分布式服务发现
服务发现机制:两种协议:一种是私有定制化协议,另一种是通用的DNS协议
1、RPC服务发现:服务调用方与服务提供方通过接口来查找,服务IP集合就是服务地址,通过接口获取服务IP的集合来完成服务的发现,就是所谓PRC框架服务发现机制(对业务有一定侵入)
(1)通过zookeeper实现,具有强一致性,但系统性能影响较大(CP)
(2)通过消息总线模式,达到最终一致性,牺牲一部分强一致性(AP)
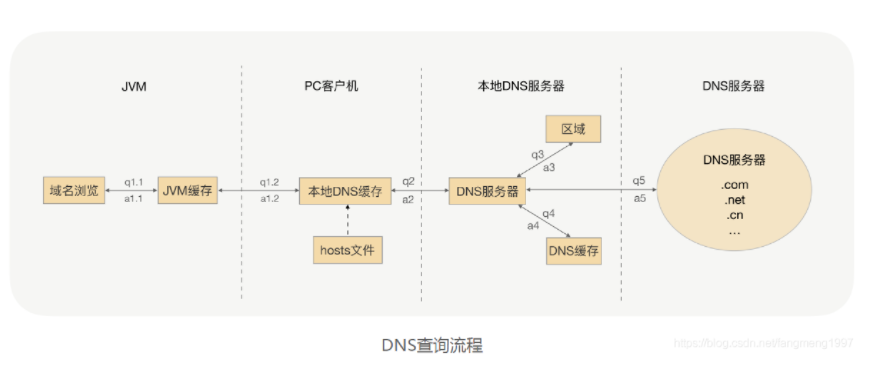
2、DNS:域名系统;正向解析:将域名解析为IP地址,反向解析,将IP地址解析为域名
DNS服务发现:注册中心数据应该可以用DNS的数据格式暴露,让任何系统的DNS客户端通过DNS协议获取服务列表
(1)独立的DNS server (2)DNS filter:DNS服务器集成到服务调用者上
DNS的多级缓存机制:除了直接把域名解析结果缓存起来,还会将整个分布式DNS管理服务器的数据缓存到本地,多级缓存,永久保存;导致服务调用者无法及时感知服务节点的变化
一、Eureka
1、AWS(amazon web services)的每个区域(region)一般由多个可用区(Availability Zone:AZ)组成,而一个可用区一般由多个数据中心组成,提高应用程序高可用性
区域:将某个地区的基础设置服务集合称为一个区域
2、Eureka Server:服务注册中心,用于提供服务注册功能;
Eureka Server:客户端,系统中的微服务,用于和EurekaServer交互,会主动发送心跳来续约,让服务端知道自己存活;服务端若超过90s没收到续约则会将服务从列表中删除
3、服务注册与发现流程:
(1)搭建Eureka server作为服务注册中心
(2)服务提供者启动时,作为Eureka client注册到server
(3)服务消费者启动时,作为Eureka client注册到server
(4)服务消费者获取server上可用的服务列表,通过HTTP或消息中间件远程调用,当服务有多个时,通过ribbon负载均衡;当server宕掉时,消费者依然可以使用缓存中信息找到服务提供者
4、自我保护机制:在运行期间会去统计心跳失败比例在15分钟内是否低于85%,低于85%会进入自我保护机制,启动以下:
(1)不会再从服务列表删除没收到心跳而应该过期的服务
(2)能够接受新服务的注册与查询请求,但不会被同步到其他节点上(保证当前节点依然可用)
(3)网络稳定时,当前实例新的注册信息会同步到其他节点
自我保护机制:当个别客户端心跳失联时认为是客户端问题,剔除客户端;捕获到大量心跳失败,认为是网络问题;心跳恢复时,退出保护机制
5、Eureka 集群原理:server通过复制来同步数据,当某台server宕机时候,会自动切换到其他server节点;当节点接收客户端请求时,所有操作都会在节点间复制;所有server进行两两复制,采用异步来进行同步,不保证节点状态一致,基本能保证最终状态一致(保证AP)
6、Eureka分区:提供region跟zone概念分区(AWS)
二、Nacos:服务发现+服务配置
1、服务发现:基于DNS和RPC的服务发现
2、动态配置服务:管理所有环境的应用配置与服务配置
3、动态DNS服务:DNS解析服务
4、两大组件:server 与 client
5、同时支持AP与CP两种模式,有两套协议
Nocas中的实例提供一个ehpemeral字段,与zk含义差不多,都代表是否为临时节点,如果为临时节点采用AP协议,非零时节点采用CP协议,注册中心中所有实例都默认是临时节点
AP:Distro协议
CP:Raft协议(在注册中心数据持久化存储以及配置中心两个地方采用CP)
三、ETCD
1、强一致性的服务发现存储仓库,键值存储仓库,用于配置共享与服务发现
例如:k8s采用etcd存储docker集群的配置信息
2、curl是一个命令行工具,用于服务器间传输数;一个节点维护一个状态机,任意时刻至多存在一个有效节点,主节点处理所有来自客户端的写操作,通过Raft协议保证写操作对状态机的改动会可靠地同步到其他节点
3、特性:
(1)基于http+json的API用curl可以使用
(2)可选SSL客户认证机制
(3)每个实例每秒支持一千次写操作
(4)用raft算法实现分布式
4、分布式系统的数据分为控制数据与应用数据,etcd默认处理的是控制数据
5、ETCD采用Raft协议来维护各个节点状态的一致性,每个节点存储了完整的数据,通过Raft协议保证各个节点维护的数据是一致的

6、集群节点数与网络分割
(1)日志复制需要等其他节点成功返回才写入状态机,说明节点数量越少性能越好
(2)网络分割时:
a、当集群leader在多数一侧时,集群可以正常工作,少数一侧无法收到心跳无法选举,
b、当leader在少数一侧时,集群可正常工作,多数侧节点可进行选举新leader集群服务正常
(3)不要选择偶数节点:避免选举失败或无效;网络分割时,若被对半分割,会导致集群无法正常工作
7、ETCD整体架构
(1)分为网络层,Raft模块,复制状态机,存储模块
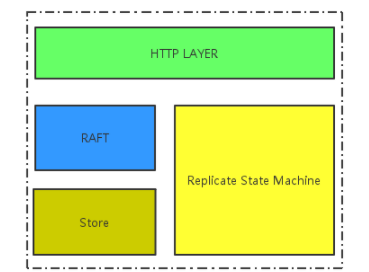
网络层:收发客户端数据
raft模块:实现raft协议
存储模块:KV存储,WAL文件,snapshot管理
复制状态机:状态及数据维护在内存中,定期持久化到磁盘,每次写请求会持久化到WAL文件,根据写请求内容修改状态机数据
8、ETCD的日志及快照管理
(1)对数据持久化采用binlog(日志,也称为WAL)加snapshot(快照)方式
WAL(预写式日志)是关系型数据库中提供原子性与持久性的技术,所有修改在提交前都要写入Log文件
(2)etcd数据库所有操作都会写入到Binlog中,而Binlog是实时写到磁盘上,不会丢失数据,保证持久化(故障快速回复与数据回滚功能)
(3)etcd数据高可用性与一致性是Raft算法实现,master节点会通过raft协议向slave节点复制binlog,slave节点根据Binlog对操作进行回放,以保证数据多个副本的一致性;
(4)快照是将内存中整个输数据库复制一份,序列化为json,写到磁盘;
9、两种数据传输通道
(1)Stream类型通道:长连接,传输数据量较小的消息,如追加日志,心跳
(2)Pipeline类型通道:短连接,传输数据量大的消息,如snapsot消息
10、网络层与Raft模块之间通过GolangChannel完成数据通信
四、Raft协议
1、选主:选举一个主节点对外提供服务;当follower节点没有收到主节点的心跳时,会将自己的角色改变Candidate(选举人),进行选举;若caddidate收到主节点心跳,进入follower角色
2、日志复制:主节点将每次操作形成日志条目,并持久化到本地磁盘,通过网络IO发到其他节点;其他节点判断是否将日志持久化到本地,若主节点超过半数的成功返回,认为该日志是可提交的,并将日志输入到状态机,将结果返回给客户端
3、安全性:假设挂掉的节点被重新推选为主节点,那他挂掉期间缺失日志,选为主节点时,会用缺失的日志列表覆盖其他节点,将集群已经提交的日志覆盖掉;
draf协议对选主逻辑进行限制,确保选出的节点已经包含了集群已经提交的所有日志
https://www.cnblogs.com/softidea/p/6517959.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号