树链剖分
树链剖分
基本思想
将树分割成若干条链的形式,使它组合成线性结构,再用其他数据结构来维护树上路径的信息。
用途
-
修改树上两点间路径上所有点的值。
-
查询树上两点间所有节点权值的和、极值或其他信息。
重链剖分
定义
-
重儿子:父亲节点所有儿子中子树最大的子节点。
-
轻儿子:除了重儿子外所有的儿子。
-
重边:从指定节点到其重儿子的边。
-
轻边:从指定节点到其轻儿子的边。
-
重链:多条重边连接而成的路径。
-
轻链:多条轻边连接而成的路径。
-
特别声明,落单的节点也当成一条重链。
看看图(图源oi-wiki):
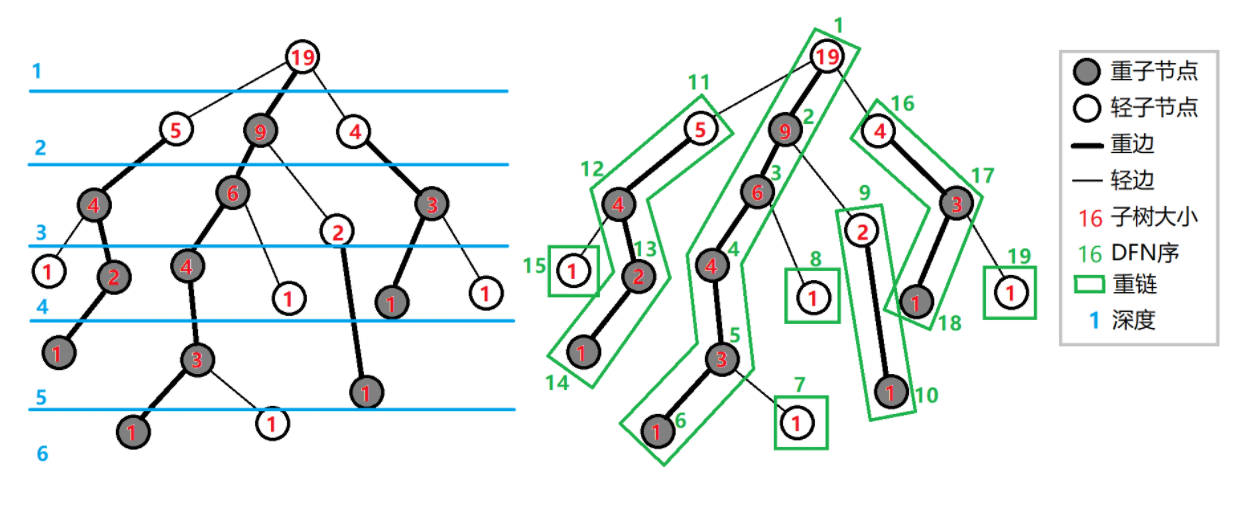
性质
-
树上每个节点属于且仅属于一条重链。也就是说,所有的重链将一棵树完全剖分。
-
第二次深度优先遍历结束后,任意一条重链内的\(dfs\)序是连续的,那么按\(dfs\)序排序后的序列就是剖分后得到的一条链。
-
一颗子树内的\(dfs\)序也是连续的。
-
向下经过一条轻边时,所在子树的大小至少会除以二。那么有:对于树上任意一条路径,把它拆分成从\(lca\)往下走,分别最多走\(O(logn)\)次。树上的每条路径都可以被拆分成不超过\(O(logn)\)条重链。
变量声明
-
\(fa[i]\)表示节点\(i\)的父亲
-
\(dep[i]\)表示节点\(i\)的深度
-
\(sz[i]\)表示节点\(i\)的子树大小
-
\(son[i]\)表示节点\(i\)的重儿子
-
\(top[i]\)表示节点\(i\)所在重链的顶部节点(深度最小的节点)
-
\(dfn[i]\)表示节点\(i\)的\(dfs\)序
-
\(rk[i]\)表示\(dfs\)序所对应的节点编号 (也就是说\(rk[dfn[i]]=i\))
实现
第一次\(dfs\)
可以得到的:\(fa\)数组,\(dep\)数组,\(sz\)数组,\(son\)数组。
inline void dfs1(int u,int f,int depth) {
dep[u]=depth; fa[u]=f; sz[u]=1;
for (ri i=head[u];i;i=e[i].nxt) {
int v=e[i].to; if (v==fa[u]) continue;
dfs1(v,u,depth+1);
sz[u]+=sz[v]; //当前节点子树大小累加它儿子的子树大小。
if (sz[v]>sz[son[u]]) son[u]=v; //若当前儿子子树大小大于目前遍历过的重儿子大小,就更新当前节点的重儿子。
}
}
第二次\(dfs\)
可以得到的:\(top\)数组,\(dfn\)数组,\(rk\)数组。
inline void dfs2(int u,int t) {
top[u]=t; dfn[u]=++dfncnt; rk[dfncnt]=u;
if (!son[u]) return;
dfs2(son[u],t); //优先处理重儿子,以保证一条重链上节点的dfs序是连续的
for (ri i=head[u];i;i=e[i].nxt) {
int v=e[i].to;
if (v==son[u] || v==fa[u]) continue; //只处理轻儿子
dfs2(v,v); //轻儿子的top是自己
}
}
查询两点间路径上所有点权和
类似\(lca\)的思想。当两点不在一条链上时,取所在链顶端节点深度更深的那个点,一次加上从这个点到它所在链顶端节点路径上的点权和,再把它跳到链顶端节点的父亲,也就是另一条链上,再次判断处理。其实就是把两点间的路径拆成几条重链,然后由于重链上\(dfs\)序是连续的,就可以用线段树等数据结构来维护,从而求和。
修改也是一样的。
inline ll QueryPath(int u,int v) {
ll ans=0;
while (top[u]!=top[v]) {
if (dep[top[u]]<dep[top[v]]) swap(u,v);
ans=(ans+query(1,dfn[top[u]],dfn[u]))%mod; //注意查询的时候一定是深度浅的在前,作为区间左端点,因为它的dfs序小。
u=fa[top[u]];
}
if (dep[u]<dep[v]) swap(u,v);
ans=(ans+query(1,dfn[v],dfn[u]))%mod; //同样,深度浅的在前。本人好几次把这个地方顺手就写成了从u到v qaq。
return ans;
}
inline void UpdatePath(int u,int v,ll w) {
while (top[u]!=top[v]) {
if (dep[top[u]]<dep[top[v]]) swap(u,v);
update(1,dfn[top[u]],dfn[u],w);
u=fa[top[u]];
}
if (dep[u]<dep[v]) swap(u,v);
update(1,dfn[v],dfn[u],w);
}
查询一个点及它的子树内所有点权和
前面有说,子树内的\(dfs\)序也是连续的,那么求这个就相当于求一段连续的序列区间和,用线段树维护。同样可以得到修改操作。
inline ll QuerySon(int u) {
return query(1,dfn[u],dfn[u]+sz[u]-1); //dfn[u]+sz[u]-1即为区间右端点。
}
inline void UpdateSon(int u,ll w) {
update(1,dfn[u],dfn[u]+sz[u]-1,w);
}
例题
1.首先看模板吧:luogu P3384
把上面几个操作搬抄一遍就完事了。
代码
2.luogu P1505
对于我这个大彩笔来说,本题有四个难点。
首先,这个题目中给出的都是边权,所以我们需要把边权转换成点权。这个操作可以直接让一条边通向的那个点(深度更深的点)继承这条边的权值。有一个数组的定义需要改变一下,就是\(rk\)数组,我们把它改成\(dfs\)序所对应的点的点权(当然不改也没问题),这样更方便后面的操作。这些可以在第一二次\(dfs\)中完成。
inline void dfs1(int u,int f,int depth) {
fa[u]=f; dep[u]=depth; sz[u]=1;
for (int i=head[u];i;i=e[i].nxt) {
int v=e[i].to;
if (v==f) continue;
dfs1(v,u,depth+1);
val[v]=e[i].w;
sz[u]+=sz[v];
if (sz[v]>sz[son[u]]) son[u]=v;
}
}
inline void dfs2(int u,int t) {
top[u]=t; dfn[u]=++dfncnt; rk[dfncnt]=val[u];
if (son[u]) dfs2(son[u],t);
for (int i=head[u];i;i=e[i].nxt) {
int v=e[i].to;
if (v==son[u] || v==fa[u]) continue;
dfs2(v,v);
}
}
其次,是一条路径上权值取反,也就是第二类操作。对于一个线段树中的元素,我们定义一个flag变量来表示它是否需要取反。每次取反过后把其flag异或1,表示这一段区间已经取反过了,其实意义有点类似于懒标记。
需要注意的是,一条路径取反过后,也就是一个区间取反过后,最大值和最小值都是有变化的。更新最大值为原最小值的相反数,更新最小值为原最大值的相反数。
inline void oppo(int p) {
swap(t[p].maxx,t[p].minx);
t[p].maxx*=-1;
t[p].minx*=-1;
t[p].sum*=-1;
t[p].flag^=1;
}
inline void pushdown(int p) {
if (!t[p].flag) return;
oppo(ls); oppo(rs);
t[p].flag=0;
}
inline void updateblock(int p,int l,int r,int L,int R) {
if (L<=l && r<=R) {oppo(p); return;}
pushdown(p);
if (L<=mid) updateblock(ls,l,mid,L,R);
if (R>mid) updateblock(rs,mid+1,r,L,R);
pushup(p);
}
第三,是树剖中跳出\(while\)循环时,不应该统计此时两点间的路径,而是要把其中深度浅的那一个+1,再统计。
为什么?当我们跳出循环时(假设我们在循环中一直让\(u\)往上跳),得到的\(top[u]\)的点权是\(top[u]\)和其父亲的连边的边权,按照我们之前用点权替换边权的规则,也就是深度更深的那个点继承这条边权,那么这条边的边权是归在\(top[u]\)身上,所以我们要跳过这个点权。
inline int getit(int x,int op) {
if (op==1) x=0;
else if (op==2) x=-inf;
else if (op==3) x=inf;
return x;
}
inline void updatepath(int u,int v) {
while (top[u]!=top[v]) {
if (dep[top[u]]<dep[top[v]]) swap(u,v);
updateblock(1,1,n,dfn[top[u]],dfn[u]);
u=fa[top[u]];
}
if (u==v) return;
if (dfn[u]<dfn[v]) swap(u,v);
updateblock(1,1,n,dfn[v]+1,dfn[u]);
}
inline int querypath(int u,int v,int op) {
int res=0; res=getit(res,op);
while (top[u]!=top[v]) {
if (dep[top[u]]<dep[top[v]]) swap(u,v);
int tmp=query(1,1,n,dfn[top[u]],dfn[u],op);
if (op==1) res+=tmp;
else if (op==2) res=max(res,tmp);
else if (op==3) res=min(res,tmp);
u=fa[top[u]];
}
if (dfn[u]<dfn[v]) swap(u,v);
if (u!=v) {
int tmp=query(1,1,n,dfn[v]+1,dfn[u],op);
if (op==1) res+=tmp;
else if (op==2) res=max(res,tmp);
else if (op==3) res=min(res,tmp);
u=fa[top[u]];
}
return res;
}
好耶,交一发!哦,wa掉了。
第四个难点,在第一类操作修改边权时,不能直接修改输入的边通向的那个点,因为它不一定是深度更深的!我们要找出这条边的两个端点中深度更深的点,再修改它。
if (s[0]=='C') {
int i=read(),w=read();
int tmp;
if (dep[a[i].x]>dep[a[i].y]) tmp=a[i].x;
else tmp=a[i].y;
updatepoint(1,1,n,dfn[tmp],w);
}
长链剖分
待学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号