
Redis+Caffeine!
在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或Memcached 这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。
随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffeine,从而再次提升程序的响应速度与服务性能。于是,就产生了使用本地缓存作为一级缓存,再加上远程缓存作为二级缓存的两级缓存架构。
在先不考虑并发等复杂问题的情况下,两级缓存的访问流程可以用下面这张图来表示:
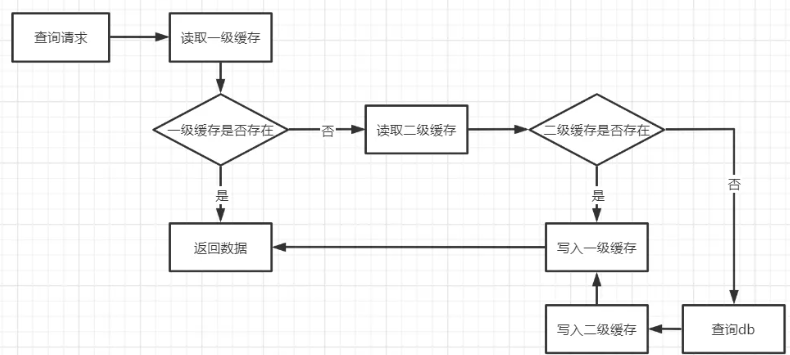
为什么要使用本地缓存
- 本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度
- 使用本地缓存能够减少和Redis类的远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时
设计一个本地内存需要有什么功能
- 存储,并可以读、写;
- 原子操作(线程安全),如ConcurrentHashMap
- 可以设置缓存的最大限制;
- 超过最大限制有对应淘汰策略,如LRU、LFU
- 过期时间淘汰,如定时、懒式、定期;
- 持久化
- 统计监控
本地缓存方案选型
1. 使用ConcurrentHashMap实现本地缓存
缓存的本质就是存储在内存中的KV数据结构,对应的就是jdk中线程安全的ConcurrentHashMap,但是要实现缓存,还需要考虑淘汰、最大限制、缓存过期时间淘汰等等功能;
优点是实现简单,不需要引入第三方包,比较适合一些简单的业务场景。缺点是如果需要更多的特性,需要定制化开发,成本会比较高,并且稳定性和可靠性也难以保障。对于比较复杂的场景,建议使用比较稳定的开源工具。
2. 基于Guava Cache实现本地缓存
Guava是Google团队开源的一款 Java 核心增强库,包含集合、并发原语、缓存、IO、反射等工具箱,性能和稳定性上都有保障,应用十分广泛。Guava Cache支持很多特性:
- 支持最大容量限制
- 支持两种过期删除策略(插入时间和访问时间)
- 支持简单的统计功能
- 基于LRU算法实现
使用代码如下:
1 <dependency> 2 <groupId>com.google.guava</groupId> 3 <artifactId>guava</artifactId> 4 <version>31.1-jre</version> 5 </dependency>
1 /** 2 * @Author: Bytezero_zhengLei 4 * @Project_Name: GuavaCacheTest.java 5 * @Description: 6 * Guava是Google团队开源的一款 Java 核心增强库,包含集合、并发原语、缓存、IO、反射等工具箱,性能和稳定性上都有保障,应用十分广泛。 7 * Guava Cache支持很多特性: 8 * 支持最大容量限制 9 * 支持两种过期删除策略(插入时间和访问时间) 10 * 支持简单的统计功能 11 * 基于LRU算法实现 12 */
6 @Slf4j 7 public class GuavaCacheTest { 8 public static void main(String[] args) throws ExecutionException { 9 Cache<String, String> cache = CacheBuilder.newBuilder() 10 .initialCapacity(5) // 初始容量 11 .maximumSize(10) // 最大缓存数,超出淘汰 12 .expireAfterWrite(60, TimeUnit.SECONDS) // 过期时间 13 .build(); 14 15 String orderId = String.valueOf(123456789); 16 // 获取orderInfo,如果key不存在,callable中调用getInfo方法返回数据 17 String orderInfo = cache.get(orderId, () -> getInfo(orderId)); 18 log.info("orderInfo = {}", orderInfo); 19 20 } 21 22 private static String getInfo(String orderId) { 23 String info = ""; 24 // 先查询redis缓存 25 log.info("get data from redis"); 26 27 // 当redis缓存不存在查db 28 log.info("get data from mysql"); 29 info = String.format("{orderId=%s}", orderId); 30 return info; 31 } 32 }
3. Caffeine
Caffeine是基于java8实现的新一代缓存工具,缓存性能接近理论最优。可以看作是Guava Cache的增强版,功能上两者类似,不同的是Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,在性能上有明显的优越性
使用代码如下:
1 <dependency> 2 <groupId>com.github.ben-manes.caffeine</groupId> 3 <artifactId>caffeine</artifactId> 4 <version>2.9.3</version> 5 </dependency> 6 @Slf4j
1 /** 2 * @Author: Bytezero_zhengLei 3 * @Project_Name: CaffeineTest.java 4 * @Description: 5 * Caffeine是基于java8实现的新一代缓存工具,缓存性能接近理论最优。 6 * 可以看作是Guava Cache的增强版,功能上两者类似, 7 * 不同的是Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,在性能上有明显的优越性 8 */
7 public class CaffeineTest { 8 public static void main(String[] args) { 9 Cache<String, String> cache = Caffeine.newBuilder() 10 .initialCapacity(5) 11 // 超出时淘汰 12 .maximumSize(10) 13 //设置写缓存后n秒钟过期 14 .expireAfterWrite(60, TimeUnit.SECONDS) 15 //设置读写缓存后n秒钟过期,实际很少用到,类似于expireAfterWrite 16 //.expireAfterAccess(17, TimeUnit.SECONDS) 17 .build(); 18 19 String orderId = String.valueOf(123456789); 20 String orderInfo = cache.get(orderId, key -> getInfo(key)); 21 System.out.println(orderInfo); 22 } 23 24 private static String getInfo(String orderId) { 25 String info = ""; 26 // 先查询redis缓存 27 log.info("get data from redis"); 28 29 // 当redis缓存不存在查db 30 log.info("get data from mysql"); 31 info = String.format("{orderId=%s}", orderId); 32 return info; 33 } 34 }
4. Encache
Encache是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。同Caffeine和Guava Cache相比,Encache的功能更加丰富,扩展性更强:
- 支持多种缓存淘汰算法,包括LRU、LFU和FIFO
- 缓存支持堆内存储、堆外存储、磁盘存储(支持持久化)三种
- 支持多种集群方案,解决数据共享问题
使用代码如下:
1 <dependency> 2 <groupId>org.ehcache</groupId> 3 <artifactId>ehcache</artifactId> 4 <version>3.9.7</version> 5 </dependency>
1 /** 2 * @Author: Bytezero_zhengLei 3 * @Project_Name: EhcacheTest.java 4 * @Description: 5 * Encache是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。 6 * 同Caffeine和Guava Cache相比,Encache的功能更加丰富,扩展性更强: 7 * 支持多种缓存淘汰算法,包括LRU、LFU和FIFO 8 * 缓存支持堆内存储、堆外存储、磁盘存储(支持持久化)三种 9 * 支持多种集群方案,解决数据共享问题 10 */
6 @Slf4j 7 public class EhcacheTest { 8 private static final String ORDER_CACHE = "orderCache"; 9 public static void main(String[] args) { 10 CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder() 11 // 创建cache实例 12 .withCache(ORDER_CACHE, CacheConfigurationBuilder 13 // 声明一个容量为20的堆内缓存 14 .newCacheConfigurationBuilder(String.class, String.class, ResourcePoolsBuilder.heap(20))) 15 .build(true); 16 // 获取cache实例 17 Cache<String, String> cache = cacheManager.getCache(ORDER_CACHE, String.class, String.class); 18 19 String orderId = String.valueOf(123456789); 20 String orderInfo = cache.get(orderId); 21 if (StrUtil.isBlank(orderInfo)) { 22 orderInfo = getInfo(orderId); 23 cache.put(orderId, orderInfo); 24 } 25 log.info("orderInfo = {}", orderInfo); 26 } 27 28 private static String getInfo(String orderId) { 29 String info = ""; 30 // 先查询redis缓存 31 log.info("get data from redis"); 32 33 // 当redis缓存不存在查db 34 log.info("get data from mysql"); 35 info = String.format("{orderId=%s}", orderId); 36 return info; 37 } 38 }
本地缓存问题及解决
1. 缓存一致性
两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
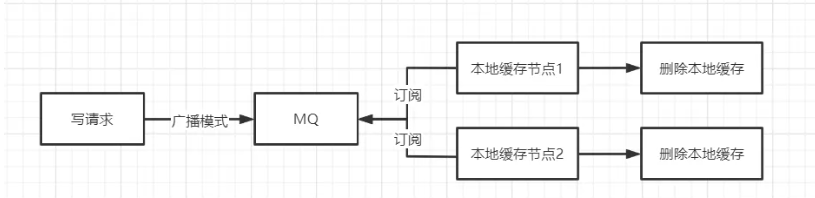
解决方案1: MQ
一般现在部署都是集群部署,有多个不同节点的本地缓存; 可以使用MQ的广播模式,当数据修改时向MQ发送消息,节点监听并消费消息,删除本地缓存,达到最终一致性;
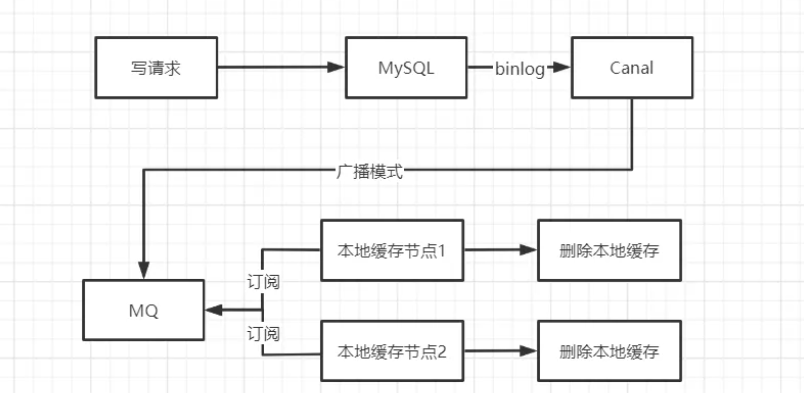
解决方案2:Canal + MQ
如果你不想在你的业务代码发送MQ消息,还可以适用近几年比较流行的方法:订阅数据库变更日志,再操作缓存。Canal 订阅Mysql的 Binlog日志,当发生变化时向MQ发送消息,进而也实现数据一致性。
2. 本地内存的技术选型问题
- 从易用性角度,Guava Cache、Caffeine和Encache都有十分成熟的接入方案,使用简单。
- 从功能性角度,Guava Cache和Caffeine功能类似,都是只支持堆内缓存,Encache相比功能更为丰富
- 从性能上进行比较,Caffeine最优、GuavaCache次之,Encache最差(下图是三者的性能对比结果)
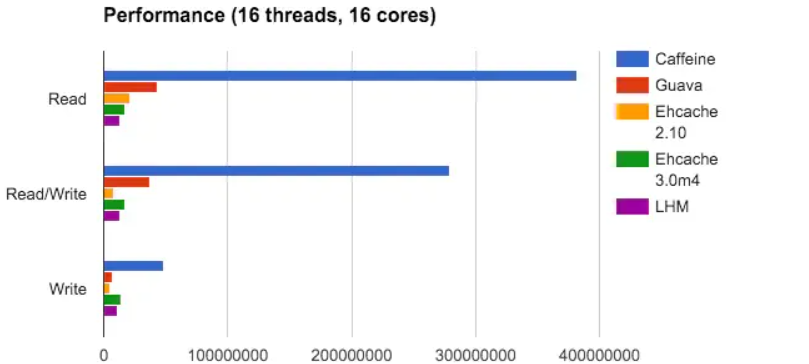
虽然Encache功能更为丰富,甚至提供了持久化和集群的功能,但是这些功能完全可以依靠其他方式实现。真实的业务工程中,建议使用Caffeine作为本地缓存,另外使用redis或者memcache作为分布式缓存,构造多级缓存体系,保证性能和可靠性。
本文来自博客园,作者:Bytezero!,转载请注明原文链接:https://www.cnblogs.com/Bytezero/p/18820662

 浙公网安备 33010602011771号
浙公网安备 33010602011771号