

个人项目-第一次编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 作业目标 | 实现一个论文查重程序 |
| github链接 | https://github.com/ZnZn-cat/3223003267 |
一.PSP表格
| 进程 | 预估耗时(分钟) | 实际耗时(分钟) |
| 计划 | 30 | 25 |
| ·估计这个任务需要多少时间 | 30 | 25 |
| 开发 | 210 | 200 |
| ·需求分析 | 60 | 50 |
| ·生成设计文档 | 20 | 10 |
| ·设计复审 | 30 | 25 |
| ·代码规范 | 10 | 5 |
| ·具体设计 | 30 | 25 |
| ·具体编码 | 120 | 100 |
| ·代码复审 | 30 | 25 |
| ·测试(自我测试,修改代码,提交修改) | 60 | 50 |
| 报告 | 90 | 80 |
| ·测试报告 | 30 | 25 |
| ·计算工作量 | 30 | 25 |
| ·事后总结 | 30 | 30 |
| 合计 | 330 | 285 |
二、计算模块接口的设计与实现过程
程序整体框架
1. 模块架构
论文查重系统
├── 核心算法模块
│ ├── LCS动态规划算法
│ ├── 空间优化计算功能
│ └── 相似度计算功能
├── 文件处理模块
│ ├── 二进制文件读取功能
│ ├── 文件大小动态检测功能
│ └── 内存精确分配功能
├── 编码处理模块
│ ├── UTF-8多字节转换功能
│ ├── 宽字符字符串处理功能
│ └── 编码验证与错误处理功能
├── 异常处理模块
│ ├── 命令行参数验证
│ ├── 文件操作异常处理
│ ├── 内存分配异常处理
│ └── 编码转换异常处理
└── 资源管理模块
├── 动态内存分配管理
├── 文件句柄生命周期管理
└── 资源释放安全保障
2. 函数结构
(1)LCS计算函数
lcs_length函数使用动态规划算法计算两个宽字符串的最长公共子序列长度。该函数采用空间优化策略,通过一维数组替代传统的二维数组,将空间复杂度从O(m×n)降低到O(n)。函数接收两个宽字符串及其长度作为参数,返回它们的最长公共子序列长度。
(2)文件处理函数
程序通过标准的C文件操作函数实现文件读取功能。采用二进制模式打开文件,先获取文件大小再分配精确的内存空间,确保文件内容完整加载。包含完整的错误处理机制,对文件不存在、读取失败等情况进行检测和处理。
(3)字符串转换函数
使用mbstowcs函数将多字节字符串转换为宽字符串,支持UTF-8编码的中文文本处理。转换过程分为两步:首先计算所需缓冲区大小,然后进行实际转换,确保内存分配的精确性。
(4)主控制函数
main函数负责程序的整体流程控制,包括命令行参数验证、资源管理、模块协调和错误处理。它按照顺序调用各个功能模块,并确保在程序结束时正确释放所有分配的内存资源。
3. 程序流程图
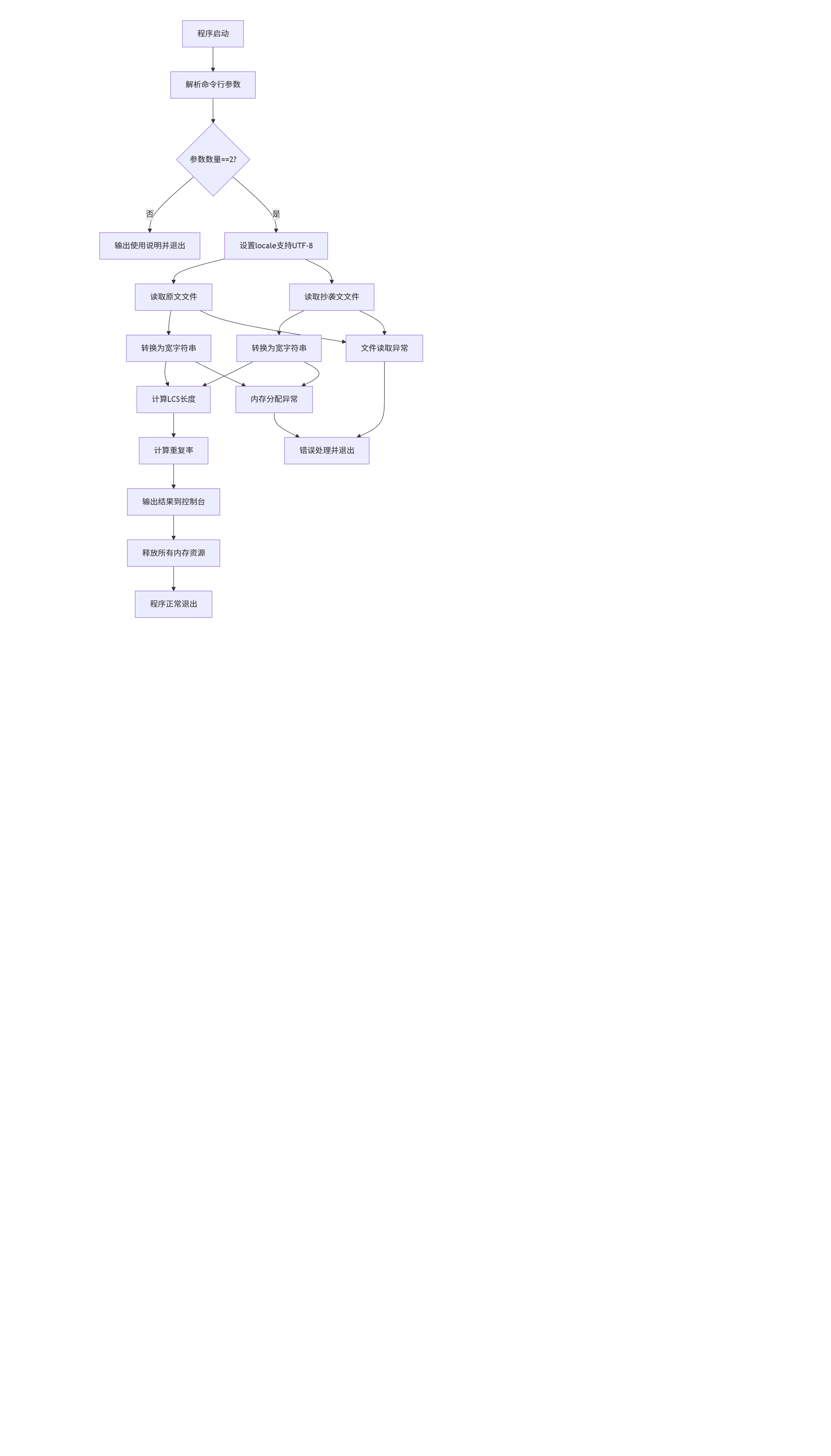
4.算法独到之处
(1)基于LCS的精确字符级匹配算法
该查重系统采用最长公共子序列算法进行文本相似度计算,能够识别调换顺序的抄袭内容。与基于词语的余弦相似度算法相比,LCS算法进行字符级比对,对代码、公式等结构严谨的文本具有更好的检测效果。算法不要求连续匹配,能有效抵抗插入、删除、修改等抄袭手段的干扰。
(2)完整的宽字符国际化支持
程序使用wchar_t类型处理Unicode字符,通过mbstowcs函数实现UTF-8编码到宽字符的转换,完整支持中文等多语言文本处理。在内存管理方面,程序精确计算所需缓冲区大小,避免内存浪费,并建立了统一的资源释放机制,防止内存泄漏。
(3)空间优化的动态规划实现
传统的LCS算法需要O(m×n)的空间复杂度,而本实现通过使用一维数组和临时变量保存中间结果,将空间复杂度优化到O(n)。这种优化使算法能够处理更长的文本,同时减少内存占用,提高程序运行效率。
(4)完善的异常处理体系
程序包含多层错误检测机制,涵盖命令行参数验证、文件操作检查、内存分配验证和字符串转换错误处理。在资源管理方面,确保所有动态分配的内存都有对应的释放操作,文件句柄及时关闭,错误发生时能正确清理已分配的资源。
(5)平衡性能与准确性的设计
算法采用流式读取方式处理文件,避免一次性加载过大文件导致内存压力。空间优化的LCS算法支持较长文本的查重需求,同时保持对细微抄袭模式的高灵敏度。输出设计注重实用性,提供重复率、原文长度和LCS长度等详细信息,方便用户理解和验证查重结果。
三、计算模块部分单元测试展示
-
单元测试代码展示
`size_t orig_wide_len = mbstowcs(NULL, orig_text, 0);
size_t plag_wide_len = mbstowcs(NULL, plag_text, 0);
if (orig_wide_len == (size_t)-1 || plag_wide_len == (size_t)-1) {
perror("mbstowcs failed");
free(orig_text);
free(plag_text);
return 1;
}
wchar_t *orig_wide = (wchar_t *)malloc((orig_wide_len + 1) * sizeof(wchar_t));
wchar_t *plag_wide = (wchar_t *)malloc((plag_wide_len + 1) * sizeof(wchar_t));
if (orig_wide == NULL || plag_wide == NULL) {
perror("malloc wide string");
free(orig_text);
free(plag_text);
if (orig_wide) free(orig_wide);
if (plag_wide) free(plag_wide);
return 1;
}
mbstowcs(orig_wide, orig_text, orig_wide_len + 1);
mbstowcs(plag_wide, plag_text, plag_wide_len + 1);
size_t lcs_len = lcs_length(orig_wide, plag_wide, orig_wide_len, plag_wide_len);double rate;
if (orig_wide_len == 0) {
rate = 0.0;
} else {
rate = (double)lcs_len / orig_wide_len;
}printf("查重率: %.2f\n", rate);
printf("原文长度: %zu 字符\n", orig_wide_len);
printf("最长公共子序列长度: %zu 字符\n", lcs_len);
` -
测试数据构造思路
(1)基础功能测试数据
构造经典的LCS算法测试用例,使用英文字符串验证算法的正确性。选择已知LCS结果的字符串对,确保算法实现符合预期。
(2)边界条件测试数据
测试空字符串和极端情况下的算法行为。验证程序在输入为空或长度为0时的处理能力,防止边界情况导致的程序崩溃。
(3)中文文本测试数据
使用中文字符串测试宽字符处理功能。验证算法对Unicode字符的支持程度,特别是中文字符的正确匹配和长度计算。
(4)完全不同的文本测试
构造毫无相似性的文本对,测试算法在零匹配情况下的表现。验证重复率计算在无公共子序列时的正确性。
(5)相同内容测试数据
使用完全相同的文本测试100%匹配情况。验证算法在理想匹配场景下的准确性,确保重复率计算正确。
四. 异常处理机制
(1)命令行参数异常处理:程序启动时首先检查argc的值,确保用户提供了正确数量的命令行参数。如果参数数量不符合要求,立即输出使用说明并退出,避免后续操作因参数缺失而失败。虽然当前实现没有深入检查参数格式,但可以扩展验证文件路径的合法性。比如检查文件扩展名、路径是否存在等,提高程序的健壮性。
if (argc != 3) { // 现在只需要两个参数 printf("Usage: %s original_file plagiarized_file\n", argv[0]); printf("Example: %s orig.txt plagiarized.txt\n", argv[0]); return 1; }
(2)文件操作异常处理:使用fopen函数后立即检查返回值,确保文件成功打开。如果打开失败,通过perror输出具体错误信息,帮助用户快速定位问题。通过比较fread返回值与文件大小,确认文件内容被完整读取。防止因磁盘错误或权限问题导致的数据读取不完整。
FILE *orig_file = fopen(orig_path, "rb"); if (orig_file == NULL) { perror("Failed to open original file"); return 1; } size_t read_size = fread(orig_text, 1, orig_size, orig_file); orig_text[read_size] = '\0';
(3)内存管理异常处理:每次调用malloc后立即检查返回的指针是否为NULL。内存分配失败时及时释放已分配的资源,避免内存泄漏。确保所有动态分配的内存都有对应的free操作。即使在错误处理路径中,也按照分配顺序的逆序释放资源,保证程序退出前的资源清理。
char *orig_text = (char *)malloc(orig_size + 1); if (orig_text == NULL) { perror("malloc"); fclose(orig_file); return 1; } wchar_t *orig_wide = (wchar_t *)malloc((orig_wide_len + 1) * sizeof(wchar_t)); wchar_t *plag_wide = (wchar_t *)malloc((plag_wide_len + 1) * sizeof(wchar_t)); if (orig_wide == NULL || plag_wide == NULL) { perror("malloc wide string"); free(orig_text); free(plag_text); if (orig_wide) free(orig_wide); if (plag_wide) free(plag_wide); return 1; }
(4)字符串转换异常处理:mbstowcs函数调用后检查返回值,确保多字节到宽字符的转换成功。处理编码不匹配或无效字符序列导致的转换失败。在分配宽字符缓冲区前,先通过mbstowcs(NULL, ...)计算所需大小,避免缓冲区溢出或不足。
size_t orig_wide_len = mbstowcs(NULL, orig_text, 0); size_t plag_wide_len = mbstowcs(NULL, plag_text, 0); if (orig_wide_len == (size_t)-1 || plag_wide_len == (size_t)-1) { perror("mbstowcs failed"); free(orig_text); free(plag_text); return 1; }
(5)算法计算异常处理:在计算重复率时,检查分母(原文长度)是否为零。避免因空文本导致的除零错误,确保数学计算的稳定性。确保LCS长度不超过原文长度,防止算法实现错误导致的数值异常。验证计算结果的合理性范围。
double rate; if (orig_wide_len == 0) { rate = 0.0; } else { rate = (double)lcs_len / orig_wide_len; }
五、总结
·主要特性
- 基于LCS的精确字符级查重
系统采用最长公共子序列算法,实现字符级别的精确比对,能够有效识别调换顺序、插入删除等复杂抄袭手法。相比基于词语的查重方法,本系统对代码、公式等结构化文本具有更好的检测效果。 - 完整的UTF-8国际化支持
通过宽字符处理机制,系统全面支持中文等多语言文本查重。使用标准的mbstowcs函数实现编码转换,确保不同编码格式的文件都能正确读取和处理,满足国际化需求。 - 空间优化的动态规划算法
创新性地使用一维数组替代传统二维数组,将LCS算法的空间复杂度从O(m×n)优化到O(n),大幅减少内存占用。这种优化使系统能够处理更长的文本,同时保持较高的运行效率。 - 多层次异常处理保障机制
建立从命令行参数验证到资源清理的完整异常处理链条。包含文件操作、内存分配、编码转换等多方面的错误检测,确保程序在各类异常情况下都能安全退出,避免资源泄漏。 - 详细的查重报告输出
除基本的重复率外,系统还提供原文长度、LCS长度等详细信息,方便用户全面了解查重结果。输出格式清晰规范,支持控制台直接查看,便于集成到自动化流程中。
·系统优点 - 算法精准度高
LCS算法在字符级比对方面具有天然优势,特别适合检测精确抄袭和局部修改。对学术论文、程序代码等需要精确比对的场景效果显著。 - 内存使用效率优秀
通过空间优化算法,系统在保持计算准确性的同时,大幅降低了内存需求。这使得系统能够在资源受限的环境中稳定运行,处理较大规模的文本数据。 - 代码结构清晰简洁
采用函数式编程风格,各功能模块职责分明,代码可读性强。核心算法封装良好,便于后续维护和功能扩展。 - 跨平台兼容性好
基于标准C库开发,不依赖特定平台API,具有良好的跨平台特性。可以在Windows、Linux、macOS等主流操作系统上编译运行。 - 运行稳定性强
完善的错误处理机制确保了系统在各种异常情况下的稳定运行。从文件不存在到内存分配失败,系统都能给出明确的错误提示并安全退出。 - 处理速度快
优化后的LCS算法在保持准确性的同时具有较好的时间复杂度,能够快速完成文本比对任务,满足实际应用中的性能要求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号