OceanBase研究
1、数据模型:
(1)层次数据模型:数据之间存在着像树一样的层级关系
(2)网状数据模型:数据之间存在着像网一样的关系
(3)关系数据模型:关系型数据库就是采用关系模型作为数据的组织形式,数据的逻辑结构是一张二维表
非关系型数据库:也叫nosql数据库,以键值对存储,且结构不固定
2、多版本并发控制:通过对数据行的多个版本管理来实现数据库的并发控制
3、Paxos算法:分布式选举算法;分布式一致性算法来解决一个分布式系统就某个值达成一致的问题;基于消息传递的通讯模型
多种节点之间存在两种通讯模型:共享内存,消息传递
4、传统机械磁盘具有快速顺序读写,慢速随机读写的访问特性,为改变此特性,系统通常会对数据进行排序后存储,需保证数据在不断更新,插入,删除仍然保持有序,目前常用的是B+树与LSM树
(1)B+树:
a、有k个子树的中间节点包含有k个元素,每个越苏不保存数据,只用来索引,所有数据保存在叶子节点
b、所有叶子节点包含了所有元素信息,及指向这些元素记录的指针,且叶子节点本身依关键字的大小自小而大顺序连接
c、所有的中间节点元素同时存在于子节点,在子节点元素中是最大(或最小)元素
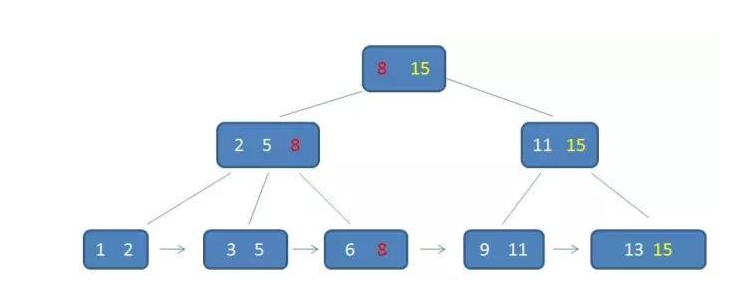
上树中,根节点的最大元素(15)是整个B+树的最大元素,无论插入删除多少元素,始终保持最大元素在根节点
所有叶子节点包含了全量的元素信息,且每个叶子节点都带有指向下一个节点的指针,形成有序链表
(2)LSM树:日志结构合并树,放弃部分读性能,提高写性能;不需要每次有数据更新就必须把数据写入磁盘,将最新数据保留在磁盘,积累到一定量后,再使用归并排序将内粗数据合并追加到磁盘对位
一、OceanBase
1、OceanBase是一个关系型数据库
2、存储引擎采用基于LSM-Tree的架构,分别吧基线数据与增量数据存储在磁盘(SSTable)和内存(MemTable),具备读写分离特点,数据的修改是增量数据,只写内存,性能高;读的时候,数据可能会在内存里有更新过的版本,在持久化存储里有基线版本,需要将两个版本合并,获得新版本(当内存的增量数据达到一定规模时,会触发合并,把增量落盘)
2、分布式存储与事务
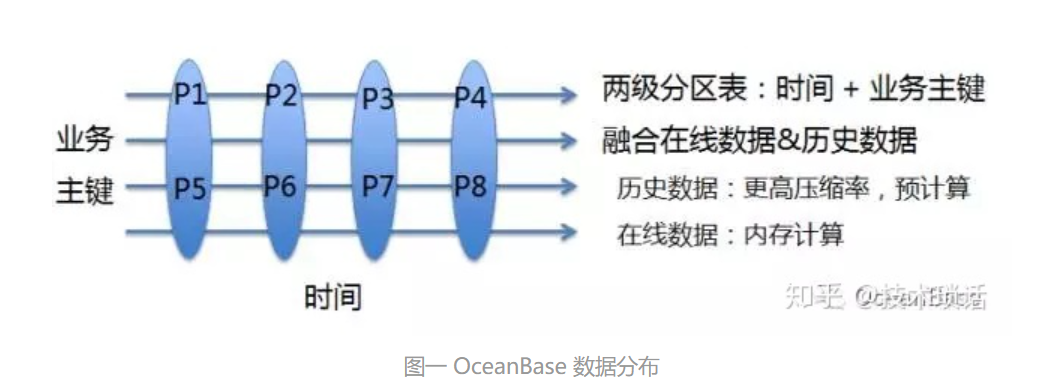
(1)两级分区表:Mysql与oacle均智齿,大部分业务可以按照两个维度划分数据,一个维度是时间,数据按照时间顺序生成;另外一个维度,对于互联网业务来说,是用户,不同用户产生不同数据
OceanBase通过时间和业务两个维度将表格氛围2P1-P8总共8个分区,传统数据库所有分区在同一服务器,OceanBase每个分区可以分布到不同服务器上;分区分布式对于用户来说,是完全透明
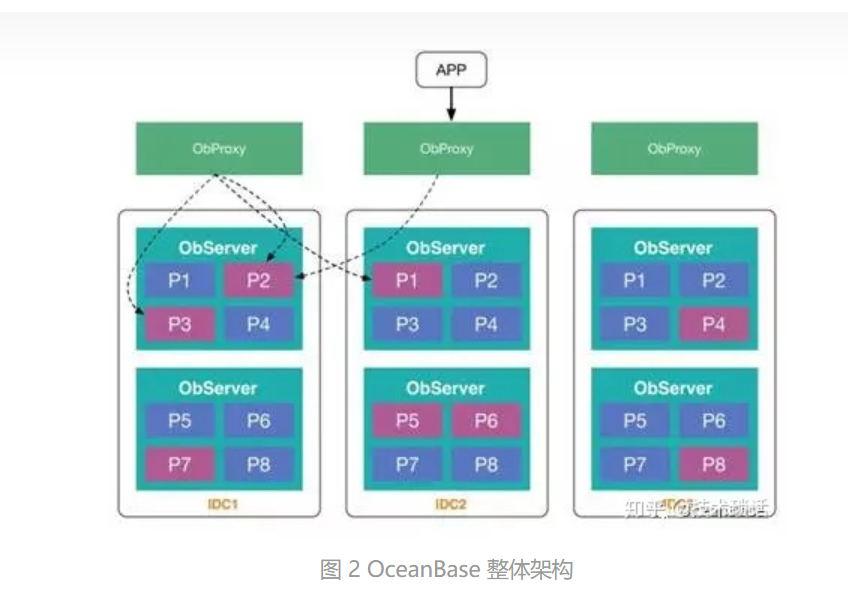
(2)为了实现机房故障无损容灾,需要部署到3个机房,每个机房会有很多服务器,每个服务器会服务很多不同分区,P1-P8代表不同分区,每个分区有3个副本,分布在3个机房,用户请求先分发给Obproxy,Obproxy是一个访问代理,会根据用户请求的数据将请求转发到合适的服务器上
一般分布式系统会有一个总控进程,用来做全局管理,负载均衡;Oceanbase没有单独的总控,其总控是一个服务,叫rootservice,集成在Oserver里,Oceanbase会从所有工作机中动态选出一台Observer执行总控服务,当其故障时,会重新选举
3、SQL语句执行


 浙公网安备 33010602011771号
浙公网安备 33010602011771号