
读学生课程分数文件chapter4-data01.txt,创建DataFrame:
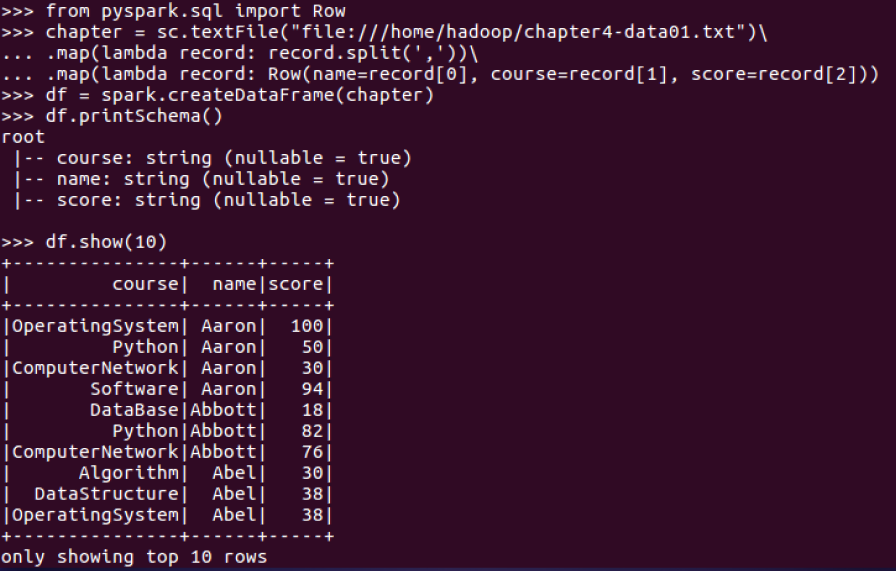
一、用DataFrame的操作或SQL语句完成以下数据分析要求,并和用RDD操作的实现进行对比:
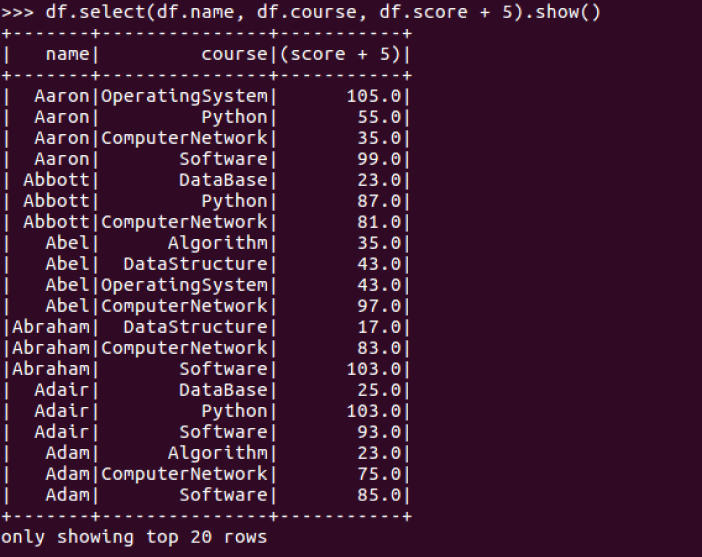
1.每个分数+5分。
2.总共有多少学生?

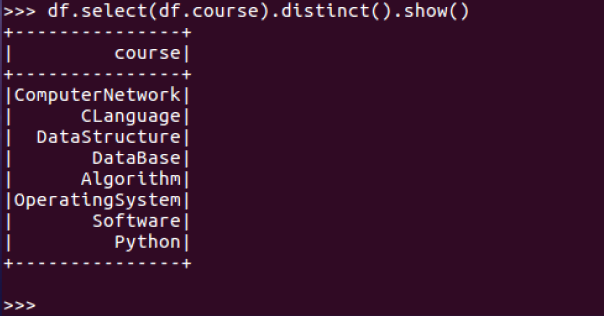
3.总共开设了哪些课程?
4.每个学生选修了多少门课?

5.每门课程有多少个学生选?

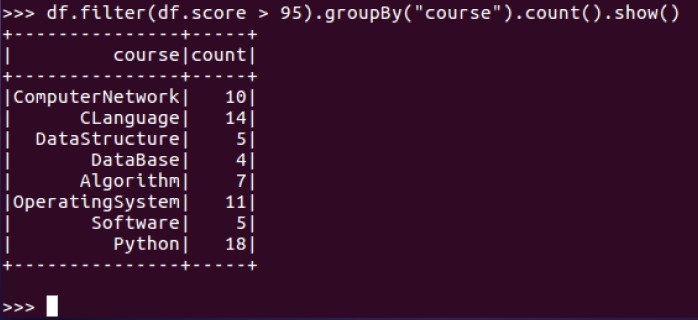
6.每门课程大于95分的学生人数?
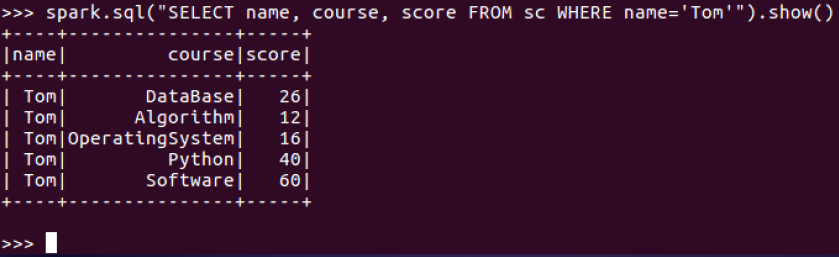
7.Tom选修了几门课?

8.Tom每门课多少分?
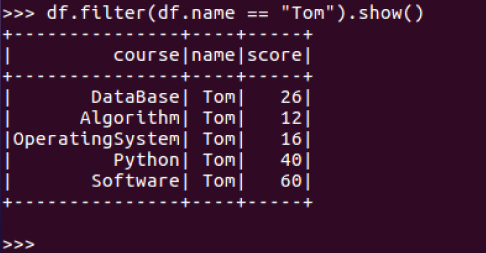
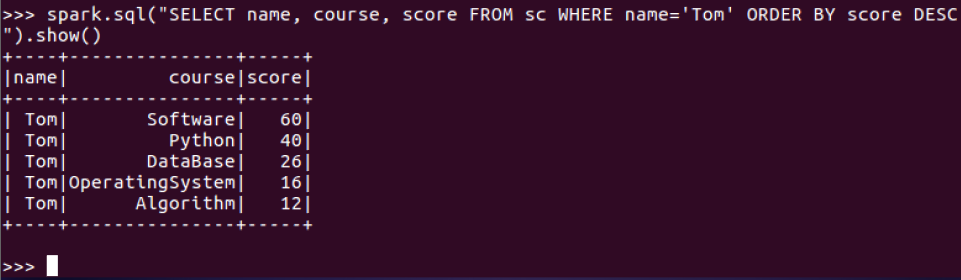
9.Tom的成绩按分数大小排序。
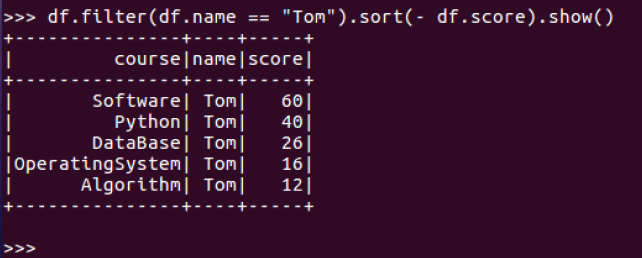
10.Tom的平均分。
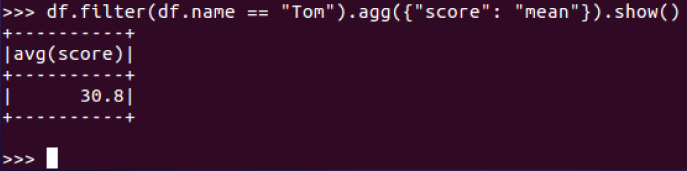
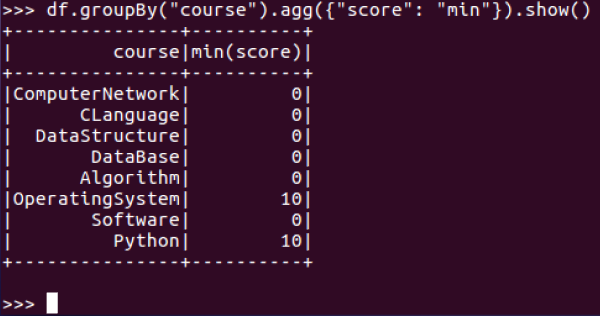
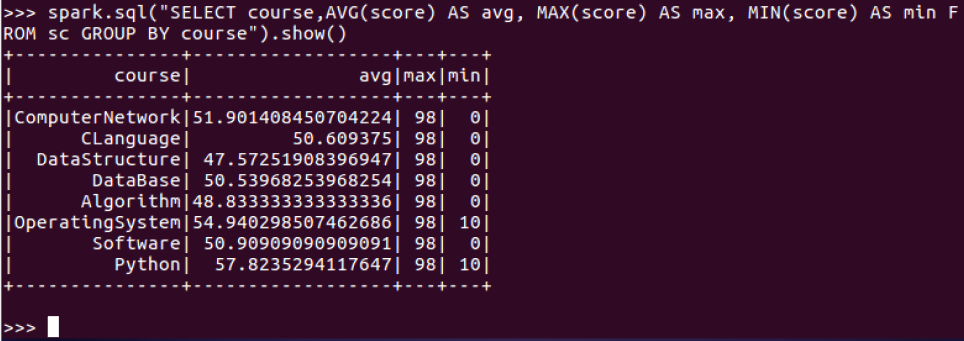
11.求每门课的平均分,最高分,最低分。
每门课的平均分:
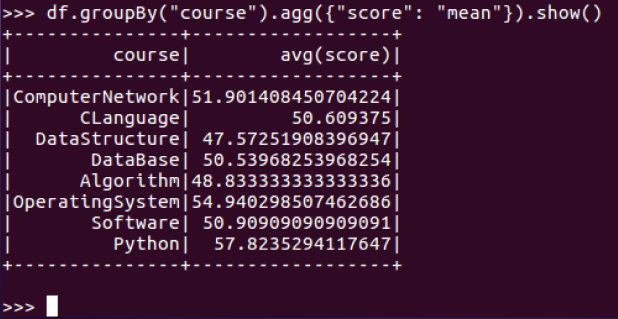
每门课的最高分:
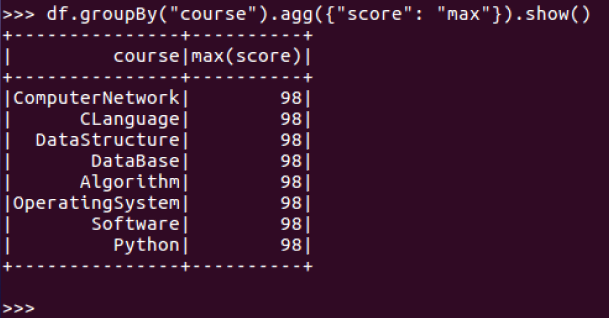
每门课的最低分:
12.求每门课的选修人数及平均分,精确到2位小数。

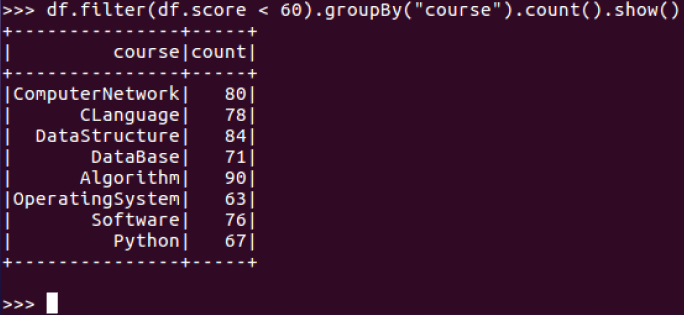
13.每门课的不及格人数,通过率
二、用SQL语句完成以上数据分析要求

1.每个分数+5分
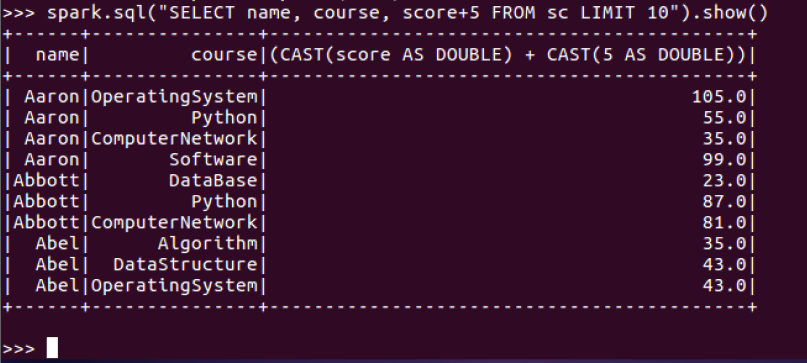
2.总共有多少学生?
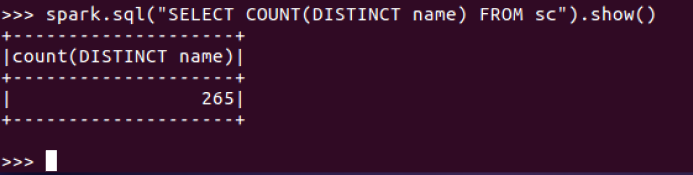
3.总共开设了哪些课程?
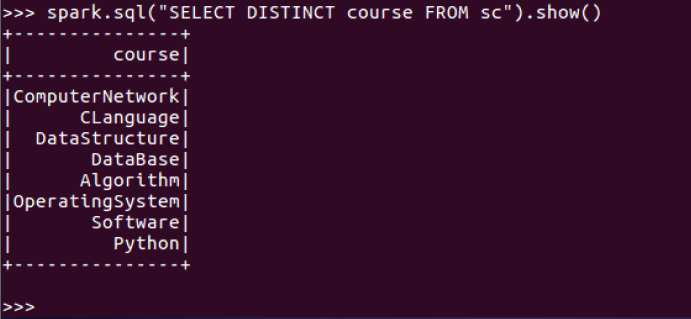
4.每个学生选修了多少门课?
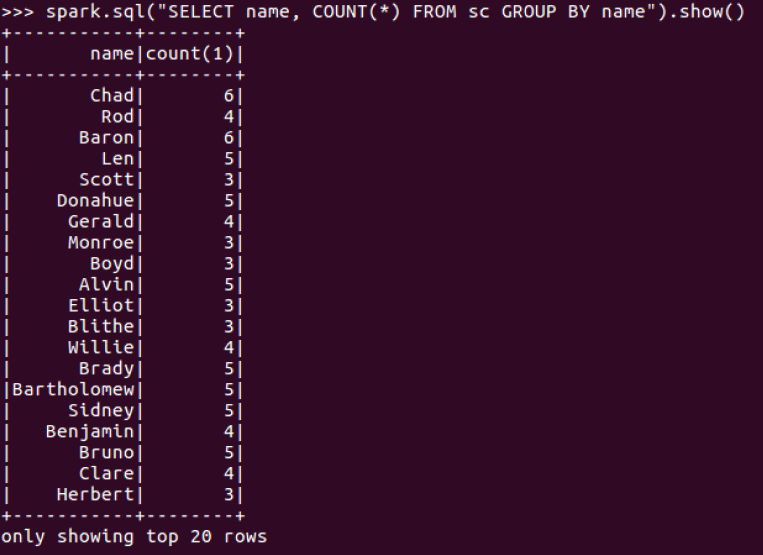
5.每门课程有多少个学生选?
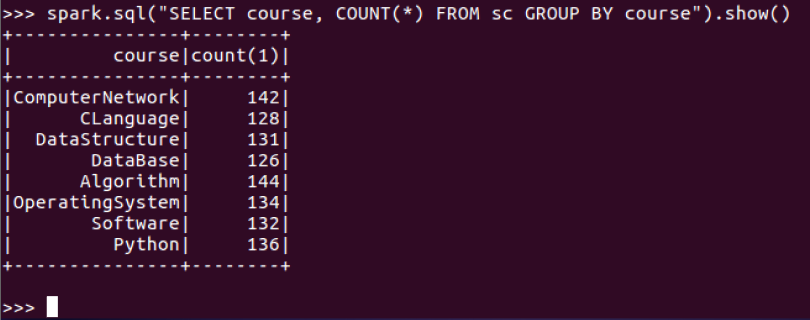
6.每门课程大于95分的学生人数?
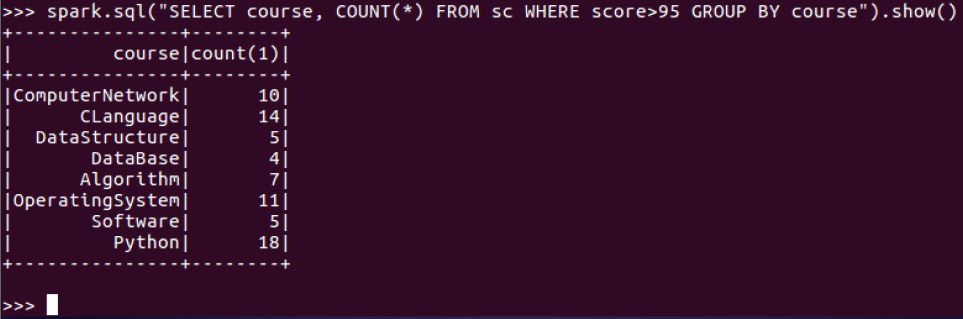
7.Tom选修了几门课?

8.每门课多少分?
9.Tom的成绩按分数大小排序
10.Tom的平均分

11.求每门课的平均分,最高分,最低分
12.求每门课的选修人数及平均分,精确到2位小数
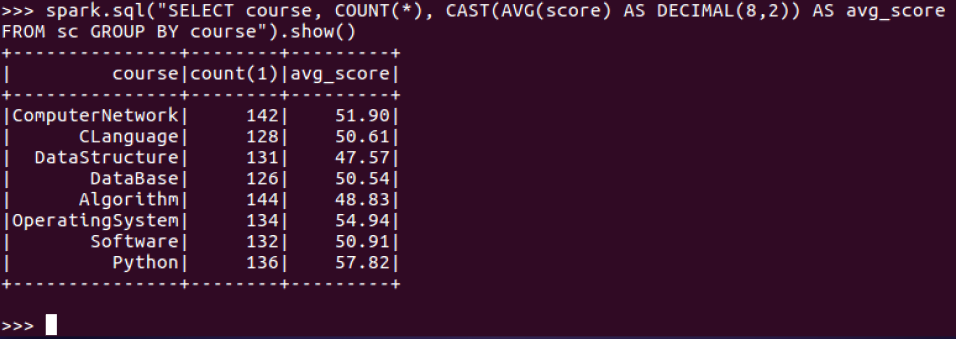
13.每门课的不及格人数

三、对比分别用RDD操作实现、用DataFrame操作实现和用SQL语句实现的异同。(比较两个以上问题)
RDD API是函数式的,强调不变性,在大部分场景下倾向于创建新对象而不是修改老对象。这一特点虽然带来了干净整洁的API,却也使得Spark应用程序在运行期倾向于创建大量临时对象,对GC造成压力。在现有RDD API的基础之上,我们固然可以利用mapPartitions方法来重载RDD单个分片内的数据创建方式,用复用可变对象的方式来减小对象分配和GC的开销,但这牺牲了代码的可读性,而且要求开发者对Spark运行时机制有一定的了解,门槛较高。另一方面,Spark SQL在框架内部已经在各种可能的情况下尽量重用对象,这样做虽然在内部会打破了不变性,但在将数据返回给用户时,还会重新转为不可变数据。
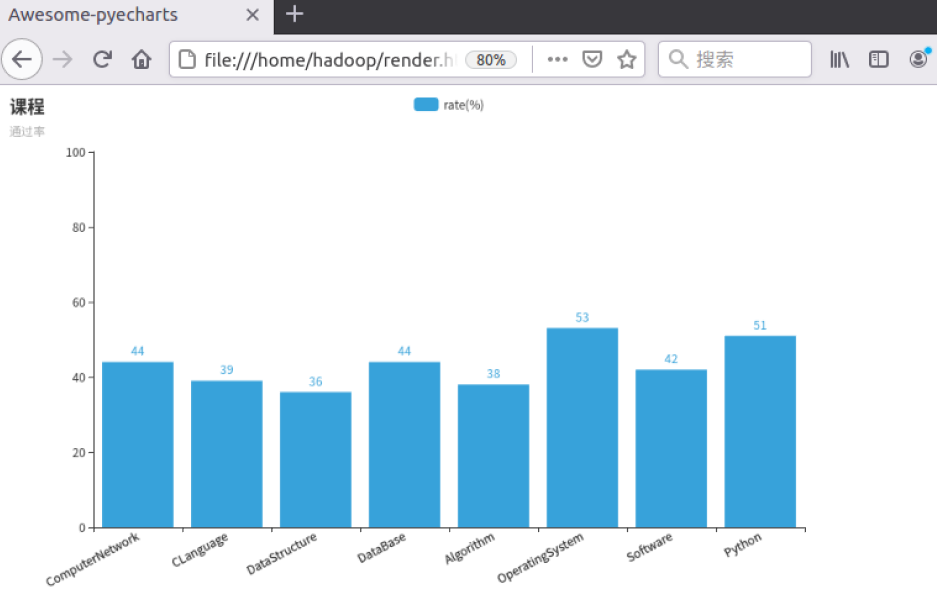
四、结果可视化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号