python编程与基础
1、切片string[::-1]表示忽略起止位置,-1表示步长;步长为正,表示从左向右取;步长为负,表示从右向左取
2、python文件有两种用法,一种是直接执行,一种是作为脚本导入;if __name__=='main'即是控制这两种情况的运行,在 if __name__ == 'main': 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而 import 到其他脚本中是不会被执行的。
3、列表用[]标志;元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表;字典用"{ }"标识。字典由索引(key)和它对应的值value组成。list用[]
4、append是list的方法,join是string的方法
5、range(start, stop[, step])
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
- stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
- step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
6、反转字符串
from collections import deque def reverse1(string): return string[::-1] #reverse是列表的一个内置方法 #reversed是python的一个类,返回一个把序列值翻转后的迭代器 def reverse2(string): list1=list(string) list1.reverse() newString="".join(list1) return newString def reverse3(string): #利用递归,每次只取一个字符 if(len(string))<=1: return string else: return reverse3(string[1:])+string[0] #range(start, stop[, step]),stop是计步结束,但不包含stop,输出一个整数列表 def reverse4(string): list=[] for i in range(len(string)-1,-1,-1): list.append(string[i]) return "".join(list) #deque是创建一个双向队列 #append(往右边添加一个元素);appendleft(往左边添加一个元素);extend(从队列右边扩展一个列表的元素);extendleft(从队列左边扩展一个列表的元素) def reverse5(string): q=deque() q.extendleft(string) return "".join(q) if __name__=='__main__': string='I am a girl' print(reverse1(string)) print(reverse2(string)) print(reverse3(string)) print(reverse4(string)) print(reverse5(string))
7、求两个数之间的质数及个数
def zhishu(num1,num2): n=0 list=[] for i in range(num1,num2+1): for j in range(2,i): if(i%j==0): break if(j==i-1): n=n+1 list.append(i) print("共有 %d 个质数,分别为:%s" % (n, list)) zhishu(101,200)
8、爬取某个页面并保存为html到本地
import urllib.request import urllib.parse def tieba(url,l): #添加Header模拟浏览器访问 # header = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'} for i in range(len(l)): file_name="D:/2019/python/"+l[i]+".html" m=urllib.request.urlopen(url+l[i]).read() with open(file_name,"wb") as file: file.write(m) if __name__=="__main__": url="http://tieba.baidu.com/f?ie=utf-8&kw=" l_tieba=["python","java"] tieba(url,l_tieba)
9、dict.has_key(key):如果键在字典里返回true,否则返回false。
dict.setdefault(key, default=None):key是要查找的键值,default是默认键值;如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。只能删除开头或结尾
import os def findFileDir(path): fileDirList=os.listdir(path) for i in fileDirList: newpath=path+'/'+i dict={} if os.path.isdir(newpath): findFileDir(newpath) elif os.path.isfile(newpath): if path in dict: dict.get(path).append(i) # else: # dict.setdefault(path,[]).append(i) else: return 1 print("%s 目录下的文件包括:%s"%(dict.keys(),str(dict.values()).strip("[]"))) if __name__=='__main__': path='D:/2019' findFileDir(path)
10、冒泡排序:两两比较
选择排序:不断选出最小值,放进排序序列
#冒泡排序 def maopao_sort(list,n): for i in range(0,n-1): for j in range(0,n-i-1): if list[j]>list[j+1]: list[j+1],list[j]=list[j],list[j+1] return list #选择排序 def xuanze_sort(list,n): for i in range(0,n-1): min = i for j in range(i+1,n): if list[j]<list[min]: min=j list[i],list[min]=list[min],list[i] #下标i跟j互换位置 return list if __name__=='__main__': list=[3,9,5,1,0,7] n=len(list) # print(maopao_sort(list,n)) print(xuanze_sort(list,n))
11、创建UDP服务器基本流程
from socket import * #1、创建套接字 udpsocket=socket(AF_INET,SOCK_DGRAM) #2、绑定服务器IP跟port bindaddr={'IP地址','8080'} udpsocket.bind(bindaddr) #3、接受数据 while True: recvData=udpsocket.recvfrom(1024) print(recvData[0].decode("gb2312")) #4、关闭套接字 udpsocket.close()
创建UDP客户端基本流程
from socket import * #1、创建套接字 udpsocket=socket(AF_INET,SOCK_DGRAM) #2、准备接收方地址 bindaddr={'',9090} udpsocket.bind(bindaddr) sendAddr={'IP地址','8080'} #3、从键盘获取数据 sendData=raw_input("请输入要发送数据:") #4、发送数据到指定电脑 udpsocket.sendto(sendData.encode("gb2312"),sendAddr) recvData=udpsocket.recvfrom(1024) print(recvData[0].decode("gb2312")) print(recvData[1][0].decode("gb2312")) print(recvData[1][1]) #5、关闭套接字 udpsocket.close()
12、文件命名时候注意不要与模块名称重合
13、深拷贝与浅拷贝:
(1)数字和字符串中的内存都指向同一个地址,所以深拷贝和浅拷贝对于他们而言都是无意义的
import copy a = 123333 print(id(a)) #输出变量a在内存的地址 b = a print(id(b)) b = copy.copy(a) #浅拷贝 print(id(b)) c=copy.deepcopy(a) #深拷贝 print(id(c))
输出:
4056944
4056944
4056944
4056944
(2)对于字典和列表,浅拷贝和深拷贝的内存地址不一致,,浅拷贝只拷贝第一层地址;对于元组ID不变
dic={'key1':123,'key2':[123,456]}
print(id(dic['key1']))
print(id(dic['key2']))
print(id(dic['key2'][0]))
new_dic=copy.copy(dic)
print("*",id(new_dic['key1']))
print("*",id(new_dic['key2']))
print("*",id(new_dic['key2'][0]))
输出:
8791105520272
37272968
8791105520272
* 8791105520272
* 37272968
* 8791105520272
深拷贝:将会把所有数据重新创建
dic={'key1':123,'key2':[123,456]}
print(id(dic['key1']))
print(id(dic['key2']))
print(id(dic['key2'][0]))
#深拷贝
new_dic=copy.deepcopy(dic)
print("*",id(new_dic['key1']))
print("*",id(new_dic['key2']))
print("*",id(new_dic['key2'][0]))
输出:
8791099228816
35962376
8791099228816
* 8791099228816
* 36043464 #地址改变
* 8791099228816
(3)浅拷贝应用:在浅拷贝中 当改变拷贝对象的值 被拷贝对象的值也会随之改变
dic={'key1':123,'key2':[123,456]}
print(dic['key2'][0])
new_dic=copy.copy(dic)
new_dic['key2'][0]=789
print(dic['key2'][0])
print(new_dic['key2'][0])
输出:
123
789
789
(4)深拷贝的应用:当不想改变被拷贝的值时 应该使用深拷贝
dic={'key1':123,'key2':[123,456]}
print(dic['key2'][0])
new_dic=copy.deepcopy(dic)
new_dic['key2'][0]=789
print(dic['key2'][0])
print(new_dic['key2'][0])
输出:
123
123
789
(5)区别:
引用:
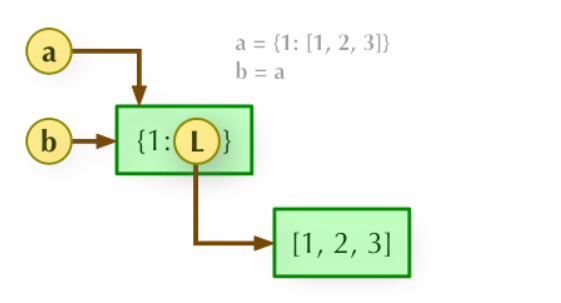
浅拷贝:a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象;
- 对于 不可 变类型 Number String Tuple,浅复制仅仅是地址指向,不会开辟新空间。
- 2、对于 可 变类型 List、Dictionary、Set,浅复制会开辟新的空间地址(仅仅是最顶层开辟了新的空间,里层的元素地址还是一样的),进行浅拷贝
- 3、浅拷贝后,改变原始对象中为可变类型的元素的值,会同时影响拷贝对象的;改变原始对象中为不可变类型的元素的值,只有原始类型受影响。 (操作拷贝对象对原始对象的也是同理)
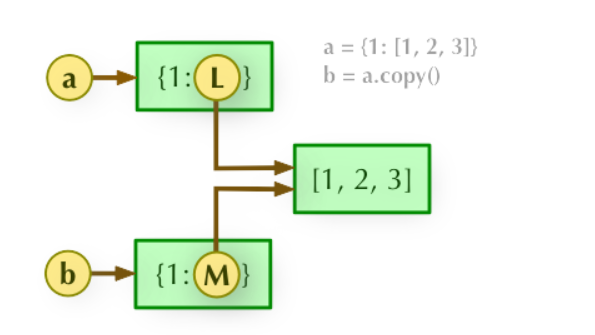
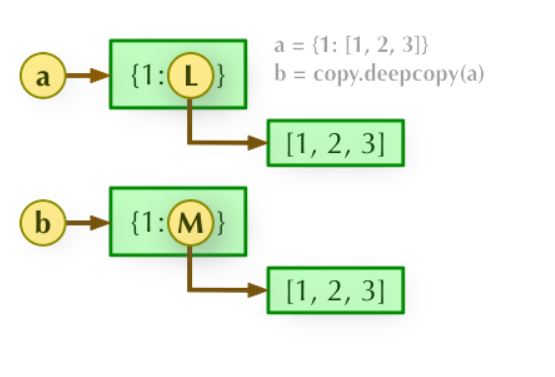
深拷贝:a 和 b 完全拷贝了父对象及其子对象
14、装饰器:格式:@函数名 (语法糖)紧挨着需要装饰的函数上方。作用:引入日志,函数执行时间统计,执行函数前预处理和执行后的清理功能,权限校验等场景,缓存。
import time def timeit(func): def test(): start = time.clock() func() end =time.clock() print("time used:", end - start) return test @timeit def sum1(): sum = 1+ 2 print (sum) sum1() 输出: 3 time used:4.0204000000002016e-05
15、集合set:无序不重复序列,可以用{}或set()来创建,空集合只能用set()创建
内置函数:
(1)intersection:返回集合的交集
(2)difference:返回差集
(3)union:返回两个集合并集
(4)symmetric_difference:返回两个元素中不重复元素集合,即交集的补集
def interSection(list1,list2): list1_set=set(list1) list2_set=set(list2) Intersection=list1_set.intersection(list2_set) Union=list1_set.union(list2_set) Difference=list1_set.difference(list2_set) Sym_difference=list1_set.symmetric_difference(list2_set) Intersection_list=list(Intersection) Union_list=list(Union) Difference_list=list(Difference) Sym_difference_list=list(Sym_difference) print("交集为:%s\n并集为:%s\n在集合a但不在集合b为:%s\n补集为:%s"%(Intersection_list,Union_list,Difference_list,Sym_difference_list)) if __name__=="__main__": list1=[1,6,9,"a","e","i"] list2=[9,3,2,"e","p","c"] interSection(list1,list2)
输出:
交集为:[9, 'e']
并集为:[1, 2, 3, 'p', 6, 9, 'e', 'a', 'c', 'i']
在集合a但不在集合b为:[1, 'a', 6, 'i']
补集为:[1, 2, 3, 'p', 6, 'c', 'a', 'i']
16、


 浙公网安备 33010602011771号
浙公网安备 33010602011771号