
09-Oracle分组查询
分组查询
聚合函数
概念
聚合函数对一组值执行计算并返回单一的值。除 COUNT 以外,聚合函数忽略空值,如果COUNT函数的应用对象是一个确定列名,并且该列存在空值,此时COUNT仍会忽略空值。
基础类型:
1、max() 求最大值
2、min() 求最小值
3、sum() 求和
4、avg() 求平均数
5、count() 求个数
示例
--1、max() 求最大值
select max(sal) from emp; -- 求emp表中最大工资

--2、min() 求最小值
select min(sal) from emp; -- 求emp表中最底工资

--3、sum() 求和
select sum(sal) from emp; -- 求emp表中的总工资

--4、avg() 求平均数
select avg(sal) from emp; -- 求emp表中的平均工资

--5、count() 求个数
count(*) -- 返回所有字段行数 不会忽略某字段空值
count(字段名/字段号) -- 返回特定字段名 会忽略空值
count(1) -- 一般来讲,,1为常量列;使用count(1)也能放回全部行数,因为只需计算一个字段,所以效率比count(*)高
select count(*) from emp; -- 求emp表中的总人数
select count(1) from emp;


注意
注意:
1)所有聚合函数都是针对非空值进行的统计(除count外)
2)COUNT()的特殊用法:使用COUNT(*)统计总数据量,若是在确定哪些字段不含空值的情况下统计总数据量,可以使用COUNT(字段/字段号)来统计
3)SUM()和AVG()只针对数值,其他三个可针对任意类型
去重函数
语法
select distinct column1,column2.... from table_name
查询 去除重复 字段名1,字段名2..... 从 数据源
示例
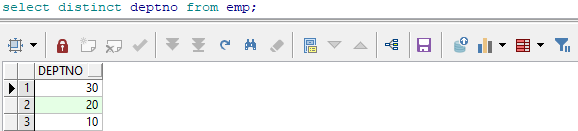
select distinct deptno from emp;
注意
1. distinct 只能紧紧跟在select后面
2. distinct 查询多个字段时,这些字段查询出的数据完全相同时,才可以去重
去空值函数
去空值函数(对null值处理)
语法
nvl(column,值1) -- 将colum中的null用 值 去代替
注意:
column 与 值1 的数据类型相同 不同类型时需要用到类型转化
nvl2(column,值1,值2) -- 将colum中的 null 用值1 去代替 , 将 非空值 用值2代替
注意:
值1可以不与nvl2的数据类型相同,但是值2的数据类型必需与值1的数据类型相同
示例
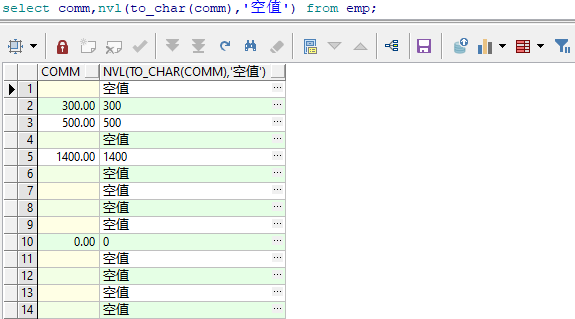
-- 查询comm列,如果有空值,把空值设置为空值
select comm,nvl(to_char(comm),'空值') from emp;
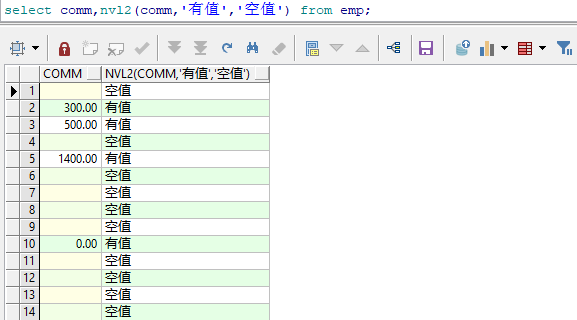
-- 查询comm列,如果不为空,返回有值,为空时返回空值
select comm,nvl2(comm,'有值','空值') from emp;
分组查询
数据分组的目的是用来汇总数据或为整个分组显示单行的汇总信息。通常在查询结果集中使用GROUP BY子句对记录进行分组。在SELECT语句中,GROUP BY子句位于FROM子句之后
语法
GROUP BY子句可以基于指定某一列的值将数据集合划分为多个分组,同一组内所有记录在分组属性上具有相同值;也可以基于指定多列的值将数据集合划分为多个分组。
select column1,column2,... from table_name where condition group by column1 order by column1;
-- 语义:从数据表table_name中根据条件筛选数据,并根据column1分组,查询数据,并根据column1排序显示数据;
示例
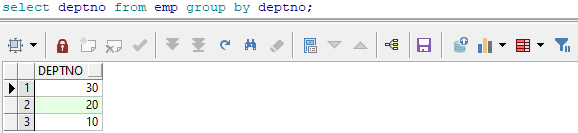
-- 按照deptno进行分组
select deptno from emp group by deptno;
注意
注意:
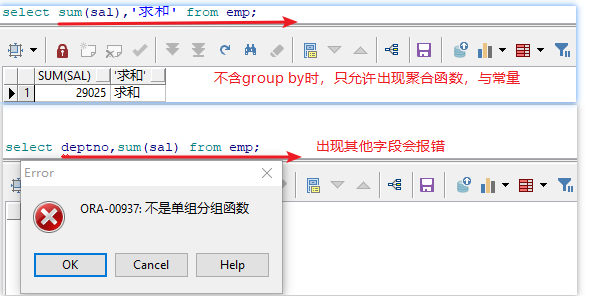
1、对于含有GROUP BY子句的SQL语句,SELECT子句中仅允许出现
1)GROUP BY中出现过的字段
2)聚合函数
3)常量
2、对于不含有GROUP BY 子句,但SELECT子句中含有聚合函数的情况,SELECT子句中除了聚合函数 和常量外,不能再出现其他字段
3、分组查询也有去重效果,但与去重函数有区别
1)分组查询是将重复的行聚合在一起
2)去重是将重复的行取一条出来
3)distinct 不能出现聚合函数
4)group by 能出现聚合函数
分组过滤
GROUP BY子句经常与聚合函数一起使用。如果SELECT子句中包含聚合函数,则计算每组的汇总值。当用户指定GROUP BY时,选择列表中任一非聚合表达式内的所有列都应包含在GROUP BY列表中,或者GROUP BY表达式必须与选择列表表达式完全匹配。
语法
select column1,column2,... from table_name where condition group by column1 having condition order by column1;
having后可以跟条件:分组后的聚合函数条件,也可以跟字段条件
示例
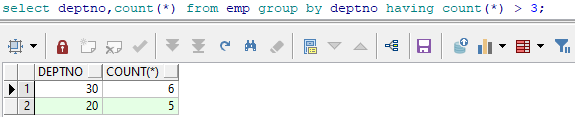
select deptno,count(*) from emp group by deptno having count(*) > 3;
注意
WHERE与HAVING的区别和联系
1)都是做筛选条件的
2)WHERE不必和GROUP BY连用,HAVING必须与GROUP BY连用
3)WHERE筛选的是针对FROM后表的数据,HAVING针对的是GROUP BY分组之后的数据进行筛选
4)WHERE中部分条件可以写在HAVING中,但非常影响执行效率,不建议使用
5)只有在GROUP BY子句中出现的字段,才能写到HAVING子句中
6)WHERE子句中不可以使用聚合函数,having可以出现聚合函数
执行顺序
书写顺序: select => from => where => group by => having => order by
执行顺序: from => where => group by => having => select => order by
找到数据源 => where筛选 => 分组 => havin过滤 => 排序
因此能写在where中的条件都尽量进where中 , 这样能提高执行效率
CASE ... WHEN ... END 判断
语法
语法1:
case
when 条件表达式1 then
sql语句1
when 条件表达式2 then
sql语句2
when 条件表达式3 then
sql语句3
......
else
sql语句4
end
语义: 当条件表达式1成立,执行sql语句1,跳过下面所有代码
当条件表达式1不成立,判断条件表达式2,当条件表达式2成立,执行sql语句2
当条件表达式1、2不成立,判断条件表达式3,当条件表达式3成立,执行sql语句3
当条件表达式1、2、3不成立,执行sql语句4
-------------------------------------------------------------------------------------
语法2:
case 表达式
when 值1 then
sql语句1
when 值2 then
sql语句2
when 值3 then
sql语句3
......
else
sql语句4
end
语义: 当表达式满足值1时,执行sql语句1,
当表达式不满足值1,判断值2,当表达式满足值2时,执行sql语句2
当表达式不满足值1、值2,判断值3,当表达式满足值3时,执行sql语句3
当表达式不满足值1、值2、值3,执行sql语句4
示例
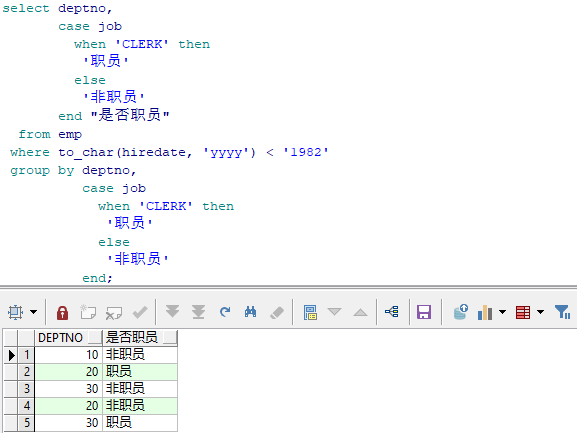
-- 11.查询 1982年以前入职的员工,按部门、职员(CLERK)与非职员分组-是否职员,
select deptno,
case job
when 'CLERK' then
'职员'
else
'非职员'
end "是否职员"
from emp
where to_char(hiredate, 'yyyy') < '1982'
group by deptno,
case job
when 'CLERK' then
'职员'
else
'非职员'
end;
注意
CASE ... WHEN ... END 相当于一列,可以在 END 后 取别名;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号