从原型到生产:揭秘大-模型应用的工业化之路 (LLMOps)
摘要: 您的AI应用还停留在“Jupyter Notebook作坊”阶段吗?当生成式AI从惊艳的原型走向严肃的生产环境,一套全新的工程化思想——LLMOps——应运而生。本文将以“启智未来”的实践为例,系统性地拆解LLMOps的四大核心阶段,从构思、开发到部署、评估,向您展示如何将AI应用从“艺术品”打造成可靠、可控、可迭代的“工业品”。
标签: LLMOps, MLOps, Prompt Flow, Azure AI Studio, 生成式AI, DevOps, 应用生命周期

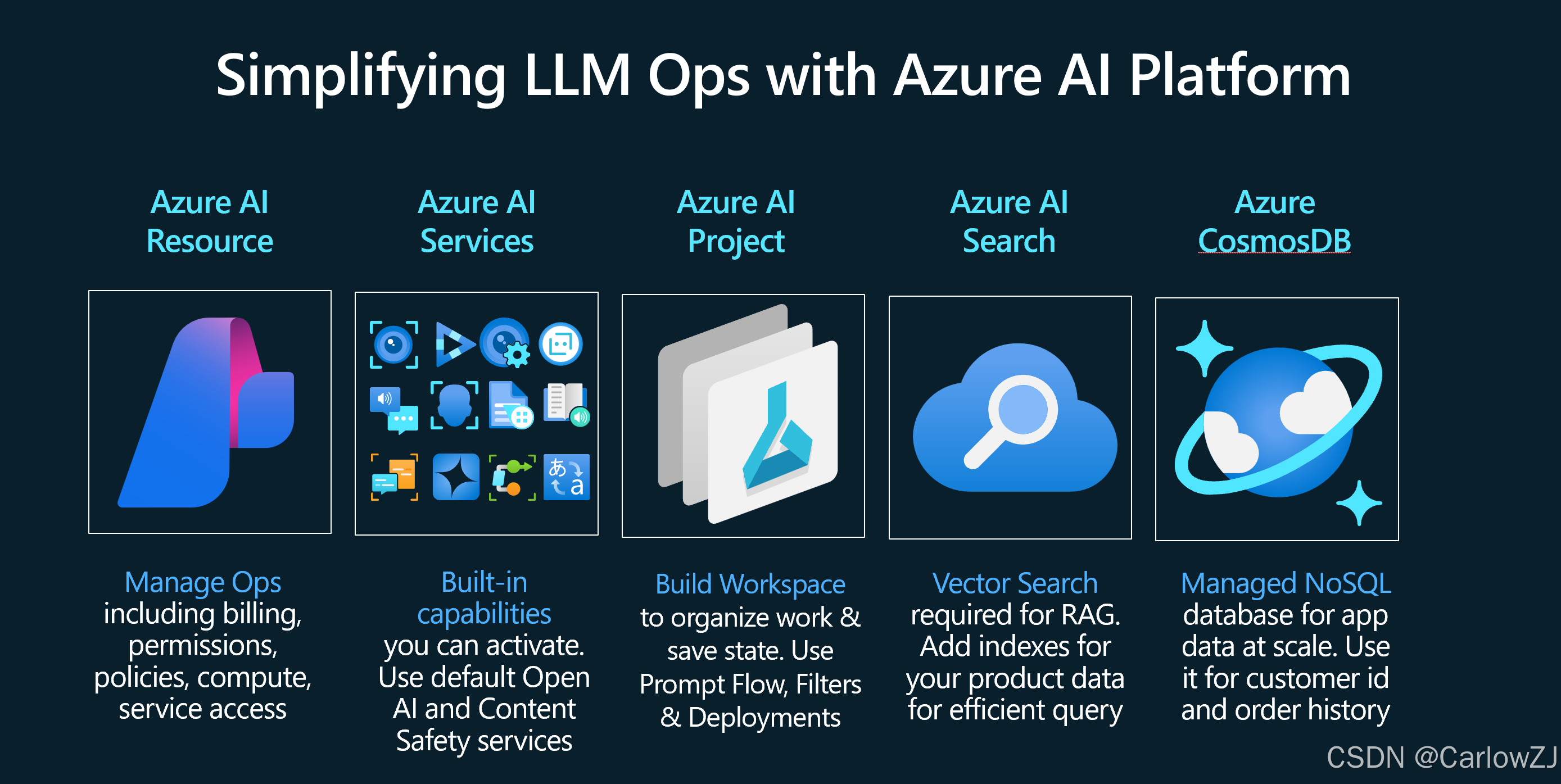
引言:“成长的烦恼”
在“启智未来”,我们经历了一段令人兴奋的“AI原型爆发期”。聊天机器人、搜索引擎、艺术品生成器……一个个充满创意的应用在我们的Jupyter Notebook中诞生。但当我们试图将这些原型投入实际生产时,混乱随之而来:
- 部署靠手动: 每个应用的部署方式都不一样,耗时耗力,还频繁出错。
- Prompt 靠“炼丹”: 优秀的Prompt散落在各个开发者的电脑里,无法管理、复用和迭代。
- 线上问题靠“猜”: 应用上线后,成本、延迟、回复质量全凭感觉,缺乏量化指标,优化无从下手。
- 迭代像“开盲盒”: 对Prompt或模型的任何微小改动,都可能引发线上性能的巨大波动。
我们意识到,我们正处于从AI作坊到AI工厂的转型阵痛中。我们需要一套标准化的、可重复的、自动化的流程来管理AI应用的整个生命周期。这,就是 LLMOps (Large Language Model Operations)。
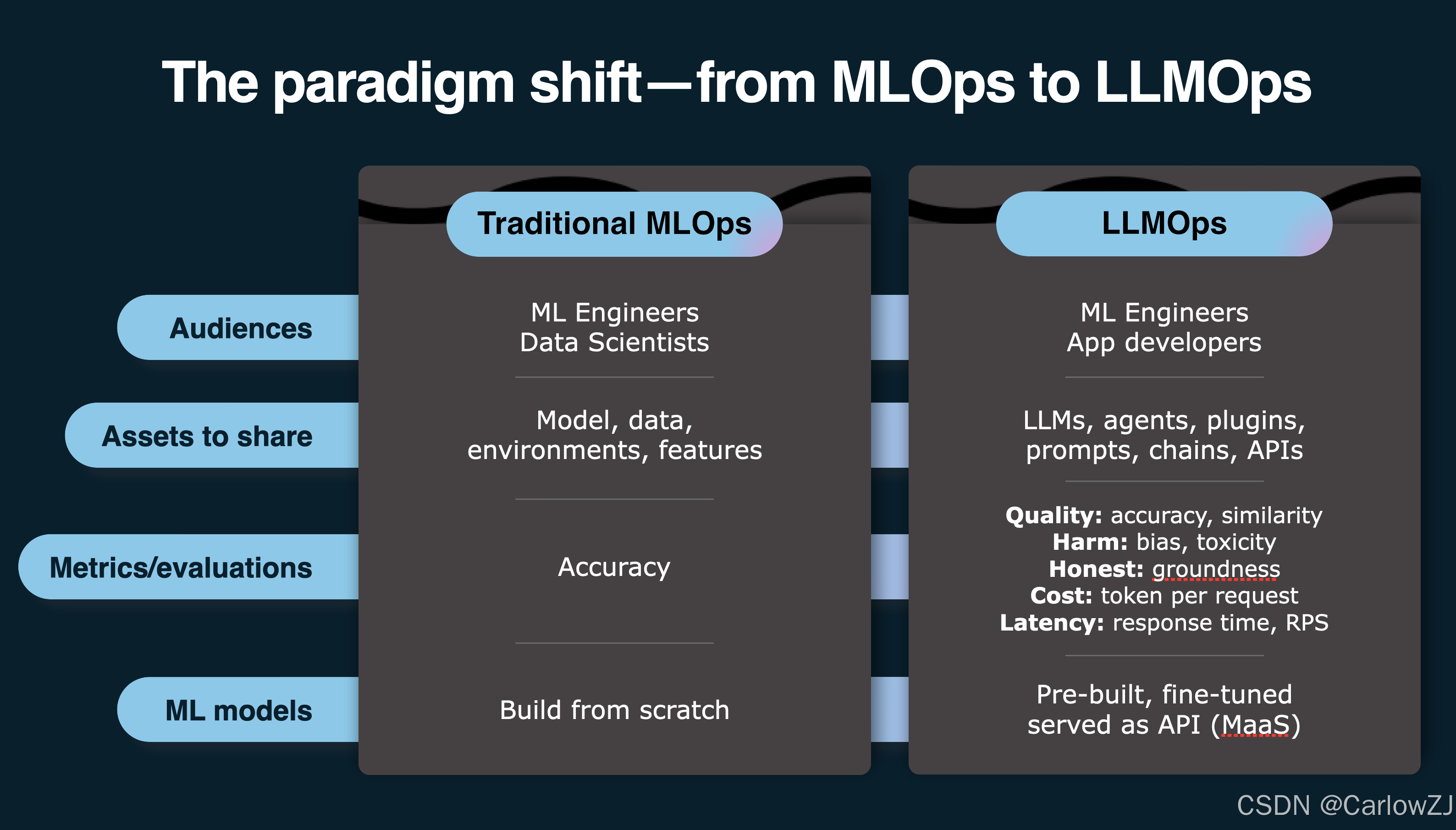
Part 1: 一场深刻的范式革命:从 MLOps 到 LLMOps
在引入LLMOps之前,我们团队熟悉的是传统的MLOps (Machine Learning Operations)。但我们很快发现,直接套用MLOps经验是行不通的。因为生成式AI的核心变了。
Mermaid 思维导图:MLOps vs. LLMOps 核心差异
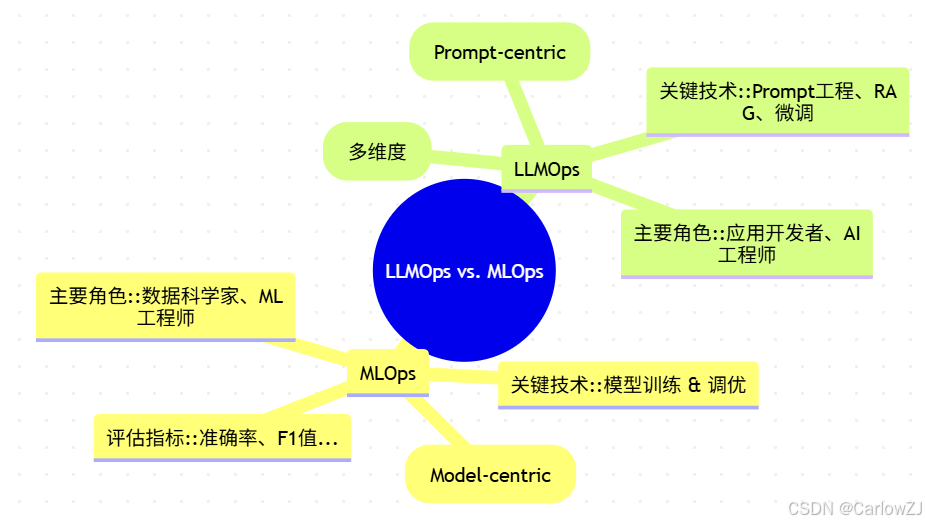
| 对比维度 | MLOps (传统机器学习) | LLMOps (大模型应用) |
|---|---|---|
| 核心资产 | 模型 (Model) | 提示 (Prompt) / 应用流 (Flow) |
| 开发重心 | 数据预处理、特征工程、模型训练 | Prompt工程、检索增强(RAG)、数据整合 |
| 迭代方式 | 重新训练模型 (成本高、周期长) | 优化Prompt、更新数据源 (成本低、周期短) |
| 模型来源 | 自主训练为主 | 以API形式调用基础模型 (MaaS) 为主 |
| 评估重点 | 预测的准确性 | 回复的综合质量、成本、延迟、安全性 |
简单来说,MLOps的核心是炼模型,而LLMOps的核心是编排和管理调用模型的应用流。这个转变,要求我们重塑整个开发、部署和运维的流程。
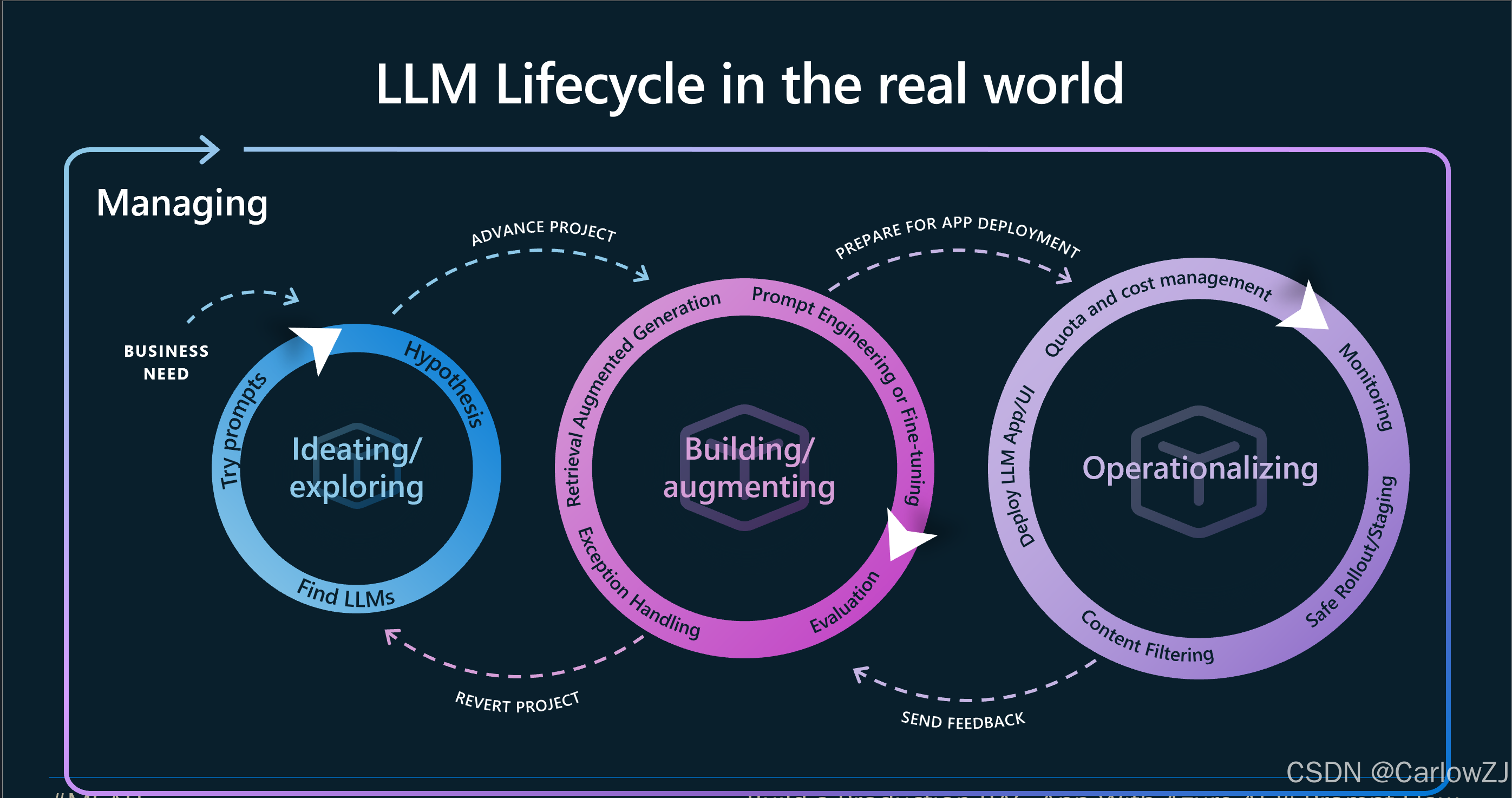
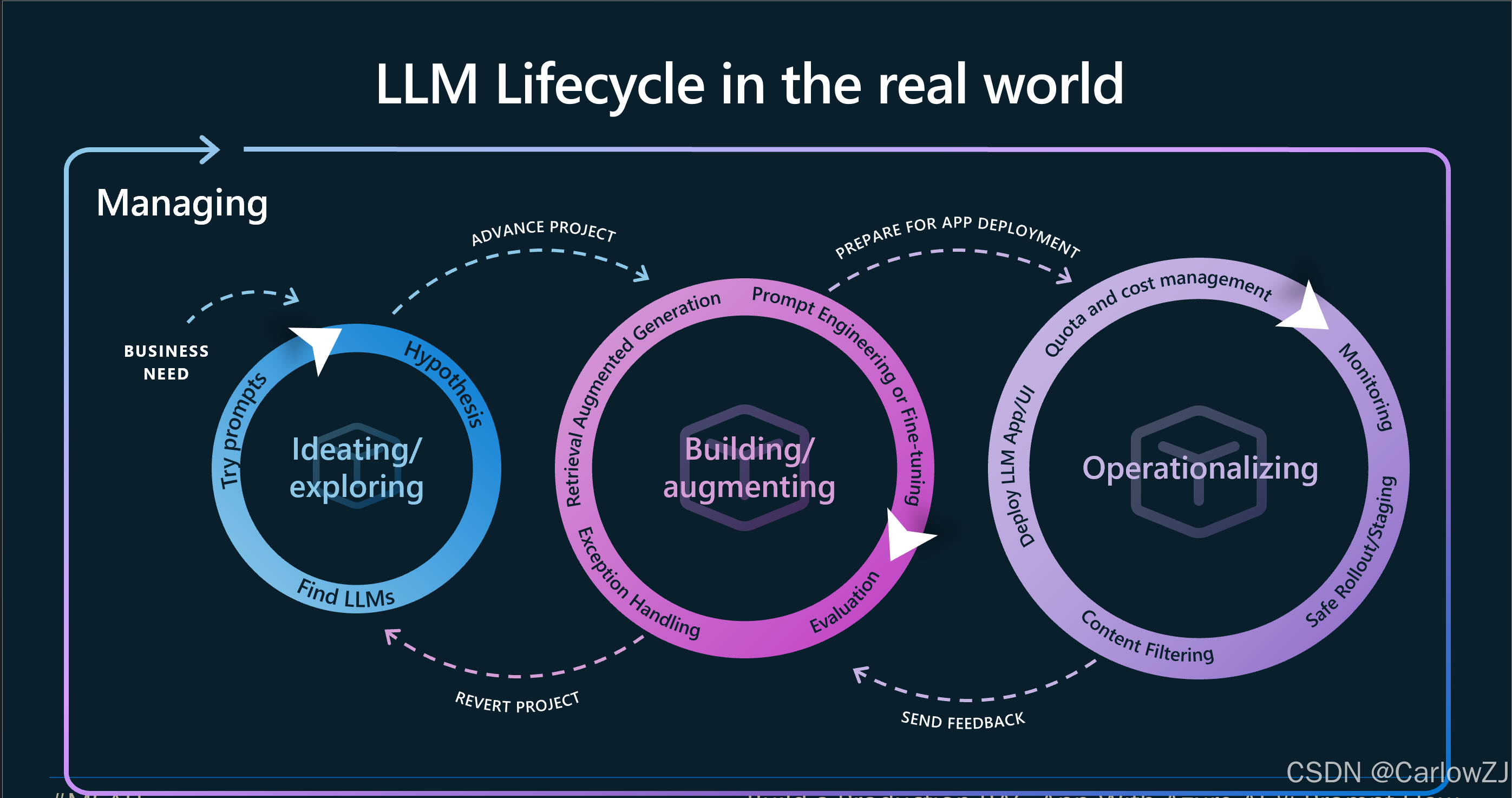
Part 2: AI 应用的工业化流水线:LLMOps 四阶生命周期
结合业界最佳实践和我们自身的探索,我们为“启智未来”定义了LLMOps的四阶生命周期。这是一个持续迭代的闭环,而非线性的瀑布流。
Mermaid 流程图:LLMOps 完整生命周期
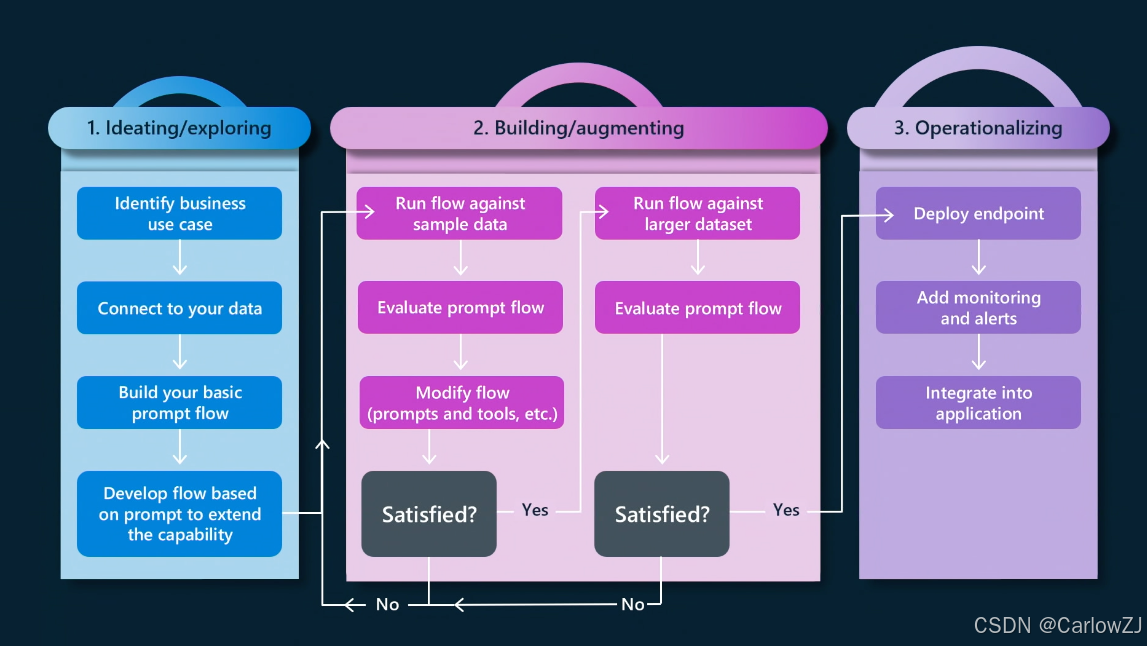
第一阶段:探索与构思 (Ideation & Exploration)
这是创意的源头,目标是快速验证一个想法是否可行。
-
活动:
- 商业假设: 提出一个希望用AI解决的业务问题。例如:“我们能否构建一个能回答新员工入职问题的聊天机器人?”
- 快速原型: 在 Azure AI Studio 或 Jupyter Notebook 中,通过 Prompt Engineering,快速实验不同的基础模型、提示和少量示例数据,观察效果。
- 可行性评估: 判断AI的初步表现是否能满足基本需求。
-
产出: 一个验证了基本可行性的 Prompt 或简短脚本。
第二阶段:开发与增强 (Development & Augmentation)
当原型被验证后,我们需要将其从“玩具”变成一个健壮、可靠的“产品”。
-
活动:
- 构建可执行流 (Flow): 使用 Prompt Flow 这样的工具,将原型中的探索性代码,转化为一个结构化的、可视化的执行流。这个“流”可以包含多个节点,如获取用户输入、从向量数据库检索数据(RAG)、调用LLM、格式化输出等。
- 版本控制: 将 Prompt、配置文件 (
flow.dag.yaml)、评估代码等所有资产纳入 Git 进行版本管理。 - 数据增强: 连接真实的、更大规模的数据源(如内部知识库的向量索引)。
- 技术增强: 根据需要,加入微调(Fine-tuning)或更复杂的RAG策略。
-
产出: 一个版本化的、可在本地和云端复现的、完整的 Prompt Flow。
伪代码示例:flow.dag.yaml 的核心结构
# 这是一个简化的 flow.dag.yaml 示例,展示了RAG流程的定义
inputs:
question:
type: string
default: "什么是LLMOps?"
outputs:
answer:
type: string
reference: ${llm_call.output}
nodes:
- name: embed_question
type: python
source: embed.py
inputs:
text: ${inputs.question}
- name: retrieve_docs
type: python
source: retrieve.py
inputs:
embedding: ${embed_question.output}
- name: llm_call
type: llm
connection: my_azure_openai_connection
inputs:
prompt: "根据以下背景知识:{{retrieve_docs.output}},请回答问题:{{inputs.question}}"
# ... 其他LLM参数
第三阶段:操作与部署 (Operationalization)
让开发好的“流”稳定地运行起来,并能被外部调用。
-
活动:
- 打包与部署: 将 Prompt Flow 打包,并通过一行命令或在 Azure AI Studio 点击几下,将其部署为一个可扩展的、受监控的在线API端点 (Online Endpoint)。
- CI/CD 集成: 将部署过程集成到现有的 CI/CD (持续集成/持续部署) 流水线中。例如,当
main分支有更新时,自动触发部署流程。 - 基础设施即代码 (IaC): 使用 Terraform 或 Bicep 来定义和管理部署所需的云资源。
-
产出: 一个受版本控制、可通过 CI/CD 自动更新的生产级 API。
第四阶段:评估与监控 (Evaluation & Monitoring)
这是保证AI应用长期可靠的关键,也是最容易被忽视的环节。
-
活动:
- 批量测试与评估: 在每次部署前,使用一个标准化的“黄金测试集”来对新的“流”版本进行批量评估。
- 定义评估指标: 除了传统的软件监控(CPU、内存),更要关注LLM应用的特有指标:
- 质量: 回复的相关性、流畅度、事实一致性(Groundedness)。
- 安全: 是否存在有害内容或提示注入风险(使用
Azure AI Content Safety)。 - 成本: 每次调用的 Token 消耗和费用。
- 延迟: 从请求到收到完整回复的时间。
- 建立监控仪表盘: 将上述指标可视化,实时监控线上服务的健康状况。
- 反馈闭环: 收集线上应用的真实用户反馈和失败案例,将其反馈到第一阶段(探索与构思),作为下一轮迭代的输入。
-
产出: 一套自动化的评估流水线、一个实时的监控仪表盘、以及一个持续优化的反馈机制。
Part 3: 项目实践的甘特图规划
为了更直观地展示LLMOps流程,我们为“新员工入职问答机器人”项目制定了一个简化的甘特图。
Mermaid 甘特图:AI 应用开发项目计划
结论:LLMOps 是“驯服”AI 的缰绳
引入LLMOps,是“启智未来”从一个创意驱动的团队,走向一个工程驱动的公司的关键一步。它就像为强大的AI野马套上了缰绳,让我们不再畏惧其不确定性,而是能够自信地驾驭它,让它稳定、可靠地为我们的业务创造价值。
对于所有致力于将生成式AI投入生产环境的开发者和团队来说,拥抱LLMOps不再是一个选项,而是通往成功的必由之路。它将决定你的AI应用,最终是昙花一现的“烟火”,还是基业长青的“引擎”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号