1.表结构
1.1.索引
1.1.1.复合索引优化
如果查询经常同时过滤多个字段(如WHERE col1 = ? AND col2 = ?),创建复合索引并强制使用
-- 创建复合索引
CREATE INDEX idx_col1_col2 ON table_name(col1, col2);
-- 强制使用复合索引
SELECT /*+ INDEX(table_name idx_col1_col2) */
*
FROM table_name
WHERE col1 = 'value1' AND col2 = 'value2';
1.1.2.使用覆盖索引避免回表
如果 CTE 只需要索引列,可以创建覆盖索引
-- 为CTE创建覆盖索引
CREATE INDEX idx_emp_salary_dept ON employees(salary, department_id);
WITH
filtered_employees AS (
/*+ INDEX(employees idx_emp_salary_dept) */
SELECT department_id, salary -- 只查询索引列
FROM employees
WHERE salary > 10000
)
SELECT * FROM filtered_employees;
作用:索引直接包含所需数据,无需访问表数据,减少 I/O
1.2.根据日期或数值类型分区
1.2.1.建表SQL
CREATE TABLE TABLE1 (
FIELD1 VARCHAR2(50),
FIELD2 VARCHAR2(50),
FIELD3 NUMBER,
...
FIELD_DATE DATE
)
PARTITION BY RANGE (FIELD_DATE)
INTERVAL (NUMTOYMINTERVAL(1, 'MONTH')) -- 自动按月份创建分区
(
PARTITION p_init VALUES LESS THAN (TO_DATE('2025-01-01', 'YYYY-MM-DD')) -- 初始分区
);
1.2.2.关键特性
自动扩展:当插入新日期数据时,Oracle 自动创建新分区(如PSTNG_DATE='2025-06-15'时,自动创建SYS_Pxxxx分区)。
分区命名:默认使用系统生成名称(如SYS_P1234),可通过触发器或 JOB 重命名。
数据路由:查询时自动定位到对应分区,无需人工干预。
1.2.3.查看分区信息
-- 查看所有分区
SELECT partition_name, high_value, tablespace_name
FROM user_tab_partitions
WHERE table_name = 'TABLE1';
-- 查看数据在各分区的分布
SELECT partition_name, num_rows
FROM user_tab_partitions
WHERE table_name = 'TABLE1';
1.2.4.预创建未来分区(可选)
-- 预创建2025年6月和7月分区(避免首次插入时的延迟)
ALTER TABLE TABLE1
ADD PARTITION p_202506 VALUES LESS THAN (TO_DATE('2025-07-01', 'YYYY-MM-DD'));
ALTER TABLE TABLE1
ADD PARTITION p_202507 VALUES LESS THAN (TO_DATE('2025-08-01', 'YYYY-MM-DD'));
1.2.5.自动重命名分区 JOB
CREATE OR REPLACE PROCEDURE rename_new_partitions AS
BEGIN
FOR p IN (
SELECT partition_name, high_value
FROM user_tab_partitions
WHERE table_name = 'TABLE1'
AND partition_name LIKE 'SYS_P%'
) LOOP
EXECUTE IMMEDIATE 'ALTER TABLE TABLE1 ' ||
'RENAME PARTITION ' || p.partition_name || ' TO p_' ||
TO_CHAR(TO_DATE(SUBSTR(p.high_value, 12, 20), 'YYYY-MM-DD'), 'YYYYMM');
END LOOP;
END;
/
-- 每日运行一次
BEGIN
DBMS_SCHEDULER.CREATE_JOB(
job_name => 'rename_partition_job',
job_type => 'PLSQL_BLOCK',
job_action => 'BEGIN rename_new_partitions; END;',
start_date => SYSDATE,
repeat_interval => 'FREQ=DAILY',
enabled => TRUE
);
END;
/
1.2.6.重建索引
-- 重建单个分区索引
ALTER INDEX idx_stock_pstng_date REBUILD PARTITION p_202505;
-- 重建所有分区索引
ALTER INDEX idx_stock_pstng_date REBUILD GLOBAL;
1.2.7.分区交换(快速归档历史数据)
-- 创建归档表
CREATE TABLE ARCHIVE_DWD_DO045_202504
AS SELECT * FROM DPDB_INTERNAL.DWD_DO045_STOCK_MOVEMENT_DATA WHERE 1=2;
-- 交换分区(瞬间完成,无需锁表)
ALTER TABLE DPDB_INTERNAL.DWD_DO045_STOCK_MOVEMENT_DATA
EXCHANGE PARTITION p_202504 WITH TABLE ARCHIVE_DWD_DO045_202504;
1.2.8.删除历史分区
-- 删除2025年1月前的分区
ALTER TABLE TABLE1 DROP PARTITION p_202412;
1.2.9.监控分区使用情况
-- 查看各分区大小
SELECT
partition_name,
ROUND(bytes/1024/1024, 2) AS size_mb,
num_rows
FROM user_segments
WHERE segment_name = 'DWD_DO045_STOCK_MOVEMENT_DATA'
ORDER BY partition_name;
1.2.10.更新分区统计信息
-- 更新单个分区统计信息
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(
ownname => 'XXX_SCHEMA',
tabname => 'TABLE1',
partname => 'p_202505',
cascade => TRUE,
estimate_percent => 100
);
END;
/
1.2.99.总结
通过 Interval 分区,Oracle 可自动处理日期范围未知的动态数据增长,主要优势:
透明扩展:无需人工干预分区创建,新日期数据自动进入对应分区。
查询优化:分区剪枝(Partition Pruning)自动过滤无关分区,提升查询效率。
管理简化:批量操作(如删除历史分区)仅需毫秒级,不影响其他分区。
1.3.禁用表变更日志
ALTER TABLE TABLE_NAME NOLOGGING;
1.4.
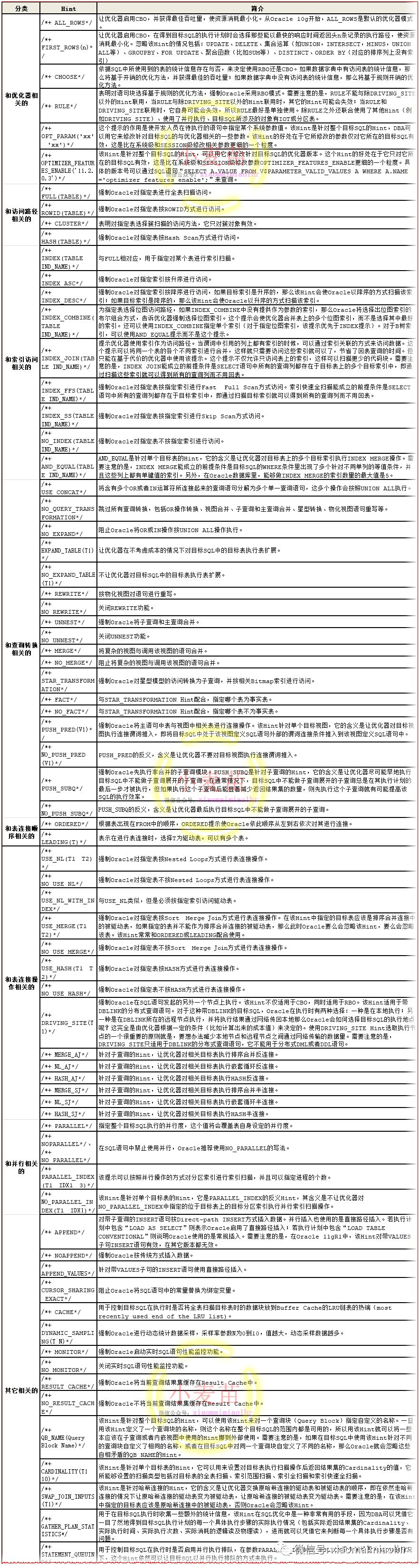
2.Hint(查询提示)
2.1.FULL(TABLE1)
核心作用:
当 Oracle 优化器选择的执行计划不理想(例如本应全表扫描却走了索引)时,可以通过 FULL(TABLE1) 提示强制优化器直接扫描整个表的数据块,跳过索引访问
语法示例:
SELECT /*+ FULL(TABLE1) */ *
FROM TABLE1
WHERE FIELD1 = 10;
常见使用场景
1.表数据量小:当表数据较少时,全表扫描可能比索引扫描更快。
2.索引选择性差:如果过滤条件的选择性低(例如 WHERE status = 'ACTIVE' 匹配大量数据),索引可能不如全表扫描高效。
3.优化器统计信息过时:当表统计信息不准确时,优化器可能误选索引。
4.批量数据处理:在 ETL 或数据批量操作中,全表扫描通常更优
注意事项
1.性能风险:
对大表使用全表扫描可能导致大量 I/O,尤其在过滤条件能高效使用索引时。
全表扫描会触发多块读(Multi-Block Read),可能阻塞 DML 操作。
2.替代方案:
优先更新统计信息:DBMS_STATS.GATHER_TABLE_STATS
使用 INDEX(TABLE1 INDEX_NAME) 提示强制走索引
创建更合适的索引
3.提示优先级:
FULL 提示会覆盖优化器的自动选择,但可能被其他提示(如 NO_INDEX)影响
2.2.INDEX / INDEX_ASC / INDEX_DESC / INDEX_FFS
1. 强制使用指定索引
-- 语法
SELECT /*+ INDEX(table_name index_name) */
column1, column2
FROM table_name
WHERE condition;
-- 示例:强制使用employees表的idx_salary索引
SELECT /*+ INDEX(employees idx_salary) */
employee_id, salary
FROM employees
WHERE salary > 10000;
作用:强制优化器使用idx_salary索引扫描数据,即使统计信息显示其他路径更优
2. 强制使用多个索引(索引合并)
SELECT /*+ INDEX(table_name index1 index2) */
column1, column2
FROM table_name
WHERE condition1 AND condition2;
-- 示例:同时使用dept_id和salary两个索引
SELECT /*+ INDEX(employees idx_dept_id idx_salary) */
employee_id, department_id, salary
FROM employees
WHERE department_id = 10 AND salary > 5000;
适用场景:当查询条件涉及多个独立索引时,通过索引合并(INDEX MERGE)提升效率
3. 指定索引扫描方向
-- 升序扫描(默认)
SELECT /*+ INDEX_ASC(table_name index_name) */
column1, column2
FROM table_name
ORDER BY indexed_column ASC;
-- 降序扫描(避免排序操作)
SELECT /*+ INDEX_DESC(table_name index_name) */
column1, column2
FROM table_name
ORDER BY indexed_column DESC;
4.索引快速全扫描(Index Fast Full Scan):
当查询只需索引列数据(无需回表)时,使用INDEX_FFS提示
SELECT /*+ INDEX_FFS(table_name index_name) */
indexed_column1, indexed_column2 -- 只查询索引列
FROM table_name
WHERE indexed_column1 > 100;
2.3.MATERIALIZED
使用 MATERIALIZED 提示强制物化 CTE 结果
WITH
my_cte AS (
/*+ MATERIALIZED */ -- 强制将CTE结果物化到临时表
SELECT col1, col2, col3
FROM large_table
WHERE condition
)
SELECT *
FROM my_cte
JOIN another_table ON my_cte.col1 = another_table.col1;
作用:将 CTE 结果存储为临时表,避免重复计算。
适用场景:CTE 被多次引用,且计算成本高。
2.4.PARALLEL(N): 指定并行度(n 为 CPU 核心数的 1-2 倍)
SELECT /*+ PARALLEL(4) */ * FROM TABLE1;
2.5.CARDINALITY(基数)
基数 (Cardinality) 是指从数据表、结果集或索引中返回的行数。基数的计算对于优化 SQL 查询非常重要,因为它直接影响执行计划的选择
2.6.APPEND
3.同步方式(更新Sql)
3.1.批量提交,减少事务开销
DECLARE
cnt NUMBER := 0;
BEGIN
FOR rec IN (SELECT * FROM source_table) LOOP
INSERT INTO backup_table VALUES rec;
cnt := cnt + 1;
IF cnt MOD 100000 = 0 THEN
COMMIT; -- 每10万条提交一次
END IF;
END LOOP;
COMMIT; -- 最终提交
END;
Refrence:
小麦苗 - Hint
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号