
102302106-陈昭颖-第2次作业
•作业①:
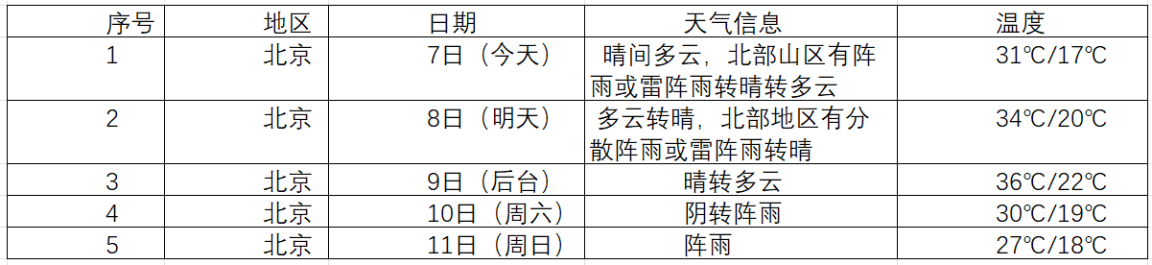
1.爬取中国气象网的七日天气预报
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
核心代码
def city_weather(city):
url = "http://www.weather.com.cn/weather/" + cityCode[city] + ".shtml"
params = {'key': city, 'page': 1, 'pagesize': 10}
response = requests.get(url, params=params)
soup = BeautifulSoup(response.content, "html.parser")
inform = soup.find("ul", {"class": "t clearfix"})
weather_data = []
for li in inform.find_all("li"):
city = city
date = li.find('h1').text
weather = li.find(class_="wea").text
temperature = li.find(class_="tem").text.strip()
weather_data.append([city ,date, weather, temperature])
return weather_data
我利用不同城市的citycode分成四个城市获取天气预报的信息,
实验结果
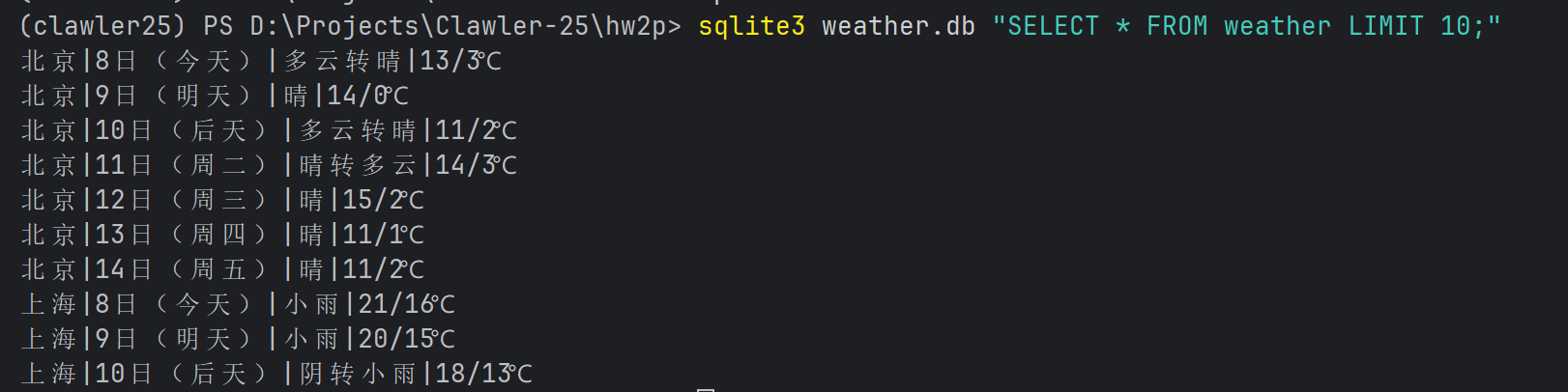
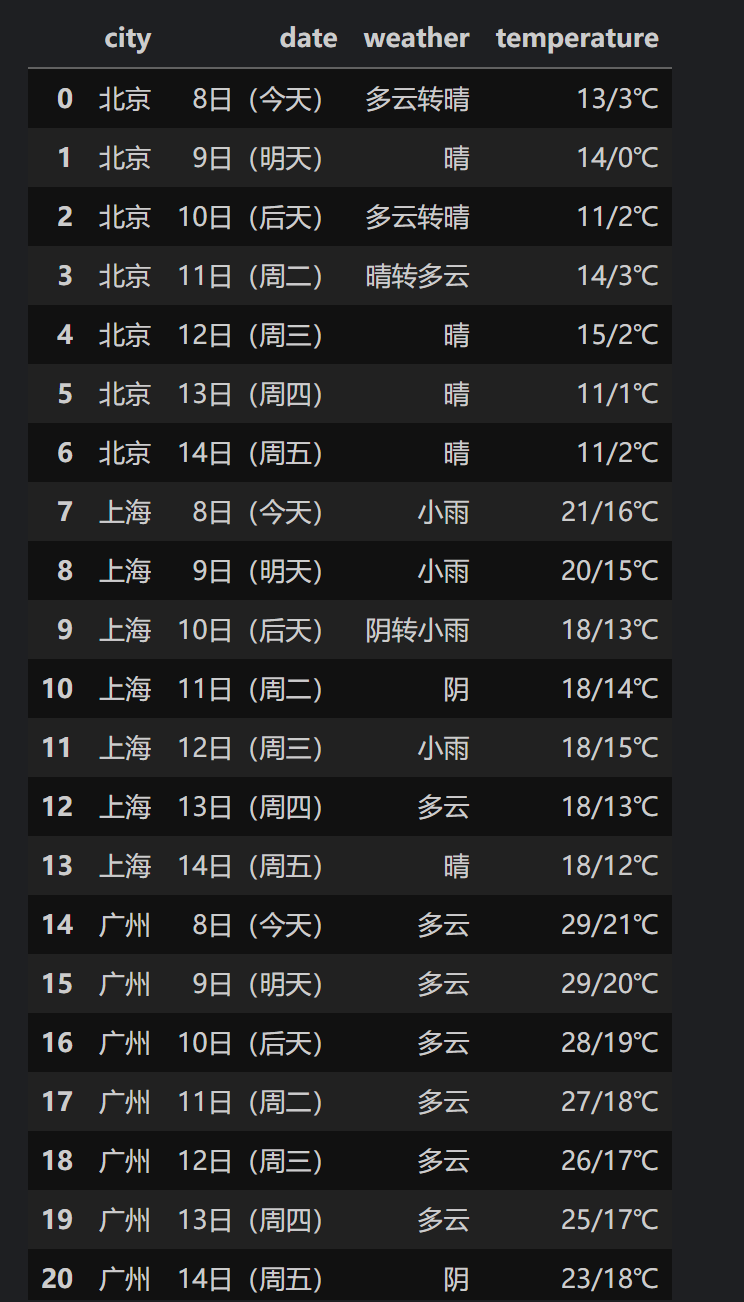
输出信息
https://gitee.com/C-Zhaoying/2025_crawl_project/blob/master/hw2p/1/weather.db
2.实验心得
这次实验我一开始是用“北京”作为特定例子爬取天气预报,后面再添加了三个其他城市,在存入数据库的时候我想把每个城市的信息都存入city_data这个空列表里面,但是用成了append,发现前面一个城市的信息全部都被覆盖掉了,只剩下最后一个城市,后面改成了extend就没问题了。
•作业②:
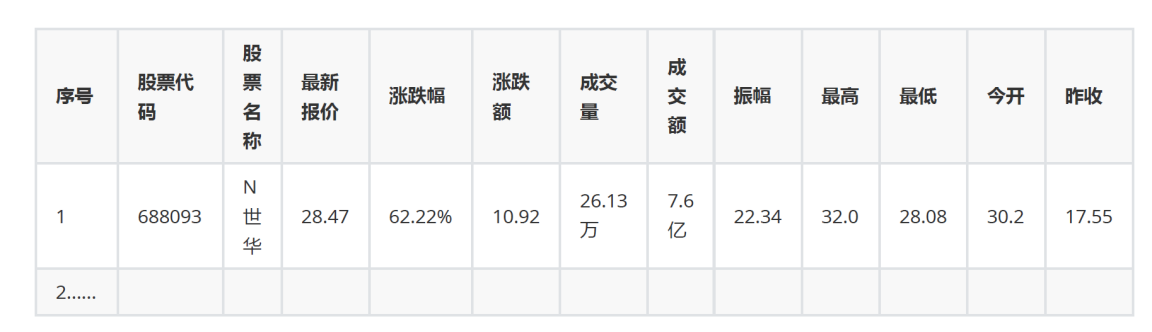
1.爬取股票的相关信息
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
 、
、
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
核心代码
我选取东方财富网:https://www.eastmoney.com/ 的行情中心作为爬取目标,点击F12观察js文件
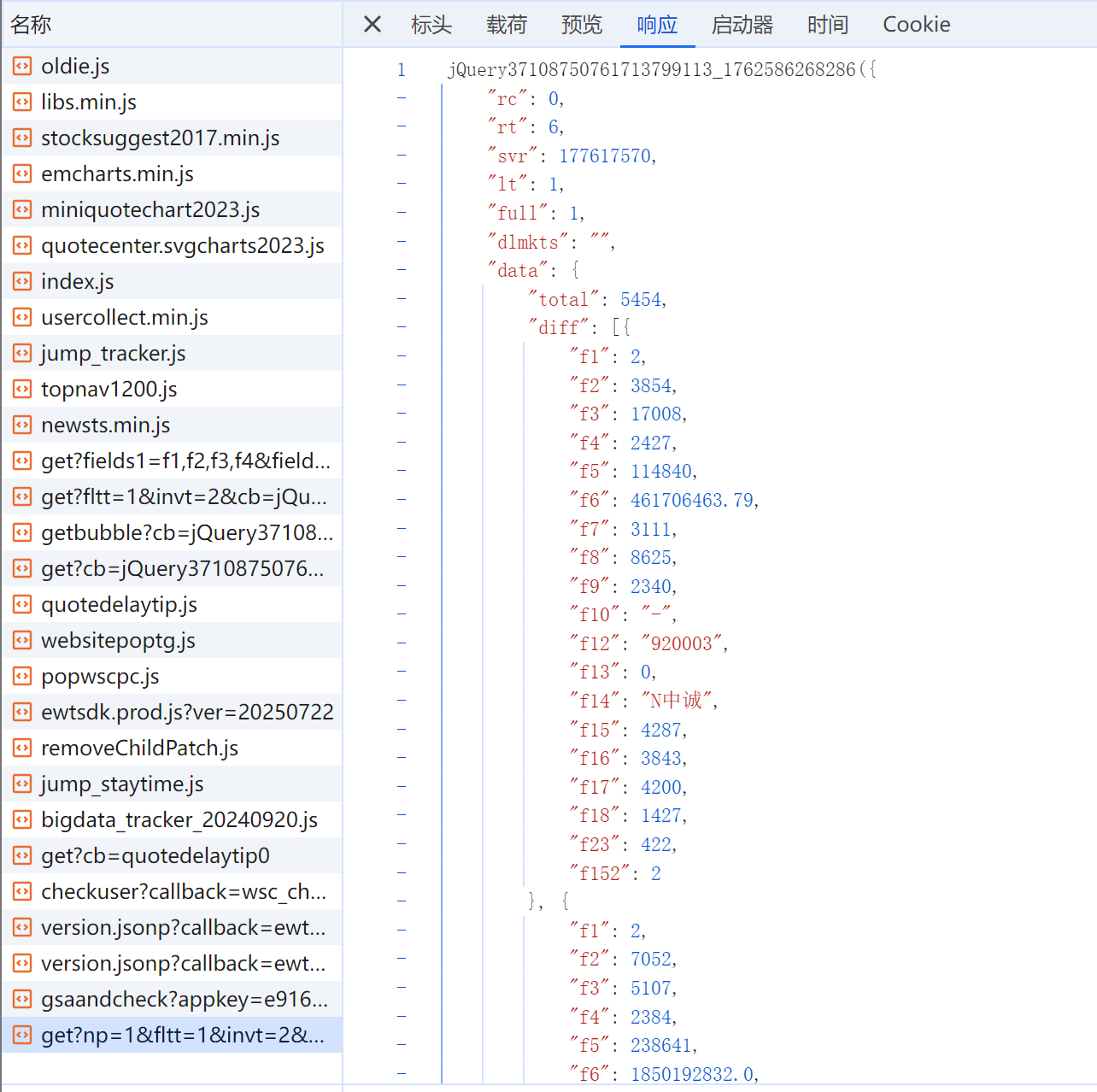
#获取股票的数据
def get_stock_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
html = response.text
json_str = re.search(r'\(({.*})\)', html).group(1)
data = json.loads(json_str)
return data
#对数据预处理
def data_process(data):
stock_data = []
if 'data' in data and 'diff' in data['data']:
for item in data['data']['diff']:
stock_num = item['f12'] #代码
stock_name = item['f14'] #名称
stock_price = item['f2']/100 #最新价
stock_change = str(item['f3']/100 )+"%" #涨跌幅
demo0 = item['f4']/100 #涨跌额
demo1 = str(item['f5'] /10000)+"万" #成交量
demo2 = str(item['f6']/100000000 )+"亿" #成交额
demo3 = str(item['f7']/100)+"%" #振幅
demo4 = item['f15']/100 #最高
demo5 = item['f16']/100 #最低
demo6 = item['f17']/100 #今开
demo7 = item['f18']/100 #昨收
stock_data.append((stock_num,stock_name, stock_price, stock_change,demo0,demo1,demo2,demo3,demo4,demo5,demo6,demo7))
return stock_data
根据网页的不同f(例如f12代表股票代码,f14代表股票名称)对其进行一些处理,包括后面的一些数字,给它统一成以“万”或“亿”表示的数字,更加清晰
运行结果
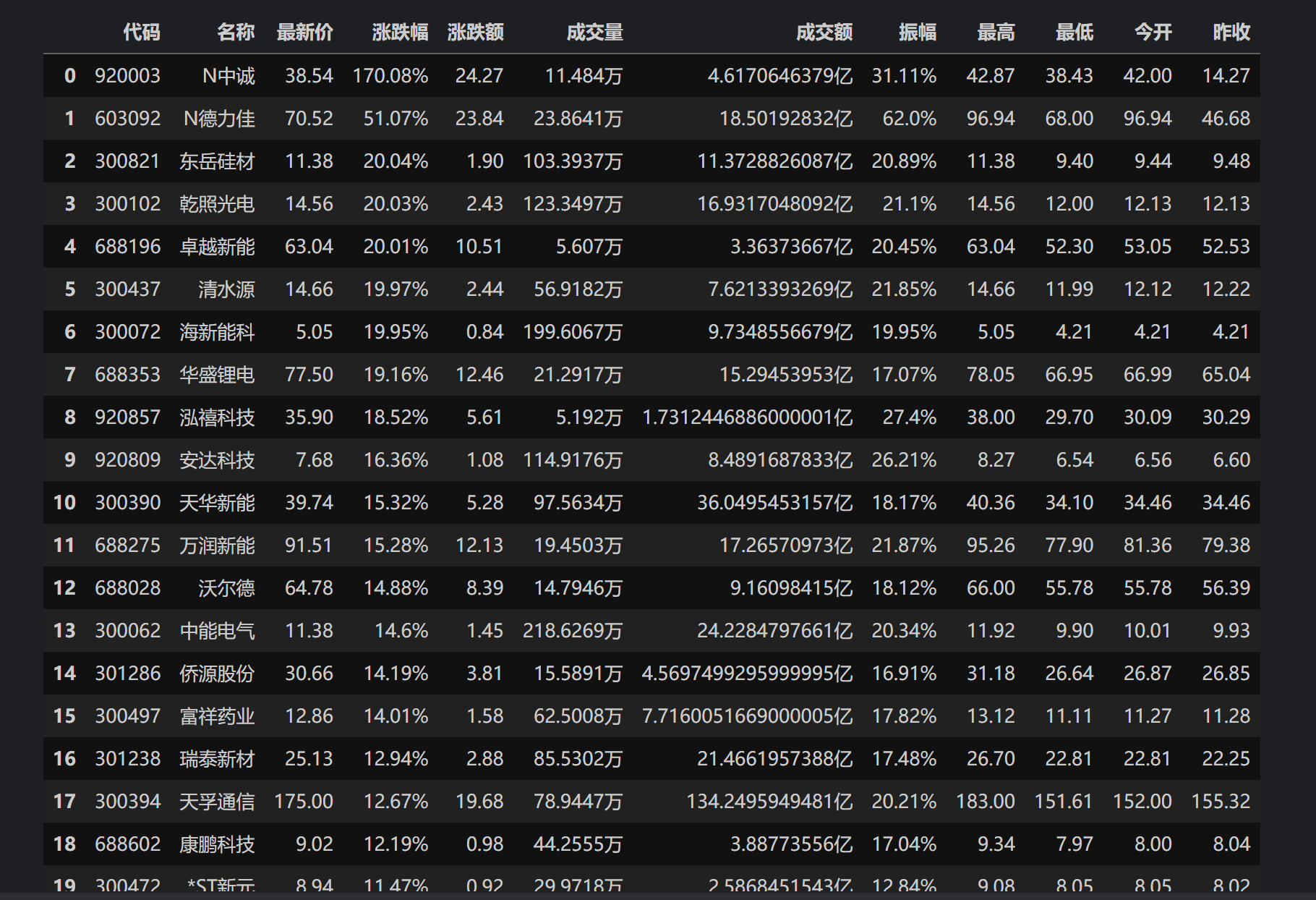
输出信息
https://gitee.com/C-Zhaoying/2025_crawl_project/blob/master/hw2p/2/stock.db
2.心得体会
这次实验我学会了用网页里面的js来调取相关信息,爬虫的另一种新途径,并且面对众多的信息内容要去更有耐心的拆解分析,并且进行一些处理简化,使得数据更加容易看懂清晰
•作业③:
1.爬取中国大学2021主榜的院校信息
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。

核心代码
#获取大学数据
def get_university_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
html = response.text
data = json.loads(html)
return data
#处理数据
def data_process(data):
school_data = []
school_datas = []
if 'data' in data and 'rankings' in data['data']:
for item in data['data']['rankings']:
ranking = item['rankOverall'] #排名
cn_name = item['univNameCn'] #中文名
en_name = item['univNameEn'] #英文名
name = f"{cn_name} {en_name}"
province = item['province'] #省市
school_type = item['univCategory'] #学校类型
score = float(item['score']) if item['score'] else 0 #总分
if name not in school_data:
school_data.append((ranking, name, province, school_type, score))
return school_data
运行结果
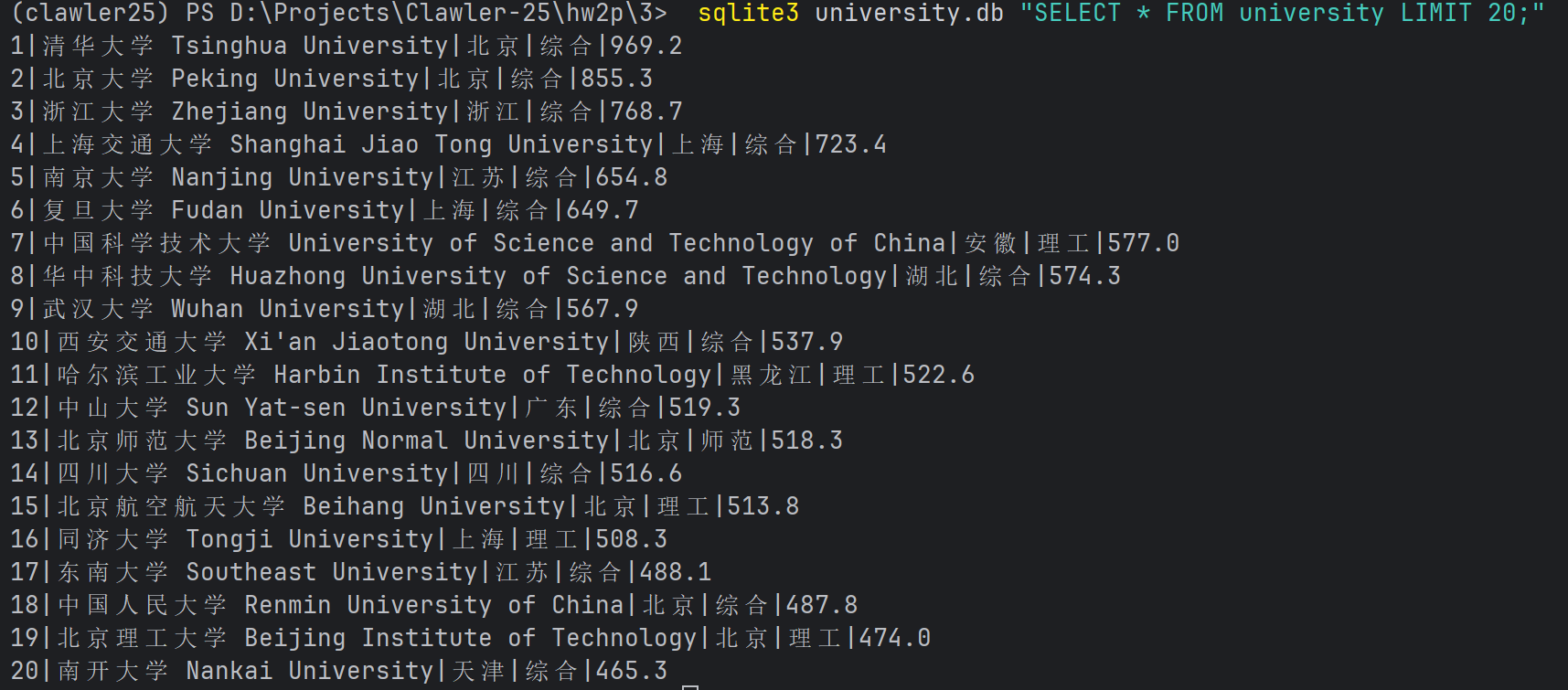
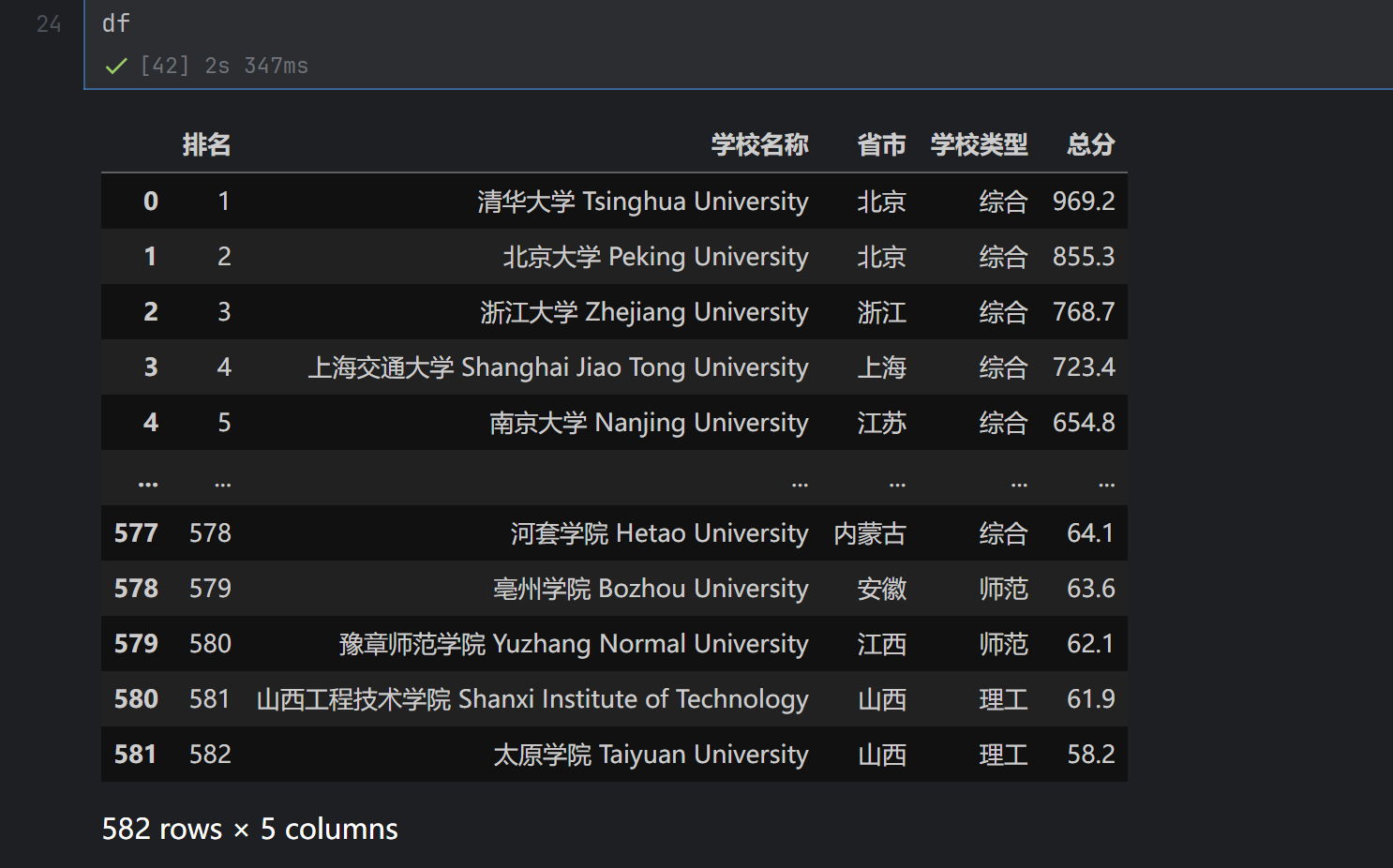
浏览器F12调试分析:

输出信息
https://gitee.com/C-Zhaoying/2025_crawl_project/blob/master/hw2p/3/university.db
心得体会
这次实验跟之前的作业一有点类似,但如果要爬所有院校的话就不能用之前的老方法了,这次是去获取了该网页的api,实际操作还是有些困难的,需要更多的耐心和耐心
完整代码:https://gitee.com/C-Zhaoying/2025_crawl_project/tree/master/hw2p

 浙公网安备 33010602011771号
浙公网安备 33010602011771号