getPlatformMBeanServer();
}
// Register the server classloader
ObjectName objectName =
new ObjectName("Catalina:type=ServerClassLoader,name=" + name);
// 生命周期管理.
mBeanServer.registerMBean(classLoader, objectName);
return classLoader;
}虽然上面的代码写了注释,但是我们还是梳理一下逻辑:
- 从
/org/apache/catalina/startup/catalina.properties配置文件中获取 lib 仓库和 jar 包位置. 如果key (分别为common.loader、server.loader、shared.loader)所对应的value 不存在则返回父类加载器. 默认情况有.则继续下面的逻辑. - 处理从配置文件中获取的字符串, 得到jar 包的位置.
- 使用
ClassLoaderFactory.createClassLoader(repositories, parent)方法, 该方法使用一个继承自java.net.URLClassLoader废弃的StandardClassLoader类加载 jar 处理后得到的文件, 实际上调用的是URLClassLoader的构造方法, 下面代码是 crateClassLoader 方法中最后的逻辑, array 中是 jar 包的地址,根据父类加载器是否为 null 调用StandardClassLoader不同的构造方法. - 将ClassLoader 注册到JMX服务中(这里涉及到生命周期的内容,我们按下不表,后面再说)。
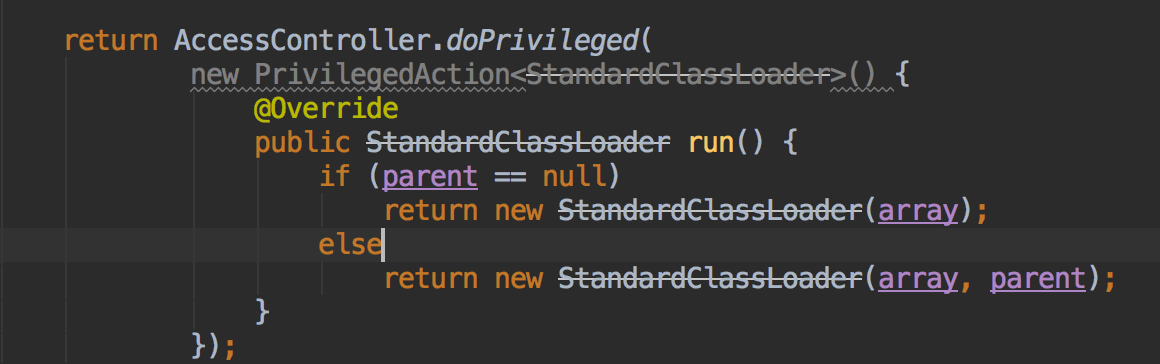
下面的是StandardClassLoader的构造方法,可以看到,实际上只是使用URLClassLoader 的构造方法:
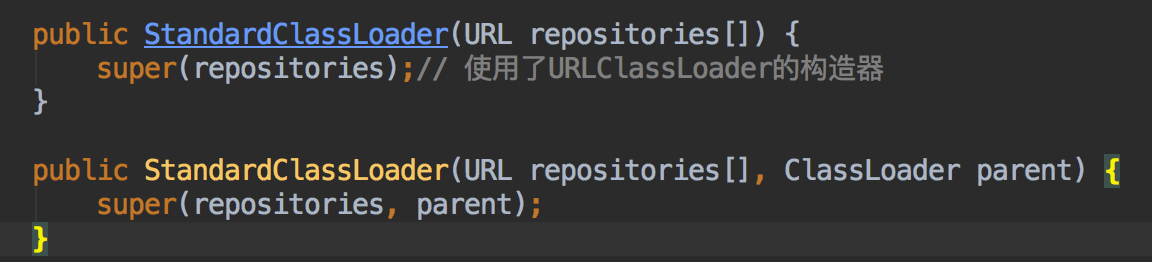
而 URLClassLoader 将会调用父类 SecureClassLoader 的构造方法, 而 SecureClassLoader 将会调用 ClassLoader 的构造方法, 从而完成一个类加载器的初始化. 可谓不易.
7. 我们回到 initClassLoaders 方法中来
执行完commonLoader = createClassLoader("common", null);, 接下里就会判断返回的类加载器是否为 null, 什么时候会为 null 呢? 找不到配置文件中的 key 的时候或者 key 对应的 value 为空的时候回返回 null, 如果返回 null, 那么就设置默认的类加载器为 common 类加载器.
继续初始化 catalinaloader 和 sharedLoader 两个类加载器, 同样调用 createClassLoader 方法, 不同的是, 他们的父类加载器不是 null, 而是上面的 common 类加载器. 我们看看他们进入这个方法的时候回怎么样?我们 debug 看一下:

可以看到两个获取到都是空, 所以他们直接返回父类加载器, 也就是说, 他们三个使用的是同一个类加载器.
8. 再回到 init 方法中, 类加载器初始化结束, 接下来干嘛?

将 catalinaLoader 类加载器设置为当前线程上下文类加载器. 并设置线程安全类加载器.同时检查是否安全, 如果不安全,则直接结束.
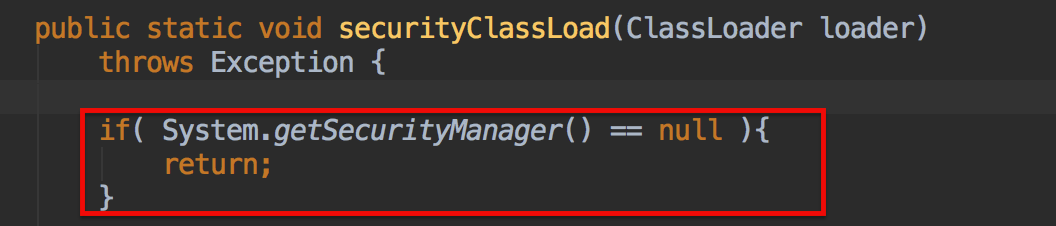
9. 设置完线程上下文类加载器之后做什么呢? 进入 securityClassLoad 方法

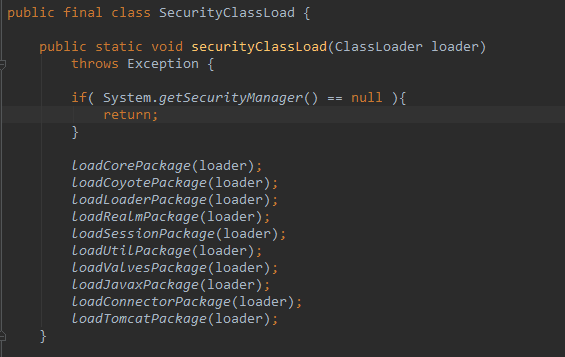
可以看到,该类时加载Tomcat容器中类资源,传递的ClassLoader时catalinaLoader,也就是说,Tomcat容器的类资源都是catalinaLoader加载完成的。
securityClassLoad方法主要加载Tomcat容器所需的class,包括:
- Tomcat核心class,即org.apache.catalina.core路径下的class;
- org.apache.catalina.loader.WebappClassLoader$PrivilegedFindResourceByName;
- Tomcat有关session的class,即org.apache.catalina.session路径下的class;
- Tomcat工具类的class,即org.apache.catalina.util路径下的class;
- javax.servlet.http.Cookie;
- Tomcat处理请求的class,即org.apache.catalina.connector路径下的class;
- Tomcat其它工具类的class,也是org.apache.catalina.util路径下的class;
10. 进入 loadCorePackage 方法
我们以加载Tomcat核心class的loadCorePackage方法为例,我们看源码实现:
private static final void loadCorePackage(ClassLoader loader)
throws Exception {
final String basePackage = "org.apache.catalina.core.";
loader.loadClass
(basePackage +
"AccessLogAdapter");
loader.loadClass
(basePackage +
"ApplicationContextFacade$1");
loader.loadClass
(basePackage +
"ApplicationDispatcher$PrivilegedForward");
loader.loadClass
(basePackage +
"ApplicationDispatcher$PrivilegedInclude");
loader.loadClass
(basePackage +
"AsyncContextImpl");
loader.loadClass
(basePackage +
"AsyncContextImpl$DebugException");
loader.loadClass
(basePackage +
"AsyncContextImpl$1");
loader.loadClass
(basePackage +
"AsyncContextImpl$PrivilegedGetTccl");
loader.loadClass
(basePackage +
"AsyncContextImpl$PrivilegedSetTccl");
loader.loadClass
(basePackage +
"AsyncListenerWrapper");
loader.loadClass
(basePackage +
"ContainerBase$PrivilegedAddChild");
loader.loadClass
(basePackage +
"DefaultInstanceManager$1");
loader.loadClass
(basePackage +
"DefaultInstanceManager$2");
loader.loadClass
(basePackage +
"DefaultInstanceManager$3");
loader.loadClass
(basePackage +
"DefaultInstanceManager$AnnotationCacheEntry");
loader.loadClass
(basePackage +
"DefaultInstanceManager$AnnotationCacheEntryType");
loader.loadClass
(basePackage +
"ApplicationHttpRequest$AttributeNamesEnumerator");
}我们可以看到,catalinaClassLoader 加载了该包下的类。根据我们之前的理解:catalinaClassLoader 加载的类是Tomcat容器私有的类加载器,加载路径中的class对于Webapp不可见。
11. 回到 init 方法

首先打印一波日志, 然后使用类 catalinaLoader 类加载器加载 org.apache.catalina.startup.Catalina 类, 接着创建该类的一个对象, 名为 startupInstance, 意为”启动对象实例”, 然后使用反射调用该实例的setParentClassLoader 方法, 参数为 sharedLoader, 表示该实例的父类加载器为 sharedLoader.
最后, 设置 catalinaDaemon 为该实例。
12. 寻找 WebAppClassLoader, 进入 startInternal 方法
我们通过源码知道了初始化了commonClassLoader, catalinaClassLoader, sharedLoader,但是,我们想起我们上一篇文章的图,好像少了点什么?
WebAppClassLoader呢?
我们知道, WebAppClassLoaser 是各个Webapp私有的类加载器,加载路径中的class只对当前Webapp可见,那么他是如何初始化的呢?WebAppClassLoaser 的初始化时间和这3个类加载器初始化的时间不同,由于WebAppClassLoaser 和Context 紧紧关联,因此咋初始化
org.apache.catalina.core.StandardContext 会一起初始化 WebAppClassLoader, 该类中startInternal方法含有初始化类加载器的逻辑,核心源码如下:
@Override
protected synchronized void startInternal() throws LifecycleException {
if (getLoader() == null) {
WebappLoader webappLoader = new WebappLoader(getParentClassLoader());
webappLoader.setDelegate(getDelegate());
setLoader(webappLoader);
}
if ((loader != null) && (loader instanceof Lifecycle)) {
((Lifecycle) loader).start();
}
}首先创建 WebAppClassLoader , 然后 setLoader(webappLoader),再调用start方法,该方法是个模板方法,内部有 startInternal 方法用于子类去实现, 我们看WebAppClassLoader的startInternal 方法核心实现:
@Override
protected void startInternal() throws LifecycleException {
classLoader = createClassLoader();
classLoader.setResources(container.getResources());
classLoader.setDelegate(this.delegate);
classLoader.setSearchExternalFirst(searchExternalFirst);
if (container instanceof StandardContext) {
classLoader.setAntiJARLocking(
((StandardContext) container).getAntiJARLocking());
classLoader.setClearReferencesStatic(
((StandardContext) container).getClearReferencesStatic());
classLoader.setClearReferencesStopThreads(
((StandardContext) container).getClearReferencesStopThreads());
classLoader.setClearReferencesStopTimerThreads(
((StandardContext) container).getClearReferencesStopTimerThreads());
classLoader.setClearReferencesHttpClientKeepAliveThread(
((StandardContext) container).getClearReferencesHttpClientKeepAliveThread());
}
for (int i = 0; i < repositories.length; i++) {
classLoader.addRepository(repositories[i]);
}
}13. 进入 createClassLoader 方法
首先classLoader = createClassLoader();创建类加载器,并且设置其资源路径为当前Webapp下某个context的类资源。最后我们看看createClassLoader的实现:
/**
* Create associated classLoader.
*/
private WebappClassLoader createClassLoader()
throws Exception {
Class<?> clazz = Class.forName(loaderClass);
WebappClassLoader classLoader = null;
if (parentClassLoader == null) {
parentClassLoader = container.getParentClassLoader();
}
Class<?>[] argTypes = { ClassLoader.class };
Object[] args = { parentClassLoader };
Constructor<?> constr = clazz.getConstructor(argTypes);
classLoader = (WebappClassLoader) constr.newInstance(args);
return classLoader;
}这里的loaderClass 是 字符串 org.apache.catalina.loader.WebappClassLoader, 首先通过反射实例化classLoader。现在我们知道了, WebappClassLoader 是在 StandardContext 初始化的时候实例化的,也证明了WebappClassLoader 和 Context 息息相关。
14. omcat 类加载结构体系创建完毕
至此,我们的Tomcat 类加载结构体系创建完毕。真TMD复杂啊!!! 不过,请记住, 阅读源码是提高我们水平最快速的手段。源码中大师们的设计模式和各种高级用法。会让我们功力大增。继续加油吧!!!
深入理解 Tomcat(六)源码剖析Tomcat 启动过程----生命周期和容器组件_ignore-CSDN博客
好了,今天我们继续分析 tomcat 源码, 这是第六篇了, 上一篇我们一边 debug 一边研究了 tomcat 的类加载体系, 我觉得效果还不错, 楼主感觉对 tomcat 的类加载体系的理解又加深了一点. 所以, 我们今天还是按照之前的方式来继续看源码, 一边 debug, 一边看, 今天我们分析的是tomcat 中2个非常重要的组件——-生命周期和容器. tomcat 庞大的架构, 他是如何管理每个对象的呢? 我们在深入理解 Tomcat (二) 从宏观上理解 Tomcat 组件及架构中说过一段:
基于JMX Tomcat会为每个组件进行注册过程,通过Registry管理起来,而Registry是基于JMX来实现的,因此在看组件的init和start过程实际上就是初始化MBean和触发MBean的start方法,会大量看到形如: Registry.getRegistry(null, null).invoke(mbeans, “init”, false); Registry.getRegistry(null, null).invoke(mbeans, “start”, false); 这样的代码,这实际上就是通过JMX管理各种组件的行为和生命期。
当时大家可能还不是很理解这句话, 觉得这是在扯淡, 听不懂. 好吧, 今天我们就用代码说话, 看看 JMX 到底怎么管理 tomcat 的 组件.
1. 什么是 JMX?
我们之前说过:
JMX 即 Java Management Extensions(JMX 规范), 是用来对 tomcat 进行管理的. tomcat 中的实现是 commons modeler 库, Catalina 使用这个库来编写托管 Bean 的工作. 托管 Bean 就是用来管理 Catalina 中其他对象的 Bean.
简单来说: 就是一个可以为Java应用程序或系统植入远程管理功能的框架。
既然是框架, 肯定要有架构图:
这里对上图中三个分层进行介绍:
-
Probe Level:负责资源的检测(获取信息),包含MBeans,通常也叫做Instrumentation Level。MX管理构件(MBean)分为四种形式,分别是标准管理构件(Standard MBean)、动态管理构件(Dynamic MBean)、开放管理构件(Open Mbean)和模型管理构件(Model MBean)。
-
Agent Level:即MBeanServer,是JMX的核心,负责连接Mbeans和应用程序。
-
Remote Management Level:通过connectors和adaptors来远程操作MBeanServer,常用的控制台,例如JConsole、VisualVM(等会我们就要用这个)等。
2. 我们看看生命周期组件接口是如何设计的:

这是一张 IDEA 生成的简单的 StandardHost(Host 容器的标准实现) 的 UML类图, 基本上, tomcat 的容器类都是这样的继承结构.
因此我们就可以直接看下面这张图:
这里对上图中涉及的主要类作个简单介绍:
-
Lifecycle:定义了容器生命周期、容器状态转换及容器状态迁移事件的监听器注册和移除等主要接口;
-
LifecycleBase:作为Lifecycle接口的抽象实现类,运用抽象模板模式将所有容器的生命周期及状态转换衔接起来,此外还提供了生成LifecycleEvent事件的接口;
-
LifecycleSupport:提供有关LifecycleEvent事件的监听器注册、移除,并且使用经典的监听器模式,实现事件生成后触达监听器的实现;
-
MBeanRegistration:Java JMX框架提供的注册MBean的接口,引入此接口是为了便于使用JMX提供的管理功能;
-
LifecycleMBeanBase:Tomcat提供的对MBeanRegistration的抽象实现类,运用抽象模板模式将所有容器统一注册到JMX;
-
此外,ContainerBase、StandardServer、StandardService、WebappLoader、Connector、StandardContext、StandardEngine、StandardHost、StandardWrapper等容器都继承了LifecycleMBeanBase,因此这些容器都具有了同样的生命周期并可以通过JMX进行管理。
3. 再看看我们的容器结构
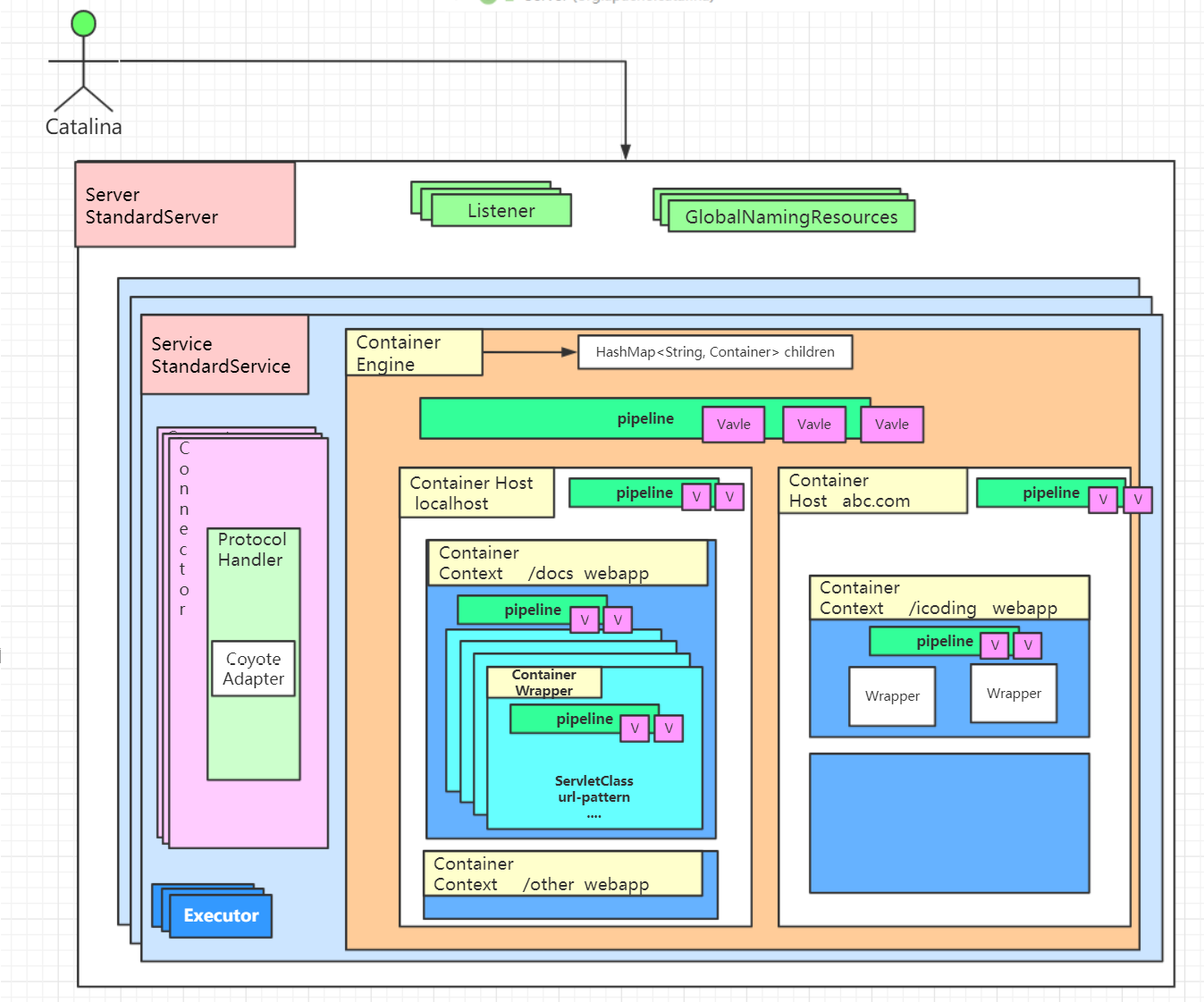
我们之前说, 如果从宏观上讲容器, 画画图, 讲讲就好了, 就可以在脑海里形成一个映象, 今天, 我们要好好的讲讲容器, 从代码层面去理解他们. 这样一来, 也顺便把我们的容器组件也讲了, 等于又讲了生命周期组件, 还有容器组件. 一举两得. 哈哈哈. 好吧, 不扯了, 回来, 我们继续讲容器. 还是先来一张图吧:

从上图中我们可以看到: StandardServer、StandardService、Connector、StandardContext这些容器,彼此之间都有父子关系,每个容器都可能包含零个或者多个子容器,这些子容器可能存在不同类型或者相同类型的多个. 所以他们都包含的关系, 如果让你来设计这些容器的生命周期, 你会用什么设计模式呢?
4. 容器初始化, 开始 Debug
首先我们启动 main 方法:
public static void main(String args[]) {
try {
// 命令
String command = "start";
// 如果命令行中输入了参数
if (args.length > 0) {
// 命令 = 最后一个命令
command = args[args.length - 1];
}
// 如果命令是启动
if (command.equals("startd")) {
args[args.length - 1] = "start";
daemon.load(args);
daemon.start();
}
// 如果命令是停止了
else if (command.equals("stopd")) {
args[args.length - 1] = "stop";
daemon.stop();
}
// 如果命令是启动
else if (command.equals("start")) {
daemon.setAwait(true);// bootstrap 和 Catalina 一脉相连, 这里设置, 方法内部设置 Catalina 实例setAwait方法
daemon.load(args);// args 为 空,方法内部调用 Catalina 的 load 方法.
daemon.start();// 相同, 反射调用 Catalina 的 start 方法 ,至此,启动结束
} else if (command.equals("stop")) {
daemon.stopServer(args);
} else if (command.equals("configtest")) {
daemon.load(args);
if (null==daemon.getServer()) {
System.exit(1);
}
System.exit(0);
} else {
log.warn("Bootstrap: command \"" + command + "\" does not exist.");
}
} catch (Throwable t) {
// Unwrap the Exception for clearer error reporting
if (t instanceof InvocationTargetException &&
t.getCause() != null) {
t = t.getCause();
}
handleThrowable(t);
t.printStackTrace();
System.exit(1);
}
}熟悉这个方法或者看过我们上篇文章的同学都知道, 我已经把类加载那部分代码去除了, 因为我们今天不研究类加载. 所以 ,我们看逻辑, 首先, 判断命令是什么, 我们现在的命令肯定是 start 啊, 所以进入 else if 块, 调用 load 方法 , 进入 load 方法, 可以看到, 该方法实际上就是 Catalina 类的 load 方法, 那么我们进入 Catalina 类的 load 方法看看(方法很长, 楼主去除了和今天的模块无关的代码):
public void load() {
// Start the new server
try {
getServer().init();
} catch (LifecycleException e) {
if (Boolean.getBoolean("org.apache.catalina.startup.EXIT_ON_INIT_FAILURE")) {
throw new java.lang.Error(e);
} else {
log.error("Catalina.start", e);
}
}
}可以看到, 这里有一个我们今天感兴趣的方法, getServer.init(), 这个方法看名字是启动 Server 的初始化, 而 Server 是我们上面图中最外层的容器. 因此, 我们去看看该方法, 也就是LifecycleBase.init() 方法. 该方法是一个模板方法, 只是定义了一个算法的骨架, 将一些细节算法延迟到了子类中. 看, 我们又学到了一个设计模式. 我们看看该方法:
@Override
public final synchronized void init() throws LifecycleException {
// 1
if (!state.equals(LifecycleState.NEW)) {
invalidTransition(Lifecycle.BEFORE_INIT_EVENT);
}
// 2
setStateInternal(LifecycleState.INITIALIZING, null, false);
try {
// 模板方法
/**
* 采用模板方法模式来对所有支持生命周期管理的组件的生命周期各个阶段进行了总体管理,
* 每个需要生命周期管理的组件只需要继承这个基类,
* 然后覆盖对应的钩子方法即可完成相应的声明周期阶段的管理工作
*/
initInternal();
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
setStateInternal(LifecycleState.FAILED, null, false);
throw new LifecycleException(
sm.getString("lifecycleBase.initFail",toString()), t);
}
// 3
setStateInternal(LifecycleState.INITIALIZED, null, false);
}我们看看该方法, 这应该就是容器启动的逻辑了, 先前我们定义了那么多状态, 现在用上了. 首先判断该方法的状态, 如果不是 NEW, 则抛出异常, 否则则设置状态为 INITIALIZING, 然后调用一个抽象方法 initInternal , 该方法由子类具体实现. 执行完则修改状态为 INITIALIZED. 这里应该是使用了状态模式. 依赖状态时,同步该方法, 防止并发错误. tomcat 可以的.
5. 那么我们来看看 StandardServer 是如何实现 initInternal 方法的:
@Override
protected void initInternal() throws LifecycleException {
super.initInternal();
// Register global String cache
// Note although the cache is global, if there are multiple Servers
// present in the JVM (may happen when embedding) then the same cache
// will be registered under multiple names
onameStringCache = register(new StringCache(), "type=StringCache");
// Register the MBeanFactory
MBeanFactory factory = new MBeanFactory();
factory.setContainer(this);
onameMBeanFactory = register(factory, "type=MBeanFactory");
// Register the naming resources
globalNamingResources.init();
// Populate the extension validator with JARs from common and shared
// class loaders
if (getCatalina() != null) {
ClassLoader cl = getCatalina().getParentClassLoader();
// Walk the class loader hierarchy. Stop at the system class loader.
// This will add the shared (if present) and common class loaders
while (cl != null && cl != ClassLoader.getSystemClassLoader()) {
if (cl instanceof URLClassLoader) {
URL[] urls = ((URLClassLoader) cl).getURLs();
for (URL url : urls) {
if (url.getProtocol().equals("file")) {
try {
File f = new File (url.toURI());
if (f.isFile() &&
f.getName().endsWith(".jar")) {
ExtensionValidator.addSystemResource(f);
}
} catch (URISyntaxException e) {
// Ignore
} catch (IOException e) {
// Ignore
}
}
}
}
cl = cl.getParent();
}
}
// Initialize our defined Services
for (int i = 0; i < services.length; i++) {
services[i].init();
}
}6. LifecycleMBeanBase.initInternal() 实现
首先调用父类的 super.initInternal() 方法,此initInternal方法用于将容器托管到JMX,便于运维管理:
@Override
protected void initInternal() throws LifecycleException {
// If oname is not null then registration has already happened via
// preRegister().
if (oname == null) {
mserver = Registry.getRegistry(null, null).getMBeanServer();
oname = register(this, getObjectNameKeyProperties());
}
}7. LifecycleMBeanBase.register 方法实现
LifecycleMBeanBase 会调用自身的 register 方法, 该方法会将容器注册到 MBeanServer:
protected final ObjectName register(Object obj,
String objectNameKeyProperties) {
// Construct an object name with the right domain
StringBuilder name = new StringBuilder(getDomain());
name.append(':');
name.append(objectNameKeyProperties);
ObjectName on = null;
try {
on = new ObjectName(name.toString());
// 核心实现:registerComponent
Registry.getRegistry(null, null).registerComponent(obj, on, null);
} catch (MalformedObjectNameException e) {
log.warn(sm.getString("lifecycleMBeanBase.registerFail", obj, name),
e);
} catch (Exception e) {
log.warn(sm.getString("lifecycleMBeanBase.registerFail", obj, name),
e);
}
return on;
}该方法内部核心方法是 Registry. registerComponent, 在org.apache.catalina.util 包下, 我们看看该方法实现。
8. Registry.registerComponent 方法实现
public void registerComponent(Object bean, ObjectName oname, String type)
throws Exception
{
if( log.isDebugEnabled() ) {
log.debug( "Managed= "+ oname);
}
if( bean ==null ) {
log.error("Null component " + oname );
return;
}
try {
if( type==null ) {
type=bean.getClass().getName();
}
ManagedBean managed = findManagedBean(bean.getClass(), type);
// The real mbean is created and registered
DynamicMBean mbean = managed.createMBean(bean);
if( getMBeanServer().isRegistered( oname )) {
if( log.isDebugEnabled()) {
log.debug("Unregistering existing component " + oname );
}
getMBeanServer().unregisterMBean( oname );
}
getMBeanServer().registerMBean( mbean, oname);
} catch( Exception ex) {
log.error("Error registering " + oname, ex );
throw ex;
}
}该方法会为当前容器创建一个 DynamicMBean , 并且注册到MBeanServer。调用 MBeanServer.registerMBean() 方法。而 MBeanServer 在 javax.management, 也就是 rt.jar 中,该包由 java 的 BootStrap 启动类加载器加载。
注册进MBeanServer 的 key 是什么呢? 相信细心的同学会注意到 LifecycleMBeanBase.getObjectNameKeyProperties 和 LifecycleMBeanBase.getDomain 方法 和
LifecycleMBeanBase.getDomainInternal 方法, 这三个方法由具体子类实现,会生成一个专属于容器的key。格式为:Catalina:type=Server, 这是 Server 容器的 key, debug 可以看出来:

9. JMX 如何管理 组件?
至此, 我们已经知道 Tomcat 是如何将容器注册到 MBeanServer 中的。 那么注册到 MBeanServer 中后是什么样子呢?我们看图:

这是 JDK 自带的 JvisualVM 工具, 添加了 MBeans 插件, 就可以远程操作容器中的 组件了, 可以看到 Service 容器暴漏了很多接口, 用于运维人员管理容器和组件。
10. 回到 StandardServer.initInternal 方法
好了, 我们回到 StandardServer.initInternal 方法, 回到我们梦最开始的地方,super.initInternal 方法就是将容器注册到 JMX 中。 那下面的逻辑是做什么的呢? 在执行完父类的 super.initInternal 的方法后, 该方法又注册个两个 JMX 。然后寻启动子容器的 init 方法:
// Initialize our defined Services
for (int i = 0; i < services.length; i++) {
services[i].init();
}而子容器的 init 方法和 Server 的 init 方法的逻辑基本一致,所以不再赘述。
11. 执行完 getServer().init() 方法后做什么——容器启动
Bootstrap 的 load 方法调用了 Catalina 的 load 方法 ,该方法调用了Server 的init方法,执行完初始化过程,当然就是要执行 start 方法了, 那么如何执行呢?
Bootstrap 调用了 Catalina 的 start 方法,该方法也同样执行了 Server 的 start 方法, 该方法的具体实现也在LifecycleBase 中:
@Override
public final synchronized void start() throws LifecycleException {
if (LifecycleState.STARTING_PREP.equals(state) ||
LifecycleState.STARTING.equals(state) ||
LifecycleState.STARTED.equals(state)) {
if (log.isDebugEnabled()) {
Exception e = new LifecycleException();
log.debug(sm.getString("lifecycleBase.alreadyStarted",
toString()), e);
} else if (log.isInfoEnabled()) {
log.info(sm.getString("lifecycleBase.alreadyStarted",
toString()));
}
return;
}
if (state.equals(LifecycleState.NEW)) {
init();
} else if (state.equals(LifecycleState.FAILED)){
stop();
} else if (!state.equals(LifecycleState.INITIALIZED) &&
!state.equals(LifecycleState.STOPPED)) {
invalidTransition(Lifecycle.BEFORE_START_EVENT);
}
setStateInternal(LifecycleState.STARTING_PREP, null, false);
try {
startInternal();
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
setStateInternal(LifecycleState.FAILED, null, false);
throw new LifecycleException(
sm.getString("lifecycleBase.startFail",toString()), t);
}
if (state.equals(LifecycleState.FAILED) ||
state.equals(LifecycleState.MUST_STOP)) {
stop();
} else {
// Shouldn't be necessary but acts as a check that sub-classes are
// doing what they are supposed to.
if (!state.equals(LifecycleState.STARTING)) {
invalidTransition(Lifecycle.AFTER_START_EVENT);
}
setStateInternal(LifecycleState.STARTED, null, false);
}
}12. StandardServer.startInternal 启动容器方法实现
可以看到该方法对状态的判断特别多,我们感兴趣的是 try 块中的 startInternal() 方法, 同样, 该方法也是个抽象方法,需要子类去具体实现自己的启动逻辑。我们看看Server 的启动逻辑:
@Override
protected void startInternal() throws LifecycleException {
fireLifecycleEvent(CONFIGURE_START_EVENT, null);
setState(LifecycleState.STARTING);//将自身状态更改为LifecycleState.STARTING;
globalNamingResources.start();
// Start our defined Services
synchronized (services) {
for (int i = 0; i < services.length; i++) {
services[i].start();// 启动所有子容器
}
}
}13. LifecycleSupport.fireLifecycleEvent()方法实现
该方法首先执行自己的fireLifecycleEvent方法, 该方法内部是LifecycleSupport.fireLifecycleEvent()方法, 我们进入该方法看个究竟:
public void fireLifecycleEvent(String type, Object data) {
// 事件监听,观察者模式的另一种方式
LifecycleEvent event = new LifecycleEvent(lifecycle, type, data);
LifecycleListener interested[] = listeners;// 监听器数组 关注 事件(启动或者关闭事件)
// 循环通知所有生命周期时间侦听器????
for (int i = 0; i < interested.length; i++)
// 每个监听器都有自己的逻辑
interested[i].lifecycleEvent(event);
}该方法很简单, 楼主没有删一行代码, 首先, 创建一个事件对象, 然通知所有的监听器发生了该事件.并做响应.那么 Server 有哪些监听器呢?

这些监听器将根据这个事件的类型做出响应.
14. 我们回到 startInternal 方法, 启动所有容器
事件监听结束之后, 调用 setState(LifecycleState.STARTING); 表明状态时开始中, 并且循环启动子容器, 这里的 Server 启动的是Service 数组, 循环启动他们的 start 方法. 以此类推. 启动所有的容器:
synchronized (services) {
for (int i = 0; i < services.length; i++) {
services[i].start();// 启动所有子容器
}
}现在我们关注的是Server 容器, 因此, Server 会启动 services 数组中的所有 Service 组件。该方法就完成了通知所有监听器发送了启动事件,然后使用观察者模式,启动所有子容器,然后子容器继续递归启动。最后修改自己的状态并告诉监听器。
15. 总结
其实楼主在啃代码最深的感触就是设计模式, 真的很牛逼,不知道同学们发现了几个设计模式,楼主在本篇文章中发现了状态模式, 观察者模式,模板方法, 事件监听,代理模式。真的收益良多。不枉楼主每天看代码。
还有就是对 Tomcat 生命周期组件的总结。我们再看看我们的类图:
tomcat 的主要容器都继承了 LifecycleMBeanBase 抽象类,该类中关于 init 和 start 两个模板方法。定义了主要算法骨架,而方法中又都有抽象方法,需要子类自己去实现。而 LifecycleBase 中又定义了如何实现事件监听代理,LifecycleBase 依赖 LifecycleSupport 去完成真正的事件监听。对了,监听器是如何添加进 LifecycleSupport 的呢?LifecycleSupport 中含有
addLifecycleListener 方法。该方法也是被LifecycleBase代理的。而每个容器下面的子容器也是使用相同的逻辑完成初始化和启动。父容器和子容器使用了聚合的方式设计。
可以说, tomcat的容器的生命周期组件设计是非常牛逼的。我们阅读源码不仅能了解他的设计原理,也能同大师交流,学会更多。
好了, 今天的深入理解 Tomcat(六)源码剖析Tomcat 启动过程—-生命周期和容器组件就到这里,谢谢大家的耐心,再这个世界,耐心和坚持是无比珍贵的。尤其是程序员。
深入理解 Tomcat(七)源码剖析 Tomcat 完整启动过程_ignore-CSDN博客_深入剖析tomcat 源码
前言
这是我们分析 Tomcat 的第七篇文章,前面我们依据启动过程理解了类加载过程,生命周期组件,容器组件等。基本上将启动过程拆的七零八落,分析的差不多了, 但是还没有从整体的视图下来分析Tomcat 的启动过程。因此,这篇文章的任务就是这个,我们想将Tomcat的启动过程彻底的摸清,把它最后一件衣服扒掉。然后我们就分析连接器和URL请求了,不再留恋这里了。
好吧。我们开始吧。
说到Tomcat的启动,我们都知道,我们每次需要运行tomcat/bin/startup.sh这个脚本,而这个脚本的内容到底是什么呢?我们来看看。
1. startup.sh 脚本内容
#!/bin/sh
os400=false
case "`uname`" in
OS400*) os400=true;;
esac
# resolve links - $0 may be a softlink
PRG="$0"
while [ -h "$PRG" ] ; do
ls=`ls -ld "$PRG"`
link=`expr "$ls" : '.*-> \(.*\)$'`
if expr "$link" : '/.*' > /dev/null; then
PRG="$link"
else
PRG=`dirname "$PRG"`/"$link"
fi
done
PRGDIR=`dirname "$PRG"`
EXECUTABLE=catalina.sh
# Check that target executable exists
if $os400; then
# -x will Only work on the os400 if the files are:
# 1. owned by the user
# 2. owned by the PRIMARY group of the user
# this will not work if the user belongs in secondary groups
eval
else
if [ ! -x "$PRGDIR"/"$EXECUTABLE" ]; then
echo "Cannot find $PRGDIR/$EXECUTABLE"
echo "The file is absent or does not have execute permission"
echo "This file is needed to run this program"
exit 1
fi
fi
exec "$PRGDIR"/"$EXECUTABLE" start "$@"楼主删除了一些无用的注释,我们来看看这脚本。该脚本中有2个重要的变量:
1. PRGDIR:表示当前脚本所在的路径
2. EXECUTABLE:catalina.sh 脚本名称
其中最关键的一行代码就是 exec "$PRGDIR"/"$EXECUTABLE" start "$@",表示执行了脚本catalina.sh,参数是start。
2. catalina.sh 脚本实现
然后我们看看catalina.sh 脚本中的实现:
elif [ "$1" = "start" ] ; then
if [ ! -z "$CATALINA_PID" ]; then
if [ -f "$CATALINA_PID" ]; then
if [ -s "$CATALINA_PID" ]; then
echo "Existing PID file found during start."
if [ -r "$CATALINA_PID" ]; then
PID=`cat "$CATALINA_PID"`
ps -p $PID >/dev/null 2>&1
if [ $? -eq 0 ] ; then
echo "Tomcat appears to still be running with PID $PID. Start aborted."
echo "If the following process is not a Tomcat process, remove the PID file and try again:"
ps -f -p $PID
exit 1
else
echo "Removing/clearing stale PID file."
rm -f "$CATALINA_PID" >/dev/null 2>&1
if [ $? != 0 ]; then
if [ -w "$CATALINA_PID" ]; then
cat /dev/null > "$CATALINA_PID"
else
echo "Unable to remove or clear stale PID file. Start aborted."
exit 1
fi
fi
fi
else
echo "Unable to read PID file. Start aborted."
exit 1
fi
else
rm -f "$CATALINA_PID" >/dev/null 2>&1
if [ $? != 0 ]; then
if [ ! -w "$CATALINA_PID" ]; then
echo "Unable to remove or write to empty PID file. Start aborted."
exit 1
fi
fi
fi
fi
fi
shift
touch "$CATALINA_OUT"
if [ "$1" = "-security" ] ; then
if [ $have_tty -eq 1 ]; then
echo "Using Security Manager"
fi
shift
eval $_NOHUP "\"$_RUNJAVA\"" "\"$LOGGING_CONFIG\"" $LOGGING_MANAGER $JAVA_OPTS $CATALINA_OPTS \
-classpath "\"$CLASSPATH\"" \
-Djava.security.manager \
-Djava.security.policy=="\"$CATALINA_BASE/conf/catalina.policy\"" \
-Dcatalina.base="\"$CATALINA_BASE\"" \
-Dcatalina.home="\"$CATALINA_HOME\"" \
-Djava.io.tmpdir="\"$CATALINA_TMPDIR\"" \
org.apache.catalina.startup.Bootstrap "$@" start \
>> "$CATALINA_OUT" 2>&1 "&"
else
eval $_NOHUP "\"$_RUNJAVA\"" "\"$LOGGING_CONFIG\"" $LOGGING_MANAGER $JAVA_OPTS $CATALINA_OPTS \
-classpath "\"$CLASSPATH\"" \
-Dcatalina.base="\"$CATALINA_BASE\"" \
-Dcatalina.home="\"$CATALINA_HOME\"" \
-Djava.io.tmpdir="\"$CATALINA_TMPDIR\"" \
org.apache.catalina.startup.Bootstrap "$@" start \
>> "$CATALINA_OUT" 2>&1 "&"
fi
if [ ! -z "$CATALINA_PID" ]; then
echo $! > "$CATALINA_PID"
fi
echo "Tomcat started."该脚本很长,但我们只关心我们感兴趣的:如果参数是 start, 那么执行这里的逻辑,关键再最后一行执行了 org.apache.catalina.startup.Bootstrap "$@" start, 也就是说,执行了我们熟悉的main方法,并且携带了start 参数,那么我们就来看Bootstrap 的main方法是如何实现的。
3. Bootstrap.main 方法实现
public static void main(String args[]) {
System.err.println("Have fun and Enjoy! cxs");
// daemon 就是 bootstrap
if (daemon == null) {
Bootstrap bootstrap = new Bootstrap();
try {
bootstrap.init();
} catch (Throwable t) {
handleThrowable(t);
t.printStackTrace();
return;
}
daemon = bootstrap;
} else {
Thread.currentThread().setContextClassLoader(daemon.catalinaLoader);
}
try {
String command = "start";
if (args.length > 0) {
command = args[args.length - 1];
}
if (command.equals("startd")) {
args[args.length - 1] = "start";
daemon.load(args);
daemon.start();
}
else if (command.equals("stopd")) {
args[args.length - 1] = "stop";
daemon.stop();
}
else if (command.equals("start")) {
daemon.setAwait(true);
daemon.load(args);
daemon.start();
} else if (command.equals("stop")) {
daemon.stopServer(args);
} else if (command.equals("configtest")) {
daemon.load(args);
if (null==daemon.getServer()) {
System.exit(1);
}
System.exit(0);
} else {
log.warn("Bootstrap: command \"" + command + "\" does not exist.");
}
} catch (Throwable t) {
if (t instanceof InvocationTargetException &&
t.getCause() != null) {
t = t.getCause();
}
handleThrowable(t);
t.printStackTrace();
System.exit(1);
}
}我们看看该方法, 首先 bootstrap.init() 的方法用于初始化类加载器,我们已经分析过该方法了,就不再赘述了,然后我们看下面的try块,默认命令行参数是 start ,但我们刚刚的脚本传的参数就是 start, 因此进入该if块
else if (command.equals("start")) {
daemon.setAwait(true);
daemon.load(args);
daemon.start();- 设置catalina 的 await 属性为true;
- 运行 catalina 的 load 方法。该方法内部主要逻辑是解析server.xml文件,初始化容器。我们已经再生命周期那篇文章中讲过容器的初始化。
- 运行 catalina 的 start 方法。也就是启动 tomcat。这个部分我们上次分析了容器启动。但是容器之后的逻辑我们没有分析。今天我们就来看看。
4. Catalina.start 方法
public void start() {
if (getServer() == null) {
load();
}
if (getServer() == null) {
log.fatal("Cannot start server. Server instance is not configured.");
return;
}
long t1 = System.nanoTime();
// Start the new server
try {
getServer().start();
} catch (LifecycleException e) {
log.fatal(sm.getString("catalina.serverStartFail"), e);
try {
getServer().destroy();
} catch (LifecycleException e1) {
log.debug("destroy() failed for failed Server ", e1);
}
return;
}
long t2 = System.nanoTime();
if(log.isInfoEnabled()) {
log.info("Server startup in " + ((t2 - t1) / 1000000) + " ms");
}
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);
// If JULI is being used, disable JULI's shutdown hook since
// shutdown hooks run in parallel and log messages may be lost
// if JULI's hook completes before the CatalinaShutdownHook()
LogManager logManager = LogManager.getLogManager();
if (logManager instanceof ClassLoaderLogManager) {
((ClassLoaderLogManager) logManager).setUseShutdownHook(
false);
}
}
if (await) {
await();
stop();
}
}该方法我们上次分析到了 getServer().start() 这里,也就是容器启动的逻辑,我们不再赘述。
今天我们继续分析下面的逻辑。主要逻辑是:
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);
// If JULI is being used, disable JULI's shutdown hook since
// shutdown hooks run in parallel and log messages may be lost
// if JULI's hook completes before the CatalinaShutdownHook()
LogManager logManager = LogManager.getLogManager();
if (logManager instanceof ClassLoaderLogManager) {
((ClassLoaderLogManager) logManager).setUseShutdownHook(
false);
}
}
if (await) {
await();
stop();
}可以看到是 Runtime.getRuntime().addShutdownHook(shutdownHook)方法。那么这个方法的作用是什么呢?JDK 文档是这样说的:
注册新的虚拟机来关闭钩子。
只是一个已初始化但尚未启动的线程。虚拟机开始启用其关闭序列时,它会以某种未指定的顺序启动所有已注册的关闭钩子,并让它们同时运行。运行完所有的钩子后,如果已启用退出终结,那么虚拟机接着会运行所有未调用的终结方法。最后,虚拟机会暂停。注意,关闭序列期间会继续运行守护线程,如果通过调用方法来发起关闭序列,那么也会继续运行非守护线程。
简单来说,如果用户的程序出现了bug, 或者使用control + C 关闭了命令行,那么就需要做一些内存清理的工作。该方法就会再虚拟机退出时做清理工作。再ApplicationShutdownHooks 类种维护着一个IdentityHashMap
5. CatalinaShutdownHook.run 线程方法实现
protected class CatalinaShutdownHook extends Thread {
@Override
public void run() {
try {
if (getServer() != null) {
Catalina.this.stop();
}
} catch (Throwable ex) {
ExceptionUtils.handleThrowable(ex);
log.error(sm.getString("catalina.shutdownHookFail"), ex);
} finally {
// If JULI is used, shut JULI down *after* the server shuts down
// so log messages aren't lost
LogManager logManager = LogManager.getLogManager();
if (logManager instanceof ClassLoaderLogManager) {
((ClassLoaderLogManager) logManager).shutdown();
}
}
}
}该线程是Catalina的内部类,方法逻辑是,如果Server容器还存在,就是执行Catalina的stop方法用于停止容器。(为什么要用Catalina.this.stop 呢?因为它继承了Thread,而Thread也有一个stop方法,因此需要显式的指定该方法)最后关闭日志管理器。我们看看stop方法的实现:
6. Catalina.stop 方法实现:
public void stop() {
try {
// Remove the ShutdownHook first so that server.stop()
// doesn't get invoked twice
if (useShutdownHook) {
Runtime.getRuntime().removeShutdownHook(shutdownHook);
// If JULI is being used, re-enable JULI's shutdown to ensure
// log messages are not lost
LogManager logManager = LogManager.getLogManager();
if (logManager instanceof ClassLoaderLogManager) {
((ClassLoaderLogManager) logManager).setUseShutdownHook(
true);
}
}
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
// This will fail on JDK 1.2. Ignoring, as Tomcat can run
// fine without the shutdown hook.
}
// Shut down the server
try {
Server s = getServer();
LifecycleState state = s.getState();
if (LifecycleState.STOPPING_PREP.compareTo(state) <= 0
&& LifecycleState.DESTROYED.compareTo(state) >= 0) {
// Nothing to do. stop() was already called
} else {
s.stop();
s.destroy();
}
} catch (LifecycleException e) {
log.error("Catalina.stop", e);
}
}该方法首先移除关闭钩子,为什么要移除呢,因为他的任务已经完成了。然后设置useShutdownHook 为true。最后执行Server的stop方法,Server的stop方法基本和init方法和start方法一样,都是使用父类的模板方法,首先出发事件,然后调用stopInternal,该方法内部循环停止子容器,子容器递归停止,和我们之前的逻辑一致,不再赘述。destroy方法同理。
好了,我们已经看清了关闭钩子的逻辑,其实就是开辟一个守护线程交给虚拟机,然后虚拟机在某些异常情况(比如System.exit(0))前执行停止容器的逻辑。
好。我们回到start方法。
7. 回到 Catalina.start 方法
在设置好关闭钩子后,tomcat 的启动过程还没有启动完毕,接下来的逻辑式什么呢?
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);
// If JULI is being used, disable JULI's shutdown hook since
// shutdown hooks run in parallel and log messages may be lost
// if JULI's hook completes before the CatalinaShutdownHook()
LogManager logManager = LogManager.getLogManager();
if (logManager instanceof ClassLoaderLogManager) {
((ClassLoaderLogManager) logManager).setUseShutdownHook(
false);
}
}
if (await) {
await();
stop();
}在设置完关闭钩子之后,会将 useShutdownHook 这个变量为false,然后执行 await 方法。然后执行stop方法,我们记得stop方法式关闭容器的方法,神经病啊,好不容易启动了,为什么又要关闭呢? 先不着急,我们还是看看 await 方法吧,该方法调用了Server.await 方法,我们来看看:
8. Catalian.await 方法实现
注意:该方法很长
@Override
public void await() {
// Negative values - don't wait on port - tomcat is embedded or we just don't like ports
if( port == -2 ) {
// undocumented yet - for embedding apps that are around, alive.
return;
}
if( port==-1 ) {
try {
awaitThread = Thread.currentThread();
while(!stopAwait) {
try {
Thread.sleep( 10000 );
} catch( InterruptedException ex ) {
// continue and check the flag
}
}
} finally {
awaitThread = null;
}
return;
}
// Set up a server socket to wait on
try {
awaitSocket = new ServerSocket(port, 1,
InetAddress.getByName(address));
} catch (IOException e) {
log.error("StandardServer.await: create[" + address
+ ":" + port
+ "]: ", e);
return;
}
try {
awaitThread = Thread.currentThread();
// Loop waiting for a connection and a valid command
while (!stopAwait) {
ServerSocket serverSocket = awaitSocket;
if (serverSocket == null) {
break;
}
// Wait for the next connection
Socket socket = null;
StringBuilder command = new StringBuilder();
try {
InputStream stream;
try {
socket = serverSocket.accept();
socket.setSoTimeout(10 * 1000); // Ten seconds
stream = socket.getInputStream();
} catch (AccessControlException ace) {
log.warn("StandardServer.accept security exception: "
+ ace.getMessage(), ace);
continue;
} catch (IOException e) {
if (stopAwait) {
// Wait was aborted with socket.close()
break;
}
log.error("StandardServer.await: accept: ", e);
break;
}
// Read a set of characters from the socket
int expected = 1024; // Cut off to avoid DoS attack
while (expected < shutdown.length()) {
if (random == null)
random = new Random();
expected += (random.nextInt() % 1024);
}
while (expected > 0) {
int ch = -1;
try {
ch = stream.read();
} catch (IOException e) {
log.warn("StandardServer.await: read: ", e);
ch = -1;
}
if (ch < 32) // Control character or EOF terminates loop
break;
command.append((char) ch);
expected--;
}
} finally {
// Close the socket now that we are done with it
try {
if (socket != null) {
socket.close();
}
} catch (IOException e) {
// Ignore
}
}
// Match against our command string
boolean match = command.toString().equals(shutdown);
if (match) {
log.info(sm.getString("standardServer.shutdownViaPort"));
break;
} else
log.warn("StandardServer.await: Invalid command '"
+ command.toString() + "' received");
}
} finally {
ServerSocket serverSocket = awaitSocket;
awaitThread = null;
awaitSocket = null;
// Close the server socket and return
if (serverSocket != null) {
try {
serverSocket.close();
} catch (IOException e) {
// Ignore
}
}
}
}我们看一下他的逻辑:首先创建一个socketServer 链接,然后循环等待消息。如果发过来的消息为字符串SHUTDOWN, 那么就break,停止循环,关闭socket。否则永不停歇。回到我们刚刚的疑问,await 方法后面执行 stop 方法,现在一看就合情合理了,只要不发出关闭命令,则不会执行stop方法,否则则继续执行关闭方法。
到现在,Tomcat 的整体启动过程我们已经了然于胸了,总结一下就是:
1. 初始化类加载器。
2. 初始化容器并注册到JMX后启动容器。
3. 设置关闭钩子。
4. 循环等待关闭命令。
等一下。好像缺了点什么??? Tomcat 启动后就只接受关闭命令,接受的http请求怎么处理,还要不要做一个合格的服务器了??? 别急,实际上,这个是主线程,负责生命周期等事情。处理Http请求的线程在初始化容器和启动容器的时候由子容器做了,这块的逻辑我们下次再讲。大家不要疑惑。
9. 我们知道了Tomcat 是怎么启动的,那么是怎么关闭的呢?
顺便说说关闭的逻辑:
shutdown.sh 脚本同样会调用 Bootstrap的main 方法,不同是传递 stop参数, 我们看看如果传递stop参数会怎么样:
ry {
String command = "start";
if (args.length > 0) {
command = args[args.length - 1];
}
if (command.equals("startd")) {
args[args.length - 1] = "start";
daemon.load(args);
daemon.start();
}
else if (command.equals("stopd")) {
args[args.length - 1] = "stop";
daemon.stop();
}
else if (command.equals("start")) {
daemon.setAwait(true);
daemon.load(args);
daemon.start();
} else if (command.equals("stop")) {
daemon.stopServer(args);
} else if (command.equals("configtest")) {
daemon.load(args);
if (null==daemon.getServer()) {
System.exit(1);
}
System.exit(0);
} else {
log.warn("Bootstrap: command \"" + command + "\" does not exist.");
}
} catch (Throwable t) {可以看到调用的是 stopServer 方法,实际上就是 Catalina的stopServer 方法,我们看看该方法实现:
10. Catalina.stopServer 方法
public void stopServer(String[] arguments) {
if (arguments != null) {
arguments(arguments);
}
Server s = getServer();
if( s == null ) {
// Create and execute our Digester
Digester digester = createStopDigester();
digester.setClassLoader(Thread.currentThread().getContextClassLoader());
File file = configFile();
FileInputStream fis = null;
try {
InputSource is =
new InputSource(file.toURI().toURL().toString());
fis = new FileInputStream(file);
is.setByteStream(fis);
digester.push(this);
digester.parse(is);
} catch (Exception e) {
log.error("Catalina.stop: ", e);
System.exit(1);
} finally {
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
// Ignore
}
}
}
} else {
// Server object already present. Must be running as a service
try {
s.stop();
} catch (LifecycleException e) {
log.error("Catalina.stop: ", e);
}
return;
}
// Stop the existing server
s = getServer();
if (s.getPort()>0) {
Socket socket = null;
OutputStream stream = null;
try {
socket = new Socket(s.getAddress(), s.getPort());
stream = socket.getOutputStream();
String shutdown = s.getShutdown();
for (int i = 0; i < shutdown.length(); i++) {
stream.write(shutdown.charAt(i));
}
stream.flush();
} catch (ConnectException ce) {
log.error(sm.getString("catalina.stopServer.connectException",
s.getAddress(),
String.valueOf(s.getPort())));
log.error("Catalina.stop: ", ce);
System.exit(1);
} catch (IOException e) {
log.error("Catalina.stop: ", e);
System.exit(1);
} finally {
if (stream != null) {
try {
stream.close();
} catch (IOException e) {
// Ignore
}
}
if (socket != null) {
try {
socket.close();
} catch (IOException e) {
// Ignore
}
}
}
} else {
log.error(sm.getString("catalina.stopServer"));
System.exit(1);
}
}注意,该停止命令的虚拟机和启动的虚拟机不是一个虚拟机,因此,没有初始化 Server , 进入 IF 块,解析 server.xml 文件,获取文件中端口,用以创建Socket。然后像启动服务器发送 SHUTDOWN 命令,关闭启动服务器,启动服务器退出刚刚的循环,执行后面的 stop 方法,最后退出虚拟机,就是这么简单。
11. 总结
我们从整体上解析了Tomcat的启动和关闭过程,发现不是很难,为什么?因为我们之前已经分析过很多遍了,有些逻辑我们已经清除了,这次分析只是来扫尾。复杂的Tomcat的启动过程我们基本就分析完了。我们知道了启动和关闭都依赖Socket。只是我们惊奇的发现他的关闭竟然是如此实现。很牛逼。我原以为会像我们平时一样,直接kill。哈哈哈。
好吧。今天我们就到这里 ,tomcat 这座大山我们已经啃的差不多了,还剩一个 URL 请求过程和连接器,这两个部分是高度关联的,因此,楼主也会将他们放在一起分析。透过源码看真相。
连接器,等着我们来撕开你的衣服!!!!
深入理解 Tomcat(八)源码剖析之连接器_ignore-CSDN博客
这是我们分析tomcat的第八篇文章,这次我们分析连接器,我们早就想分析连接器了,因为各种原因拖了好久。不过也确实复杂。
首先我们之前定义过连接器:
Tomcat都是在容器里面处理问题的, 而容器又到哪里去取得输入信息呢? Connector就是专干这个的。 他会把从socket传递过来的数据, 封装成Request, 传递给容器来处理。 通常我们会用到两种Connector,一种叫http connectoer, 用来传递http需求的。 另一种叫AJP, 在我们整合apache与tomcat工作的时候,apache与tomcat之间就是通过这个协议来互动的。 (说到apache与tomcat的整合工作, 通常我们的目的是为了让apache 获取静态资源, 而让tomcat来解析动态的jsp或者servlet。)
简单来说,连接器就是接收http请求并解析http请求,然后将请求交给servlet容器。
那么在 Tomcat中 ,那个类表示连接器呢? 答案是 org.apache.catalina.connector.Connector,该类继承自 LifecycleMBeanBase, 也就是说,该类的生命周期归属于容器管理。而该类的父容器是谁呢? 答案是 org.apache.catalina.core.StandardService,也就是我们的Service 组件,StandardService是该接口的标准实现。StandardService 聚合了 Connector 数组和一个Container 容器,也就验证了我们之前说的一个Service 组件中包含一个Container和多个连接器。
那么连接器什么时候初始化被放入容器和JMX呢?这是个大问题,也是我们今天的主要问题。
1. Tomcat 解析 server.xml 并创建对象
我们之前扒过启动源码,我们知道,在Catalina 的 load 方法中是初始化容器的方法,所有的容器都是在该方法中初始化的。Connector 也不例外。我们还记得 Tomcat 的conf 目录下的server.xml 文件吗?
<?xml version='1.0' encoding='utf-8'?>
<Server port="8005" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.startup.VersionLoggerListener" />
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<Listener className="org.apache.catalina.core.JasperListener" />
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
<GlobalNamingResources>
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<Service name="Catalina">
<Connector port="8061" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
<Engine name="Catalina" defaultHost="localhost">
<Realm className="org.apache.catalina.realm.LockOutRealm">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
</Realm>
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log." suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
</Engine>
</Service>
</Server>可以看到该配置文件中有2个Connector 标签,有就是说默认有2个连接器。一个是HTTP协议,一个AJP协议。
我们的Connector是什么时候创建的呢?就是在解析这个xml文件的时候,那么是怎么解析的呢?我们平时在解析 xml 的时候经常使用dom4j(真的不喜欢xml,最爱json),而tomcat 使用的是 Digester 解析xml,我们来看看 Catalina.load() 关于解析并创建容器的关键代码:
public void load() {
// Create and execute our Digester
Digester digester = createStartDigester();
digester.parse(inputSource);
}首先创建一个 Digester, 其中的关键代码我们看看:
Digester digester = new Digester();
digester.addRule("Server/Service/Connector",
new ConnectorCreateRule());
digester.addRule("Server/Service/Connector",
new SetAllPropertiesRule(new String[]{"executor"}));
digester.addSetNext("Server/Service/Connector",
"addConnector",
"org.apache.catalina.connector.Connector");上面的代码的意思是将对应的字符串创建成对应的角色,以便后面和xml对应便解析。
我们再看看它是如何解析的,由于 digester.parse(inputSource) 这个方法调用层次太深,而且该方法只是解析xml,因此楼主把就不把每段代码贴出来了,我们看看IDEA生成的该方法的方法调用栈:这些方法都是在 rt.jar 包中,因此我们不做分析了。主要就是解析xml。

上图是楼主在 Digester.startDocument 的方法中打的断点。该方法作用为开始解析 xml 做准备。

上图是楼主在 Digester.startElement 的方法中打的断点,startDocument 和 startElement 是多次交替执行的,确定他们执行逻辑的是什么方法呢?从堆栈图中我们可以看到:是 com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse()这个方法,代码我就不贴出来了,很长没有意义,该方法在 819行间接调用 startDocument,在841行间接调用startElement。上下执行,并且回执行多次。因为 xml 会解析多次嘛。
我们重点说说 startElement 方法:
public void startElement(String namespaceURI, String localName,
String qName, Attributes list) {
List<Rule> rules = getRules().match(namespaceURI, match);
matches.push(rules);
if ((rules != null) && (rules.size() > 0)) {
for (int i = 0; i < rules.size(); i++) {
try {
Rule rule = rules.get(i);
if (debug) {
log.debug(" Fire begin() for " + rule);
}
rule.begin(namespaceURI, name, list);
} catch (Exception e) {
log.error("Begin event threw exception", e);
throw createSAXException(e);
} catch (Error e) {
log.error("Begin event threw error", e);
throw e;
}
}
}
}楼主只贴了关键代码,就是for循环中的逻辑,便利 Rule 集合,Rule 是什么呢?是我们之前 createStartDigester 方法里创建的。而 Rule 是一个接口,tomcat 中有很多不同的实现。然后循环调用他们的 begin 方法。我们看看有哪些实现:

我们从上图中看到了有很多的实现,而我们今天只关注连接器:也就是 ConnectorCreateRule 的 begin 方法:
@Override
public void begin(String namespace, String name, Attributes attributes)
throws Exception {
Service svc = (Service)digester.peek();
Executor ex = null;
if ( attributes.getValue("executor")!=null ) {
ex = svc.getExecutor(attributes.getValue("executor"));
}
Connector con = new Connector(attributes.getValue("protocol"));
if ( ex != null ) _setExecutor(con,ex);
digester.push(con);
}方法不长,我们看看该方法逻辑,该方法首先从List中取出一个Service,然后会分别创建2个连接器,一个是HTTP, 一个是AJP,也就是我们配置文件中写的。
现在,我们已经剖析了tomcat 是如何解析xml的,并如何创建对象的,接下来,我们就看看创建对象的逻辑。
2. 创建连接器对象
我们来到我们的Connector类的构造方法:
public Connector() {
this(null);
}
public Connector(String protocol) {
setProtocol(protocol);
// Instantiate protocol handler
try {
Class<?> clazz = Class.forName(protocolHandlerClassName);
this.protocolHandler = (ProtocolHandler) clazz.newInstance();// 反射创建protocolHandler 默认 http1.1 协议实现 (org.apache.coyote.http11.Http11Protocol)
} catch (Exception e) {
log.error(sm.getString(
"coyoteConnector.protocolHandlerInstantiationFailed"), e);
}
}我记得阿里规约里说,构造器不要太复杂,复杂的逻辑请放在init里,不知道tomcat这么写算好还是不好呢?嘿嘿。我们还是来看看我们的逻辑吧。
1. 根据传进来的字符串设置协议处理器类名(setProtocol 方法中调用了setProtocolHandlerClassName 方法)。
2. 根据刚刚设置好的 protocolHandlerClassName 反射创建 ProtocolHandler 类型的对象。
既然是反射创建,那么我们就要看看完整的类名是什么了,所以需要看看设置 protocolHandlerClassName 方法的细节:
public void setProtocol(String protocol) {
if (AprLifecycleListener.isAprAvailable()) {
if ("HTTP/1.1".equals(protocol)) {
setProtocolHandlerClassName
("org.apache.coyote.http11.Http11AprProtocol");
} else if ("AJP/1.3".equals(protocol)) {
setProtocolHandlerClassName
("org.apache.coyote.ajp.AjpAprProtocol");
} else if (protocol != null) {
setProtocolHandlerClassName(protocol);
} else {
setProtocolHandlerClassName
("org.apache.coyote.http11.Http11AprProtocol");
}
} else {
if ("HTTP/1.1".equals(protocol)) {
setProtocolHandlerClassName
("org.apache.coyote.http11.Http11Protocol");
} else if ("AJP/1.3".equals(protocol)) {
setProtocolHandlerClassName
("org.apache.coyote.ajp.AjpProtocol");
} else if (protocol != null) {
setProtocolHandlerClassName(protocol);
}
}
}此方法会直接进入下面的else块,我们知道,该处可能会传 HTTP 或者 AJP ,根据不同的协议创建不同的协议处理器。也就是连接器,我们看到这里的全限定名是 org.apache.coyote.http11.Http11Protocol 或者 org.apache.coyote.ajp.AjpProtocol,这两个类都是在 coyote 包下,也就是连接器模块。
好了,到现在,我们的 Connector 对象就创建完毕了,创建它的过程同时也根据配置文件创建了 protocolHandler, 他俩是依赖关系。
3. Http11Protocol 协议处理器构造过程
创建了 Http11Protocol 对象,我们有必要看看他的构造过程是什么样的。按照tomcat的性格,一般构造器都很复杂,所以,我们找到该类,看看他的类和构造器:
该类的类说明是这样说的:
抽象协议的实现,包括线程等。处理器是单线程的,特定于基于流的协议,不适合像JNI那样的Jk协议。
我们看看构造方法
public Http11Protocol() {
endpoint = new JIoEndpoint();
cHandler = new Http11ConnectionHandler(this);
((JIoEndpoint) endpoint).setHandler(cHandler);
setSoLinger(Constants.DEFAULT_CONNECTION_LINGER);
setSoTimeout(Constants.DEFAULT_CONNECTION_TIMEOUT);
setTcpNoDelay(Constants.DEFAULT_TCP_NO_DELAY);
}我就说嘛,肯定和复杂。复杂也要看啊。
1. 创建以了一个 JIoEndpoint 对象。
2. 创建了一个 Http11ConnectionHandler 对象,参数是 Http11Protocol;
3. 设置处理器为 Http11ConnectionHandler 对象。
4. 设置一些属性,比如超时,优化tcp性能。
那么我们来看看 JIoEndpoint 这个类,这个类是什么玩意,如果大家平时调试tomcat比较多的话,肯定会熟悉这个类,楼主今天就遇到了,请看:
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:243)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:210)
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:121)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:243)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:210)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:222)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:123)
at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:502)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:171)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:100)
at org.apache.catalina.valves.AccessLogValve.invoke(AccessLogValve.java:953)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:118)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:408)
at org.apache.coyote.http11.AbstractHttp11Processor.process(AbstractHttp11Processor.java:1041)
at org.apache.coyote.AbstractProtocol$AbstractConnectionHandler.process(AbstractProtocol.java:603)
at org.apache.tomcat.util.net.JIoEndpoint$SocketProcessor.run(JIoEndpoint.java:310)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)异常信息,我们看倒数第四行,就是 JIoEndpoint 的内部类 SocketProcessor 的 run 方法报错了,我们今天就亲密接触一下这个类,顺便扒了它的衣服:

赤裸裸的在我们面前。所有错误的根源都在该方法中。
不扯了,我们继续看 JIoEndpoint 的构造器,该构造器很简单,就是设置最大连接数。默认是0,我们看代码:

上图中什么看到该方法将 maxConnections 设置为0,本来是10000,然后进入else if(maxCon > 0) 的逻辑。这里也就完成了 JIoEndpoint 对象的创建过程。
我们回到 Http11Protocol 的构造方法中,执行完了 JIoEndpoint 的创建过程,下面就执行 Http11ConnectionHandler 的构造。参数是Http11Protocol自己,Http11ConnectionHandler 是 Http11Protocol 的静态内部类,该类中有一个属性就是Http11Protocol,一个简单的创建过程,然后设置 Http11Protocol 的 Handler 属性为 Http11ConnectionHandler。可以感觉的到,Http11Protocol, JIoEndpoint , Http11ConnectionHandler 这三个类是互相依赖关系。
至此,完成了 Http11Protocol 对象的创建。同时也完成了 Connector 对象的创建。 创建完对象干嘛呢。。。。不要想歪了,不是啪啪啪,而是初始化。
4. Connector 连接器的初始化 init 方法
我们知道 Connector 的父容器是 Service ,Service 执行 initInternal 方法初始化的时候会同时初始化子容器,也就是 Connector,在一个 for 循环重启动。

该段代码抽取自 StandardService.initInternal 方法,也就是Service 组件。通过debug我们知道了该连接器数组中只有2个连接器,就是我们的HTTP和AJP,刚刚创建的。并调用他们的 init 方法。我们看看该方法,该方法同所有容器一样,执行了LifecycleBase 的模板方法,重点在子类重写的抽象方法 initInternal 中。

这既是 Connector 的 initInternal 方法实现,该方法有几个步骤:
1. 调用父类的 initInternal 方法,将自己注册到JMX中。
2. 创建一个 CoyoteAdapter 对象,参数是自己。
3. 设置 Http11Protocol 的适配器为刚刚创建的 CoyoteAdapter 适配器。
4. 设置解析请求的请求方法类型,默认是 POST。
5. 初始化 Http11Protocol(不要小看这个类,Connector就是一个虚的,真正做事的就是这个类和 JIoEndpoint);
6. 初始化 mapperListener;
我们重点关注 CoyoteAdapter 和 Http11Protocol 的初始化,CoyoteAdapter 是连接器的一种适配,构造参数是 Connector ,很明显,他是要适配 Connector,这里的设计模式就是适配器模式了,所以,写设计模式的时候,一定要在类名上加上设计模式的名字。方便后来人读代码。接下就是设置 Http11Protocol 的适配器为 刚刚构造的 CoyoteAdapter ,也就是说,tomcat 的设计者为了解耦或者什么将 Http11Protocol 和 Connector 中间插入了一个适配器。最后来到我们的 Http11Protocol 的初始化。
这个 Http11Protocol 的初始化很重要。Http11Protocol 不属于 Lifecycle 管理,他的 init 方法在他的抽象父类 org.apache.coyote.AbstractProtocol 中就已经写好了,我们来看看该方法的实现(很重要):

上图就是 AbstractProtocol 的 init 方法,我们看看红框中的逻辑。
1. 将 endpoint 注册到JMX中。
2. 将 Http11ConnectionHandler(Http11Protocol 的 内部类)注册到JMX中。
3. 设置 endpoint 的名字,Http 连接器是 http-bio-8080;
4. endpoint 初始化。
设置JMX的逻辑我们就不讲了,之前讲生命周期的时候讲过了,设置名字也没生命好讲的。最后讲最重要的 endpoint 的初始化。我们来看看他的 init 方法。该方法是 JIoEndpoint 抽象父类 AbstractEndpoint 的模板方法。该类被3个类继承:AprEndpoint, JIoEndpoint, NioEndpoint,我们今天只关心JIoEndpoint。我们还是先看看 AbstractEndpoint 的 init 方法吧:

其中 bind()是抽象方法,然后设置状态为绑定已经初始化。我们看看 JIoEndpoint 的 bind 方法。有兴趣也可以看看其他 Endpoint 的 bind 方法,比如NIO。我们看看JIo的:

这个方法很重要,我们仔细看看逻辑:
1. 设置最大线程数,默认是200;
2. 创建一个默认的 serverSocketFactory 工厂(就是一个封装了ServerSocket 的类);
3. 使用刚刚工厂创建一个 serverSocket。因此,JIoEndpoint 也就有了 serverSocket。
至此,我们完成了 Connector, Http11Protocol,JIoEndpoint 的初始化。
接下来就是启动了
5. 连接器启动
如我们所知,Connector 启动肯定在 startInternal 方法中,因此我们直接看此方法。

该方法步骤如下:
1. 设置启动中状态。状态更新会触发事件监听机制。
2. 启动 org.apache.coyote.http11.Http11Protocol 的 srart 方法。
3. 启动 org.apache.catalina.connector.MapperListener 的 start 方法。
我们感兴趣的是 org.apache.coyote.http11.Http11Protocol 的 srart 方法。该方法由其抽象父类 AbstractProtocol.start 执行,我们看看该方法:

该方法主要逻辑是启动 endpoint 的 start 方法。说明干事的还是 endpoint 啊 ,我们看看该方法实现,该方法调用了抽象父类的模板方法 AbstractEndpoint.start:

其主要逻辑是调用子类重写的 startInternal 方法,我们来看 JIoEndpoint 的实现:

该方法可以说是 Tomcat 中 真正做事情的方法,绝对不是摸鱼员工。说说他的逻辑:
1. 创建一个线程阻塞队列,和一个线程池。
2. 初始化最大连接数,默认200.
3. 调用抽象父类 AbstractEndpoint 的 startAcceptorThreads 方法,默认创建一个守护线程。他的任务是等待客户端请求,并将请求(socket 交给线程池)。AbstractEndpoint 中有一个 Acceptor 数组,作用接收新的连接和传递请求。
4. 创建一个管理超时socket 的线程。
让我们看看他的详细实现:
6. JIoEndpoint startInternal(Tomcat socket 管理) 方法的详细实现
先看第一步:创建一个线程阻塞队列,和一个线程池。我们进入该方法:

该方法步骤:
1. 创建一个 “任务队列”,实际上是一个继承了 LinkedBlockingQueue 的类。该队列最大长度为 int 最大值 0x7fffffff。
2. 创建一个线程工厂,TaskThreadFactory 是一个继承 ThreadFactory 的类,默认创建最小线程 10, 最大线程200, 名字为 “http-bio-8080-exec-” 拼接线程池编号,优先级为5。
3. 使用上面的线程工厂创建一个线程池,预先创建10个线程,最大线程200,线程空闲实际60秒.
4. 将线程池设置为队列的属性,方便后期判断线程池状态而做一些操作。
再看第二步:初始化最大连接数,默认200.

该方法很简单,就是设置最大连接数为200;
第三步:用抽象父类 AbstractEndpoint 的 startAcceptorThreads 方法,默认创建一个守护线程。他的任务是等待客户端请求,并将请求(socket 交给线程池)。AbstractEndpoint 中有一个 Acceptor 数组,作用接收新的连接和传递请求。我们看看该方法:

步骤:
1. 获取可接收的连接数,并创建一个连接线程数组。
2. 循环该数组,设置优先级为5,设置为守护线程。
3.启动该线程。
该方法也不是很复杂,获取的这个连接数,在完美初始化的时候,调用bind 方法的时候设置的,请看:

设置为1.
复杂的是 Acceptor 中的逻辑,Acceptor 是一个抽象静态内部类,实现了 Runnable 接口,JIoEndpoint 类中也继承了该类,其中 run 方法如下(高能预警,方法很长)。
@Override
public void run() {
int errorDelay = 0;
// Loop until we receive a shutdown command
while (running) {
// Loop if endpoint is paused
while (paused && running) {
state = AcceptorState.PAUSED;
try {
Thread.sleep(50);
} catch (InterruptedException e) {
// Ignore
}
}
if (!running) {
break;
}
state = AcceptorState.RUNNING;
try {
//if we have reached max connections, wait
countUpOrAwaitConnection();
Socket socket = null;
try {
// Accept the next incoming connection from the server
// socket
socket = serverSocketFactory.acceptSocket(serverSocket);
} catch (IOException ioe) {
countDownConnection();
// Introduce delay if necessary
errorDelay = handleExceptionWithDelay(errorDelay);
// re-throw
throw ioe;
}
// Successful accept, reset the error delay
errorDelay = 0;
// Configure the socket
if (running && !paused && setSocketOptions(socket)) {
// Hand this socket off to an appropriate processor
if (!processSocket(socket)) {
countDownConnection();
// Close socket right away
closeSocket(socket);
}
} else {
countDownConnection();
// Close socket right away
closeSocket(socket);
}
} catch (IOException x) {
if (running) {
log.error(sm.getString("endpoint.accept.fail"), x);
}
} catch (NullPointerException npe) {
if (running) {
log.error(sm.getString("endpoint.accept.fail"), npe);
}
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
log.error(sm.getString("endpoint.accept.fail"), t);
}
}
state = AcceptorState.ENDED;
}其实逻辑也还好,不是那么复杂,我们化整为零,一个一个分析,首先判断状态,进入循环,然后设置一些状态,最后进入一个 try 块。
1. 执行 countUpOrAwaitConnection 方法,该方法注释说:如果已经达到最大连接,就等待。
2. 阻塞获取socket。
3. setSocketOptions(socket) 设置 tcp 一些属性优化性能,比如缓冲字符大小,超时等。
4. 执行 processSocket(socket) 方法,将请求包装一下交给线程池执行。
我们看看第一个方法 countUpOrAwaitConnection:

主要是 latch.countUpOrAwait() 这个方法,我们看看该方法内部实现:

这个 Sync 类 变量是 继承了java.util.concurrent.locks.AbstractQueuedSynchronizer 抽象类(该类是JDK 1.8 新增的),说实话,楼主不熟悉这个类。再一个今天的主题也不是并发,因此放过这个类,给大家一个链接 深度解析Java 8:AbstractQueuedSynchronizer的实现分析(下);
我们暂时知道这个方法作用是什么就行了,就像注释说的:如果已经达到最大连接,就等待。我们继续我们的分析。
我们跳过设置 tcp 优化,重点查看 processSocket 方法,这个方法是 JIoEndpoint 的,我们看看该方法实现:

该方法逻辑是:
1. 封装一个 SocketWrapper。
2. 设置长连接时间为100,
3.然后封装成 SocketProcessor(还记得这个类吗,就是我们刚开始异常信息里出现的类,原来是在这里报错的,哈哈) 交给线程池执行。
到这里,我们必须停下来,因为如果继续追踪 SocketProcessor 这个类,这篇文章就停不下来了,楼主想留在下一篇文章慢慢咀嚼。慢慢品味。
第四步:好了,回到我们的 JIoEndpoint.startInternal 方法,我们已经解析完了 startAcceptorThreads 方法,那么我们继续向下走,看到一个 timeoutThread 线程。创建一个管理超时socket 的线程。设置为了守护线程,名字叫 “http-bio-8080-AsyncTimeout”,优先级为5.
我们看看该程序的实现,还好,代码不多:

我们看看主要逻辑:
1. 获取当前时间;
2. waitingRequests 的类型是 ConcurrentLinkedQueue
7. 总结
今天的文章真是超长啊,谁叫连接器是tomcat中最重要的组件呢?其实还没有讲完呢;我们讲了连接器的如何根据server.xml 创建对象,如何初始化connector 和 endpoint ,如何启动connector,如何启动 endpoint中各个线程。楼主能力有限,暂时先讲这么多,还有很多的东西我们都还没讲,没事,留着下次讲。
深入理解 Tomcat(九)源码剖析之请求过程_ignore-CSDN博客
前言
不知不觉,这已经是我们深入理解tomcat的第九篇文章了,我们在第八篇分析了tomcat的连接器,分析了连接器的的Connector,Http11Protocol,Http11ConnectionHandler,JIoEndpoint,Acceptor 等等这些有关连接器的类和组件,当时我们分析到Acceptor的run方法后就停止分析了,因为后面的代码与请求过程高度相关,而且请求过程这段代码时比较复杂的,需要很大的篇幅去讲述。废话不多说,今天我们就开始分析 http://localhost:8080 在tomcat中是如何运作的,是如何到达的Servlet的。
序列图
首先来一张楼主画的序列图,然后,我们这篇文章基本就按照我们的这张图来讲述了。这张图有47个层次的调用,上传到简书就变模糊了,因此楼主将图片放到了github上,大家可以看的清楚一点。
楼主这次分析,会先启动tomcat, 然后在
1. JIoEndpoint 分析
上次我们分析连接器的时候提到了一个干实事不摸鱼的好员工,JIoEndpoint,该类在创建Http11Protocol对象的时候会一起被创建,可以说他们是依赖关系。并且 JIoEndpoint 也包含一个 Http11ConnectionHandler 协议连接处理器类,该类是 Http11Protocol 的静态内部类。而 Http11ConnectionHandler 由依赖 Http11Protocol,可以说三者是一种循环的关系,Http11Protocol 依赖着 JIoEndpoint,Http11ConnectionHandler 依赖着 Http11Protocol ,JIoEndpoint 依赖着 Http11ConnectionHandler 。而处理 HTTP BIO 模式的连接主要由 JIoEndpoint 和它的两个(共4个内部类和一个内部接口)内部类 Acceptor 和 SocketProcessor 完成的。下面是JIoEndpoint 的类结构图:

Acceptor 我们在上次分析连接器的时候已经分析过了,它其实是用于接收HTTP 请求的线程。用于从 SocketServer 接受请求。
SocketProcessor 则是我们今天分析的源头,因为从我们的第八篇文章中知道,Acceptor 将请求处理之后会交给 SocketProcessor 进行真正的处理。那么我们就来分析分析该类。
2. SocketProcessor 分析
首先该类是一个继承了 Runnable 的内部类,还记得在连接器启动的时候,会启动一个线程池,该连接池就是用于执行该线程的。那么我们就看看该类的实现:
/**
* This class is the equivalent of the Worker, but will simply use in an
* external Executor thread pool.
*
* 这个类相当于工作人员,但是只会在一个外部执行器线程池中使用
*/
protected class SocketProcessor implements Runnable {
protected SocketWrapper<Socket> socket = null;
protected SocketStatus status = null;
public SocketProcessor(SocketWrapper<Socket> socket) {
if (socket==null) throw new NullPointerException();
this.socket = socket;
}
public SocketProcessor(SocketWrapper<Socket> socket, SocketStatus status) {
this(socket);
this.status = status;
}
@Override
public void run() {
boolean launch = false;
synchronized (socket) {
try {
SocketState state = SocketState.OPEN;
try {
// SSL handshake
serverSocketFactory.handshake(socket.getSocket()); // 什么都不做
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
if (log.isDebugEnabled()) {
log.debug(sm.getString("endpoint.err.handshake"), t);
}
// Tell to close the socket
state = SocketState.CLOSED;
}
if ((state != SocketState.CLOSED)) {// open
if (status == null) { // status == null
state = handler.process(socket, SocketStatus.OPEN);// AbstractProtocol.process(); state 变为 close
} else { // handler == Http11Protocol$Http11ConnectionHandler
state = handler.process(socket,status); // state = closed
}
}
if (state == SocketState.CLOSED) {
// Close socket
if (log.isTraceEnabled()) {
log.trace("Closing socket:"+socket);
}
countDownConnection();// 进入该方法
try {
socket.getSocket().close(); // 关闭流
} catch (IOException e) {
// Ignore
}
} else if (state == SocketState.OPEN ||
state == SocketState.UPGRADING ||
state == SocketState.UPGRADED){
socket.setKeptAlive(true);
socket.access();
launch = true; // 此时才走finally try 逻辑
} else if (state == SocketState.LONG) {
socket.access();
waitingRequests.add(socket);// 长连接,
}
} finally {
if (launch) {
try {
getExecutor().execute(new SocketProcessor(socket, SocketStatus.OPEN));
} catch (RejectedExecutionException x) {
log.warn("Socket reprocessing request was rejected for:"+socket,x);
try {
//unable to handle connection at this time
handler.process(socket, SocketStatus.DISCONNECT);
} finally {
countDownConnection();
}
} catch (NullPointerException npe) {
if (running) {
log.error(sm.getString("endpoint.launch.fail"),
npe);
}
}
}
}
}
socket = null; // 完成请求
// Finish up this request
}
}首先该类由2个属性,一个是 SocketWrapper ,看名字就知道他其实就是 Socket 的包装类,另一个是 SocketStatus, 也就是 Socket 的状态。我们看看该类的 run 方法的执行逻辑:
1. 首先处理socket的SSL。实际上 DefaultServerSocketFactory(也就是我们默认的) 是空的,什么都不做。
2. 判断socket状态,如果是null,则设置为open,执行 Http11ConnectionHandler 的 process 方法。
3. 执行 Http11ConnectionHandler 的 process 方法会返回一个 SocketState,后面会根据该状态执行不同的逻辑,如果是关闭,则减去一个连接数,并且关闭流。如果是开或则升级状态,则进入finally块继续交给线程池执行。如果是长连接,则放入ConcurrentLinkedQueue 队列,供另一个线程 AsyncTimeout 执行(最后还是交给 SocketProcessor 执行 );
可以看到这个方法不是很复杂,并且我们能感觉到主要逻辑会在第二步,因此我们就进入到第二步的 process 方法中查看。
3. Http11ConnectionHandler process 方法剖析
进入handler 的process 方法,实际上是进入了 Http11ConnectionHandler 的父类 AbstractConnectionHandler 的 process 方法,该方法是个模板方法,让我们看看该方法:
public SocketState process(SocketWrapper<S> socket,
SocketStatus status) {
Processor<S> processor = connections.remove(socket.getSocket()); // connections 是用于缓存长连接的socket
if (status == SocketStatus.DISCONNECT && processor == null) { // 如果是断开连接状态且协议处理器为null
//nothing more to be done endpoint requested a close
//and there are no object associated with this connection
return SocketState.CLOSED;
}
socket.setAsync(false);// 非异步
try {
if (processor == null) {
processor = recycledProcessors.poll();// 如果从缓存中没取到,从可以循环使用的 ConcurrentLinkedQueue 获取
}
if (processor == null) {
processor = createProcessor(); // 如果还没有,则创建一个
}
initSsl(socket, processor); // 设置SSL 属性,默认为null,可以配置
SocketState state = SocketState.CLOSED;
do {
if (status == SocketStatus.DISCONNECT &&
!processor.isComet()) {
// Do nothing here, just wait for it to get recycled
// Don't do this for Comet we need to generate an end
// event (see BZ 54022)
} else if (processor.isAsync() ||
state == SocketState.ASYNC_END) {
state = processor.asyncDispatch(status); // 如果是异步的
} else if (processor.isComet()) {
state = processor.event(status); // 事件驱动???
} else if (processor.isUpgrade()) {
state = processor.upgradeDispatch(); // 升级转发???
} else {
state = processor.process(socket); // 默认的 AbstractHttp11Processor.process
}
if (state != SocketState.CLOSED && processor.isAsync()) {
state = processor.asyncPostProcess();
}
if (state == SocketState.UPGRADING) {
// Get the UpgradeInbound handler
UpgradeInbound inbound = processor.getUpgradeInbound();
// Release the Http11 processor to be re-used
release(socket, processor, false, false);
// Create the light-weight upgrade processor
processor = createUpgradeProcessor(socket, inbound);
inbound.onUpgradeComplete();
}
} while (state == SocketState.ASYNC_END ||
state == SocketState.UPGRADING);
if (state == SocketState.LONG) {
// In the middle of processing a request/response. Keep the
// socket associated with the processor. Exact requirements
// depend on type of long poll
longPoll(socket, processor);
} else if (state == SocketState.OPEN) {
// In keep-alive but between requests. OK to recycle
// processor. Continue to poll for the next request.
release(socket, processor, false, true);
} else if (state == SocketState.SENDFILE) {
// Sendfile in progress. If it fails, the socket will be
// closed. If it works, the socket will be re-added to the
// poller
release(socket, processor, false, false);
} else if (state == SocketState.UPGRADED) {
// Need to keep the connection associated with the processor
longPoll(socket, processor);
} else {
// Connection closed. OK to recycle the processor.
if (!(processor instanceof UpgradeProcessor)) {
release(socket, processor, true, false);
}
}
return state;
} catch(java.net.SocketException e) {
// SocketExceptions are normal
getLog().debug(sm.getString(
"abstractConnectionHandler.socketexception.debug"), e);
} catch (java.io.IOException e) {
// IOExceptions are normal
getLog().debug(sm.getString(
"abstractConnectionHandler.ioexception.debug"), e);
}
// Future developers: if you discover any other
// rare-but-nonfatal exceptions, catch them here, and log as
// above.
catch (Throwable e) {
ExceptionUtils.handleThrowable(e);
// any other exception or error is odd. Here we log it
// with "ERROR" level, so it will show up even on
// less-than-verbose logs.
getLog().error(
sm.getString("abstractConnectionHandler.error"), e);
}
// Don't try to add upgrade processors back into the pool
if (!(processor instanceof UpgradeProcessor)) {
release(socket, processor, true, false);
}
return SocketState.CLOSED;
}该方法很长,我们简略的说一下主要逻辑:
1. 从 ConcurrentHashMap 中获取长连接的封装了soceket的处理类。
2. 如果没有,则从循环使用的 ConcurrentLinkedQueue 队列中获取。如果还没有,则调用自己的 createProcessor 直接创建一个。
3. 调用子类的 initSsl 方法,初始化 SSL 属性。如果配置文件没配置,则设置为null。
4. 根据不同的属性调用不同的方法,优先判断是否异步,默认使用同步,也就是 Http11Processor.process 方法。
5. 执行结束后,根据返回的不同的状态调用不同的方法,比如 longPoll,release,参数也不同,默认是 release(socket, processor, true, false),放入ConcurrentLinkedQueue (recycledProcessors)队列中。
我们重点关注 AbstractHttp11Processor.process 方法,该方法是处理socket的主要逻辑。
4. Http11Processor.process 方法解析
该方法其实是其父类 AbstractHttp11Processor 的方法,特别的长,不知道为什么tomcat的大师们为什么不封装一下,代码这么长真的不太好看。楼主认为一个方法最好不要超过50行。越短越好。楼主无奈,只好贴出楼主简化的代码,大家凑合着看,如果想看详细的源码,可以留言也可以去我的github clone;
@Override
public SocketState process(SocketWrapper<S> socketWrapper) throws IOException {
// Setting up the I/O
setSocketWrapper(socketWrapper);
getInputBuffer().init(socketWrapper, endpoint);// 设置输入流
getOutputBuffer().init(socketWrapper, endpoint);// 设置输出流
prepareRequest();// 准备请求内容
adapter.service(request, response); // 真正处理的方法 CoyoteAdapter
return SocketState.OPEN;
}该方法步骤:
1. 设置socket。
2. 设置输入流和输出流。
3. 继续向下执行。执行 CoyoteAdapter 的service 方法。
4. 返回状态(默认返回 OPEN)供上层判断。
我们重点关注 CoyoteAdapter 的service 方法;
5. CoyoteAdapter.service 方法解析
该方法同样很长,我们看看该方法的逻辑:
/**
* Service method.
*/
@Override
public void service(org.apache.coyote.Request req,
org.apache.coyote.Response res)
throws Exception {
Request request = (Request) req.getNote(ADAPTER_NOTES); // 实现了 servlet 标准的 Request
Response response = (Response) res.getNote(ADAPTER_NOTES);
if (request == null) {
// Create objects
request = connector.createRequest();
request.setCoyoteRequest(req);
response = connector.createResponse();
response.setCoyoteResponse(res);
// Link objects
request.setResponse(response); // 互相关联
response.setRequest(request);
// Set as notes
req.setNote(ADAPTER_NOTES, request);
res.setNote(ADAPTER_NOTES, response);
// Set query string encoding
req.getParameters().setQueryStringEncoding // 解析 uri
(connector.getURIEncoding());
}
if (connector.getXpoweredBy()) { // 网站安全狗IIS
response.addHeader("X-Powered-By", POWERED_BY);
}
boolean comet = false;
boolean async = false;
try {
// Parse and set Catalina and configuration specific
// request parameters
req.getRequestProcessor().setWorkerThreadName(Thread.currentThread().getName());
boolean postParseSuccess = postParseRequest(req, request, res, response); // 解析请求内容
if (postParseSuccess) {
//check valves if we support async
request.setAsyncSupported(connector.getService().getContainer().getPipeline().isAsyncSupported());
// Calling the container 调用 容器
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response); // 一个复杂的调用
if (request.isComet()) {
if (!response.isClosed() && !response.isError()) {
if (request.getAvailable() || (request.getContentLength() > 0 && (!request.isParametersParsed()))) {
// Invoke a read event right away if there are available bytes
if (event(req, res, SocketStatus.OPEN)) {
comet = true;
res.action(ActionCode.COMET_BEGIN, null);
}
} else {
comet = true;
res.action(ActionCode.COMET_BEGIN, null);
}
} else {
// Clear the filter chain, as otherwise it will not be reset elsewhere
// since this is a Comet request
request.setFilterChain(null);
}
}
}
AsyncContextImpl asyncConImpl = (AsyncContextImpl)request.getAsyncContext();
if (asyncConImpl != null) {
async = true;
} else if (!comet) {
request.finishRequest();
response.finishResponse();
if (postParseSuccess &&
request.getMappingData().context != null) {
// Log only if processing was invoked.
// If postParseRequest() failed, it has already logged it.
// If context is null this was the start of a comet request
// that failed and has already been logged.
((Context) request.getMappingData().context).logAccess(
request, response,
System.currentTimeMillis() - req.getStartTime(),
false);
}
req.action(ActionCode.POST_REQUEST , null);
}
} catch (IOException e) {
// Ignore
} finally {
req.getRequestProcessor().setWorkerThreadName(null);
// Recycle the wrapper request and response
if (!comet && !async) {
request.recycle();
response.recycle();
} else {
// Clear converters so that the minimum amount of memory
// is used by this processor
request.clearEncoders();
response.clearEncoders();
}
}
}我们分析一下该方法的逻辑:
1. 创建实现 Servlet 标准的 Request 和 Response。
2. 将Request 和 Response 互相关联。
4. 执行 postParseRequest 解析请求内容。
5. 执行最重要的步骤:connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);
6. 执行一些清理工作。
6. CoyoteAdapter.postParseRequest 方法解析
我们看看他是如何解析请求的内容的,也就是 postParseRequest 方法的实现:
protected boolean postParseRequest(org.apache.coyote.Request req,
Request request,
org.apache.coyote.Response res,
Response response)
throws Exception {
// XXX the processor may have set a correct scheme and port prior to this point,
// in ajp13 protocols dont make sense to get the port from the connector...
// otherwise, use connector configuration
if (! req.scheme().isNull()) {
// use processor specified scheme to determine secure state
request.setSecure(req.scheme().equals("https"));
} else {
// use connector scheme and secure configuration, (defaults to
// "http" and false respectively)
req.scheme().setString(connector.getScheme());
request.setSecure(connector.getSecure());
}
// FIXME: the code below doesnt belongs to here,
// this is only have sense
// in Http11, not in ajp13..
// At this point the Host header has been processed.
// Override if the proxyPort/proxyHost are set
String proxyName = connector.getProxyName();
int proxyPort = connector.getProxyPort();
if (proxyPort != 0) {
req.setServerPort(proxyPort);
}
if (proxyName != null) {
req.serverName().setString(proxyName);
}
// Copy the raw URI to the decodedURI
MessageBytes decodedURI = req.decodedURI();
decodedURI.duplicate(req.requestURI());
// Parse the path parameters. This will:
// - strip out the path parameters
// - convert the decodedURI to bytes
parsePathParameters(req, request);
// URI decoding
// %xx decoding of the URL
try {
req.getURLDecoder().convert(decodedURI, false);
} catch (IOException ioe) {
res.setStatus(400);
res.setMessage("Invalid URI: " + ioe.getMessage());
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
// Normalization
if (!normalize(req.decodedURI())) {
res.setStatus(400);
res.setMessage("Invalid URI");
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
// Character decoding
convertURI(decodedURI, request);
// Check that the URI is still normalized
if (!checkNormalize(req.decodedURI())) {
res.setStatus(400);
res.setMessage("Invalid URI character encoding");
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
// Set the remote principal
String principal = req.getRemoteUser().toString();
if (principal != null) {
request.setUserPrincipal(new CoyotePrincipal(principal));
}
// Set the authorization type
String authtype = req.getAuthType().toString();
if (authtype != null) {
request.setAuthType(authtype);
}
// Request mapping.
MessageBytes serverName;
if (connector.getUseIPVHosts()) {
serverName = req.localName();
if (serverName.isNull()) {
// well, they did ask for it
res.action(ActionCode.REQ_LOCAL_NAME_ATTRIBUTE, null);
}
} else {
serverName = req.serverName();
}
if (request.isAsyncStarted()) {
//TODO SERVLET3 - async
//reset mapping data, should prolly be done elsewhere
request.getMappingData().recycle();
}
boolean mapRequired = true;
String version = null;
while (mapRequired) {
if (version != null) {
// Once we have a version - that is it
mapRequired = false;
}
// This will map the the latest version by default
connector.getMapper().map(serverName, decodedURI, version,
request.getMappingData());
request.setContext((Context) request.getMappingData().context);
request.setWrapper((Wrapper) request.getMappingData().wrapper);
// Single contextVersion therefore no possibility of remap
if (request.getMappingData().contexts == null) {
mapRequired = false;
}
// If there is no context at this point, it is likely no ROOT context
// has been deployed
if (request.getContext() == null) {
res.setStatus(404);
res.setMessage("Not found");
// No context, so use host
Host host = request.getHost();
// Make sure there is a host (might not be during shutdown)
if (host != null) {
host.logAccess(request, response, 0, true);
}
return false;
}
// Now we have the context, we can parse the session ID from the URL
// (if any). Need to do this before we redirect in case we need to
// include the session id in the redirect
String sessionID = null;
if (request.getServletContext().getEffectiveSessionTrackingModes()
.contains(SessionTrackingMode.URL)) {
// Get the session ID if there was one
sessionID = request.getPathParameter(
SessionConfig.getSessionUriParamName(
request.getContext()));
if (sessionID != null) {
request.setRequestedSessionId(sessionID);
request.setRequestedSessionURL(true);
}
}
// Look for session ID in cookies and SSL session
parseSessionCookiesId(req, request);
parseSessionSslId(request);
sessionID = request.getRequestedSessionId();
if (mapRequired) {
if (sessionID == null) {
// No session means no possibility of needing to remap
mapRequired = false;
} else {
// Find the context associated with the session
Object[] objs = request.getMappingData().contexts;
for (int i = (objs.length); i > 0; i--) {
Context ctxt = (Context) objs[i - 1];
if (ctxt.getManager().findSession(sessionID) != null) {
// Was the correct context already mapped?
if (ctxt.equals(request.getMappingData().context)) {
mapRequired = false;
} else {
// Set version so second time through mapping the
// correct context is found
version = ctxt.getWebappVersion();
// Reset mapping
request.getMappingData().recycle();
break;
}
}
}
if (version == null) {
// No matching context found. No need to re-map
mapRequired = false;
}
}
}
if (!mapRequired && request.getContext().getPaused()) {
// Found a matching context but it is paused. Mapping data will
// be wrong since some Wrappers may not be registered at this
// point.
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// Should never happen
}
// Reset mapping
request.getMappingData().recycle();
mapRequired = true;
}
}
// Possible redirect
MessageBytes redirectPathMB = request.getMappingData().redirectPath;
if (!redirectPathMB.isNull()) {
String redirectPath = urlEncoder.encode(redirectPathMB.toString());
String query = request.getQueryString();
if (request.isRequestedSessionIdFromURL()) {
// This is not optimal, but as this is not very common, it
// shouldn't matter
redirectPath = redirectPath + ";" +
SessionConfig.getSessionUriParamName(
request.getContext()) +
"=" + request.getRequestedSessionId();
}
if (query != null) {
// This is not optimal, but as this is not very common, it
// shouldn't matter
redirectPath = redirectPath + "?" + query;
}
response.sendRedirect(redirectPath);
request.getContext().logAccess(request, response, 0, true);
return false;
}
// Filter trace method
if (!connector.getAllowTrace()
&& req.method().equalsIgnoreCase("TRACE")) {
Wrapper wrapper = request.getWrapper();
String header = null;
if (wrapper != null) {
String[] methods = wrapper.getServletMethods();
if (methods != null) {
for (int i=0; i<methods.length; i++) {
if ("TRACE".equals(methods[i])) {
continue;
}
if (header == null) {
header = methods[i];
} else {
header += ", " + methods[i];
}
}
}
}
res.setStatus(405);
res.addHeader("Allow", header);
res.setMessage("TRACE method is not allowed");
request.getContext().logAccess(request, response, 0, true);
return false;
}
return true;
}- 设置 请求的消息类型。
- 设置代理名称和代理端口(如果配置文件有的话)。
- 解析URL路径参数。
- 转换 URI 的编码。
- 从Connector 容器中的Mapper 中取出对应的 Context 和 Servlet, 设置 Request 的 WebApp应用和Servlet。如果Context不存在,则返回404。
- 解析cookie,解析sessionId,设置 SessionId,
- 判断方法类型是否是 TRACE 类型的方法,如果是,则返回405.不允许该方法进入服务器。
7.connector.getService().getContainer().getPipeline().getFirst().invoke(request, response) 中的管道与阀门解析
好,解析完 postParseRequest 之后,我们再看看下面的步骤::connector.getService().getContainer().getPipeline().getFirst().invoke(request, response),这个链式调用可以说很自信,一点不怕 NPE。很明显,他们很自信,因为再启动过程中就已经设置这些属性了。而这段代码也引出了2个概念,管道和阀,getPipeline 获取管道 Pipeline,getFirst 获取第一个阀。我们先说说什么是管道?什么是阀门?
我们知道,Tomcat 是由容器组成的,容器从大到小的排列依次是:Server–>Service—->Engine—>Host—>Context—>Wrapper,那么当一个请求过来,从大容器到小容器,他们一个一个的传递,像接力比赛,如果是我们设计,我们可能只需要将让大容器持有小容器就好了,即能够传递了,但是,如果在传递的过程中我们需要做一些事情呢?比如校验,比如记录日志,比如记录时间,比如权限,并且我们要保证不能耦合,随时可去除一个功能。我们该怎么办?相信由经验的同学已经想到了。
那就是使用过滤器模式。
众多的过滤器如何管理?使用管道,将过滤器都放在管道中,简直完美!!!
那么Tomcat中 Pipeline 就是刚刚说的管道,过滤器就是阀门 Valve,每个 Pipeline 只持有第一个阀门,后面的就不管了,因为第一个会指向第二个,第二个会指向第三个,便于拆卸。
那么现在是时候看看我们的时序图了,我们先请出一部分:

从图中我们可以看出:请求从SocketProcessor 进来,然后交给 Http11ConnectionHandler,最后交给 CoyoteAdapter,开始触及容器的管道。CoyoteAdapter 持有一个 Connector 实例,我们再初始化的时候已经知道了,Connector 会获取他对应的容器(一个容器对应多个连接器)StandardService,StandardService会获取他的下级容器 StandardEngine,这个时候,就该获取管道了,管道管理着阀门。阀门接口 Pipeline 只有一个标准实现 StandardPipeline,每个容器都持有该管道实例(在初始化的时候就创建好了)。管道会获取第一个阀门,如果不存在,就返回一个基础阀门(每个容器创建的时候都会放入一个标准的对应的容器阀门作为其基础阀门)。再调用阀门的 invoke 方法,该方法在执行完自己的逻辑之后,便调用子容器的管道中的阀门的 invoke 方法。依次递归。
现在我们图也看了,原理也说了,现在该看代码了,也就是 StandardEnglineValve 阀门的 invoke 方法:
/**
* Select the appropriate child Host to process this request,
* based on the requested server name. If no matching Host can
* be found, return an appropriate HTTP error.
*
* 根据所请求的服务器名称选择适当的子主机来处理这个请求。如果找不到匹配的主机,则返回一个适当的HTTP错误。
*
*/
@Override
public final void invoke(Request request, Response response)
throws IOException, ServletException {
// Select the Host to be used for this Request
Host host = request.getHost();
if (host == null) {
response.sendError
(HttpServletResponse.SC_BAD_REQUEST,
sm.getString("standardEngine.noHost",
request.getServerName()));
return;
}
if (request.isAsyncSupported()) {
request.setAsyncSupported(host.getPipeline().isAsyncSupported());
}
// Ask this Host to process this request
host.getPipeline().getFirst().invoke(request, response);
}该方法很简单,校验该Engline 容器是否含有Host容器,如果不存在,返回400错误,否则继续执行 host.getPipeline().getFirst().invoke(request, response),可以看到 Host 容器先获取自己的管道,再获取第一个阀门,我们再看看该阀门的 invoke 方法。
8. host.getPipeline().getFirst().invoke 解析
该链式调用获取的不是Basic 阀门,因为他设置了第一个阀门:
@Override
public Valve getFirst() {
if (first != null) {
return first;
}
return basic;
}返回的是 AccessLogValve 实例,我们进入 AccessLogValve 的 invoke 方法查看:
@Override
public void invoke(Request request, Response response) throws IOException,
ServletException {
getNext().invoke(request, response);
}啥也没做,只是将请求交给了下一个阀门,执行getNext,该方法是其父类 ValveBase 的方法。下一个阀门是谁呢? ErrorReportValve,我们看看该阀门的 invoke 方法:
@Override
public void invoke(Request request, Response response)
throws IOException, ServletException {
// Perform the request
getNext().invoke(request, response);
if (response.isCommitted()) {
return;
}
Throwable throwable =
(Throwable) request.getAttribute(RequestDispatcher.ERROR_EXCEPTION);
if (request.isAsyncStarted() && response.getStatus() < 400 &&
throwable == null) {
return;
}
if (throwable != null) {
// The response is an error
response.setError();
// Reset the response (if possible)
try {
response.reset();
} catch (IllegalStateException e) {
// Ignore
}
response.sendError
(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);
}
response.setSuspended(false);
try {
report(request, response, throwable);
} catch (Throwable tt) {
ExceptionUtils.handleThrowable(tt);
}
if (request.isAsyncStarted()) {
request.getAsyncContext().complete();
}
}该方法首先执行了下个阀门的 invoke 方法。然后根据返回的Request 属性设置一些错误信息。那么下个阀门是谁呢?其实就是基础阀门了:StandardHostValve,该阀门的 invoke 的方法是如何实现的呢?
@Override
public final void invoke(Request request, Response response)
throws IOException, ServletException {
// Select the Context to be used for this Request
Context context = request.getContext();
if (context == null) {
response.sendError
(HttpServletResponse.SC_INTERNAL_SERVER_ERROR,
sm.getString("standardHost.noContext"));
return;
}
// Bind the context CL to the current thread
if( context.getLoader() != null ) {
// Not started - it should check for availability first
// This should eventually move to Engine, it's generic.
if (Globals.IS_SECURITY_ENABLED) {
PrivilegedAction<Void> pa = new PrivilegedSetTccl(
context.getLoader().getClassLoader());
AccessController.doPrivileged(pa);
} else {
Thread.currentThread().setContextClassLoader
(context.getLoader().getClassLoader());
}
}
if (request.isAsyncSupported()) {
request.setAsyncSupported(context.getPipeline().isAsyncSupported());
}
// Don't fire listeners during async processing
// If a request init listener throws an exception, the request is
// aborted
boolean asyncAtStart = request.isAsync();
// An async error page may dispatch to another resource. This flag helps
// ensure an infinite error handling loop is not entered
boolean errorAtStart = response.isError();
if (asyncAtStart || context.fireRequestInitEvent(request)) {
// Ask this Context to process this request
try {
context.getPipeline().getFirst().invoke(request, response);
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
if (errorAtStart) {
container.getLogger().error("Exception Processing " +
request.getRequestURI(), t);
} else {
request.setAttribute(RequestDispatcher.ERROR_EXCEPTION, t);
throwable(request, response, t);
}
}
// If the request was async at the start and an error occurred then
// the async error handling will kick-in and that will fire the
// request destroyed event *after* the error handling has taken
// place
if (!(request.isAsync() || (asyncAtStart &&
request.getAttribute(
RequestDispatcher.ERROR_EXCEPTION) != null))) {
// Protect against NPEs if context was destroyed during a
// long running request.
if (context.getState().isAvailable()) {
if (!errorAtStart) {
// Error page processing
response.setSuspended(false);
Throwable t = (Throwable) request.getAttribute(
RequestDispatcher.ERROR_EXCEPTION);
if (t != null) {
throwable(request, response, t);
} else {
status(request, response);
}
}
context.fireRequestDestroyEvent(request);
}
}
}
// Access a session (if present) to update last accessed time, based on a
// strict interpretation of the specification
if (ACCESS_SESSION) {
request.getSession(false);
}
// Restore the context classloader
if (Globals.IS_SECURITY_ENABLED) {
PrivilegedAction<Void> pa = new PrivilegedSetTccl(
StandardHostValve.class.getClassLoader());
AccessController.doPrivileged(pa);
} else {
Thread.currentThread().setContextClassLoader
(StandardHostValve.class.getClassLoader());
}
}首先校验了Request 是否存在 Context,其实在执行 CoyoteAdapter.postParseRequest 方法的时候就设置了,如果Context 不存在,就返回500,接着还是老套路:context.getPipeline().getFirst().invoke,该管道获取的是基础阀门:StandardContextValve,我们还是关注他的 invoke 方法。
@Override
public final void invoke(Request request, Response response)
throws IOException, ServletException {
// Disallow any direct access to resources under WEB-INF or META-INF
MessageBytes requestPathMB = request.getRequestPathMB();
if ((requestPathMB.startsWithIgnoreCase("/META-INF/", 0))
|| (requestPathMB.equalsIgnoreCase("/META-INF"))
|| (requestPathMB.startsWithIgnoreCase("/WEB-INF/", 0))
|| (requestPathMB.equalsIgnoreCase("/WEB-INF"))) {
response.sendError(HttpServletResponse.SC_NOT_FOUND);
return;
}
// Select the Wrapper to be used for this Request
Wrapper wrapper = request.getWrapper();
if (wrapper == null || wrapper.isUnavailable()) {
response.sendError(HttpServletResponse.SC_NOT_FOUND);
return;
}
// Acknowledge the request
try {
response.sendAcknowledgement();
} catch (IOException ioe) {
container.getLogger().error(sm.getString(
"standardContextValve.acknowledgeException"), ioe);
request.setAttribute(RequestDispatcher.ERROR_EXCEPTION, ioe);
response.sendError(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);
return;
}
if (request.isAsyncSupported()) {
request.setAsyncSupported(wrapper.getPipeline().isAsyncSupported());
}
wrapper.getPipeline().getFirst().invoke(request, response);
}该方法也只是一些校验,最后卡是调用 wrapper.getPipeline().getFirst().invoke,获取到的也是基础阀门,该阀门是StandardWeapperValve ,我们看看该方法。该方法很重要。
9. wrapper.getPipeline().getFirst().invoke 解析
该方法超长:
@Override
public final void invoke(Request request, Response response)
throws IOException, ServletException {
// Initialize local variables we may need
boolean unavailable = false;
Throwable throwable = null;
// This should be a Request attribute...
long t1=System.currentTimeMillis();
requestCount++;
StandardWrapper wrapper = (StandardWrapper) getContainer();
Servlet servlet = null;
Context context = (Context) wrapper.getParent();
// Check for the application being marked unavailable
if (!context.getState().isAvailable()) {
response.sendError(HttpServletResponse.SC_SERVICE_UNAVAILABLE,
sm.getString("standardContext.isUnavailable"));
unavailable = true;
}
// Check for the servlet being marked unavailable
if (!unavailable && wrapper.isUnavailable()) {
container.getLogger().info(sm.getString("standardWrapper.isUnavailable",
wrapper.getName()));
long available = wrapper.getAvailable();
if ((available > 0L) && (available < Long.MAX_VALUE)) {
response.setDateHeader("Retry-After", available);
response.sendError(HttpServletResponse.SC_SERVICE_UNAVAILABLE,
sm.getString("standardWrapper.isUnavailable",
wrapper.getName()));
} else if (available == Long.MAX_VALUE) {
response.sendError(HttpServletResponse.SC_NOT_FOUND,
sm.getString("standardWrapper.notFound",
wrapper.getName()));
}
unavailable = true;
}
// Allocate a servlet instance to process this request
try {
if (!unavailable) {
servlet = wrapper.allocate();
}
} catch (UnavailableException e) {
container.getLogger().error(
sm.getString("standardWrapper.allocateException",
wrapper.getName()), e);
long available = wrapper.getAvailable();
if ((available > 0L) && (available < Long.MAX_VALUE)) {
response.setDateHeader("Retry-After", available);
response.sendError(HttpServletResponse.SC_SERVICE_UNAVAILABLE,
sm.getString("standardWrapper.isUnavailable",
wrapper.getName()));
} else if (available == Long.MAX_VALUE) {
response.sendError(HttpServletResponse.SC_NOT_FOUND,
sm.getString("standardWrapper.notFound",
wrapper.getName()));
}
} catch (ServletException e) {
container.getLogger().error(sm.getString("standardWrapper.allocateException",
wrapper.getName()), StandardWrapper.getRootCause(e));
throwable = e;
exception(request, response, e);
} catch (Throwable e) {
ExceptionUtils.handleThrowable(e);
container.getLogger().error(sm.getString("standardWrapper.allocateException",
wrapper.getName()), e);
throwable = e;
exception(request, response, e);
servlet = null;
}
// Identify if the request is Comet related now that the servlet has been allocated
boolean comet = false;
if (servlet instanceof CometProcessor && request.getAttribute(
Globals.COMET_SUPPORTED_ATTR) == Boolean.TRUE) {
comet = true;
request.setComet(true);
}
MessageBytes requestPathMB = request.getRequestPathMB();
DispatcherType dispatcherType = DispatcherType.REQUEST;
if (request.getDispatcherType()==DispatcherType.ASYNC) dispatcherType = DispatcherType.ASYNC;
request.setAttribute(Globals.DISPATCHER_TYPE_ATTR,dispatcherType);
request.setAttribute(Globals.DISPATCHER_REQUEST_PATH_ATTR,
requestPathMB);
// Create the filter chain for this request
ApplicationFilterFactory factory =
ApplicationFilterFactory.getInstance();
ApplicationFilterChain filterChain =
factory.createFilterChain(request, wrapper, servlet);
// Reset comet flag value after creating the filter chain
request.setComet(false);
// Call the filter chain for this request
// NOTE: This also calls the servlet's service() method
try {
if ((servlet != null) && (filterChain != null)) {
// Swallow output if needed
if (context.getSwallowOutput()) {
try {
SystemLogHandler.startCapture();
if (request.isAsyncDispatching()) {
//TODO SERVLET3 - async
((AsyncContextImpl)request.getAsyncContext()).doInternalDispatch();
} else if (comet) {
filterChain.doFilterEvent(request.getEvent());
request.setComet(true);
} else {
filterChain.doFilter(request.getRequest(),
response.getResponse());
}
} finally {
String log = SystemLogHandler.stopCapture();
if (log != null && log.length() > 0) {
context.getLogger().info(log);
}
}
} else {
if (request.isAsyncDispatching()) {
//TODO SERVLET3 - async
((AsyncContextImpl)request.getAsyncContext()).doInternalDispatch();
} else if (comet) {
request.setComet(true);
filterChain.doFilterEvent(request.getEvent());
} else {
filterChain.doFilter
(request.getRequest(), response.getResponse());
}
}
}
} catch (ClientAbortException e) {
throwable = e;
exception(request, response, e);
} catch (IOException e) {
container.getLogger().error(sm.getString(
"standardWrapper.serviceException", wrapper.getName(),
context.getName()), e);
throwable = e;
exception(request, response, e);
} catch (UnavailableException e) {
container.getLogger().error(sm.getString(
"standardWrapper.serviceException", wrapper.getName(),
context.getName()), e);
// throwable = e;
// exception(request, response, e);
wrapper.unavailable(e);
long available = wrapper.getAvailable();
if ((available > 0L) && (available < Long.MAX_VALUE)) {
response.setDateHeader("Retry-After", available);
response.sendError(HttpServletResponse.SC_SERVICE_UNAVAILABLE,
sm.getString("standardWrapper.isUnavailable",
wrapper.getName()));
} else if (available == Long.MAX_VALUE) {
response.sendError(HttpServletResponse.SC_NOT_FOUND,
sm.getString("standardWrapper.notFound",
wrapper.getName()));
}
// Do not save exception in 'throwable', because we
// do not want to do exception(request, response, e) processing
} catch (ServletException e) {
Throwable rootCause = StandardWrapper.getRootCause(e);
if (!(rootCause instanceof ClientAbortException)) {
container.getLogger().error(sm.getString(
"standardWrapper.serviceExceptionRoot",
wrapper.getName(), context.getName(), e.getMessage()),
rootCause);
}
throwable = e;
exception(request, response, e);
} catch (Throwable e) {
ExceptionUtils.handleThrowable(e);
container.getLogger().error(sm.getString(
"standardWrapper.serviceException", wrapper.getName(),
context.getName()), e);
throwable = e;
exception(request, response, e);
}
// Release the filter chain (if any) for this request
if (filterChain != null) {
if (request.isComet()) {
// If this is a Comet request, then the same chain will be used for the
// processing of all subsequent events.
filterChain.reuse();
} else {
filterChain.release();
}
}
// Deallocate the allocated servlet instance
try {
if (servlet != null) {
wrapper.deallocate(servlet);
}
} catch (Throwable e) {
ExceptionUtils.handleThrowable(e);
container.getLogger().error(sm.getString("standardWrapper.deallocateException",
wrapper.getName()), e);
if (throwable == null) {
throwable = e;
exception(request, response, e);
}
}
// If this servlet has been marked permanently unavailable,
// unload it and release this instance
try {
if ((servlet != null) &&
(wrapper.getAvailable() == Long.MAX_VALUE)) {
wrapper.unload();
}
} catch (Throwable e) {
ExceptionUtils.handleThrowable(e);
container.getLogger().error(sm.getString("standardWrapper.unloadException",
wrapper.getName()), e);
if (throwable == null) {
throwable = e;
exception(request, response, e);
}
}
long t2=System.currentTimeMillis();
long time=t2-t1;
processingTime += time;
if( time > maxTime) maxTime=time;
if( time < minTime) minTime=time;
}我们分析一下该方法的重要步骤:
1. 获取 StandardWrapper(封装了Servlet) 实例调用 allocate 方法获取 Stack 中的 Servlet 实例;
2. 判断servlet 是否实现了 CometProcessor 接口,如果实现了则设置 request 的comet(Comet:基于 HTTP 长连接的“服务器推”技术) 属性为 true。
3. 获取 ApplicationFilterFactory 单例(注意:这个获取单例的代码是有线程安全问题的),调用该单例的 createFilterChain 方法获取 ApplicationFilterChain 过滤器链实例。
4. 执行过滤器链 filterChain 的 doFilter 方法。该方法会循环执行所有的过滤器,最终执行 servlet 的 servie 方法。
我们分析一下 allocate 方法。
10. StandardWrapper.allcate 获取 Servlet 实例方法解析
源码:
@Override
public Servlet allocate() throws ServletException {
// If we are currently unloading this servlet, throw an exception
if (unloading)
throw new ServletException
(sm.getString("standardWrapper.unloading", getName()));
boolean newInstance = false;
// If not SingleThreadedModel, return the same instance every time
if (!singleThreadModel) {
// Load and initialize our instance if necessary
if (instance == null) {
synchronized (this) {
if (instance == null) {
try {
if (log.isDebugEnabled())
log.debug("Allocating non-STM instance");
instance = loadServlet();
if (!singleThreadModel) {
// For non-STM, increment here to prevent a race
// condition with unload. Bug 43683, test case
// #3
newInstance = true;
countAllocated.incrementAndGet();
}
} catch (ServletException e) {
throw e;
} catch (Throwable e) {
ExceptionUtils.handleThrowable(e);
throw new ServletException
(sm.getString("standardWrapper.allocate"), e);
}
}
}
}
if (!instanceInitialized) {
initServlet(instance);
}
if (singleThreadModel) {
if (newInstance) {
// Have to do this outside of the sync above to prevent a
// possible deadlock
synchronized (instancePool) {
instancePool.push(instance);
nInstances++;
}
}
} else {
if (log.isTraceEnabled())
log.trace(" Returning non-STM instance");
// For new instances, count will have been incremented at the
// time of creation
if (!newInstance) {
countAllocated.incrementAndGet();
}
return (instance);
}
}
synchronized (instancePool) {
while (countAllocated.get() >= nInstances) {
// Allocate a new instance if possible, or else wait
if (nInstances < maxInstances) {
try {
instancePool.push(loadServlet());
nInstances++;
} catch (ServletException e) {
throw e;
} catch (Throwable e) {
ExceptionUtils.handleThrowable(e);
throw new ServletException
(sm.getString("standardWrapper.allocate"), e);
}
} else {
try {
instancePool.wait();
} catch (InterruptedException e) {
// Ignore
}
}
}
if (log.isTraceEnabled())
log.trace(" Returning allocated STM instance");
countAllocated.incrementAndGet();
return instancePool.pop();
}
}该方法很长,我们来看看该方法步骤: 判断该类(StandardWrapper)中的 Servlet 实例是否为null,默认不为null,该实例在初始化的时候就已经注入,如果没有注入,则调用 loadServlet 方法,反射加载实例(注意,如果这个servlet 实现了 singleThreadModel 接口,该StandardWrapper 就是多个servlet 实例的,默认是单个实例,多个实例会放入一个Stack(这个栈不是早就不建议使用了吗) 类型的栈中)。
11. ApplicationFilterFactory 解析(tomcat 7 会有并发问题)
获取创建过滤器链工厂的单例,但楼主看了代码,发现该代码一定会有问题。
public static ApplicationFilterFactory getInstance() {
if (factory == null) {
factory = new ApplicationFilterFactory();
}
return factory;
}读过楼主 深入解析单例模式 的文章应该知道,这种写法并发的时候一定是有问题的,会创建多个实例。但是楼主下载了最新的 tomcat 源码,已经解决了该 bug,新的 tomcat 已经把 getInstance 去除了,将 createFilterChain 方法改为静态方法。
获取过滤器工厂链后,创建过滤器链实例,从该Wrapper 中获取父容器,从父容器 StandardContext 中获取实例,从该实例中获取 filterMaps,该 filterMaps 在初始化容器时从web.xml 中创建。
12. 执行过滤器链的 doFilter 方法
该方法主要执行 ApplicationFilterChain.internalDoFilter() 方法,那么 方法 internalDoFilter 内部又是如何实现的呢?下面时该方法的主要逻辑(主要时楼主字数受限了):java
// Call the next filter if there is one
if (pos < n) {
filter.doFilter(request, response, this);
}
servlet.service(request, response);
可以看到,ApplicationFilterChain 中维护了2个变量,当前位置 pos 和 过滤器数量,因此要执行完所有的过滤器,而过滤器最终又会执行 doFilter 方法,就会又回到该方法,直到执行完所有的过滤器,最后执行 servlet 的 service 方法。到这里,一个完整的http请求就从socket 到了我们编写的servlet中了。
13. 总结
终于,我们完成了对tomcat请求过程的剖析,详细理解了tomcat是如何处理一个http请求,也完了我们最初的计划,下一篇就是总结我们的前9篇文章,敬请期待。
深入理解 Tomcat(十) 总结_ignore-CSDN博客
前言
这篇文章是我们深入理解 Tomcat 的第十篇文章,也是总结文章, 学习就是这样,先是理论,再是实践,最后是总结, 楼主习惯了在每次学习之后总结, 让从脑海中过的知识能够再扎实一点.
我们的第一篇文章 << 深入理解 Tomcat(一)源码环境搭建和 How Tomcat works 源码>>中介绍了楼主下载的源码和 git 地址, 方便大家去 clone 源码,不然怎么来依据理论去剖析源码实现呢? 楼主认为, 任何一门技术都要借助文档和源码一起去理解(可能是楼主比较菜). 而楼主也放了2个源码,一个是使用 maven 改过的 tomcat 7 源码,一个是名著 <> 的实例源码, 方便我们更深入的理解 tomcat.
源码环境搭建好了,楼主从网上,从早上… 额,不, 从各个地方看文章, 想了解 tomcat 的结构设计和文档, 当然也搭配楼主从图书馆借来的 <<How Tomcat Works>> 书, 最终写了一篇 <<深入理解 Tomcat (二) 从宏观上理解 Tomcat 组件及架构>>, 我们讲了我们准备如何学习, 以及什么是 Tomcat , 什么是 Servlet, tomcat 源码目录的解释, tomcat 整体框架的层次结构和架构图, 分析每个组件, 包括 Connector, Container, Component, 也从接口和类的角度(UML 类图)看架构. 这让我们对 tomcat 整体也有了一个大致的了解, 为我们接下来的分析源码做了铺垫.
我们在大致了解了 tomcat 的整体架构和设计后, 我们想了解一个最简单的 web 服务器是如何实现的, 我们写了一篇<< 深入理解 Tomcat(三)Tomcat 底层实现原理>>, 参照<<How Tomcat Works>>源码实现了一个简单的阻塞式的 Web 服务器, 虽然现在最新的 Tomcat 9 已经将阻塞 socket 去除了,全部使用 NIO 和 JNI 以提高速度, 但他仍是我们学习的一个很好的例子.
在了解原理之后, 我们开始循序渐进, 我们的第一个研究的就是著名的 Tomcat 的类加载机制, 于是我们写了一篇 << 深入理解 Tomcat(四)Tomcat 类加载器之为何违背双亲委派模型>>, 先从 java 的类加载器开始分析, 分析双亲委任模型的原理, 以及类加载机制的发展及变化, 最后讲 Tomcat 的类加载机制的设计, 讲 Tomcat 为何破坏双亲委派模型. 也讲了 Tomcat 中每个类加载器的功能. 从理论上了解了 Tomcat 类加载器的设计. 为我们从源码层面理解做了铺垫.
在了解了 Tomcat 的类加载器理论后, 我们第一次开始 debug tomcat 的源码, 写了一篇<<深入理解 Tomcat(五)源码剖析Tomcat 启动过程----类加载过程>>, 从 BootStrap 开始, 我们一步步分析 Tomcat 是如何加载类,加载 jar 包, 是如何将公用的 jar 包使用 common 类加载器, 而私有的 jar 包及 web 应用使用
WebAppClassLoader 的. 并且知道了 WebAppClassLoader的加载时间和另外几个的时间不一致. 从源码层面知道了 Tomcat 的类加载设计和机制.
我们继续深入 tomcat, 开始按照我们在第二篇文章中的计划去阅读源码, 我们写了 << 深入理解 Tomcat(六)源码剖析Tomcat 启动过程----生命周期和容器组件>>, 深入源码去了解 tomcat 是如何设计容器,容器是如何初始化的, 又是如何交给 JMX 去管理对象的. tomcat 的众多容器又是如何通过观察者模式来管理他们的生命周期的.
在了解了 tomcat 的生命周期组件和容器初始化过程后, 我们决定从整体上看看 tomcat 是如何启动的又是如何关闭的, 我们写了 <<深入理解 Tomcat(七)源码剖析 Tomcat 完整启动过程>>并且也见到 tomcat 传说中的钩子. tomcat 的关闭很有趣, 靠着启动一个 socket 去发送SHUTDOWN命令.
之后我们决定去深入另一个很重要的组件—-连接器, 在 <<深入理解 Tomcat(八)源码剖析之连接器>>中, 我们深入源码, 理解了连接器 Connector 的构造过程, 连接器是如何初始化的, 又是如何启动, 启动之后如何监听 Http 请求端口的. 如何处理浏览器发送过来的 socket 请求的.这些实在是太有意思了.
最后我们以一个最常见的请求为基础, 写了 <<深入理解 Tomcat(九)源码剖析之请求过程>>, 理解了一个 HTTP 请求是如何从 socket 到达我们编写的 Servlet 的, 并且了解了tomcat 是如何设计各个容器直接的通信—-使用管道和阀门. 也知道了 tomcat 是如何解析消息头, 如何设计过滤器. 让我们对 tomcat 的认识可以说更加的清晰.我们无意中也发现了 tomcat 7 中关于单例模式的一个潜在 bug(最新的 tomcat 已经修复).
最后, 就到了我们这篇总结的文章, 总的来说, 我们完成了我们最初定制的任务, 剖析了最重要的几个组件, 包括类加载器, 容器, 生命周期管理, 连接器, 管道, 阀门, 从启动过程和请求过程这两条路线去分析源码, 让我们不会在浩瀚的源码世界迷路. 虽然还要一些源码没有阅读, 但我们相信, 我们已经体会到了 tomcat 最重要的东西, 我们也不可能将所有的源码全都阅读一遍, 楼主是万万做不到的.
想想楼主最初阅读源码的目的, 就是好奇 tomcat 到底是如何实现的. 现在, 楼主认为楼主的疑问已经被解答, 接下来, 楼主就要研究另一个 Java 世界中有名的框架了, 楼主不要做个只知道 know how 不知道 know why 的人.

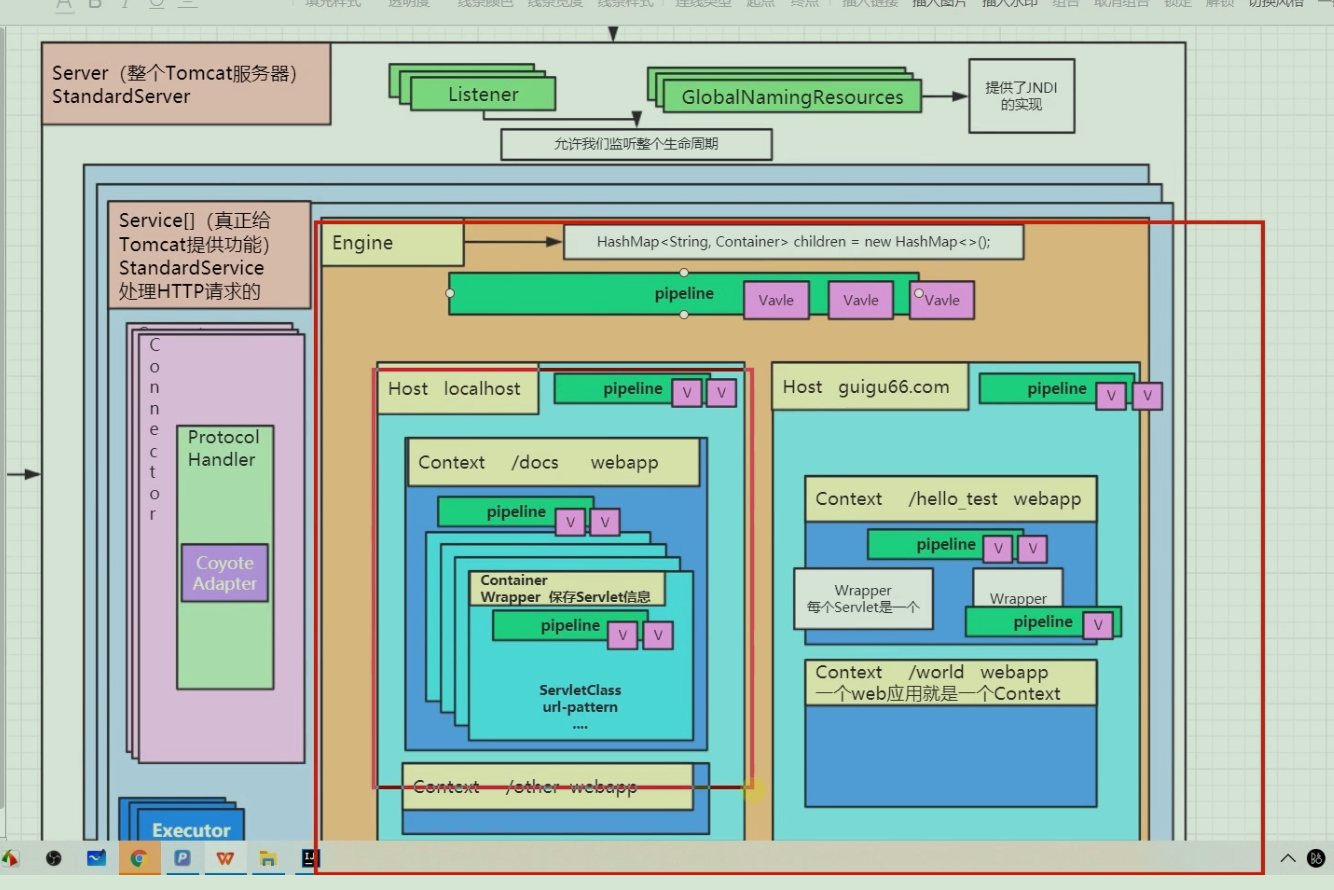

 浙公网安备 33010602011771号
浙公网安备 33010602011771号