


OO第三单元总结
1. JML
JML是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言,基于Larch方法构建。BISL提供了对方法和类型的规格定义手段。
一般而言,JML有两种主要的用法:(1)开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。(2)针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
1.1 JML语言的理论基础
为了统一描述java程序的规格,JML定义了四种表达式:
(1)原子表达式:如\result, \old(expr), \not_assigned(x,y,...), \not_modified(x,y,...) ,\notnullelements(container), \type(type), \typeof(expr)等。
(2)量化表达式:如\forall表达式、\exists表达式等。
(3)集合表达式:通过集合表达式构造一个局部的容器,明确集合中包含的元素,其一般形式为:new ST {T x|R(x)&&P(x)},其中的R(x)对应集合中x的范围,通常是来自于某个既有集合中的元素。
(4)操作符:JML表达式中除了可以正常使用Java语言所定义的操作符外,还专门定义了四类操作符:子类型关系操作符、等价关系操作符、推理操作符和变量引用操作符。
使用上述的表达式,便可以进行JML的书写。
对于方法规格,JML区分这两种场景,分别对应正常行为规格和异常行为规格。规格由三个部分组成:
(1)前置条件:前置条件通过requires子句来表示:requires P;。其中requires是JML关键词,表达的意思是“要求调用者确保P为真”。
(2)后置条件:后置条件通过ensures子句来表示:ensures P;。其中ensures是JML关键词,表达的意思是“方法实现者确保方法执行返回结果一定满足谓词P的要求,即确保P为真”。
(3)副作用范围限定:副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响。
对于异常行为规格,还应当有signals字句,表示在满足一定条件下抛出异常。
通过上述方法规格的三个部分,就可以把一个方法的输入输出要求唯一确定下来,保证不会产生歧义,这正是规格化设计的目的之一。对副作用范围的限定,可以让调用者在调用某一方法时明确是否会对现有的对象产生影响以及对哪些对象产生影响。
除了方法规格外,还有类型规格来对Java程序中定义的数据类型设计限制规则。课程中的类型规格主要涉及两类:
(1)不变式限制:规定在所有可见状态下都必须满足的特性,形式为invariant P,其中invariant为关键词,P为谓词。
(2)约束限制:规定前序可见状态和当前可见状态的关系的约束,形式为constraint P。
1.2 JML应用工具链
(1)OpenJML:OpenJML可以完成对JML的静态检查,检查JML规格的正确性。比如在规格中少写了一个‘=’,它便会报如下错误:
给出错误的类型及位置。
(2)SMT Solver:SMT Solver用于验证代码等价性。
(3)JMLUnitNG:JMLUnitNG可以自动生成测试数据来验证代码的正确性。此单元我只是简单尝试了一下这个工具,具体内容见2.1。
(4)JMLUnit:JMLUnit可以自动生成用于测试的框架,填写完成要测试的数据后用来验证代码的正确性。这个工具我觉得挺有用的,尤其是在改变代码后仍可以用来测试新的代码的正确性。具体内容见2.2。
2. JMLUnitNG与JMLUnit
2.1 JMLUnitNG
由于这个工具用于复杂的表达式会出现一些问题,所以我用了一段简单的代码进行验证:
1 // demo/Demo.java
2 package demo;
3
4 public class Demo {
5 /*@ public normal_behaviour
6 @ ensures \result == lhs + rhs;
7 */
8 public static int add(int lhs, int rhs) {
9 return lhs + rhs;
10 }
11
12 /*@ public normal_behaviour
13 @ ensures \result == lhs - rhs;
14 */
15 public static int compare(int lhs, int rhs) {
16 return lhs - rhs;
17 }
18
19 public static void main(String[] args) {
20 add(-114514,1919810);
21 compare(114514,1919810);
22 }
23 }
使用jmlunitng工具生成用于测试的.java文件,然后编译成.class文件,最后运行,结果如下图:
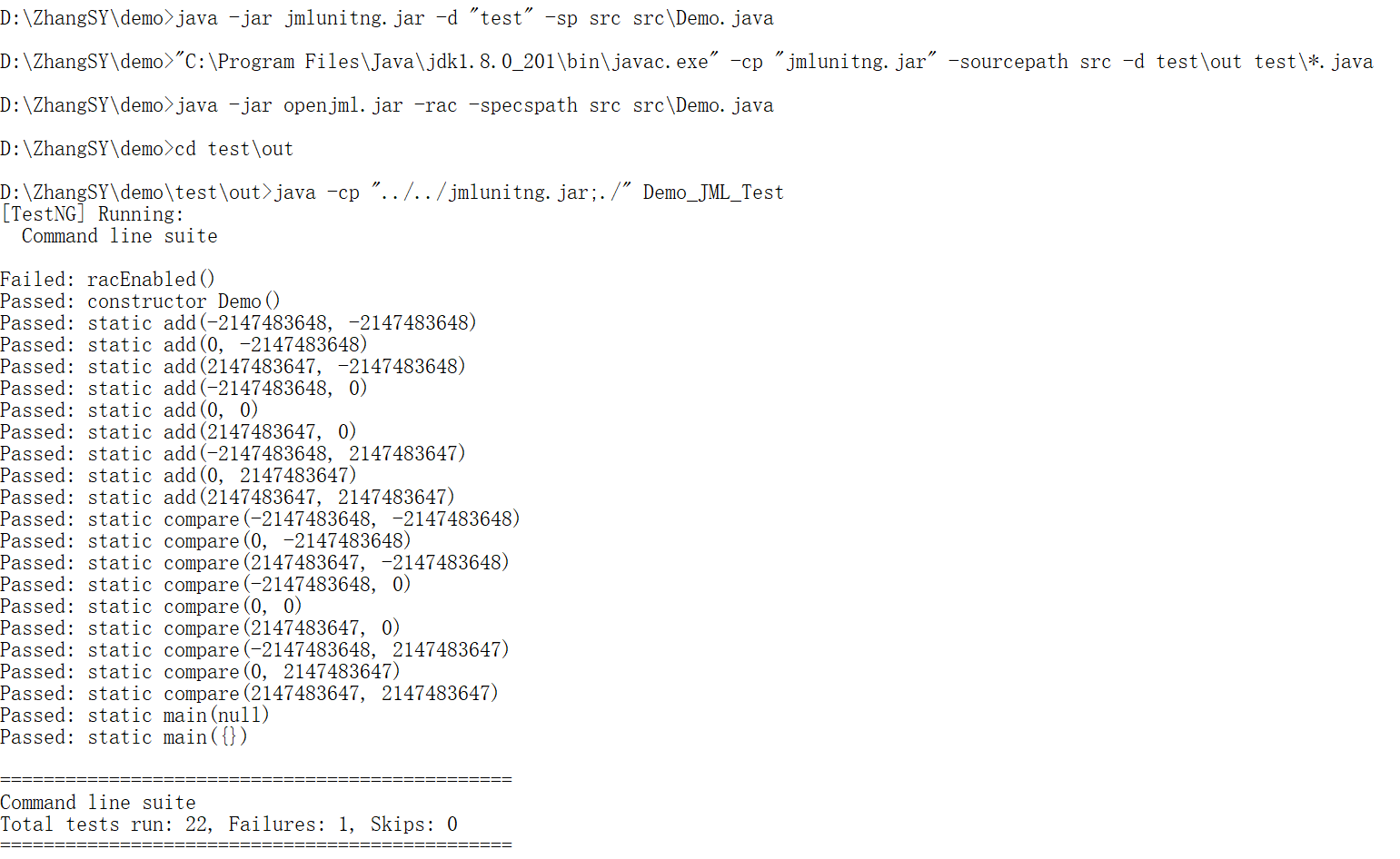
2.1 JMLUnitNG
JMLUnitNG可以自动生成测试框架,比如要测试MyGraph类的一些方法,选择要测试的方法后生成测试文件如下:
1 import org.junit.After;
2 import org.junit.Before;
3 import org.junit.Test;
4
5 import static org.junit.Assert.*;
6
7 public class MyGraphTest {
8
9 @Before
10 public void setUp() throws Exception {
11 }
12
13 @After
14 public void tearDown() throws Exception {
15 }
16
17 @Test
18 public void getPathById() {
19 }
20
21 @Test
22 public void getPathId() {
23 }
24}
补充完测试代码如下:
1 import com.oocourse.specs2.models.PathIdNotFoundException;
2 import com.oocourse.specs2.models.PathNotFoundException;
3 import org.junit.After;
4 import org.junit.Assert;
5 import org.junit.Before;
6 import org.junit.Test;
7
8 import static org.junit.Assert.*;
9
10 public class MyGraphTest {
11 MyGraph graph;
12 MyPath path1, path2, path3;
13
14 @Before
15 public void setUp() throws Exception {
16 graph = new MyGraph();
17 path1 = new MyPath(1, 2, 3, 4);
18 path2 = new MyPath(1, 2, 3, 4);
19 path3 = new MyPath(1, 2, 3, 4, 5);
20 graph.addPath(path1);
21 graph.addPath(path2);
22 graph.addPath(path3);
23 }
24
25 @After
26 public void tearDown() throws Exception {
27 System.out.println("after");
28 }
29
30 @Test
31 public void getPathById() throws PathIdNotFoundException {
32 Assert.assertEquals(graph.getPathById(1),path1);
33 Assert.assertEquals(graph.getPathById(1),path2);
34 Assert.assertEquals(graph.getPathById(2),path3);
35
36 }
37
38 @Test
39 public void getPathId() throws PathNotFoundException {
40 Assert.assertEquals(3,graph.getPathId(path1));
41 Assert.assertEquals(3,graph.getPathId(path2));
42 Assert.assertEquals(4,graph.getPathId(path3));
43 }
44 }
运行结果:
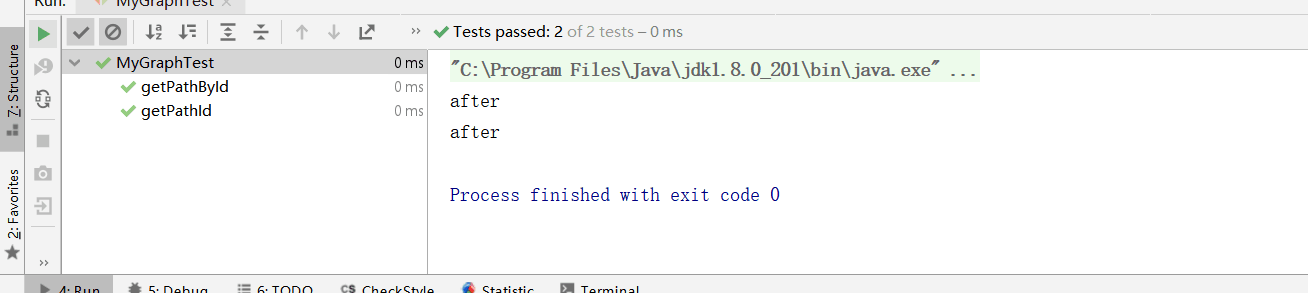
可以给出对每一个方法的测试结果是否完全正确。
3. 架构设计与分析
3.1第九次作业
第九次作业的类图如下:
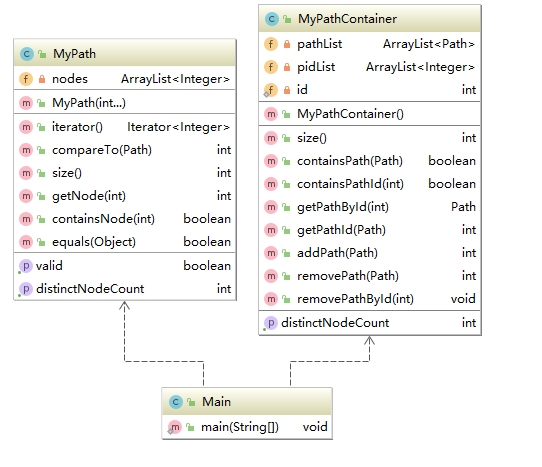
第九次作业只需要实现两个接口的类:MyPath和它对应的容器MyPathContainer即可。路径对象使用一个ArrayList对象存储对应的节点,而路径的容器是用两个ArrayList存储,一个用于存储路径,一个用于存储路径的id。这次作业中不像后两次作业需要复杂的计算,只是需要实现对路径进行增删和计算节点个数等简单的指令,因此两个类都只用较少的成员变量存储信息(MyPath类只有一个成员变量,MyPathContainer只有三个成员变量)。但由于没有考虑时间复杂度,导致我在强侧中有5个点超时了。具体原因是在DISTINCT_NODE_COUNT指令计算所有路径的不同节点个数时,采用了如下:
1 public /*@pure@*/int getDistinctNodeCount() {
2 ArrayList<Integer> arr = new ArrayList<>();
3 for (int i = 0; i < pathList.size(); i++) {
4 Iterator ite = pathList.get(i).iterator();
5 while (ite.hasNext()) {
6 Integer node = (Integer) ite.next();
7 if (!arr.contains(node)) {
8 arr.add(node);
9 }
10 }
11 }
12 return arr.size();
13 }
14
暴力双重循环的方法每次都计算一遍,而把计算出来的结果返回后就丢掉了。这也使我意识到了缓存的重要性,它在这种增删指令较少,查询指令较多的需求下能够对整体运行速度起到很大的作用,因此我在后两次作业认证思考了哪些结果需要保存下来以减少后续的计算。
3.2第十次作业
第十次作业的类图如下:
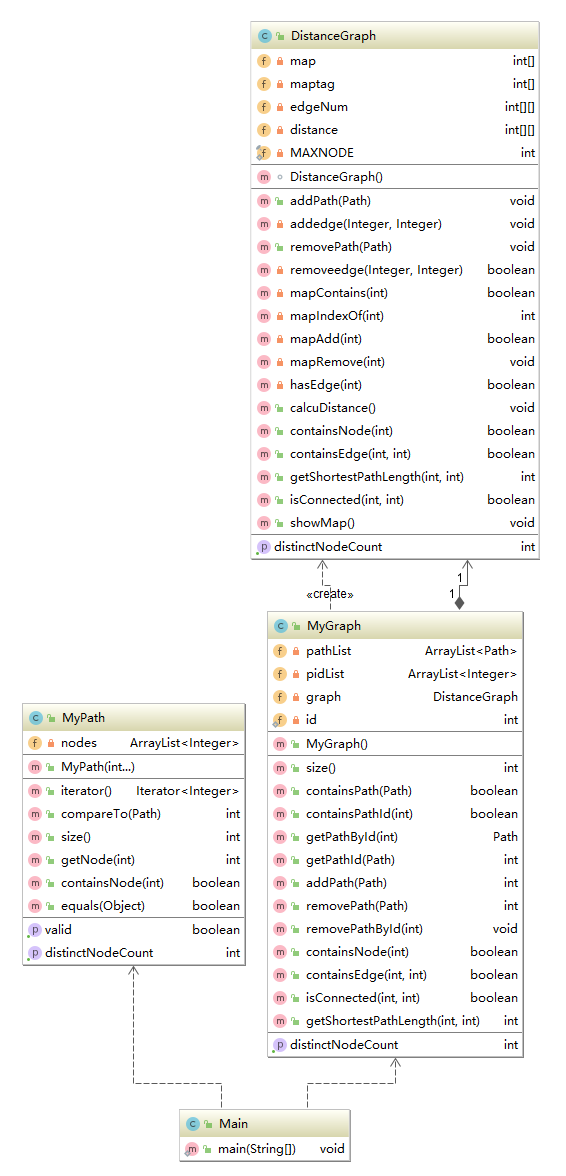
第十次作业把上次作业的路径当做无向图的边并新增了容器中是否存在某一条边、两个结点是否连通、两个结点之间的最短路径三条指令。我按照指导书的建议把无向图单独建立一个类,所以此次的架构较上次相比增加了一个类DistanceGraph。MyPath和MyGraph更上次基本相同。MyPath类吸取了上次作业教训,在构造函数时就计算好该路径的不同节点个数,需要查询时之间返回即可。MyGraph类新增了三条指令对应的方法,并在之前的方法内加上对DistanceGraph类实例化对象的操作。DistanceGraph类采用了邻接表存储无向图,因为节点的id是任意的,所以需要节点id向0-MAXNODE的映射,并有一个标志记录映射的有效性,这是通过两个数组完成的。因为有了上次超时的惨痛经历,我在这次作业中能采用数组的尽量采用数组来保证存取的效率。看完课程组发的第十一作业的架构后觉得我这样做虽然提高了效率,但弱化面向对象语言对象在其中的地位(比如官方参考架构的边和节点都有单独的类,而我边和节点都是直接用数组保存在了DistanceGraph类里,从架构上讲显然是前者更符合面向对象语言的特点,但后者更有利于运行效率,需要我权衡一下在这两方面的取舍)。对于运算的缓存,有一种做法是如果需要计算两个节点的最短距离已经缓存下来就直接返回结果,否则进行计算并缓存计算的结果。而我采用的是另一种做法,每当有增删边的指令执行后(图结构改变)就用Dijkstra算法计算任意两点的最短距离并保存。考虑到图结构变更指令总数不超过20条并且Dijkstra算法是直接用二维数组进行计算(如果采用前者策略,则应当用Floyd算法,这就需要一个容器保存已经计算过的节点),这两种策略效率应该不会差很多,在内存的占用上,后者会更少(因为前者还需要记录哪些数据缓存了)。
3.3第十一次作业
第十一作业类图如下:
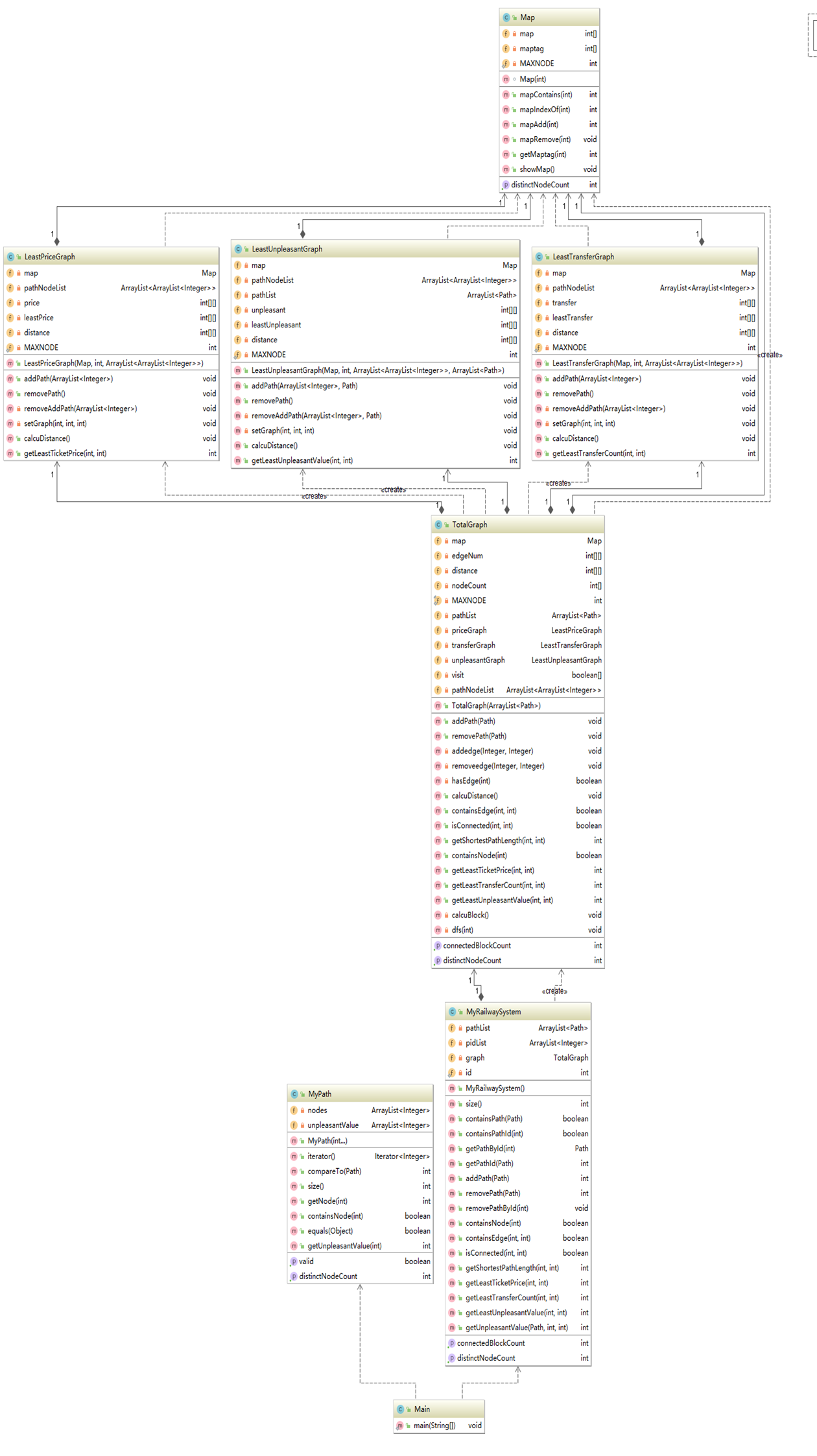
可以看出第十一次作业比上次作业多了许多类,Total类对多种图进行统一管理,LeastPriceGraph、LeastTransferGraph、LeastUnpleasantGraph三个类对应了三种类型的图,除了对图内边的权值赋值不同外,其余的都大同小异,和上次作业的DistanceGraph类相似。为了使架构更符合单一职责原则,我把在上次作业中的DistanceGraph类内的节点id和邻接表下标的对应关系及提供的相应方法分离成了一个Map类。总的来说,此次作业的内容较上次相比只是增加了几张图,实现并无太大难度。架构方面虽然不如官方参考架构那样细化地分成许多类,但我个人觉得这样的架构已经很好的满足了java的设计原则。
4. bug及修复
这三次作业中,除了第九次作业的强测外都是满分。而第九次作业出现的问题如3.1所说,没有考虑时间复杂度把计算出的结果缓存下来而导致超时。JML虽然能够保证我们符合JML规格的代码能够正确执行,但在运行的效率方面还需要编程者自己思考,这也给了我一个警告:对于编写代码,正确性固然重要,但效率也是必须要考虑的方面,毕竟我们不是纸上谈兵,我们写的代码最终是要用于实际用途的,而实际要求着我们的代码应该有尽可能高的效率。
5.规格的心得体会
撰写规格的目的类似于撰写说明文档,都是为了阐述了一个类或方法的行为,使得调用者不需要看内部的代码实现就能够正确调用方法并知道其会产生的结果和副作用。但说明文档更偏向于人类的语言,没有统一的要求,可能会出现歧义。而规格更偏向于机器的语言,有固定的文法要求,不会产生歧义,使得不同人对规格的理解是一样的。规格中对于全程量词和存在量词的应用很像数学分析课程中的各种定义,因而精确地描述了一个方法的行为。
对于规格的撰写,分为类的规格和方法的规格。对于方法的规格,要区分正常行为规格和异常行为规格,两者都要明确其前置条件(输入的范围)和副作用(改变哪些对象)。对于异常行为规格,要写出在此前置条件下抛出的异常;对于正常行为规格,要写出其后置条件,撰写后置条件时要做到的是条件充分必要。对于类的规格,则需撰写不变式限制和约束条件限制,这两个限制在明确类的方法执行后会对对象产生怎样的影响后都是易于撰写的。
对于规格的理解,主要是对规格后置条件的理解,其他方面都较易于理解。要理解后置条件,我的做法是先找到\result关键词,确认返回值和什么有关,然后在找到\result关键词所在等式中其他内容相关的东西,以一种树的结构理解返回值满足的充要条件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号