Practical Learned Lossless JPEG Recompression with Multi-Level Cross-Channel Entropy Model in the DCT Domain
简介
JPEG是一种非常流行的压缩方法,然而最近关于图像压缩的研究主要集中在未压缩的PNG图像上,而忽略了数万亿已存在的JPEG图像。为了充分压缩这些JPEG图像,并在需要时将其恢复。这篇文章提出来基于深度学习的JPEG重压缩方法,在DCT域上进行操作,提出多级交叉通道熵模型来压缩信息量最大的Y分量。该方法压缩效果优于传统的再压缩方法。
该方法考虑YCbCr4:2:0格式的JPEG图像,具体而言首先为 YCbCr 4:2:0 格式构建了一个色彩空间熵模型,提取边信息 z 作为先验信息,建立三个分量的条件分布。 然后,进一步依次利用 Y、Cb 和 Cr 分量的相关性建立条件模型(即 Cb 分量以 Cr 为条件,Y 分量以 Cb 和 Cr 为条件),此外,由于 Y 分量的信息量远大于Cb 和Cr 分量,提出了针对 Y 分量的多级跨信道(MLCC)熵增强模型,以减少估计数据分布与真实数据分布之间的不匹配。
模型
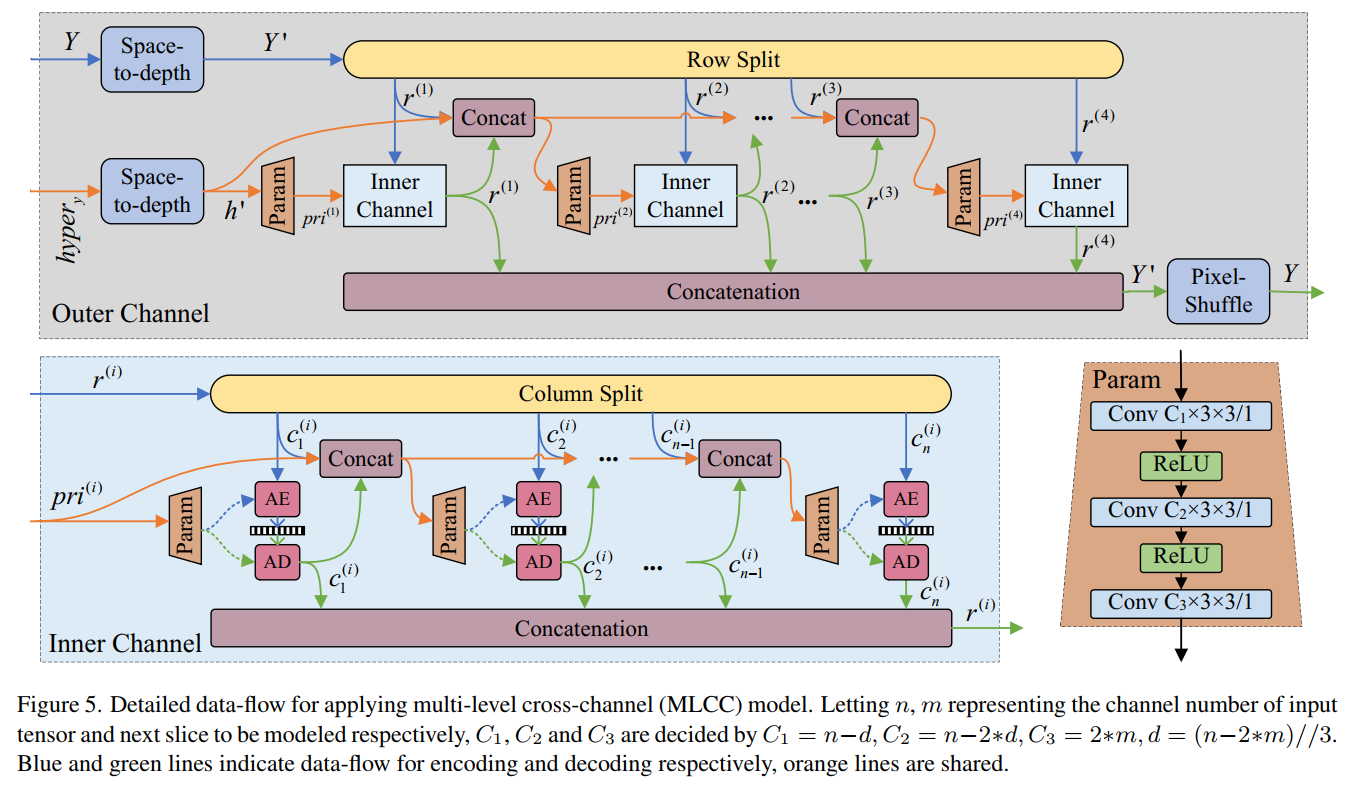
首先,重排每个8*8的DCT系数,以学习更好的分布。然后使用系数融合模型(CFM)对不同颜色成分的DCT系数进行形状对齐。最后将DCT系数发送到超编码器,产生超先验\(\hat{z}\),作为侧信息保存在比特流中。最后超先验\(\hat{z}\)经过超解码器和系数先验拆分模型(CPSM)后,将得到三个颜色分量的编码先验。
DCT Coefficients Rearrangement 将系数重排
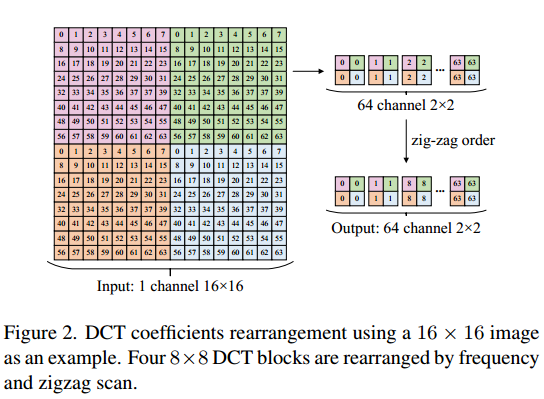
JPEG编码器将8*8的像素块转化为相同大小的DCT系数矩阵,矩阵中每个系数代表频率,左上角的为直流分量,其余63个为交流分量。如图2所示,我们重新排列DCT系数,
将所有块中相同频率的系数提取在一起构成空间维,不同频率的系数构成信道维。这一操作将 Y、Cb、Cr 分量转换分布转化为64个信道。
Cross-Color Entropy Model
对于跨色的相关性,可以隐式(通过共享超先验)和显式(通过熵参数网络)建模。
我们分别在hyperencoder和hyperdecoder中加入系数融合模型(CFM)和系数先验分割模型(CPSM)。CFM的架构如图3a所示,通过该架构对三种颜色分量进行重塑和融合。如图3b所示,利用CPSM对三种颜色分量的先验进行分割,得到通道先验Yprior、Cbprior和Crprior。
每个DCT系数元素都被建模为Laplace distribution(分布参数\(\mu\)和scale b)。Crprior,其实包括\(b_{cr}\)和\(\mu_{cr}\).因此,Cr通道元素的概率计算如下:
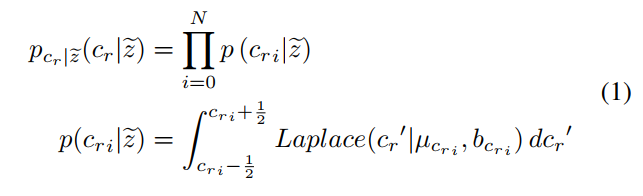
计算完Cr后,Cr 分量作为 Cb 分量的上下文被送到熵参数网络,并与 Cbprior 融合。模型的输出为\(b_{cb}\)和\(\mu_{cb}\).
因此,Cb是以超先验\(\tilde z\)和Cr为条件计算的。
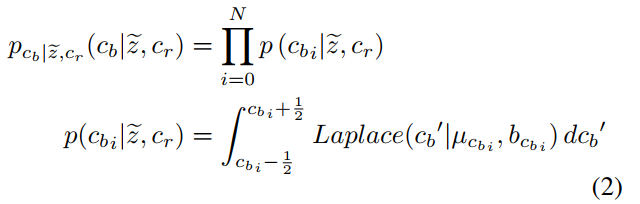
计算得到Cr和Cb后,它们被3*3步长为2转置卷积上采样,然后串联作为Y的上下文。它们和Yprior一起被送到熵参数网络中,从而得到\(hyper_y\),用来计算\(\ p_{y| \tilde{z},c_b,c_r}(y| \tilde{z}, c_b, c_r)\).
然而,这种类似于 Cr 和 Cb 分量的 PMF 对于信息量最大的 Y 分量来说还不够强大。在下一节中,我们提出了一种更合适的上下文建模方法(矩阵上下文模型),以进一步减少 Y 分量中的冗余。
Matrix Context Model
基于已解码的相邻符号精确预测未知符号概率分布
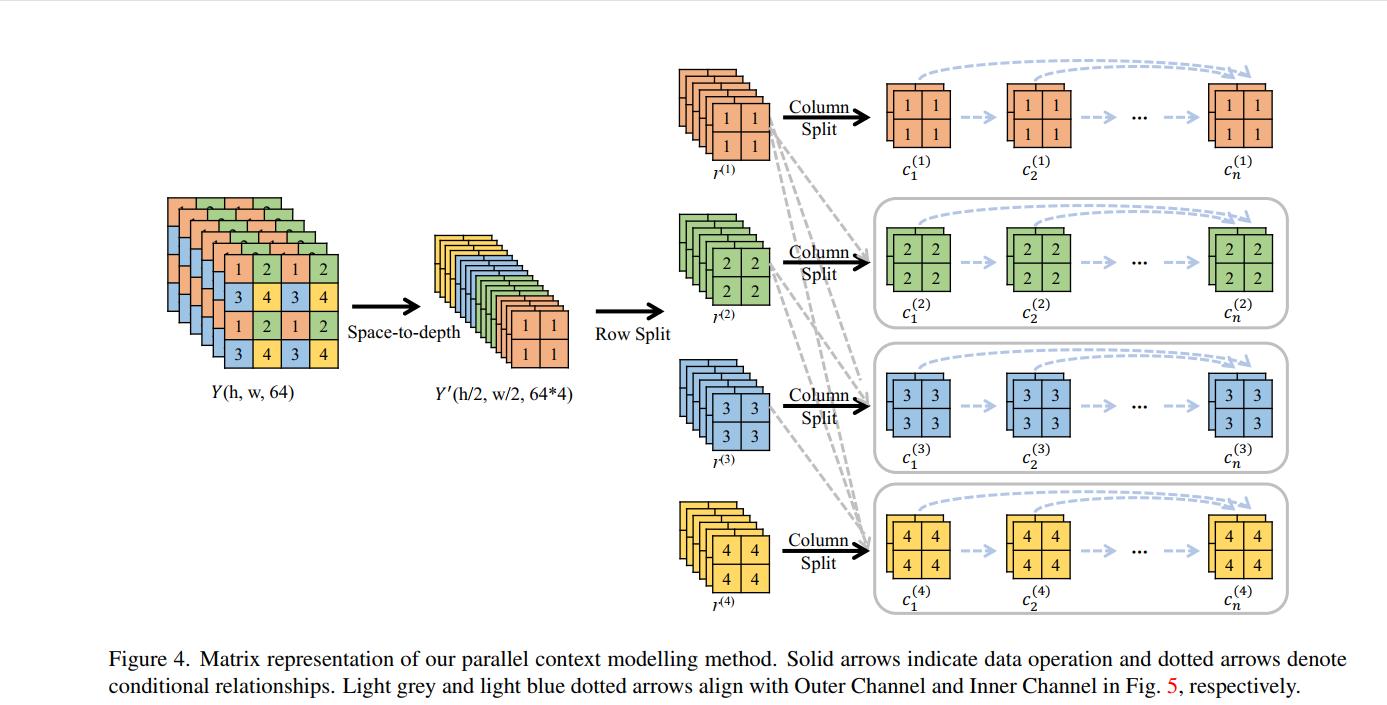
Multi-Level Cross-Channel Entropy Model
设计了一个多层交叉通道(MLCC)深度神经网络来实现我们的矩阵上下文熵模型,来估计拉普拉斯参数(µ and scale b), 沿着行的自回归模型视为外通道,沿着列的视为内通道。
MLCC利用矩阵上下文和$\ hyper_{y} $ 为Y学习更强大的PMF。
如图3.5所示,将$\ hyper_{y} $ space2depth重排得到$\ h^{'} $ 作为外通道的先验。而Y则如图3.4被分为四行。第一行仅以$\ h^{'} $ 为先验,生成prior pri(i)。接下来,prior pri(i)将与最近的 \(r^{(i)}\) 被送到内通道。
创新点
实验设置
由于我们的方法完全在DCT域中处理图像,因此在输入模型之前,我们使用orchjpeg.codec.quantize_at_quality以给定的JPEG质量水平提取量化的DCT系数,这保证了结果与使用从像Pillow这样的图像库生成的JPEG图像相同
训练数据集:
在ImageNet中选了8000张最大的图像(都在百万像素以上),每张图像加均匀噪声并下采样。
测试数据集:
Kodak的24张图像(png格式),DIV2K中的100张图像(png格式的测试集),CLIC professional中的250张图像,CLIC mobile中的178张图。 使用的是这些数据集的测试图像。
该方法完全在DCT域中处理。因此对原始图像,以给定的JPEG质量水平提取量化的DCT系数,然后再输入模型。
训练细节:
训练时,从训练数据中随机裁剪256 × 256像素块,然后提取量化的DCT系数。然后,所有的速度测试结果都是在单个Nvidia GeForce GTX 1060 6GB (GPU) {训练设备嘞?}
结果
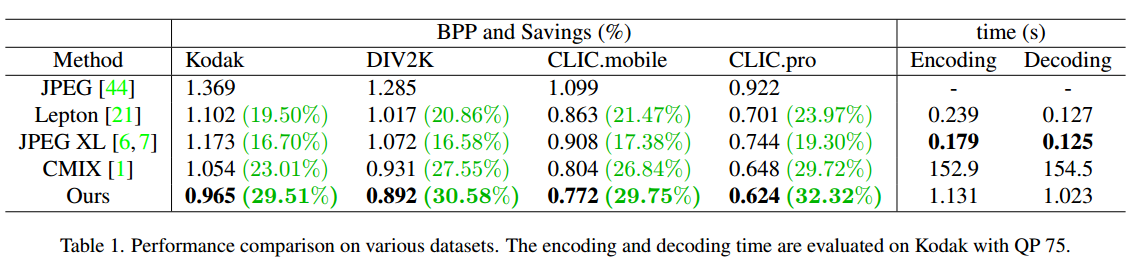
- 在四个测试数据集上与其他JPEG二次压缩方向对比,如表一所示,该重压缩方法在所有评估数据集上都能达到最低比特率,并能节省约 30% 的存储空间。方法比 CMIX 快得多,但比 JPEG XL 和 Lepton 慢
![image]()
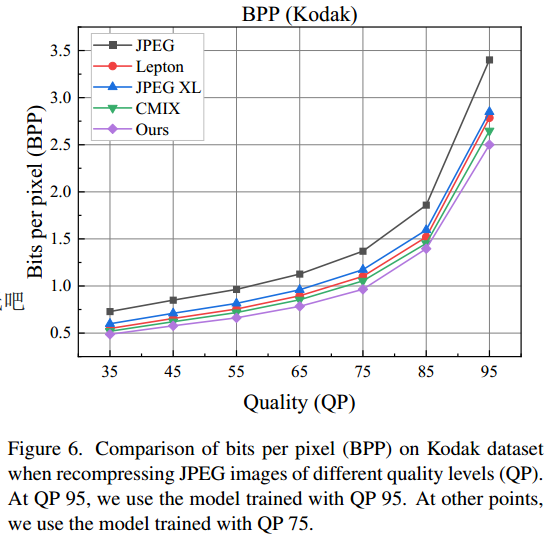
- 使用该重压缩模型在不同质量水平下进行测试:发现该模型的压缩能力仍然优于其他模型。
![image]()
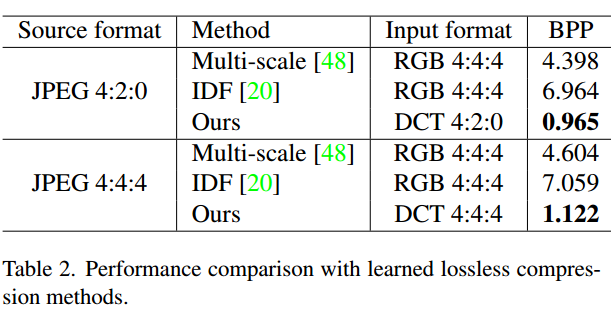
- 最后,作者使用重压缩模型与针对PNG图像直接压缩的无损深度学习方法进行了对比:
RGB444是
![image]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号