
102302106-陈昭颖-第四次作业
作业1
实验一:爬取3个板块的股票信息
要求
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
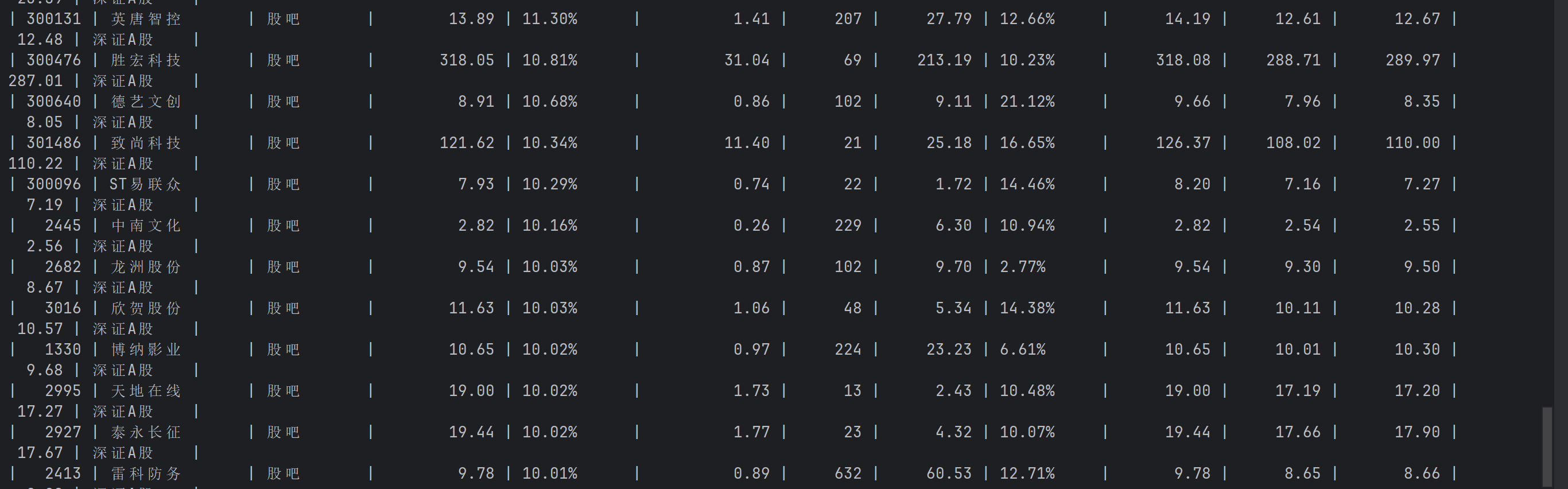
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
思路
之前的实验中有爬取过东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board这个的网页信息,但是本次实验要使用Selenium 查找HTML元素,所以思路会不太一样,我的想法是利用代码去执行点击操作,点击每一个板块的按钮然后进行切换然后爬取整页的内容:
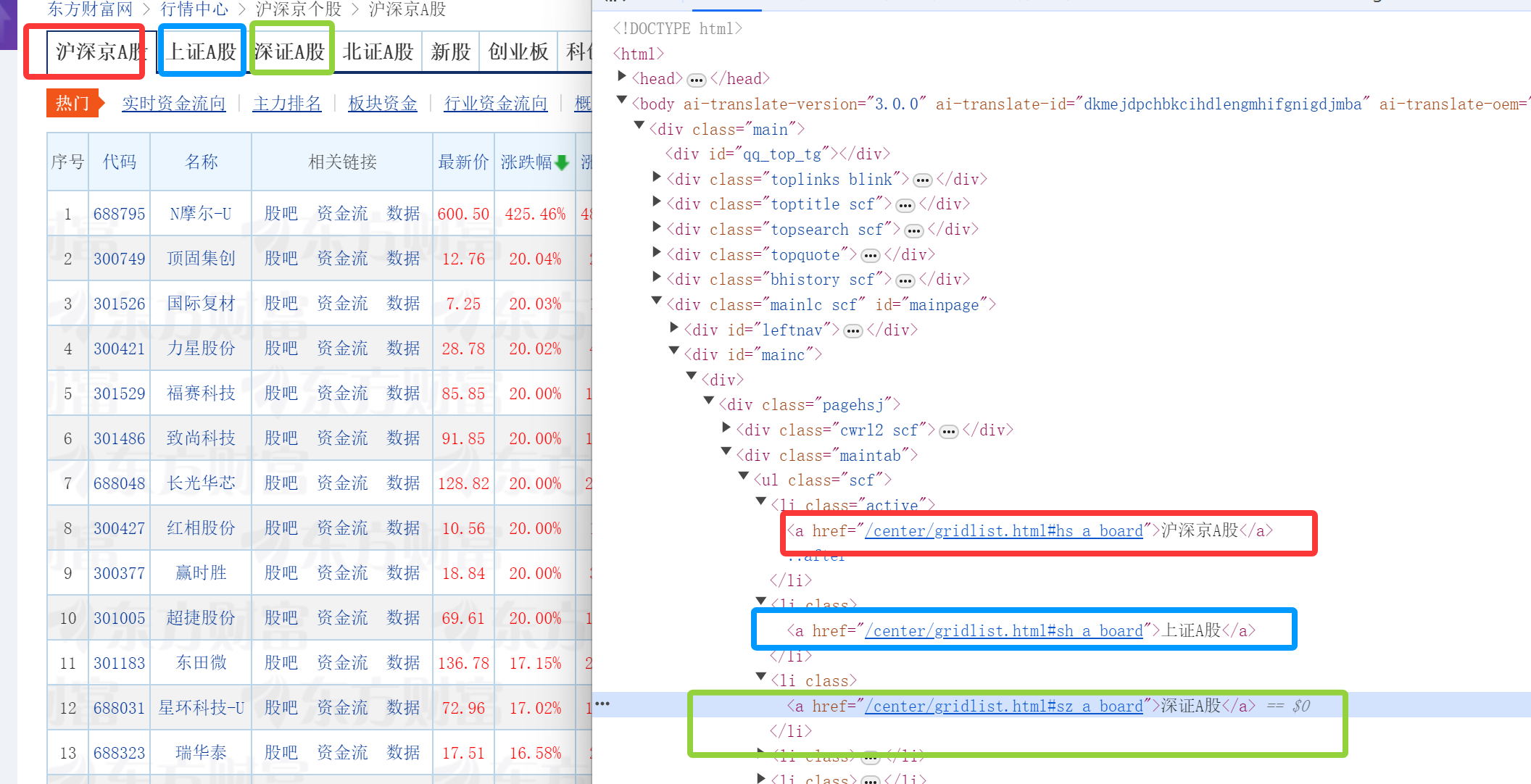
然后爬取的过程我还是像上次实验一样用了xpath,观察每个要爬取内容的xpath然后得出内容(以前三个为例子)
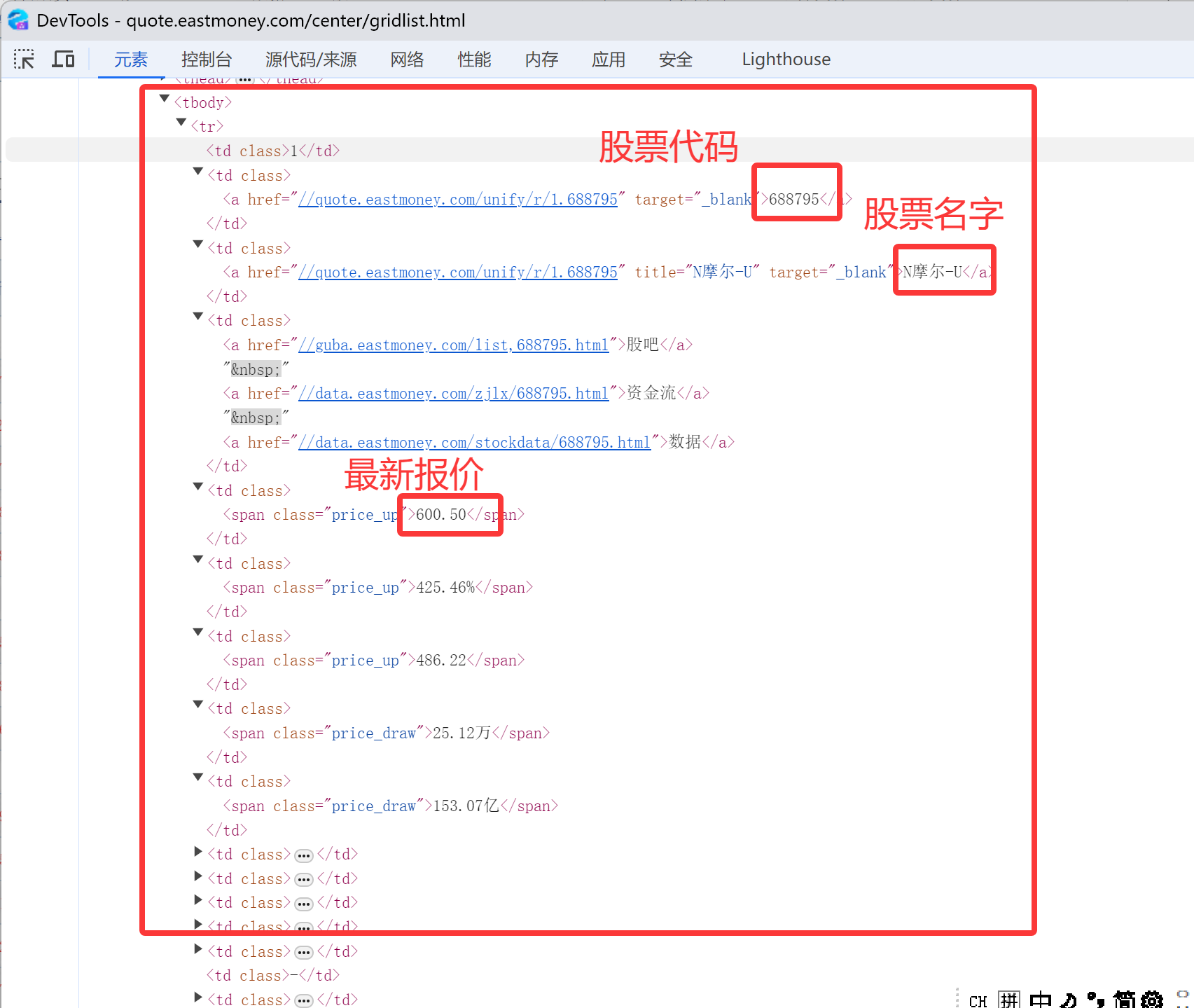
核心代码
#爬取每个板块的代码(逻辑相同)
for btn_xpath, board_name in BOARD_INFO:
if board_name != "沪深A股":
WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, btn_xpath))
).click()
time.sleep(3)
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="mainc"]/div/div/div[4]/table/tbody/tr'))
)
rows = driver.find_elements(By.XPATH, '//*[@id="mainc"]/div/div/div[4]/table/tbody/tr')
# 提取数据+插入MySQL
for row_idx in range(1, len(rows) + 1):
data = [board_name] # 先存板块名
fields = ["sBoardName"]
# 提取每个字段
for field, xpath in FIELD_XPATH:
try:
val = driver.find_element(By.XPATH, xpath.format(row_idx)).text.strip()
data.insert(0, val)
fields.insert(0, field)
except:
data.insert(0, "")
fields.insert(0, field)
# 插入SQL
sql = f"INSERT IGNORE INTO stock_info ({','.join(fields)}) VALUES ({','.join(['%s'] * len(fields))})"
cursor.execute(sql, data)
conn.commit()
运行结果:
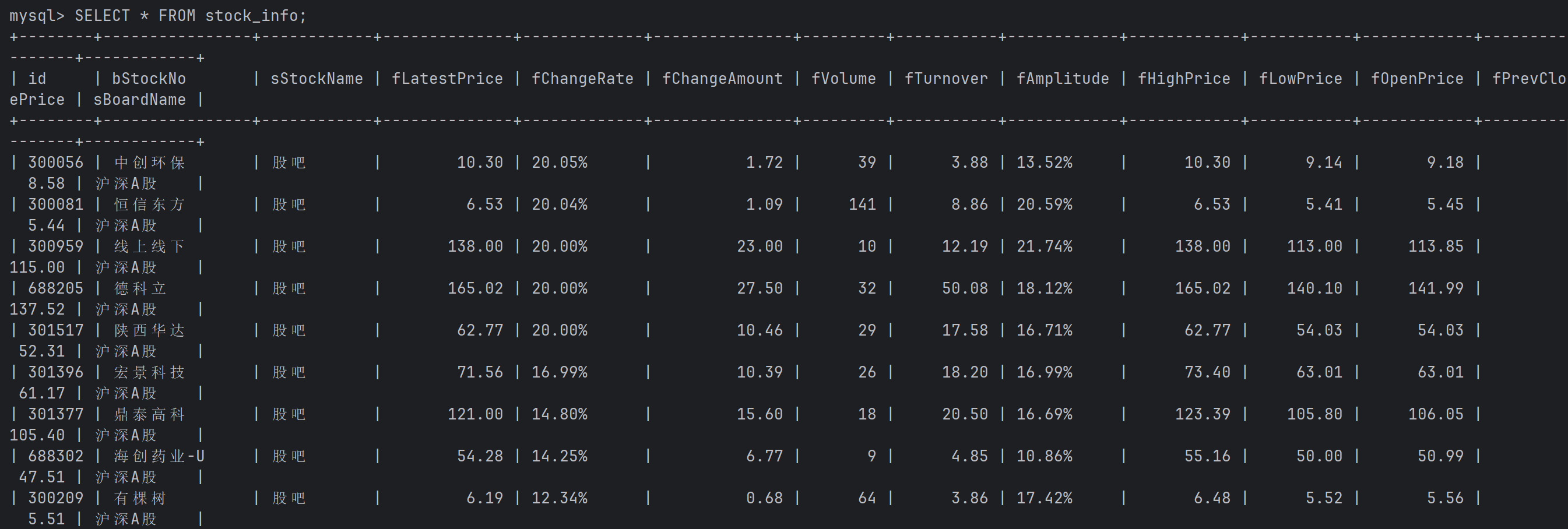
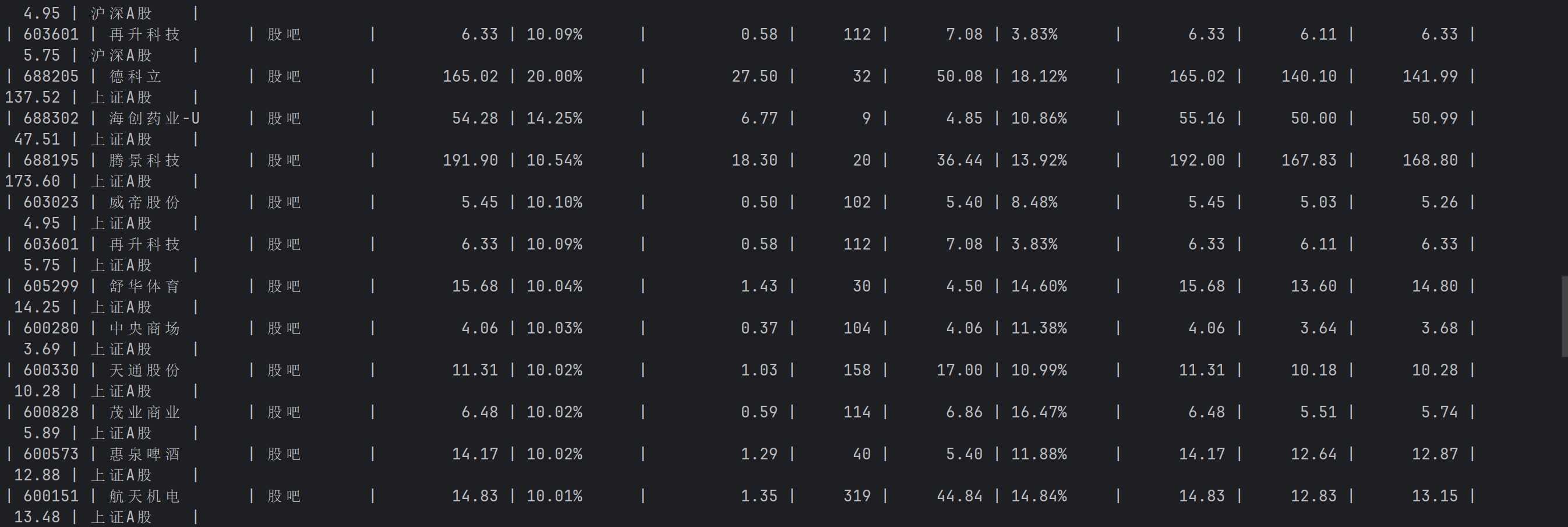
完整代码:
https://gitee.com/C-Zhaoying/2025_crawl_project/blob/master/hw5p/1/1.py
心得体会
本次实验利用了新学习的Selenium 查找HTML元素,我觉得很有意思,可以利用代码进行一些模拟用户的操作(比如点击相应板块,利用xpath),在之前爬取的时候发现这个网页还可能会出现弹窗广告什么的,可以利用代码点击关闭或者自己手动点击也可以,还是挺有趣的
作业2
实验一:爬取中国mooc网课程资源信息
要求
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
思路+核心代码
本次实验要求模拟用户登录,那么就先从界面开始观察,点击登录的按钮
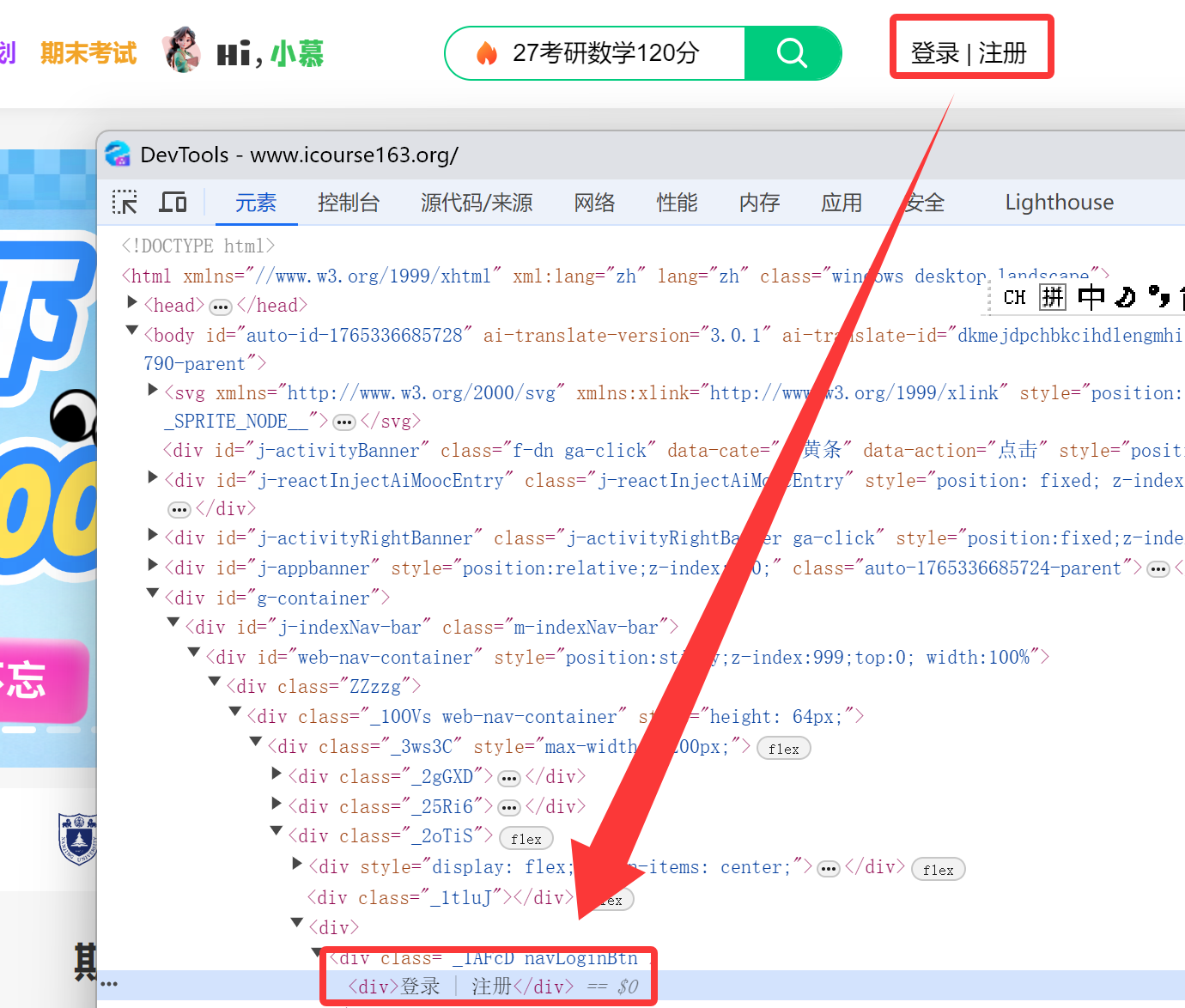
根据新的弹窗要切换到新的界面才能找到输入手机号和密码的位置
frame = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="j-ursContainer-0"]/iframe'))
)
driver.switch_to.frame(frame)
然后在相应位置输入自己的手机密码,并点击登录,注意切换到登陆后的界面要注意切回现有的界面
driver.switch_to.default_content()
进入登陆界面之后同理点击“我的课程按钮”,不过要注意的是登录界面可能会有类似用户授权的弹窗,需要点击同意的按钮,再添加相关函数即可(手动关闭应该也行但我这里是用代码完成)
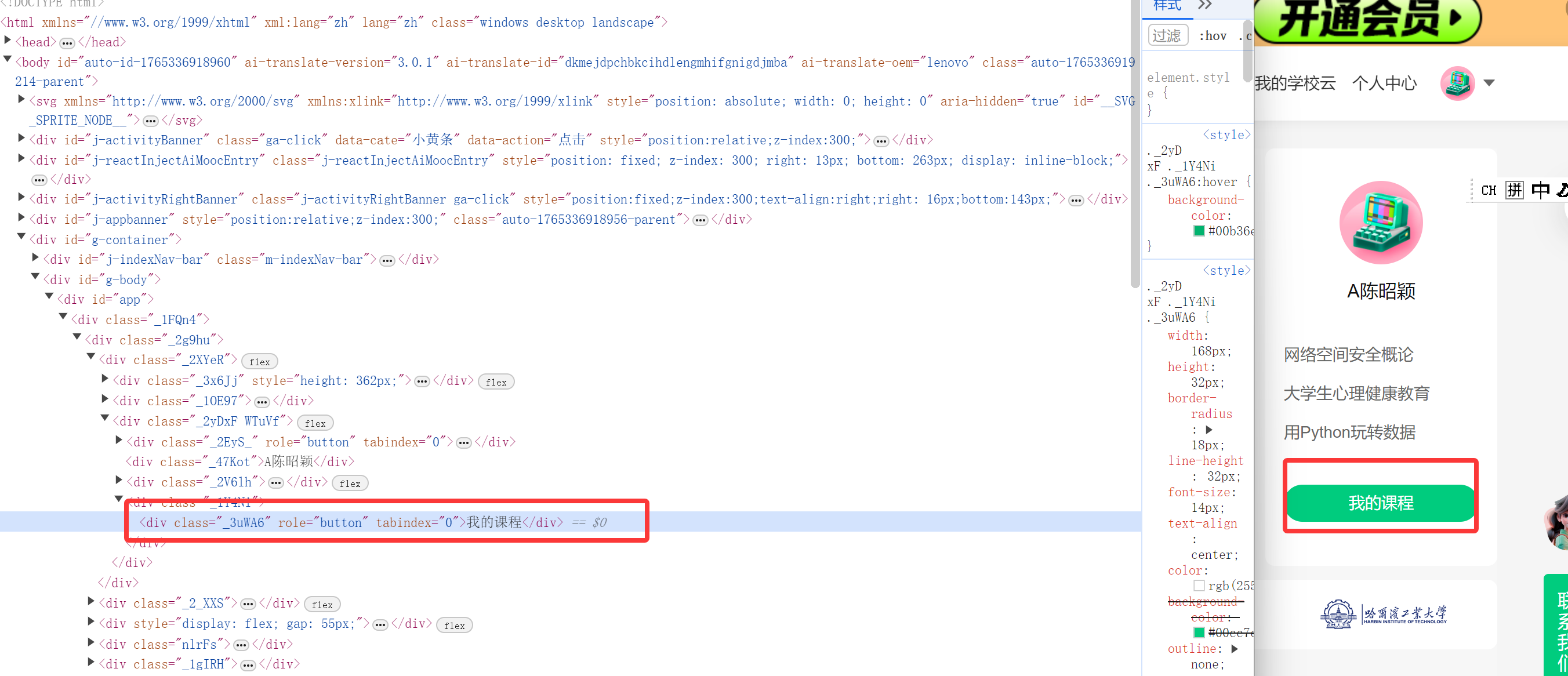
进入我的课程之后先爬取课程简介的url,然后根据url在爬取课程的详细内容数据
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.XPATH, '//div[@id="j-coursewrap"]//a[contains(@href, "/course/")]'))
)
# 爬取指定数量的课程URL
course_urls = []
for i in range(1, COURSE_URL_COUNT + 1):
try:
url_xpath = f'//*[@id="j-coursewrap"]/div/div[1]/div[{i}]/div[4]/div[1]/a'
course_a = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, url_xpath))
)
course_url = course_a.get_attribute('href') # 获取URL
if course_url: # 过滤空URL
course_urls.append(course_url)
except Exception as e:
continue
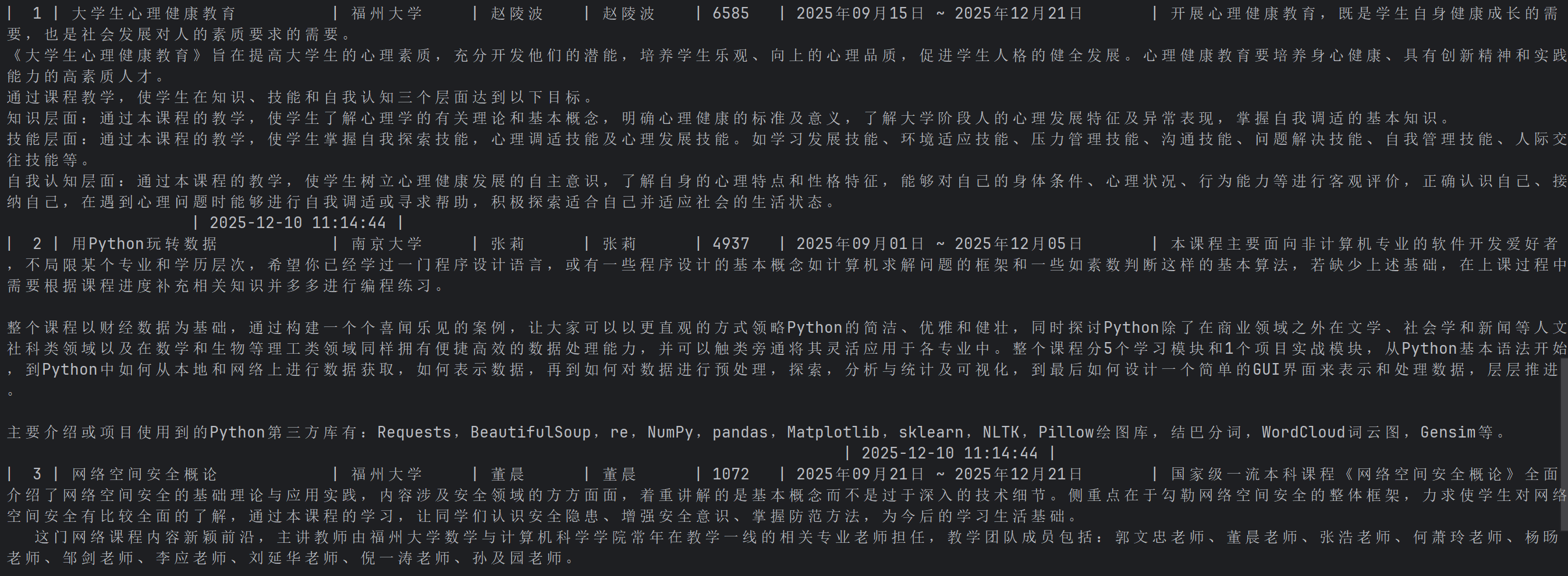
爬取课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介
# 1. 课程名字
course_name = driver.find_element(
By.XPATH, '//*[@id="g-body"]/div[1]/div/div/div/div[2]/div[2]/div/div[2]/div[1]/span[1]'
).text
# 2. 课程的学校(取img的alt文本)
course_university = driver.find_element(
By.XPATH, '//*[@id="j-teacher"]/div/a/img'
).get_attribute('alt')
# 3. 课程的老师
teacher = driver.find_element(
By.XPATH, '//*[@id="j-teacher"]/div/div/div[2]/div/div/div/div/div/h3'
).text
# 4. 课程团队
team_members = [teacher]
# 5. 课程参加人数(仅保留数字)
enroll_count_text = driver.find_element(
By.XPATH, '//*[@id="course-enroll-info"]/div/div[1]/div[4]/span[2]'
).text
enroll_count = "".join(filter(str.isdigit, enroll_count_text))
# 6. 课程进度
course_progress = driver.find_element(
By.XPATH, '//*[@id="course-enroll-info"]/div/div[1]/div[2]/div/span[2]'
).text
# 7. 课程简介(整个div的文本)
course_intro = driver.find_element(
By.XPATH, '//*[@id="content-section"]/div[4]/div'
).text.strip()
# 存入数据
course_data.append({
"cCourse": course_name,
"cCollege": course_university,
"cTeacher": teacher,
"cTeam": "、".join(team_members),
"cCount": enroll_count,
"cProcess": course_progress,
"cBrief": course_intro
})
运行结果

完整代码:
https://gitee.com/C-Zhaoying/2025_crawl_project/blob/master/hw5p/2/2.py
心得体会
本次实验是进行了一次模拟用户登录的操作,主要遇到了挺多bug的,比如点击登录的时候要在新的面板上进行操作,不然我们自己的手机号和密码是输入不进去的,还有就是登录之后还要对弹窗进行关闭,和界面得切换回来,不然也是会报错的,在爬取课程内容的时候要选中他们的课程简介的url,再拆解一个一个进行爬取(但底层逻辑都相同),还是很有意思的,但是要多点耐心去进行爬取
作业3
任务:完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验
要求
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战:
任务一:Python脚本生成测试数据
任务二:配置Kafka
任务三: 安装Flume客户端
任务四:配置Flume采集数据
实验过程
环境搭建:
任务一:开通MapReduce服务

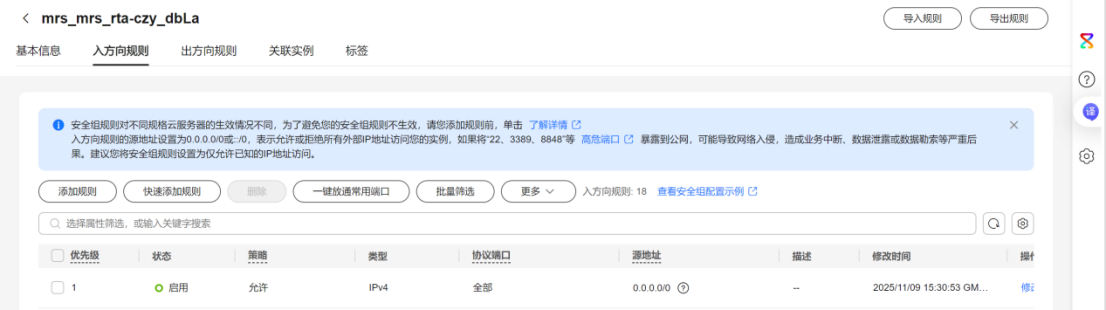
实时分析开发实战:
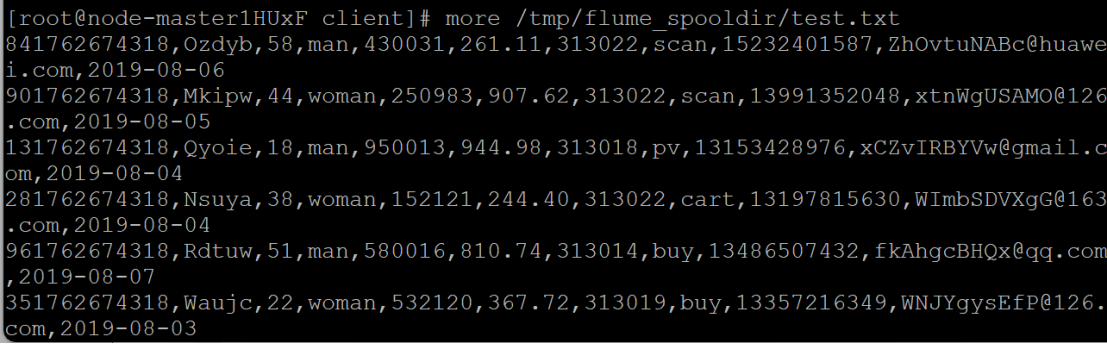
任务一:Python脚本生成测试数据
测试成功示例:
任务二:配置Kafka
Kafka的IP:
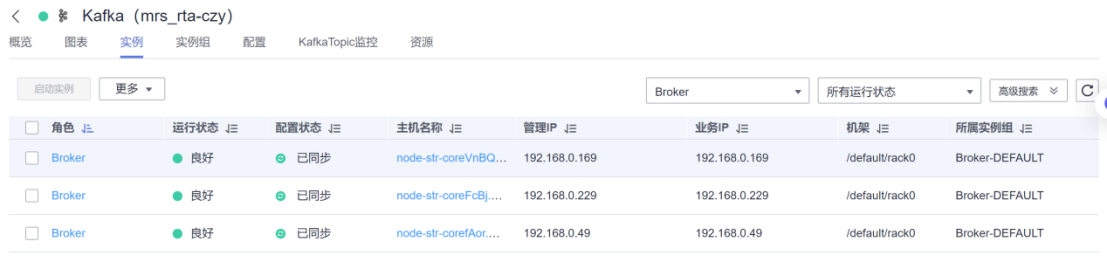
配置成功示例:

任务三: 安装Flume客户端
下载Flume客户端

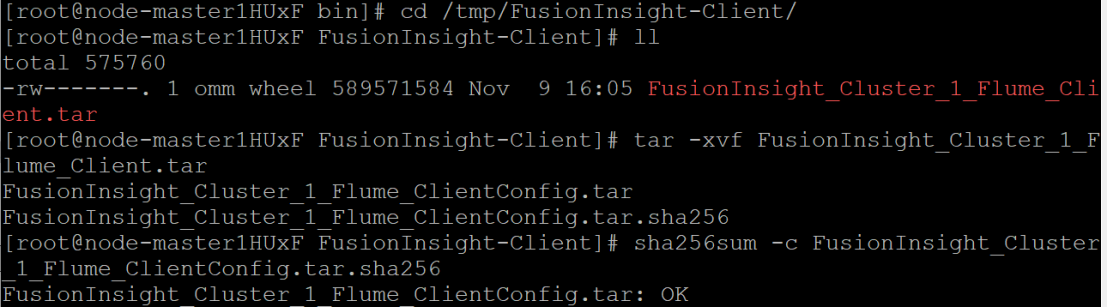

Flume下载成功:

服务重启成功,安装结束!

任务四:配置Flume采集数据
显示消费数据如下:
表明Flume到Kafka目前是打通的

心得体会
本次实验我学会了在华为云平台进行数据的实时分析处理,按照手册上一步一步来是没什么问题的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号