
任务7
一、数据存在缺失
1、删除相应的属性,即删掉整个列 —— 适用于对于某一个特征存在很多缺失值的时候删除相应的记录(但如果一个特征中只有几个样本缺失了这条特征,全部删掉整个列 等同于完全放弃此特征)
2、删除相应的记录,若一个记录里包含了缺失值,就舍弃该记录。这种方法也简单且直接,也是平时工程里常用的方法,实现起来也非常简单,但是若许多数据都出现缺失值,则要舍弃大量记录,使得样本数据量急剧变小,从而影响后续建模的效果
3、填补法 —— 尝试着用一个新的值来填补缺失值。对于数值型变量,常常使用平均值来填补缺失值(平均法则),也可以使用中位数填补。但是填补法所填的数据对当前样本来说可能不太合理
二、特征编码技术
机器学习的基础是数据,若一个模型的输入是字符串,则需要转化成数值型(如向量或矩阵形式),这个过程叫特征编码
类别特征:特征值之间没有大小关系,而且只代表某一种类别。 针对类别特征的最常用编码技术是独热编码(one-hot encoding)
标签编码:把一个类别表示成一个数值,比如0,1,2,3…. 但是,不可以直接将标签编码作为特征输入到模型里,因为数与数之间是有大小关系的,而且这些大小相关的信息必然会用到模型当中,这与原来特征的特点产生了矛盾,对于深度学习,数据分析来说它们之间并不存在所谓的“大小”,可以理解为平行关系。所以对于这类特征来说,直接用0,1,2.. 的方式来表示是存在问题的,所以用独热编码来表达一个类别性特征
独热编码:在标签特征的基础上创建一个向量,向量的长度跟类别种类的个数相同。除了一个位置是1,其他位置均为0, 1的位置对应的是相应类别出现的位置
例:标签编码——大专:0 , 本科:1, 硕士:2, 博士:3, 大专:4, 独热编码——本科:(1,0,0,0), 硕士:(0,0,1,0), 博士:(0,0,0,1)
而数值型变量直接使用,无需编码,或者做必要的标准化操作,让变量具有类似的取值范围。但是,有时因为算法的需要 或 克服数据的缺陷,变量需要离散化,离散化的数据也更容易理解
参考:https://www.cnblogs.com/zongfa/p/9434418.html
还有一个种类型的特征叫做顺序(ordinal)变量。最经典的例子就是问卷调查中用户的评价,比如非常满意,满意,一般,不满意等, 或者我们在购买物品之后给商品评价3颗星,还是4颗星…,它们每一种值都有大小的关系,也就是程度上的好坏之分,所以常常把这些变量直接看作是数值型变量来处理
三、KNN解决回归
案例:基于二手车辆的状况来估计它的实际市场价格
1、使用read_csv读取数据, 并显示数据内容
import pandas as pd
shc=pd.read_csv('二手车价格.csv')
print (shc)
运行结果:

或:
with open("二手车价格.csv") as file: for line in file: print (line)
2、特征处理
df=pd.DataFrame(shc)
df_colors=df['Color'].str.get_dummies().add_prefix('Color: ') #将颜色独热编码
df_type=df['Type'].apply(str).str.get_dummies().add_prefix('Type: ') #将类型独热编码
df=pd.concat([df,df_colors,df_type],axis=1) #添加独热编码数据列
df=df.drop(['Brand','Type','Color'],axis=1) #删去独热编码对应的原始列
print(df)
运行结果:

pd.DataFrame() 创建DataFrame
DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表 参考:https://www.cnblogs.com/IvyWong/p/9203981.html
df['Color'] #选取Color列所有数据 参考:https://www.cnblogs.com/chenhuabin/archive/2019/03/06/10485549.html https://blog.csdn.net/Arwen_H/article/details/81516204
df['Color'].str.get_dummies() #pandas.Series.str.get_dummies拆分series中以"|"分隔的字符串,然后返回一个DataFrame对象
参考:https://blog.csdn.net/w1301100424/article/details/99105668 https://www.cnblogs.com/wyy1480/p/10295084.html
add_prefix() #带有字符串前缀的前缀标签,对于Series,行标签是前缀的。对于DataFrame,列标签是前缀的。

参考:https://www.cjavapy.com/article/276/
df['Color'].str.get_dummies().add_prefix('Color') #选取Color列的数据,并增加列标签前缀“Color”
apply()
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds) 第一个参数是函数,apply函数会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。 参考:https://blog.csdn.net/yanjiangdi/article/details/94764562
df['Type'].apply(str) #将Type转换成字符型
pd.concat() 将数据根据不同的轴作简单的融合
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False)
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列
参考:https://www.jb51.net/article/164905.htm
pd.concat([df,df_colors,df_type],axis=1) #将 df,df_colors,df_type 以行对齐(axis=1)的方式合并
df.drop()
删除表中的某一行或者某一列更明智的方法是使用drop,它不改变原有的df中的数据,而是返回另一个dataframe来存放删除后的数据.drop函数默认删除行,列需要加axis = 1
参考:https://blog.csdn.net/nuaadot/article/details/78304642
3.查看数据特征之间的相关性
matrix = df.corr() f,ax = plt.subplots(figsize=(8,6)) sns.heatmap(matrix,square=True) plt.title('Car Price Variables')
运行结果:

DataFrame.corr() 计算列的成对相关性
参考:https://www.cjavapy.com/article/351/
seaborn.heatmap() 可视化已经有的数字
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
data:数据
square:是否是正方形
4、特征的归一化,把原始特征转换成均值为0方差为1的高斯分布
注:特征的归一化的标准一定要来自于训练数据,应用于测试数据。因为实际上我们无法统计到测试数据的均值和方差
from sklearn.neighbors import KNeighborsRegressor from sklearn.model_selection import train_test_split from sklearn import preprocessing from sklearn.preprocessing import StandardScaler import numpy as np X = df[['ConsTructionYear','DaysUntil MOT','Odometer']] y = df['AskPrice'].value.reshape(-1,1) X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=1) #测试集比例为30% X_normalizer = StandardScaler() X_train = X_normalizer.fit_transform(X_train) X_test = X_normalizer.transform(X_test) y_normalizer = StandardScaler() y_train = y_normalizer.fit_transform(y_train) y_test = y_normalizer.transform(y_test)
data.reshape(-1,1)
我们不知道data的shape属性是多少,但是想让data变成只有一列,行数不知道多少,通过data.reshape(-1,1),Numpy自动计算出有几行
StandardScaler() 用来将数据进行归一化和标准化的类
计算训练集的平均值和标准差,以便测试数据集使用相同的变换。
所谓归一化和标准化,即应用下列公式:
使得新的X数据集方差为1,均值为0
这时对于X_test,我们就可以直接使用transform方法。因为此时StandardScaler已经保存了X_train的
5、训练KNN模型,并用KNN模型做预测
knn = KNeighborsRegressor(n_neighbors=2) knn.fit(X_train,y_train.ravel()) y_pred = knn.predict(X_test) y_pred_inv = y_normalizer. inverse_transform(y_pred) y_test_inv=y_normalizer.inverse_transform(y_test) plt.scatter(y_pred_inv,y_test_inv) plt.xlabel('prediction') plt.ylabel('Realvalue') diagonal=np.linspace(500,1500,100) plt.plot(diagonal,diagonal,'r') plt.xlabel('Predicted ask price') plt.ylabel('Ask price') plt.show()
运行结果:
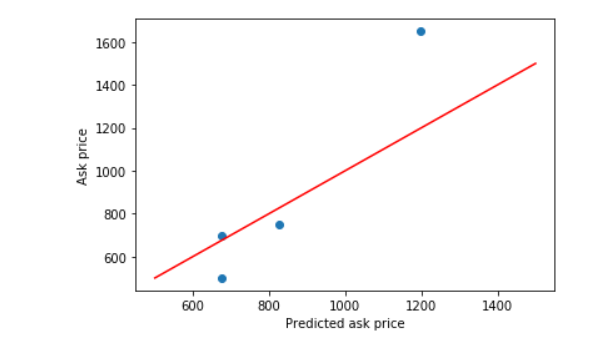
ravel() 和 flatten() Numpy中经常使用到的操作由扁平化操作。功能相同,但在内存上有很大的不同 参考:https://www.cnblogs.com/mzct123/p/8659193.html
ravel()返回的是一个数组的视图
使用过程中flatten()分配了新的内存
predict()
接收输入的 数组类型 测试样本,一般是二维数组,每一行是一个样本,每一列是一个属性。返回数组类型的预测结果,如果每个样本只有一个输出,则输出为一个一维数组。如果每个样本的输出是多维的,则输出二维数组,每一行是一个样本,每一列是一维输出
inverse_transform()
将标准化后的数据转换为原始数据
plt.scatter() 绘制简单散点图
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, verts=None, edgecolors=None, *, data=None, **kwargs)
x, y是相同长度的数组序列,作为输入的数据
参考:https://blog.csdn.net/qiu931110/article/details/68130199
np.linspace() 用于创建等差数列
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
start: 返回样本数据开始点
stop: 返回样本数据结束点
num: 生成的样本数据量,默认为50
endpoint:True则包含stop;False则不包含stop
retstep:If True, return (samples, step), where step is the spacing between samples.(即如果为True则结果会给出数据间隔)
dtype:输出数组类型
axis:0(默认)或-1
返回值:在闭区间[start, stop]或者是半开区间[start, stop)中有num个等间距的样本
参考:https://blog.csdn.net/Asher117/article/details/87855493
plt.plot()
plt.plot(x,y,format_string,**kwargs)
x轴数据,y轴数据,format_string控制曲线的格式字串
format_string 由颜色字符,风格字符,和标记字符
参考:https://blog.csdn.net/u014539580/article/details/78207537
四、KD树( K-dimension tree)
假如有N个样本,而且每个样本的特征为D维的向量。那对于一个目标样本的预测,需要的时间复杂度是为 O(N*D)
提升KNN搜索效率
1、从每一个类别里选出具有代表性的样本 —— 对于每一个类的样本做聚类
2、在搜索的过程会做一些近似运算来提升效率,但同时也会牺牲一些准确率
3、使用KD树 (一般只适合用在低维的空间)
k-d树是一种空间划分树,即把整个空间划分为特定的几个部分,然后在特定空间的部分内进行相关搜索操作。这样的好处是一个区域里的样本互相离得比较近。对于一个新的预测样本,首先来判定这个预测样本所在的区域,而且离它最近的样本很有可能就在这个区域里面。这里的每一个区域在KD树里是一个节点。本质上说,Kd-树就是一种平衡二叉树
KD树的经典应用场景:在地图上的搜索。如搜索离当前点最近的加油站、餐馆 等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号