分布式中间件--分布式协同配置
zookeeper
1、zookeeper是将复杂且容器出错的分布式一致性服务封装起来,提供一些列简单易用接口供用户使用
2、CAP理论:对于一个分布式系统,不可能同时满足以下3点
(1)一致性(Consistency):数据在多个副本中保持一致的特性
(2)可用性(Availability):每次请求都能获取正确响应
(3)分区容错性(Partition tolerance):遇到网络分区故障时能保证对外提供一致性和可用性服务(必须的)
zookeeper实现的是CP,spring cloud的eruka实现的是AP
3、BASE理论
(1)基本可用(Basically Available):系统故障时允许损失部分可用性
(2)软状态(Soft-state):允许出现中间状态,数据备份节点经过一定的延时后达到一致性
(3)最终一致性(Eventuallt consistent):data replication最终实现数据一致性
4、zookeeper=文件系统+通知系统
5、数据模式:所有存储数据由znode组成,节点也称为znode,并以key/value形式存储数据,整体结果类似于Linux文件系统的模式以树形结构存储
6、session是服务端技术,服务器为每个用户创建一个session对象,用户访问该服务器中其他web资源时,从Session中取得用户数据,将数据存储在服务器中

7、zookeeper会话管理采用“分桶策略”:将超时时间相近的会话放到一个桶里管理,以减少管理的复杂度,再检查超时会话时,只需要检查桶中剩下的会话即可
分配原则是每个会话的下一个超时时间点
8、ExpiractionInterval:在运行期间定期检查是否超时,默认值为tickTime
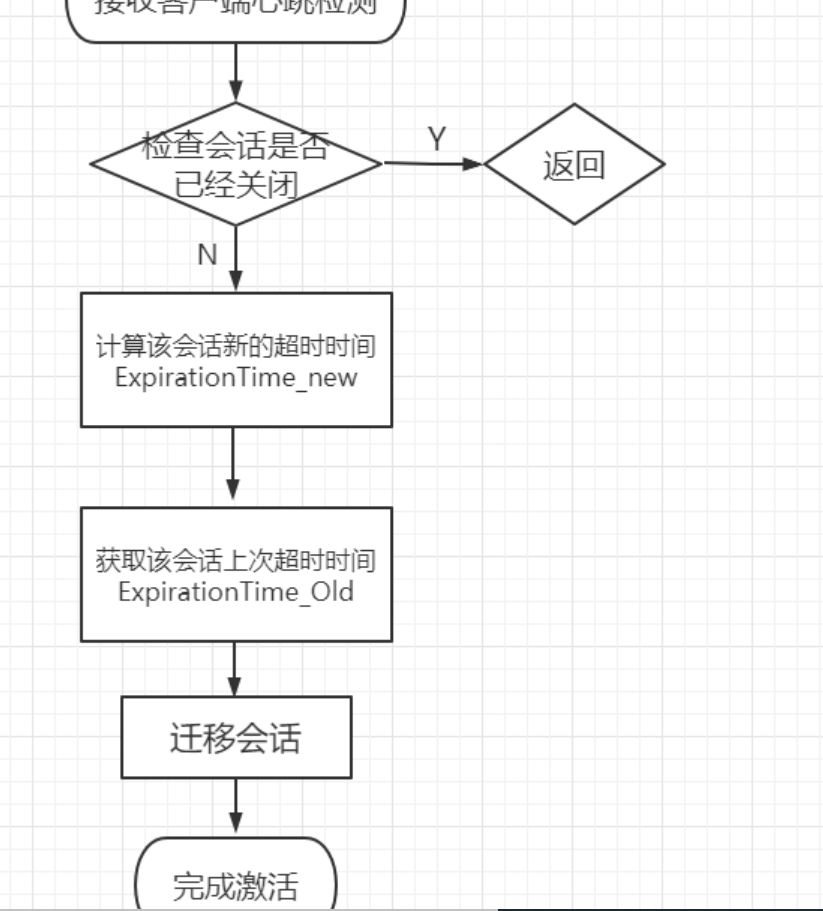
9、会话激活:客户端会在超时时间内向服务端发送ping请求来保持时效性,成为心跳检测,重新建立连接后会再次计算下一次超时时间,进行分桶
10、会话状态:正常连接为connected,由于网络等原因断开,客户端重新连接,状态为connecting;由于出现故障,权限,客户端主动断开链接为closed
11、一个session代表一个客户端会话:
(1)Ticktime:下一次会话超时时间点,便于分桶管理
(2)iscloseing:会话被关闭状态,iscloseing标记为已经关闭;不再处理请求
12、会话过程:建立连接后,根据timeout计算下一次会话的超时时间点,放入相近的桶中;zookeeper的leader服务器会定期检查是否超时,检查的周期就是expiractionTime的倍数;保留在桶中的会话就是超时的会话,会被清理;同时,客户端会在超时时间内进行心跳检测进行会话激活,如果已经是关闭状态,不再发起请求;非关闭状态即会重新计算下一过期时间点,放入区块中
会话激活:1、客户端向服务器发起读写操作;2、客户端在sessiontimeout/3范围内未与服务器进行通信,客户端会主动发起Ping请求触发激活
13、watch机制:客户端向服务端某个节点路径上注册一个watcher,同时客户端也会存储特定的watcher,当节点数据或子节点发生变化时,服务端通知客户端
14、zookeeper依赖ZAB实现分布式数据一致性:消息广播;奔溃恢复


 浙公网安备 33010602011771号
浙公网安备 33010602011771号