Fast R-CNN(理解)
扫码关注下方公众号:"Python编程与深度学习",领取配套学习资源,并有不定时深度学习相关文章及代码分享。

0 - 背景
经典的R-CNN存在以下几个问题:
- 训练分多步骤(先在分类数据集上预训练,再进行fine-tune训练,然后再针对每个类别都训练一个线性SVM分类器,最后再用regressors对bounding box进行回归,并且bounding box还需要通过selective search生成)
- 时间和空间开销大(在训练SVM和回归的时候需要用网络训练的特征作为输入,特征保存在磁盘上再读入的时间开销较大)
- 测试比较慢(每张图片的每个region proposal都要做卷积,重复操作太多)
在Fast RCNN之前提出过SPPnet来解决R-CNN中重复卷积问题,但SPPnet仍然存在与R-CNN类似的缺陷:
- 训练分多步骤(需要SVM分类器,额外的regressors)
- 空间开销大
因此,该文提出的Fast RCNN便是解决上述不足,在保证效果的同时提高效率。基于VGG16的Fast RCNN模型在训练速度上比R-CNN快大约9倍,比SPPnet快大约3倍;测试速度比R-CNN快大约213倍,比SPPnet快大约10倍,在VOC2012数据集上的mAP大约为66%。
1 - 整体思路
1.1 - 训练
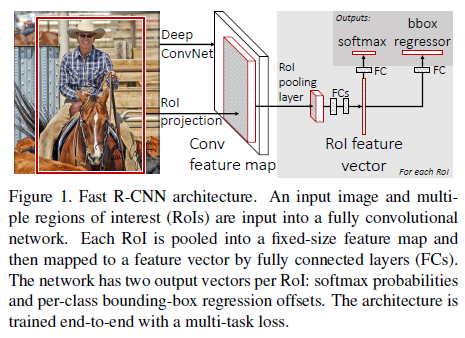
- 输入是$224 \times 224$的固定大小图片
- 经过5个卷积层+2个降采样层(分别跟在第一和第二个卷积层后面)
- 进入ROIPooling层(其输入是conv5层的输出和region proposal,region proposal个数大约为2000个)
- 再经过两个output都为4096维的全连接层
- 分别经过output各为21和84维的全连接层(并列的,前者是分类输出,后者是回归输出)
- 最后接上两个损失层(分类是softmax,回归是smoothL1)
fast R-CNN模型的流程图如下:
1.1.1 - ROIPooling
由于region proposal的尺度各不相同,而期望提取出来的特征向量维度相同,因此需要某种特殊的技术来做保证。ROIPooling的提出便是为了解决这一问题的。其思路如下:
- 将region proposal划分为$H \times W$大小的网格
- 对每一个网格做MaxPooling(即每一个网格对应一个输出值)
- 将所有输出值组合起来便形成固定大小为$H \times W$的feature map
1.1.2 - 训练样本
训练过程中每个mini-batch包含2张图像和128个region proposal(即ROI,64个ROI/张),其中大约25%的ROI和ground truth的IOU值大于0.5(即正样本),且只通过随机水平翻转进行数据增强。
1.1.3 - 损失函数
多损失融合(分类损失和回归损失融合),分类采用log loss(即对真实分类的概率取负log,分类输出K+1维),回归的loss和R-CNN基本一样。
总的损失函数如下:
$$L(p,u,t^u,v)=L_{cls}(p,u)+\lambda [u\geqslant 1]L_{loc}(t^u,v)$$
分类损失函数如下:
$$L_{cls}(p,u)=-log\ p_u$$
回归损失函数如下:
$$L_{loc}(t^u,v)=\sum_{i\epsilon \{x,y,w,h\}}smooth_{L_1}(t_i^u-v_i)$$
其中有:
$$smooth_{L_1}(x)=\left\{\begin{matrix}0.5x^2\ \ \ \ \ \ if\ |x|< 1\\|x|-0.5\ \ otherwise\end{matrix}\right.$$
1.1.4 - 改进全连接层
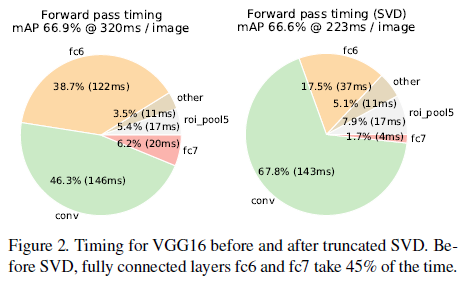
由于卷积层计算针对的是一整张图片,而全连接层需要对每一个region proposal都作用一次,所以全连接层的计算占网络计算的将近一半(如下图)。作者采用SVD来简化全连接层计算。
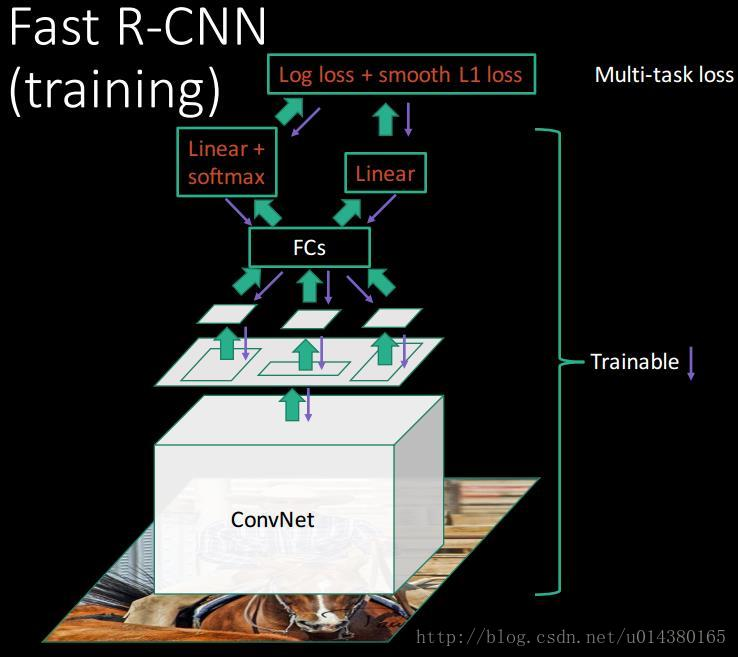
1.1.5 - 训练整体架构总结
图片引用自博客。
1.2 - 测试
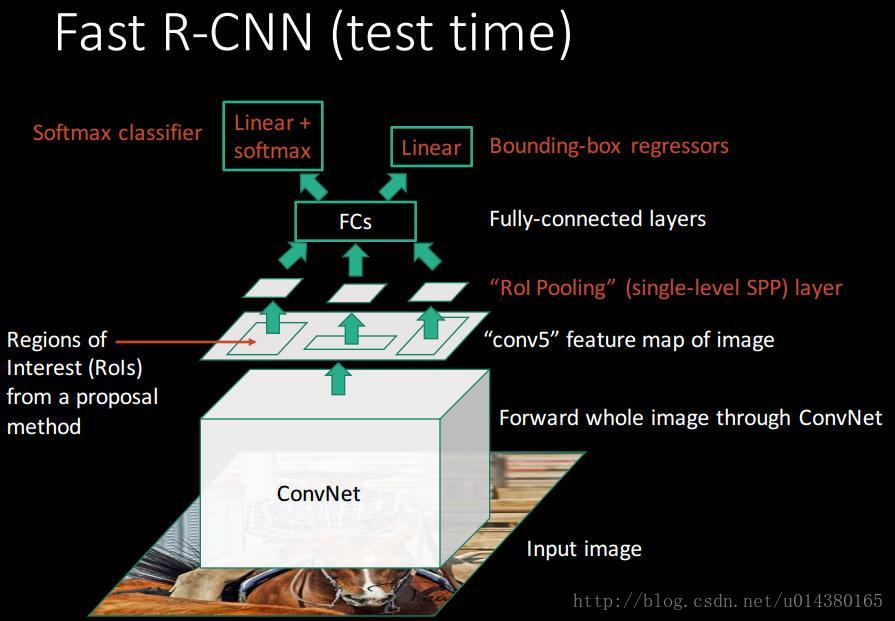
1.2.1 - 测试整体架构总结
图片引用自博客。
2 - 思考
2.1 - 改进
- 卷积不再是重复对每一个region proposal,而是对于整张图像先提取了泛化特征,这样子减少了大量的计算量(注意到,R-CNN中对于每一个region proposal做卷积会有很多重复计算)
- ROIPooling的提出,巧妙的解决了尺度放缩的问题
- 将regressor放进网络一起训练,同时用softmax代替SVM分类器,更加简单高效
2.2 - 不足
region proposal的提取仍然采用selective search,整个检测流程时间大多消耗在这上面(生成region proposal大约2~3s,而特征提取+分类只需要0.32s),之后的Faster RCNN的改进之一便是此点。
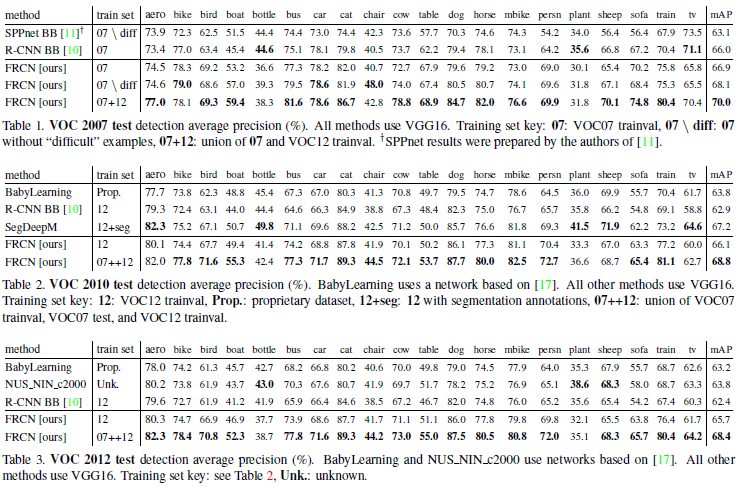
3 - 结果
3.1 - mAP
FRCN相比其他算法表现更好,且注意到,VOC12由于数据集更大而使得模型效果提高很多。(这一角度也说明了数据对于当前深度学习的重要性不容忽视!)
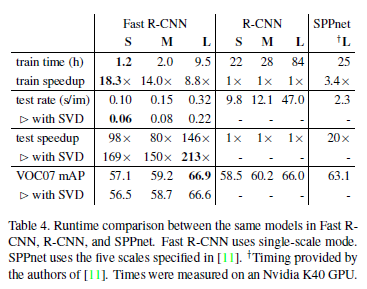
3.2 - 速度
3.3 - 多任务训练(multi-task)
由于本文提出的模型是基于R-CNN通过multi-task训练方式进行改进的,因此要说明multi-task的有效性。一共分为S/M/L三组,每组对应四列,分别为:
- 仅采用分类训练,测试也没有回归
- 采用论文中的分类+回归训练,测试没有回归
- 采用分段训练,测试没有回归
- 采用论文中的分类+回归训练,测试有回归

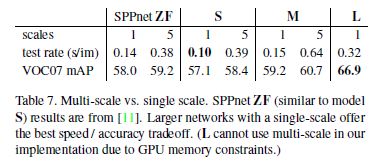
3.4 - 单尺度vs多尺度
多尺度表示输入图像采用多种尺度输入,在测试的时候发现多尺度虽然能在mAP上得到些许提升但也增加了时间开销(作者给出原因:深度卷积网络可以学习尺度不变性)。
4 - 参考资料
https://blog.csdn.net/u014380165/article/details/72851319

 浙公网安备 33010602011771号
浙公网安备 33010602011771号