Java实现协同过滤算法
点赞或收藏指标的“隐形评分”算法实现
数据库层面的设计
在设计一个系统来记录收藏和点赞这两种用户行为作为评分指标时,你不需要创建一个传统的“评分”字段来存储一个具体的数字值(如1到5的评分)。相反,你可以使用两个独立的字段或表来分别跟踪收藏和点赞的数量或状态。
数据库的设计
用户表(Users)
- 用户ID(UserID,主键)
- 用户名(Username)
- 其他用户相关信息
物品表(Items)
- 物品ID(ItemID,主键)
- 物品名称(ItemName)
- 其他物品相关信息
收藏记录表(Favorites)
- 记录ID(RecordID,主键,自增)
- 用户ID(UserID,外键,引用Users表)
- 物品ID(ItemID,外键,引用Items表)
- 收藏时间(FavoriteTime,记录收藏的时间戳)
点赞记录表(Likes)
- 记录ID(RecordID,主键,自增)
- 用户ID(UserID,外键,引用Users表)
- 物品ID(ItemID,外键,引用Items表)
- 点赞时间(LikeTime,记录点赞的时间戳)
评分计算
在这个设计中,你没有一个直接的“评分”字段。相反,你可以通过计算收藏和点赞的数量来间接地得到某种形式的“评分”。例如:
- 收藏评分:对于某个物品,你可以通过查询Favorites表来计算有多少用户收藏了它。这个数量可以作为一个指标来表示物品的受欢迎程度。
- 点赞评分:同样地,对于某个物品,你可以通过查询Likes表来计算有多少用户点赞了它。这个数量也可以作为一个指标。
取消收藏和点赞
当用户取消收藏或点赞时,你应该从相应的表中删除对应的记录。这样,当你计算评分时,你会得到准确的收藏和点赞数量。
- 取消收藏:从Favorites表中删除具有特定用户ID和物品ID的记录。
- 取消点赞:从Likes表中删除具有特定用户ID和物品ID的记录。
注意事项
- 索引:为了提高查询效率,你应该在Favorites和Likes表的用户ID和物品ID字段上创建索引。
- 一致性:确保在用户进行收藏、点赞、取消收藏或取消点赞操作时,数据库的状态保持一致。这可能需要使用事务来确保操作的原子性。
- 扩展性:如果你的系统需要支持更多的用户行为作为评分指标(如评论、分享等),你可以按照类似的模式添加更多的记录表。
总之,通过分别跟踪收藏和点赞的数量,你可以得到一种形式的“评分”,这种评分反映了用户对物品的喜爱程度和物品的受欢迎程度。当用户取消收藏或点赞时,你应该从相应的表中删除记录以保持数据的准确性。
代码层面的操作
在Java中实现协同过滤(Collaborative Filtering)算法,基于你提供的数据库设计(用户表、物品表、收藏记录表、点赞记录表),通常涉及以下几个步骤:
- 数据准备:从数据库中提取用户-物品交互数据(收藏和点赞)。
- 构建用户-物品矩阵:根据提取的数据,构建一个表示用户与物品之间交互的矩阵。
- 计算相似度:使用某种相似度度量(如余弦相似度、皮尔逊相关系数等)来计算用户或物品之间的相似度。
- 生成推荐:基于相似度矩阵,为目标用户生成推荐列表。
以下是一个简化的Java代码示例,展示了如何开始这个过程。请注意,这个示例省略了数据库连接和查询的具体实现,因为那将依赖于你使用的具体数据库和Java持久化框架(如JDBC、Hibernate等)。
java复制代码
import java.util.*;
import java.util.stream.Collectors;
// 假设我们已经有了一个方法从数据库中提取数据
// Map<UserID, Set<ItemID>> getUserFavorites(Collection<UserID> userIDs);
// Map<UserID, Set<ItemID>> getUserLikes(Collection<UserID> userIDs);
// 示例数据(在实际应用中,这些数据将从数据库中提取)
Map<Integer, Set<Integer>> favorites = new HashMap<>();
Map<Integer, Set<Integer>> likes = new HashMap<>();
// 填充示例数据
favorites.put(1, new HashSet<>(Arrays.asList(101, 102)));
favorites.put(2, new HashSet<>(Arrays.asList(102, 103)));
likes.put(1, new HashSet<>(Arrays.asList(101, 104)));
likes.put(2, new HashSet<>(Arrays.asList(103, 104)));
// 合并收藏和点赞为用户-物品交互矩阵
Map<Integer, Set<Integer>> userItemInteractions = new HashMap<>();
for (Map.Entry<Integer, Set<Integer>> entry : favorites.entrySet()) {
int userID = entry.getKey();
Set<Integer> items = entry.getValue();
userItemInteractions.putIfAbsent(userID, new HashSet<>());
userItemInteractions.get(userID).addAll(items);
}
for (Map.Entry<Integer, Set<Integer>> entry : likes.entrySet()) {
int userID = entry.getKey();
Set<Integer> items = entry.getValue();
userItemInteractions.putIfAbsent(userID, new HashSet<>());
userItemInteractions.get(userID).addAll(items);
}
// 计算用户相似度(以余弦相似度为例)
Map<Integer, Map<Integer, Double>> userSimilarity = new HashMap<>();
for (int userID1 : userItemInteractions.keySet()) {
Set<Integer> items1 = userItemInteractions.get(userID1);
userSimilarity.put(userID1, new HashMap<>());
for (int userID2 : userItemInteractions.keySet()) {
if (userID1 != userID2) {
Set<Integer> items2 = userItemInteractions.get(userID2);
Set<Integer> commonItems = new HashSet<>(items1);
commonItems.retainAll(items2);
double numerator = commonItems.size();
double denominator = Math.sqrt(items1.size() * items2.size());
double similarity = numerator / denominator;
userSimilarity.get(userID1).put(userID2, similarity);
}
}
}
// 基于用户相似度生成推荐(这里只是一个简单的示例,没有考虑性能优化)
int targetUserID = 1; // 假设我们要为用户ID为1的用户生成推荐
Set<Integer> recommendedItems = new HashSet<>();
for (Map.Entry<Integer, Double> entry : userSimilarity.get(targetUserID).entrySet()) {
int similarUserID = entry.getKey();
double similarity = entry.getValue();
Set<Integer> similarUserItems = userItemInteractions.get(similarUserID);
for (int itemID : similarUserItems) {
if (!userItemInteractions.get(targetUserID).contains(itemID)) {
recommendedItems.add(itemID);
}
}
// 这里可以根据相似度对推荐物品进行排序或过滤(例如,只选择相似度高于某个阈值的物品)
}
// 输出推荐结果
System.out.println("Recommended items for user " + targetUserID + ": " + recommendedItems);
注意:
- 这个示例代码没有处理数据库连接和查询,你需要根据自己的数据库设计来实现这部分逻辑。
- 相似度计算部分使用了简单的余弦相似度公式,但实际应用中可能需要更复杂的相似度度量方法。
- 推荐生成部分只是一个简单的示例,没有考虑性能优化和推荐质量提升的策略(如考虑时间因素、物品流行度等)。
- 在实际应用中,你还需要处理冷启动问题(即新用户或新物品没有足够交互数据的情况)。
这个示例代码提供了一个基本的框架,你可以在此基础上进行扩展和优化,以适应你的具体需求。
这种形式的一些介绍
在上述Java代码示例中,我们并没有直接处理一个显式的“评分”字段。相反,我们基于用户的收藏和点赞行为构建了一个用户-物品交互矩阵,然后计算了用户之间的相似度,并基于这些相似度生成了推荐。这里的“评分”概念是隐含的,体现在用户对物品的收藏和点赞行为上。
这些行为可以被视为用户对物品的正面反馈,类似于在传统推荐系统中用户给物品打分(如1到5星)的行为。然而,在这个例子中,我们没有将收藏和点赞转换为具体的数字评分,而是直接使用了这些行为的存在与否来构建交互矩阵。因此,这个示例中的数据可以被视为一种“隐式反馈”数据,而不是传统的“显式评分”数据。隐式反馈数据通常更容易从用户行为中收集,但也可能更难以准确解释和建模,因为不同用户可能对同一行为有不同的解释或重视程度。
在实际应用中,你可能需要根据自己的业务需求和用户行为特点来选择使用隐式反馈还是显式评分数据,或者结合两者来构建推荐系统。
(教程使用的方式)用户-物品评分实现(Apache Mahut)
下边提供的<font style="color:#000000;background-color:rgb(253, 253, 254);">MahoutUtils</font>类中的<font style="color:#000000;background-color:rgb(253, 253, 254);">recommender</font>方法实现了一个基于用户的协同过滤(User-Based Collaborative Filtering)算法。这是通过以下步骤和组件来体现的:
- 数据准备:
- 方法接受一个
<font style="color:#000000;background-color:rgb(253, 253, 254);">List<RatingDTO></font>作为输入,这个列表包含了用户对物品的评分信息。 - 这些评分信息被转换成
<font style="color:#000000;background-color:rgb(253, 253, 254);">Preference</font>对象,并添加到一个列表中。
- 方法接受一个
- 构建数据模型:
- 使用
<font style="color:#000000;background-color:rgb(253, 253, 254);">buildDataModel</font>方法,将<font style="color:#000000;background-color:rgb(253, 253, 254);">Preference</font>列表转换成一个<font style="color:#000000;background-color:rgb(253, 253, 254);">DataModel</font>对象。这个模型是Apache Mahout推荐算法所需的输入格式。 - 在
<font style="color:#000000;background-color:rgb(253, 253, 254);">buildDataModel</font>方法中,偏好被按用户ID分组,并存储在一个<font style="color:#000000;background-color:rgb(253, 253, 254);">FastByIDMap<PreferenceArray></font>中,其中每个<font style="color:#000000;background-color:rgb(253, 253, 254);">PreferenceArray</font>包含了特定用户的所有偏好。
- 使用
- 计算用户相似度:
- 使用
<font style="color:#000000;background-color:rgb(253, 253, 254);">PearsonCorrelationSimilarity</font>类来计算用户之间的相似度。Pearson相关系数是一种衡量两个变量之间线性相关程度的统计量,在这里用于衡量用户偏好之间的相似性。
- 使用
- 选择邻居用户:
- 使用
<font style="color:#000000;background-color:rgb(253, 253, 254);">NearestNUserNeighborhood</font>类来选择与目标用户最相似的邻居用户。这里指定了邻居数量为2(尽管在实际应用中,这个值可能需要根据具体情况进行调整)。
- 使用
- 生成推荐:
- 使用
<font style="color:#000000;background-color:rgb(253, 253, 254);">GenericUserBasedRecommender</font>类,结合之前构建的数据模型、用户相似度和邻居用户信息,来为目标用户生成推荐。 - 调用
<font style="color:#000000;background-color:rgb(253, 253, 254);">recommend</font>方法,传入目标用户ID和推荐的物品数量,返回一个<font style="color:#000000;background-color:rgb(253, 253, 254);">List<RecommendedItem></font>,包含了推荐给目标用户的物品列表。
- 使用
我们的实现是基于Apache Mahout库中的组件,采用Pearson相关系数作为相似度度量(皮尔逊相关系数),通过选择与目标用户最相似的邻居用户来为目标用户生成推荐的基于用户的协同过滤算法。
实现步骤
依赖
- pom.xml文件里边,导入Apache Mahut的项目依赖。
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>14.1</version>
</dependency>
实体类
定义评分的DTO类(用到了Lombok插件),三项属性:用户ID、物品ID、评分:
package cn.kmbeast.entity.dto;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* 评分DTO类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class RatingDTO {
/**
* 用户ID
*/
private Integer userId;
/**
* 物品ID
*/
private Integer itemId;
/**
* 评分
*/
private Integer score;
}
工具类
package cn.kmbeast.utils;
import cn.kmbeast.entity.dto.RatingDTO;
import lombok.extern.slf4j.Slf4j;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.impl.common.FastByIDMap;
import org.apache.mahout.cf.taste.impl.model.GenericDataModel;
import org.apache.mahout.cf.taste.impl.model.GenericItemPreferenceArray;
import org.apache.mahout.cf.taste.impl.model.GenericPreference;
import org.apache.mahout.cf.taste.impl.model.GenericUserPreferenceArray;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.model.Preference;
import org.apache.mahout.cf.taste.model.PreferenceArray;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.UserBasedRecommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* Mahout工具类,用以实现协同过滤推荐
*/
@Slf4j
public class MahoutUtils {
/**
* 为用户生成指定推荐的用户参数
*
* @param ratingDTOS 评分实体,描述的是什么用户(用户ID)对什么物品(物品ID)进行了怎样的评分(分值)
* @param targetUserId 被推荐者用户ID:向谁推荐的,就是本次调用查看者
* @param targetItems 推荐的物品条数
* @return List<RecommendedItem> 返回的推荐列表
*/
public static List<RecommendedItem> recommender(List<RatingDTO> ratingDTOS,
Long targetUserId,
int targetItems) {
List<Preference> preferences = new ArrayList<>();
for (RatingDTO ratingDTO : ratingDTOS) {
long userId = ratingDTO.getUserId().longValue(); // 确保转换为Long类型
long itemId = ratingDTO.getItemId().longValue(); // 确保转换为Long类型
float score = ratingDTO.getScore();
preferences.add(new GenericPreference(userId, itemId, score));
}
try {
DataModel model = buildDataModel(preferences);
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(2, similarity, model);
UserBasedRecommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);
return recommender.recommend(targetUserId, targetItems);
} catch (TasteException e) {
e.printStackTrace();
return Collections.emptyList();
}
}
private static DataModel buildDataModel(List<Preference> preferences) throws TasteException {
Map<Long, List<Preference>> groupedByUserID = preferences.stream()
.collect(Collectors.groupingBy(Preference::getUserID));
FastByIDMap<PreferenceArray> userPreferences = new FastByIDMap<>();
for (Map.Entry<Long, List<Preference>> entry : groupedByUserID.entrySet()) {
Long userID = entry.getKey();
List<Preference> userPrefs = entry.getValue();
PreferenceArray preferenceArray = new GenericUserPreferenceArray(userPrefs);
userPreferences.put(userID, preferenceArray);
}
return new GenericDataModel(userPreferences);
}
}
使用
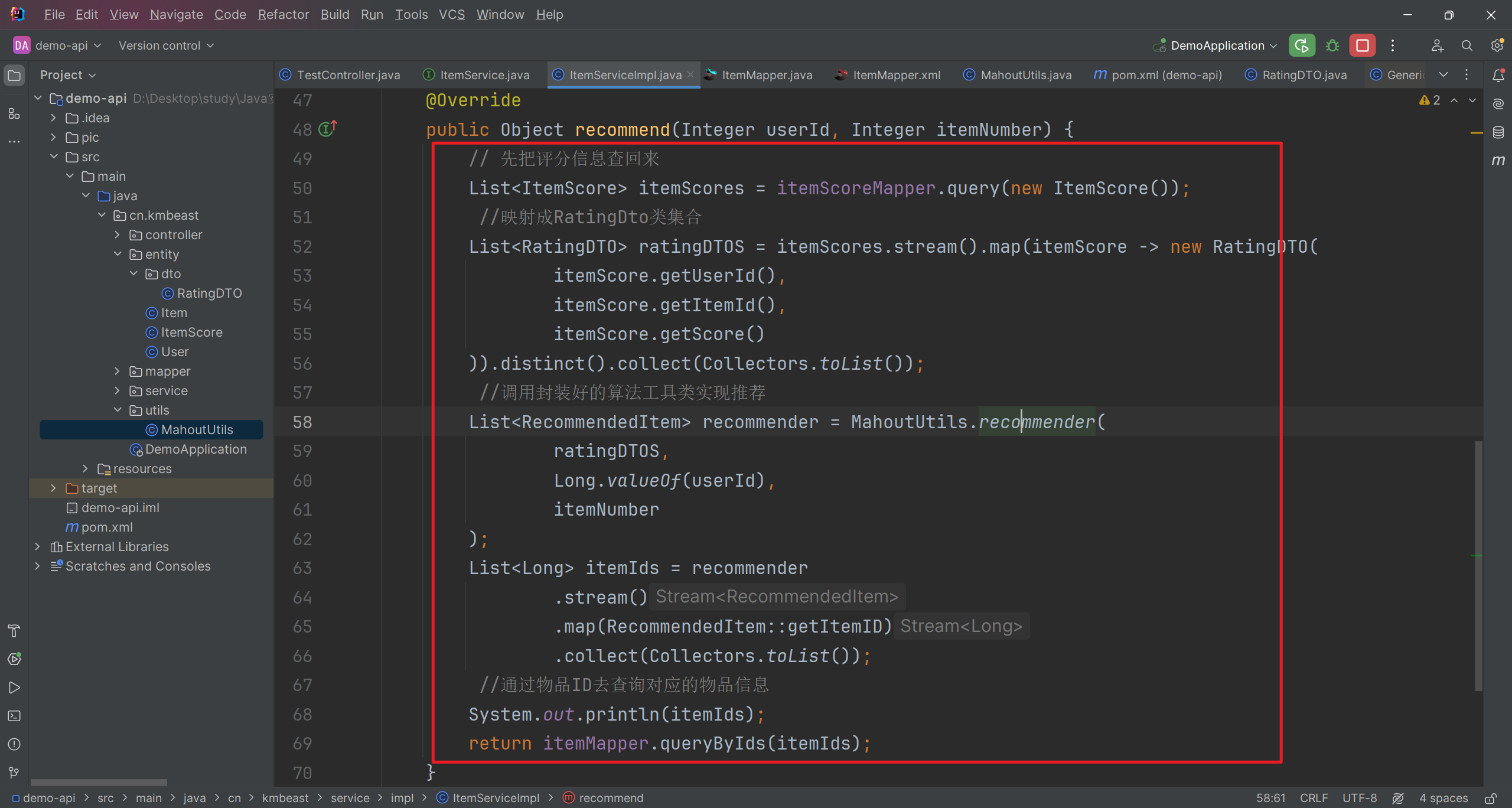
- 将用户对于物品的评分查询回来,转成List
集合 - 调用算法工具类,结果返回推荐的物品ID集合(依赖大的数据集,回来的可能为空)。
- 拿着ID去查询指定的物品信息返回即可。(如果算出来没有,可以默认推最新的数据)
可能的情况
一、返回结果为空的处理
- 检查数据完整性:
- 确保用户-物品评分矩阵或其他相关数据集是完整的,没有缺失值或异常值。
- 检查数据预处理步骤,确保没有误删或误改数据。
- 调整相似度计算方法:
- 协同过滤算法的核心是计算相似度。如果当前使用的相似度计算方法(如余弦相似度、皮尔逊相关系数等)效果不佳,可以尝试更换其他方法。
- 调整相似度计算中的参数,如阈值、权重等,以优化结果。
- 增加数据集:
- 如果数据集过小,可能导致算法无法有效学习用户或物品之间的相似性。此时,可以尝试增加数据集的大小,以提高算法的准确性。
- 处理冷启动问题:
- 对于新用户或新物品,由于缺乏历史数据,协同过滤算法可能无法为其推荐合适的物品。此时,可以考虑使用基于内容的推荐或其他混合推荐策略来补充。(推荐直接查询热度最高的物品替代)
二、返回结果数量不满足指定要求的处理
- 调整推荐策略:
- 根据实际需求调整推荐策略。例如,如果希望返回更多结果,可以放宽相似度阈值或增加推荐物品的多样性。
- 如果希望返回的结果更加精准,可以收紧相似度阈值并增加对推荐结果的筛选条件。
- 使用Top-N推荐:
- 在协同过滤算法的基础上,结合Top-N推荐策略。即根据计算出的相似度或评分,选择前N个最相似的物品或用户进行推荐。
- 可以通过调整N的值来控制返回结果的数量。
- 结合其他推荐算法:
- 如果协同过滤算法单独使用时效果不佳,可以考虑结合其他推荐算法(如基于内容的推荐、关联规则推荐等)来提高推荐效果。
- 通过混合推荐策略,可以充分利用各种算法的优势,提高推荐的准确性和多样性。
- 优化算法实现:
- 对算法实现进行优化,提高计算效率和准确性。例如,使用更高效的数据结构来存储和计算相似度矩阵。
- 对算法进行并行化处理,以缩短计算时间并提高响应速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号