BUAA-OO 第一单元总结
BUAA-OO 第一单元总结
前言
OO第一单元的三次作业都围绕着表达式展开进行。从面向过程编程逐渐转换为面向对象编程、每次作业的拓展迭代都是不小的挑战。尽管完成了三次作业,但是自己还有一些地方存在缺陷,需要进一步反思。希望能够通过这次博客作业来分析和总结这单元的收获与不足。
一、程序结构分析
1. 第一次作业
1.1 类图与设计思路
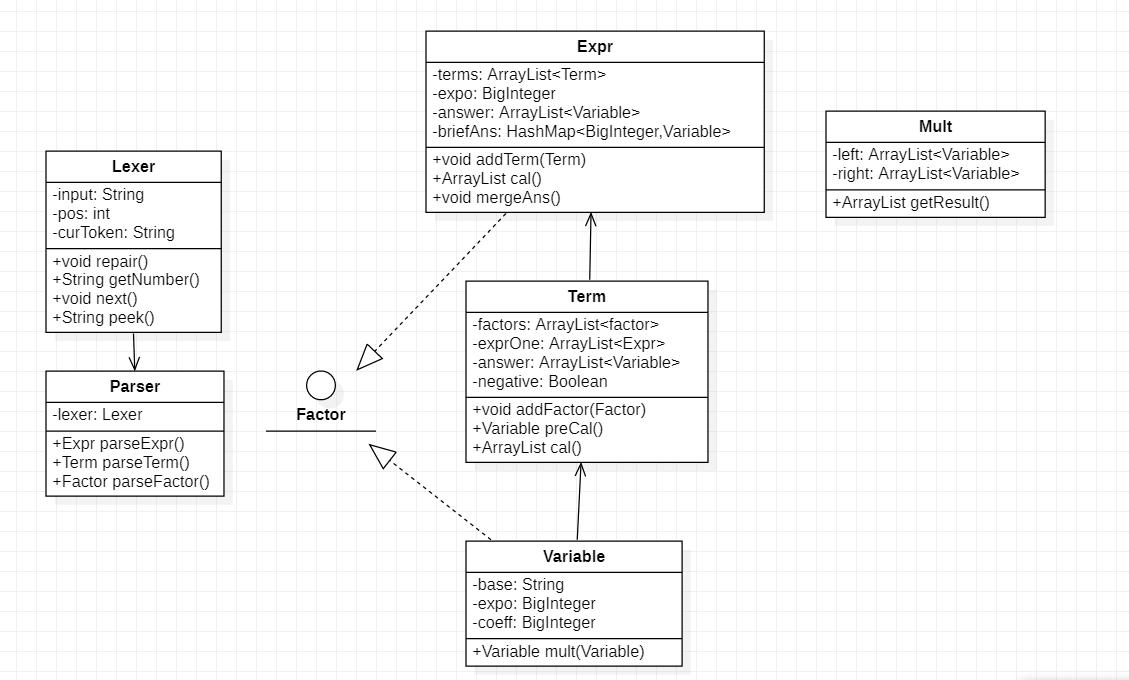
我在完成第一次作业的思路是:解析输入、建立表达式树、计算化简、输出。
对于解析输入部分,我参考了训练中的递归下降的解析方法,建立了Lexer类和Parser类对输入进行解析。通过递归的方式可以比较方便地根据形式化定义来解析出相应的类型并建立对象,也可以比较有效地避免正则表达式中一些细节方面的错误,如符号错误等。Lexer(词法分析器)类的功能主要是将输入的字符串转换成有意义的子串,如"+", "-", "*"和数字等,为进一步解析提供便利。Parser类则是类似于字符状态机,使用Lexer提供的具有词义的字符串来建立对象。
在建立表达式树部分,我根据题目的形式化定义建立了Expr、Term、Variable(包括幂函数和常数)三类。其中,Expr和Variable类实现了Interface接口(这个接口在第一次作业中只是为了方便引用,并没有实际的方法接口)。这三个类具有比较明显的层次化结构,可以比较容易地通过解析输入建立起整个表达式树。(类图中的实线箭头Association表示层次之间的关系)
计算化简部分是第一次作业我遇到的最大难题——Term所管理的Factor中可能涉及到表达式因子的展开,从而又会形成若干个Term。这使我在设计时感到无从下手。但是在阅读了讨论区其他同学的文章后,我受到了很大的启发:我们最终得到的形式一定是若干个“常数*幂函数”的和,因此我们在计算时,无论是Term的计算还是Expr的计算,最终都是得到若干个Variable。于是,通过Term和Expr之间的递归计算,再通过Mult类实现ArrayList<Variable>之间的乘法,这个问题就迎刃而解了。这也提醒我,它山之石可以攻玉,善于利用讨论区,积极和其他同学沟通想法,对于不断拓展自己眼界、不断进步有十分重要的作用。
在输出部分,只需要重写各个表达式类的toString()方法就可以得到输出。不过需要注意在化简时可能导致的非法形式错误。
第一次作业比较清晰的层次结构也为后面的两次作业打下一定的基础。但是类与类之间的关系主要是通过层次化的逻辑来表现的,在继承和实现上表现的还不够清晰(这一点在后面的多种因子中更加突出)。
1.2 复杂性度量
1.2.1 类复杂度

可以看出,Parser类的OCavg(类平均圈复杂度)最高,这是因为Parser类是类似有限状态机的一种解析器,需要对当前状态(curToken)进行判断以得出下一状态,而我的Parser类涉及到对Expr、Term、Number、Factor等的判断,同时Parser类是建立起表达式树的基础,在解析时还没有完全建立起整个层次化结构,需要用很多条件语句进行判断,因此平均圈复杂度最高。
1.2.2 方法复杂度
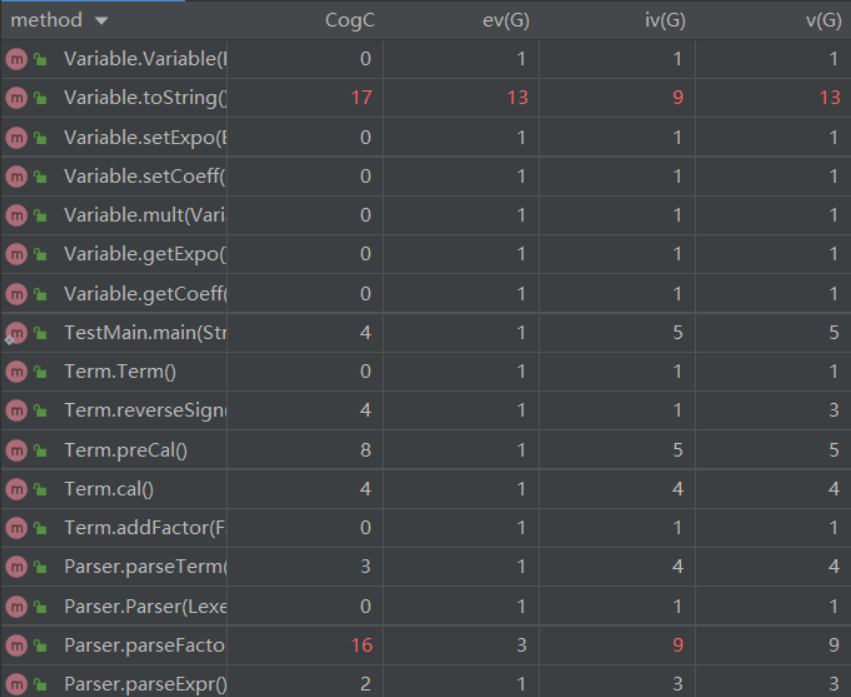
图中是部分有代表性的方法复杂度。第一次作业中,方法复杂度比较高的是Parser类的parseFactor()方法和Variable类的toString()方法。这两个方法内都进行了非常多的条件判断,尤其是Variable类的toString()方法,为了达到化简的目的,对尽可能多的情况进行分类处理,导致高复杂度。这也是我的一个不足之处,其实完全可以将各种特殊情况实现对应的化简方法,最后再在toString()方法中使用,而不是一股脑全塞在toString()方法中。而在Parser类的parseFactor()方法,该方法分别进行条件判断,调用了解析三种特定因子的方法,因此耦合复杂度较高,但是基本复杂度较低,尚可接受。这也提醒我,在接下来的学习中,要进一步注意方法的解耦,尤其要避免方法中使用一大串的条件判断语句和循环语句,尽可能降低一个方法内部流程的复杂度。
2.第二次作业
2.1 类与设计思路
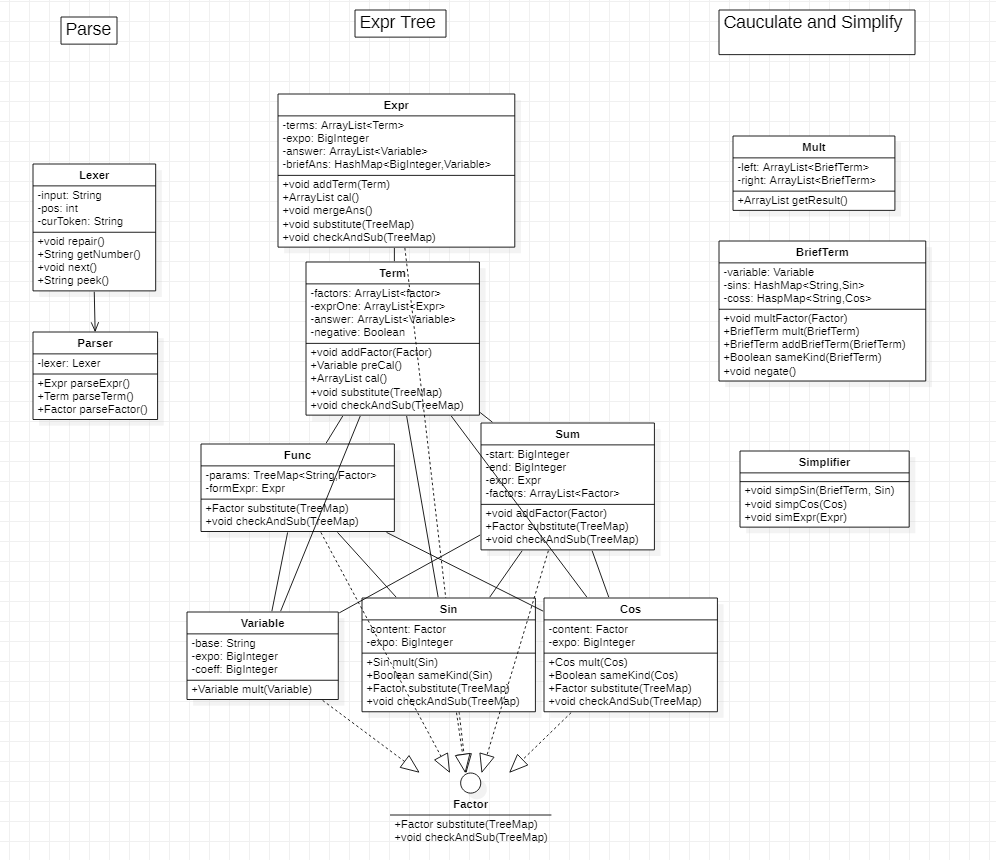
第二次作业由于涉及到自定义函数和求和函数,类的层次就更加复杂了,同时构建了新的类来进行化简。
我完成第二次作业的思路是:解析输入、建立表达式树、代入实参、计算化简、输出。
解析输入部分,和第一次作业一样使用了递归下降的方法。比较大的不同是,在读入函数定义时,需要对形式表达式和形式参数进行保存。而在解析表达式时,遇到函数调用则先解析形式表达式,之后才代入实参。
在代入实参部分,为了保存每次函数调用的形参、实参的对应关系,我在Func类中使用了TreeMap来保存,主要是考虑到TreeMap的自有序性,总能保证形参“x”(如果有的话)最先被代入,避免了形参“x”在其他形参代入之后才代入时可能导致的bug。代入实参的具体实现方法是一个比较头疼的事。但是,参考第一次作业中得到的形式一定是”常数*幂函数“,我想到实参代入也是一个递归的过程,最终真正代入的只有最底层的几种基本因子(常数、幂函数、三角函数),因此只要实现了基本因子的代入方法,其他上层结构只需要递归调用即可。这使我深刻感受到,递归的过程一开始很难理解,但是只要弄明白最终调用的简单底层函数(终止条件)就很好理解了,至于高层次的递归调用只需要从逻辑上考虑即可。
在计算化简部分,考虑到最终化简形式一定是若干个项(BriefTerm)的加减,而每个BriefTerm则形如"常数*幂函数*若干sin*若干cos",通过掌握了最底层的终止条件,就可以再次利用类似第一次作业的递归计算化简来解决。由于这次作业化简的复杂度大大提高,我构建了一个Simplifier类来实现三角函数的化简。
第二次作业比较好的拓展性(如sin、cos内允许其他类型因子)也为第三次作业打下了一定基础。
2.2 复杂性度量
2.2.1 类复杂度
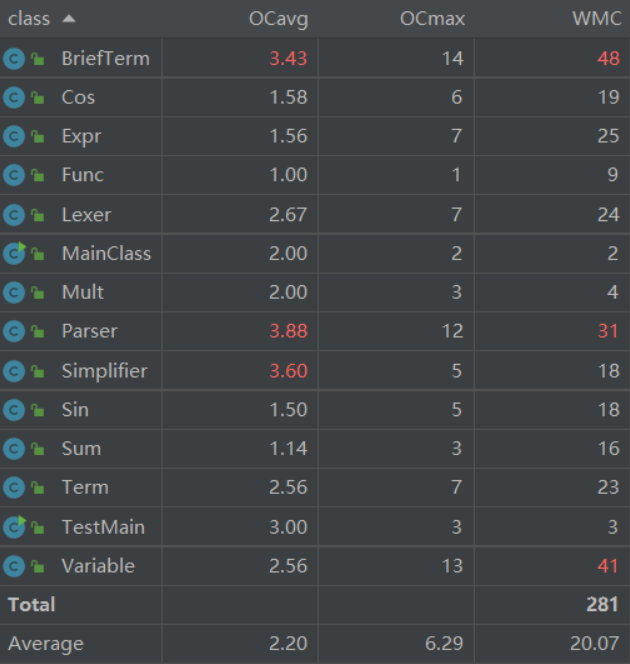
第二次作业的类复杂度相比第一次有了比较大的提高。其中,由于引入新的因子类型使Parser类的复杂度再度提高。
为了保持BriefTerm的最简性质,在每次加入一个基本因子时都会对其进行判断而不是直接加入。尽管这为后面的化简部分分担了一些工作,但也导致BriefTerm内部存在大量的判断语句,从而大大提高了其复杂度。
另一个复杂度较高的是Simplifier类,同样为了尽可能化简也要进行大量的条件判断。我认为化简部分的条件判断比较难以避免,但是可以通过预先设计好清晰的逻辑(如各种情况的分类等)来降低复杂度和出现bug的可能性。
2.2.2 方法复杂度
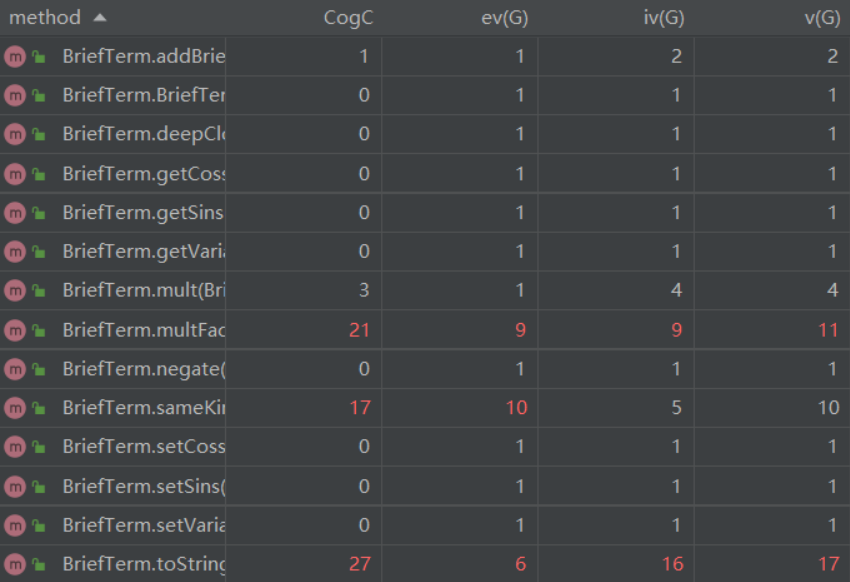
图中是BriefTerm的方法复杂度(这次作业比较突出的复杂方法都在BriefTerm类中),除此之外复杂度较高的方法是第一次作业同样出现的Parser类的parseFactor()方法与Variable类的toString()方法。
multFactor()方法为了维护BriefTerm的最简性,采用了大量条件判断语句和调用其他类的toString()方法,无论是基本复杂度还是设计复杂度(耦合)都很高。而sameKind()方法则是用于判断同类项,采用了遍历循环+条件判断的结构,基本复杂度很高。最后仍然是toString()方法,大量判断语句和其他类的toString()方法的耦合、各种边界情况的处理使其复杂度飙升。
3.第三次作业
3.1 类图与设计思路
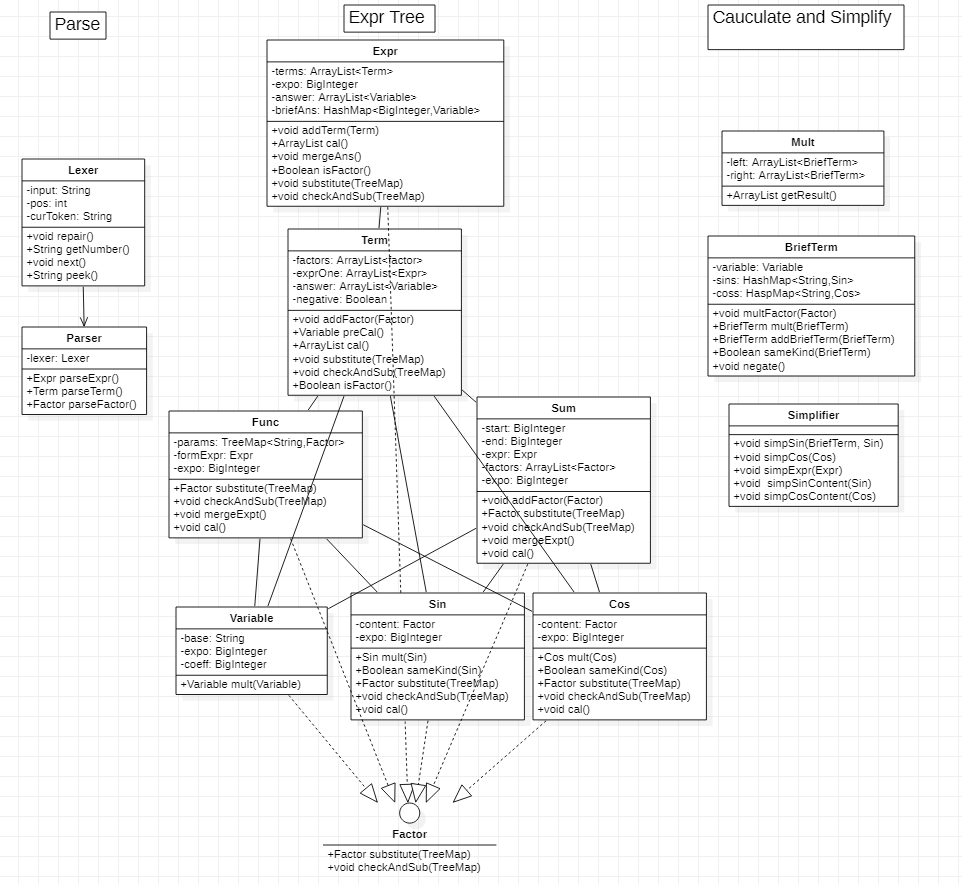
第三次作业由于第二次作业比较好的拓展性,没有再创建新的类,而是修改原有类的属性方法以兼容新的题目要求。
我完成第三次作业的思路与第二次相同:解析输入、建立表达式树、代入实参、计算化简、输出。
代入实参部分,与第二次作业不同的是,在对表达式树中某个节点代入后,需要继续向下检查是否还有要代入的地方,因为函数调用时的实参可能是自定义函数因子,意味着代入一次实参后还要继续多次代入。由于第二次作业采用递归代入的方法,因此稍微修改即可解决这个问题。
计算化简部分则是这次作业我面临的一个比较大的困难。计算化简部分不仅涉及到整体表达式的化简,还涉及到三角函数内部表达式的计算化简。这是前两次作业中我没有考虑过的。在确定了“先计算化简三角函数内部表达式,再计算化简项和整体表达式”的顺序后,通过递归的计算化简方法,也算是解决了这个问题。其中,递归的思路是解决这个问题的关键,依然需要清楚地把握递归最后的终止条件和递归逻辑。
输出部分我只增加了三角函数内部的化简输出(如括号的层数),但是这一部分我却忽略了之前建构起来的整个层次化结构,直接采用简单暴力的判断方法,导致了一个非法输出的bug。
3.2 复杂性度量
3.2.1 类复杂度
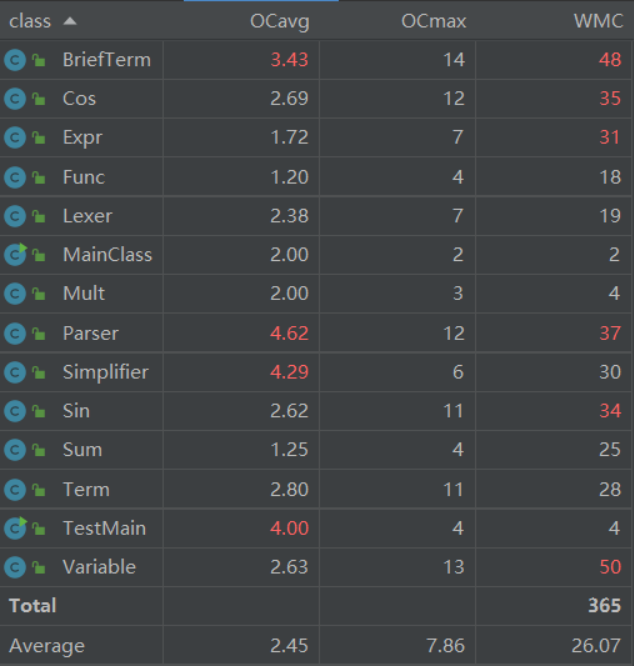
与第二次作业相同,平均复杂度较高的类依然是BriefTerm、Parser和Simplifier三个类。这三个类由于依赖大量的循环、判断语句嵌套以实现化简的目的,其平均复杂度高于其他类。此外,Cos、Sin类由于允许内含表达式因子等多种因子,引入了对应的判断和计算方法,其复杂度相比第二次作业也有一定的提高。
3.2.2 方法复杂度
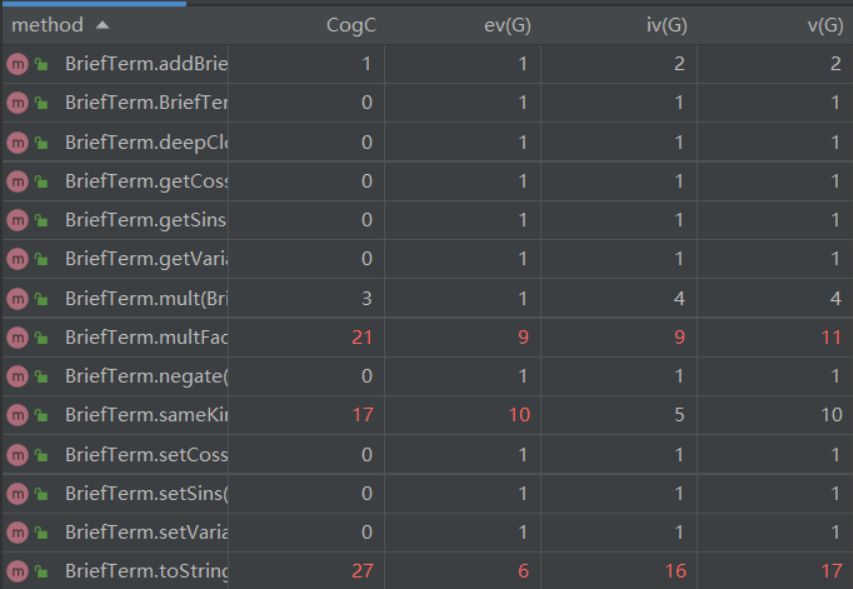
本次作业中方法复杂度较高的依然是BriefTerm中的三个化简与输出方法,内含大量判断与循环。

不过,与第二次作业不同的是,Term的计算方法preCal()的复杂度大幅度上升,尤其是与耦合相关的设计复杂度。这是因为在第二次作业中,计算Term不涉及到三角函数内部的计算,但这次作业计算Term时,需要先调用三角函数内部的计算方法以处理三角函数内部表达式,然后再返回项进行计算。这就使得项的计算与三角函数内部计算相耦合,同时还涉及到各类因子的克隆,导致了其设计复杂度的提高。

Sin和Cos的toString()方法复杂度也偏高,主要是因为化简时的多重判断。
二、程序Bug分析
1. 第一次作业
第一次作业由于结构相对简单,并没有被发现Bug。但是第一次作业中一些复杂的方法给后面埋下了隐患。
2. 第二次作业
第二次作业在互测中被发现了一个Bug——sin(0)**0错误输出为0。主要是因为自己忽略了0**0这种情况,尽管在第一次作业中考虑了,但是忽略了第二次作业新加入的sin仍然可能产生这个问题。

该Bug对应的方法是Sin类的toString()方法,可以看到其还是具有一定的复杂度。我认为产生这个Bug的原因主要是因为自己在考虑情况时不够周全,将sin()的值为0和指数为0分开考虑了,而忽略了两者同时为0的情况。这类由于多重判断嵌套,忽略某种情况而产生的Bug,我在自己测试的过程中也发现了不少。这也提醒我,在面对多种条件判断时,应当先理清好思路,弄清楚各种情况间是互不相容还是有交集,甚至是包含关系,同时还要看看边界极端情况是否能够得到正确的结果。
在自己测试的过程中,我发现了一个由于浅拷贝而产生的Bug,即改变一个对象,导致其他浅拷贝对象也发生改变,最终这种改变不断累加导致结果错误。我参考了讨论区同学提出的序列化拷贝解决了这个问题。但是我认为自己的架构应该在一开始就确定哪些类不可变,每个方法是返回一个深拷贝还是在原来的对象上进行改变的问题,这也是以后需要注意的。
3. 第三次作业
第三次作业在强测和互测中被发现了一个Bug——Sin和Cos对内部因子的暴力判断导致输出形式非法,如sin(-x)、sin(x+5)等。

该Bug对应的方法是Term类的isFactor()方法,用于判断Term中是否只含有一个基本因子从而可以去除括号。可以看到,这个方法的复杂度不算太高。问题就在于,我的判断完全忽略了之前建立起来的表达式树模型,而为了省事直接采用简单暴力的判断方法。
public Boolean isFactor() {
return this.factors.size() == 1;
}
在之前的模型中,Term的因子除了基本因子,还可能是复杂的表达式因子、函数因子。而在最后的化简步骤却忽视了这点。实际上,要真正地解决这个问题,依然需要利用建立起来的表达式树和递归的方法来逐级向下判断,而不能简单地直接判断。一部分原因是自己在最后关头没有仔细思考而是急于求成,无视整个层次化结构(这正是作业中的核心部分),另一部分原因则是因为自己的测试机制不够全面(在后文具体描述)。这提醒我在接下来的学习中,要有大局观念,要时时记住整体的结构,不能因为某些细节部分而无视整体的框架,只见树木不见森林。
三、自动测试与Hack策略
在这单元的作业中,无论是自测还是互测,我都采用自动测试的方法,因此将两部分结合在一起,对自己在第一单元采用自动测试的经验和教训做一个总结。
1. 自动测试
关于自动测试,从计组开始我就尝试着利用自动测试来检验程序,但是由于计组生成数据的难度较大(P7之前需要保证指令不出现异常),自己直到OO才真正有机会实现自动测试。
我认为,自动测试的主要过程是:生成数据、运行待测程序、正确性检验。其中最重要的是生成数据和正确性检验两个部分。
1.1 生成数据
生成数据时,既要保证数据的合法性(符合形式化定义),又要尽可能全面地覆盖多种情况。第一单元想生成合法数据并不难。我们的作业是一个将表达式由上到下解析成层次化结构的过程,而生成测试数据则是相反的从下到上的构建过程。但是要保证数据的全面性则是一个挑战。一方面,过于极端的测试数据的累加可能导致测试时间过长甚至程序崩溃(如多重sin、cos的累加嵌套,过大的指数),另一方面,普通的测试数据又没有测试价值。因此,在构造测试数据时,应当手动构造和自动构造相结合。
我们可以利用程序生成大范围覆盖、随机性强、数量巨大的测试数据。这些数据可以检验程序的整体正确性,即整体的架构是否可以实现正确的功能。通过这些自动生成的数据,基本上可以排除程序中的整体性错误。但是,仅仅依赖自动生成的数据进行测试是不够的,因为一旦生成数据的程序漏了某种情况(如求和函数中s>e),将导致所有生成的数据对该情况毫无覆盖,而这将是致命的!!
因此,我们还需要手动构造测试数据。手动构造的数据应该覆盖:1.影响自动测试性能而在自动生成数据时没有使用的(如超大指数,超大常数)2.自动生成数据难以实现或出现概率很低的(如sin(x)**2+cos(x)**2等的检验)3.题目中特别要求的(如求和函数s>e时取0)。手动构造测试数据主要是对边界极端情况进行测试,为了提高测试强度也可以手动将自己手动构造的数据插入自动生成数据中。
这次我在生成测试数据的过程中,就遇到了自动生成测试数据漏掉求和函数的s、e可以带符号的情况,导致跑了上万个数据也没有测出来Bug。最后重新回看题目要求,手动构造了几个测试数据就发现了这个Bug。这也提醒我,之后如果采用自动生成数据的方法,也不可以完全依赖于程序自动生成,因为很多情况自己对题目哪些地方有坑点、自己的程序哪里可能有Bug是最清楚的,而程序并不清楚这一点,因此还需要自己根据实际情况来手动构造测试数据。
1.2 运行待测程序
我刚开始的想法是,生成测试数据的程序将数据写入input.txt,然后在java程序中写一个TestMain类以实现循环读入数据并将输出全部写入output.txt,最后由检验程序对两个文件的内容进行正确性比较。
后来在讨论区看到了敬睿涛同学关于使用subprocess库来运行子进程的帖子(http://oo.buaa.edu.cn/assignment/325/discussion/1098)后,我便采用了这种做法。这样就可以将生成数据、运行程序、检验三个过程整合起来。但是这样也有一个小弊端,就是调用子进程会占用额外的开销,导致自动测试的效率略有下降。
1.3 正确性检验
正确性检验是自动测试过程中非常重要的一步,也是我这次掉到坑里的地方。
首先,正确性检验需要一个标准程序作为对比,也可以和其他同学对拍。在第一次作业中,由于表达式比较简单,就使用了Sympy库来进行检验。在第二、三次作业中,由于涉及到求和函数、自定义函数,我采用了和同学进行对拍的方法(即利用Sympy检验两个人的答案结果是否相同)。
其次,正确性检验需要严格覆盖所有要求(“宁可错杀一千,不可放过一个”),而这正是我三次作业的自动测试中的一个重大漏洞!就这单元作业而言,除了使用Sympy库检验计算结果是否正确,还需要检验输出形式的合法性。我三次作业的正确性检验仅仅检验了计算结果的正确性,而忽略了输出形式的检验,这就导致我第三次作业输出非法的形式(如sin(x+5))但依然判定为正确,最终在强测和互测中被Hack,给我留下了深刻的教训。
在接下来的学习中,我会从这次自动测试的教训中吸取经验,进一步完善自己的测试技术,提高自己发现Bug的能力。
2. Hack策略
在这单元的三次互测中,我都采用自动测试来进行互测。自动测试允许在短时间内对多个程序进行大量的测试,因此在互测中效率比较高,可以很快发现程序中的Bug。不过,正如测自己的程序一样,如果测试数据覆盖不够广、正确性检验不严格,就很难测出Bug。因此需要一个比较完善的自动测试程序才能提高Hack效率。
但是,在这三周的互测中,我发现自己在一定程度上过于依赖自动测试,很少去读别人的代码,针对代码的弱处进行针对性Hack。我想这不是一个好的现象,也不是互测的意义所在。一方面,读懂别人的代码将是在未来和别人开展合作的重要基础,另一方面,别人的代码中也有很多东西值得自己学习,如更好的架构等。在接下来的互测环节中,我会尝试着去分析别人代码的长处和弱项,然后针对弱项手动构造测试数据再结合自动测试来Hack(黑盒-白盒结合测试),同时也在阅读别人代码的过程中向别人学习。
四、架构设计体验
这三次作业的解析部分我都采用了递归下降的方式。最开始在训练中接触到递归下降时,想了好久才勉强理解了这种方法。但是事实证明,这种解析方式使我在后面作业的迭代中不必做太大的改动,也可以避免正则表达式中诸多细节的可能错误。
在第二次作业中,涉及到自定义函数和求和函数,我的第一想法就是字符串替换——这样就能转换成第一次作业,再“充分利用”第一次作业的代码来完成第二次作业。不过在花了一个上午试图实现字符串替换而出现各种Bug之后,加上助教建议不要使用字符串替换,我就抛弃了这种“看起来很好”的方法,重新花了很多时间思考先建模后代入的方法。事实再次证明,这种方法使我能够比较适应第三次作业的各种嵌套问题。
通过这几次作业的架构设计过程,我明白设计时不应该以利用现有的代码为导向,而应该考虑是否能适应未来的各种情况。此外,在架构设计上花时间仔细思考是值得的。在这几次作业中,我有时也会思路还没理清就开始写代码,最终导致改的一塌糊涂而推倒,重新整理思路、重新构造。这也给我留下了深刻的教训,接下来一定要把整体的思路整理清楚了再开始写代码。
五、心得体会
第一单元很快就结束了,回想每周费眼读巨长的指导书——烧脑理思路——手残写Bug——无脑构造测试数据找Bug——头秃改Bug的快乐循环,心里还是很有成就感的。在这一单元,自己也学到了很多,无论是面向对象的思想,还是思路架构的设计,无论是码代码的能力,还是第一次尝试自动测试,在各个方面上自己的能力都得到了锻炼和提高。
当然,第一单元的学习中也出现了一些不足,希望在接下来的学习中有针对性地解决和改进。以下是一些反思和总结。(怕忘,写在最后)
-
涉及到一大堆条件判断、循环语句的,先整理思路,考虑各种情况之间的关系(包含、互不相容),再写到代码中,之后还要对边界条件进行检验。
-
递归要搞清楚最终终止条件,只要搞明白最终得到的形式是什么,就可以很容易理解递归的逻辑。
-
在设计细节时,也要考虑整体的架构,要遵循整体架构来设计细节的功能,不能简单粗暴地偷懒(尤其在最后阶段)
-
在设计的一开始就要想好哪些类是不可变的,哪些方法直接改变调用对象,哪些方法返回一个深拷贝
-
自动生成数据要再根据题目指导书(虽然巨长)检查有没有尽可能覆盖
-
不能完全依赖自动生成数据,自己要对题目的一些坑点边界情况和自己程序的弱处手动构造测试数据
-
正确性检验要严格覆盖所有要求,宁可错杀一千,不可放过一个
-
互测是一个向别人学习的好机会,不能过度依赖自动测试而忽略了代码阅读和分析
-
设计架构时不应该以利用现有的代码为导向,而应该考虑是否能适应未来的各种情况
-
在架构设计上花时间仔细思考是值得的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号