
day4、字符串方式、集合、文件操作
非空即真,非零即真 不为空,就是True,是空的话,就是False 只要不是0就是True,是零的话,那就是False a= [] #list为空,则也为False b = {} c = 0 d = tuple() e = '' #以上定义为空的话,都为False
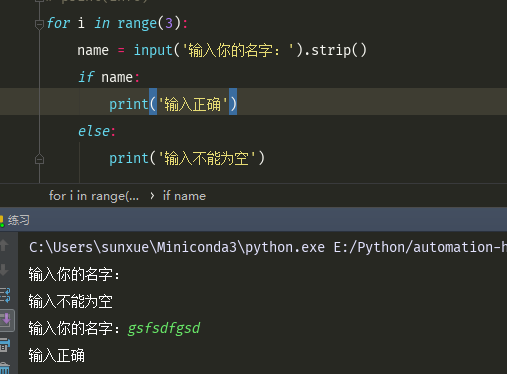
如下,当name输入为空的时候,判断输入不能为空
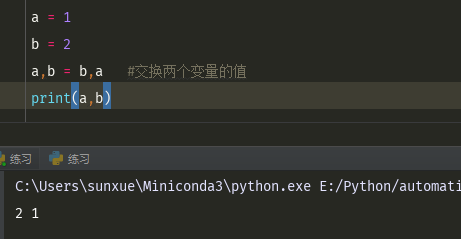
Python中,可以通过a,b = b,a 交换a,b的值
Python中是在底层通过引入一个中间变量的值实现的方法
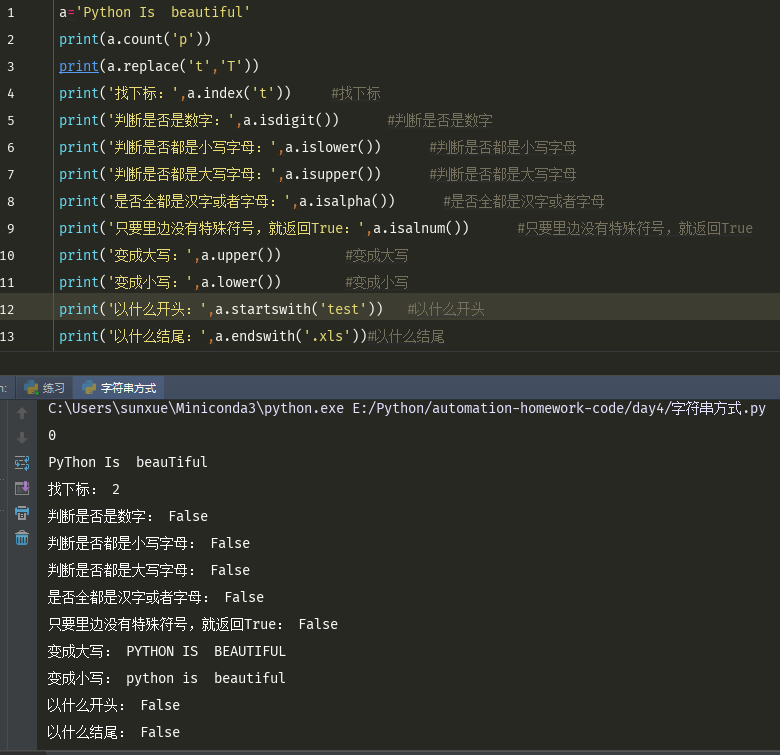
print(a.count('p')) print(a.replace('t','T')) print('找下标:',a.index('t')) #找下标 print('判断是否是数字:',a.isdigit()) #判断是否是数字 print('判断是否都是小写字母:',a.islower()) #判断是否都是小写字母 print('判断是否都是大写字母:',a.isupper()) #判断是否都是大写字母 print('是否全都是汉字或者字母:',a.isalpha()) #是否全都是汉字或者字母 print('只要里边没有特殊符号,就返回True:',a.isalnum()) #只要里边没有特殊符号,就返回True print('变成大写:',a.upper()) #变成大写 print('变成小写:',a.lower()) #变成小写 print('以什么开头:',a.startswith('test')) #以什么开头 print('以什么结尾:',a.endswith('.xls'))#以什么结尾
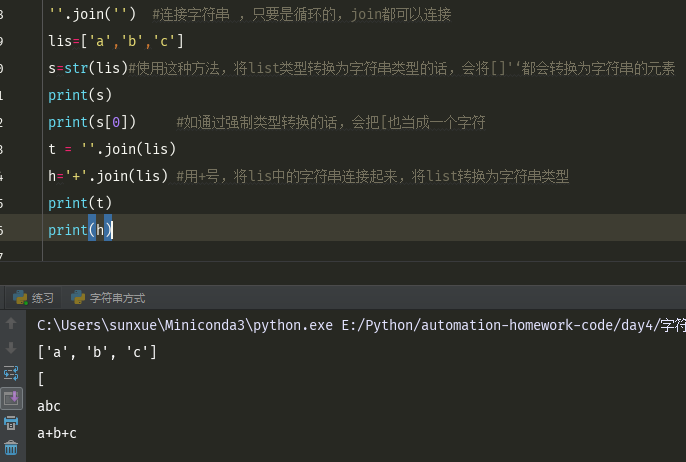
''.join('') #连接字符串 ,只要是循环的,join都可以连接 h='+'.join(lis) #用+号,将lis中的字符串连接起来,将list转换为字符串类型 1、它把一个list变成字符串 2、通过某个字符串把list里边的每个元素连接起来 3、只要是可以循环的,join都可以帮你连起来
import string #引入模块 print('所有小写:',string.ascii_lowercase) #所有小写 print('所有大写:',string.ascii_uppercase) #所有大写 print('所有数字:',string.digits) #所有数字 print('所有大写跟小写字母:',string.ascii_letters) #所有大写跟小写字母 print('所有特殊字符:',string.punctuation) #所有特殊字符 print('将小写字母每个字母用逗号连接:',','.join(string.ascii_lowercase))#将小写字母每个字母用逗号连接
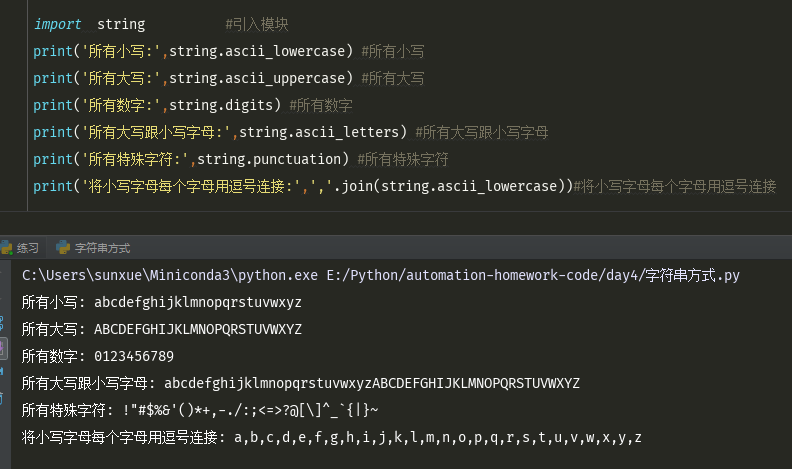
#./split分割字符串,然后将结果保存到一个list中 name='xiaoming,xiaohong,xiaolan,xiaobai' name_list=name.split(',') #将name字符串,用逗号分割,分割成多个字符串,然后保存到name_list中 name_list1=name.split('!') #将name字符串,用!分割,但是里边没有!,所以结果中,将整个字符串变成一个list的值 name_list2=name.split() #用空进行分割的话,代表以空格进行分割 name_list3=name.split('h') #用h 分割可以分割成2个字符串,然后保存到list中
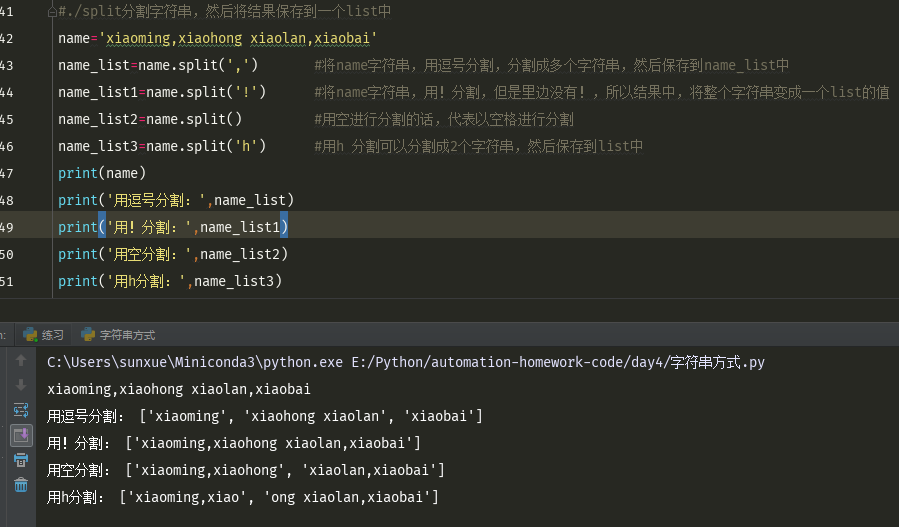
print('欢迎'.center(50,'*'))#将欢迎放到50个字符的中间,*跟‘欢迎’总共50
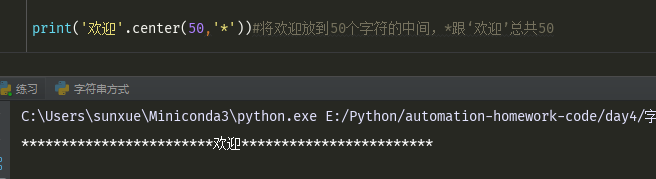
./remove删除指定的元素之后,前一个元素会往前进一个,下标-1,所以中间一个下标会不会循环到
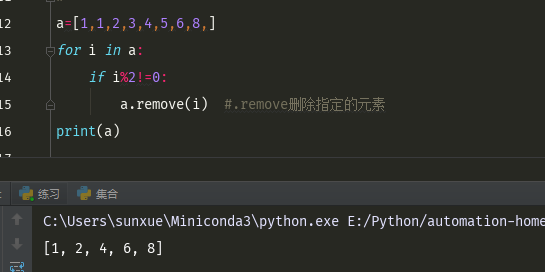
a2=copy.deepcopy(a)#深拷贝,浅拷贝跟深拷贝的区别就是深拷贝会开辟一个内存空间,深拷贝内存地址会变化 #a2=a #浅拷贝,浅拷贝,内存地址会相同 print(id(a)) #查看内存地址
#集合 #集合天生去重 #集合也是无序的 #定义一个集合 s=set() #空集合 s2 = set('432432') s3= {3,4,5,6,}
#交集,两个集合相同的地方 print('取交集:',s2 & s3) #交集,两个集合相同的地方 print('取交集:',s2.intersection(s3)) #也是取交集 #并集,吧两个集合合并到一起,然后去重 print('取并集:',s2 | s3) #取并集,两个集合合并到一起,然后去重 print('取并集:',s2.union(s3)) #也是取并集
#差集,去掉跟另一个集合重复的部分 print(s2-s3) print(s2.difference(s3)) #对称差集 #两个集合里边,去掉两集合里边重复的部分 print(s2^s3) print(s2.symmetric_difference(s3))
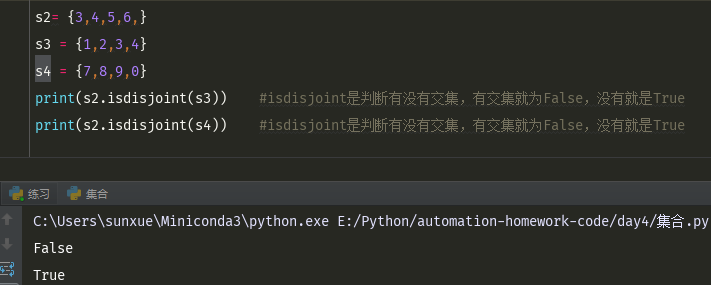
print(s2.isdisjoint(s3)) #isdisjoint是判断有没有交集,有交集就为False,没有就是True print(s2.isdisjoint(s4)) #isdisjoint是判断有没有交集,有交集就为False,没有就是True
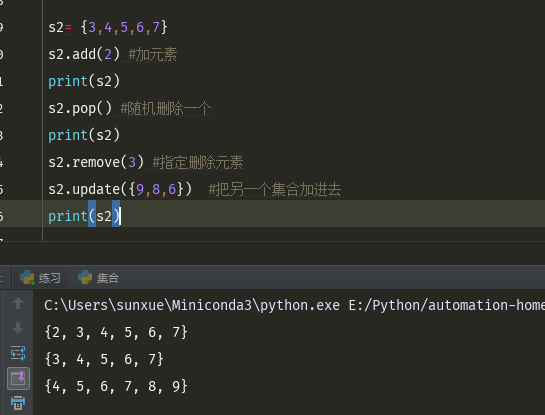
s2.add(2) #加元素 s2.pop() #随机删除一个 s2.remove(3) #指定删除元素 s2.update({9,8,6}) #把另一个集合加进去
练习: # 校验密码里面是否包含 # 数字、大写字母、小写字母、特殊符号
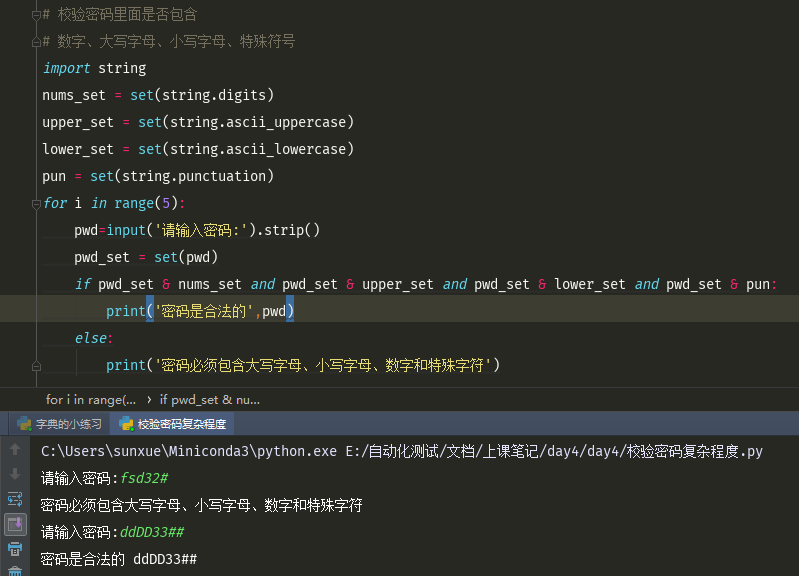
代码: import string nums_set = set(string.digits) upper_set = set(string.ascii_uppercase) lower_set = set(string.ascii_lowercase) pun = set(string.punctuation) for i in range(5): pwd=input('请输入密码:').strip() pwd_set = set(pwd) if pwd_set & nums_set and pwd_set & upper_set and pwd_set & lower_set and pwd_set & pun: print('密码是合法的',pwd) else: print('密码必须包含大写字母、小写字母、数字和特殊字符')
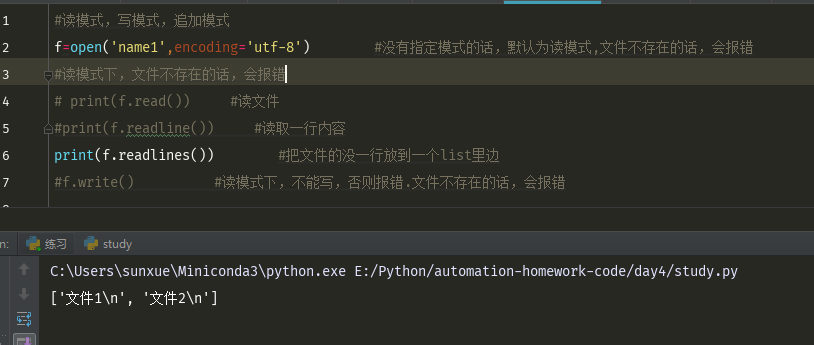
文件操作: f=open('name1',encoding='utf-8') #没有指定模式的话,默认为读模式,文件不存在的话,会报错 #读模式下,文件不存在的话,会报错 # print(f.read()) #读文件 #print(f.readline()) #读取一行内容 print(f.readlines()) #把文件的没一行放到一个list里边 #f.write() #读模式下,不能写,否则报错.文件不存在的话,会报错
f = open('C:\\Users\\sunxue\\Desktop\\access.log',encoding='utf-8') #绝对路径中的\,需要用\转义
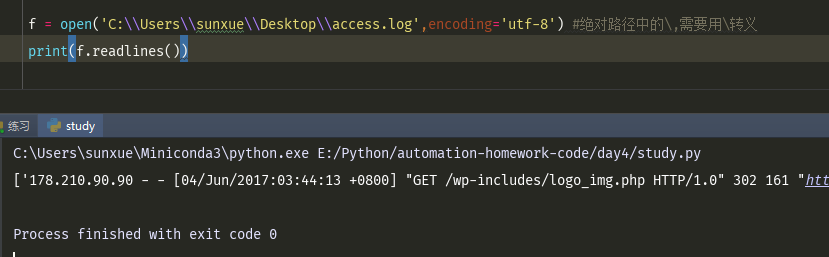
h=open('name2','w',encoding='utf-8') #打开一个不存在的文件的话,会帮忙新建文件 #打开一个已经存在的文件,会清空以前的文件内容 #print(h.read()) #写模式不能读 #print(h.readline()) #写模式不能读 h.write('中国人')
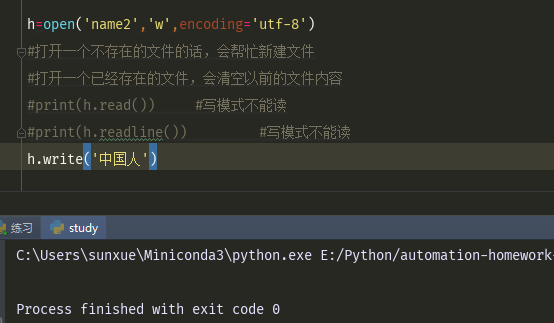
i = open('name3','a',encoding='utf-8') # 1、文件不存在的话,会帮你新建文件 # 2、打开一个已经存的文件,不会清空,末尾增加 # 3、不能读 #print(i.read()) #追加模式不能读 #print(i.readline()) #追加模式不能读 i.write('中国人')
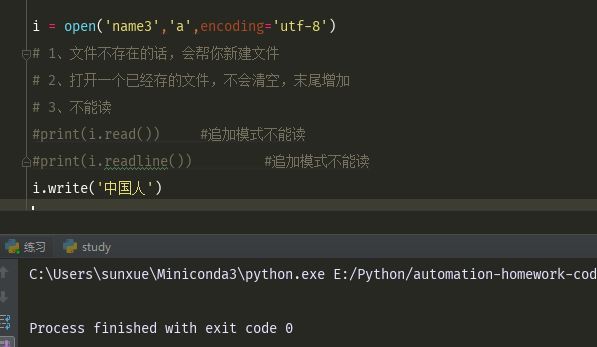
#读写模式 r+ j= open('name1','r+',encoding='utf-8') # 1、可以写 # 2、文件不存在的话会报错 print(j.read()) #读写模式可以读 print(j.readline()) #读写模式可以读 j.write('中国人') #写读模式 w+ # 1、文件不存在的话,会帮你新建文件 # 2、打开一个已经存的文件,他会清空以前文件的内容 # 3、可以读 k= open('name1','w+',encoding='utf-8') print(k.read()) #读写模式可以读 print(k.readline()) #读写模式可以读 k.write('中国人') #追加读模式 a+ # 1、文件不存在的话,会帮你新建文件 # 2、打开一个已经存的文件,不会清空,末尾增加 # 3、可以读 h= open('name1','a+',encoding='utf-8') print(h.read()) #读写模式可以读 print(h.readline()) #读写模式可以读 h.write('中国人')
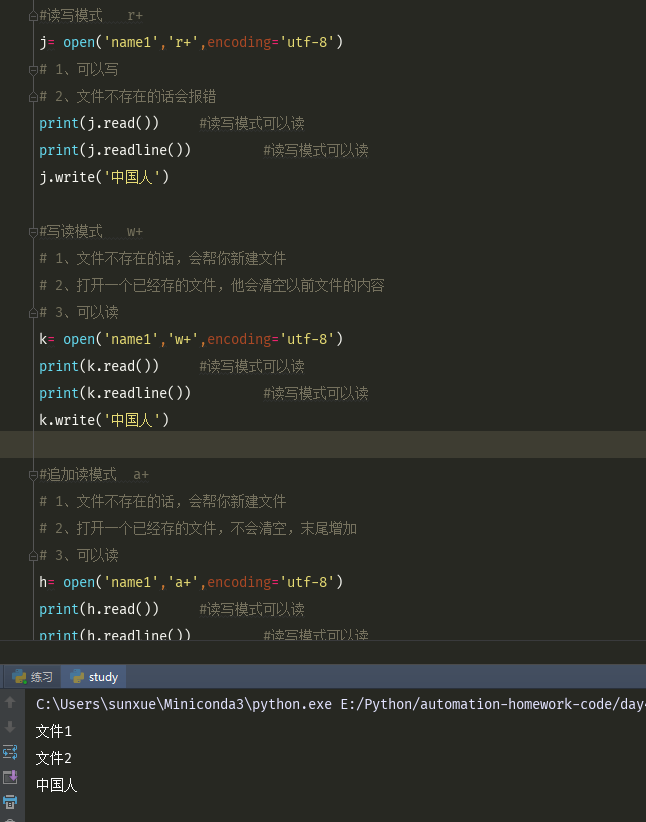
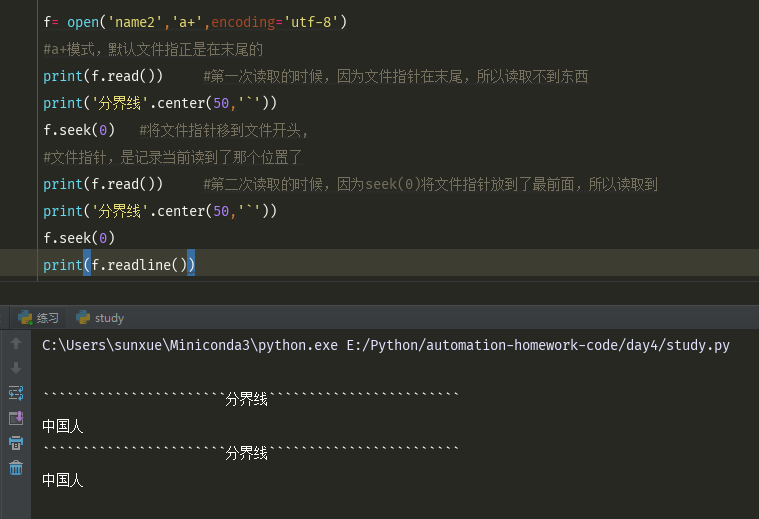
f= open('name2','a+',encoding='utf-8') #a+模式,默认文件指正是在末尾的 print(f.read()) #第一次读取的时候,因为文件指针在末尾,所以读取不到东西 print('分界线'.center(50,'`')) f.seek(0) #将文件指针移到文件开头, #文件指针,是记录当前读到了那个位置了 print(f.read()) #第二次读取的时候,因为seek(0)将文件指针放到了最前面,所以读取到 print('分界线'.center(50,'`')) f.seek(0) print(f.readline())
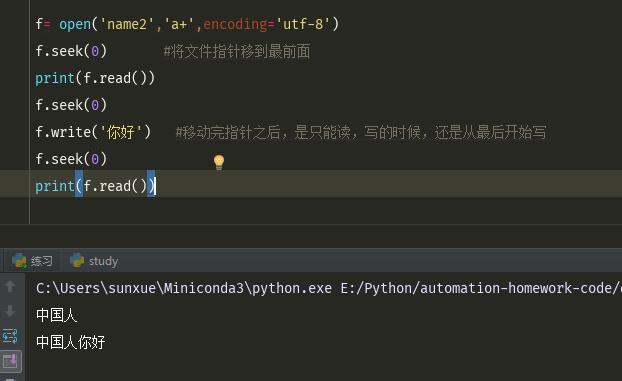
f= open('name2','a+',encoding='utf-8') f.seek(0) #将文件指针移到最前面 print(f.read()) f.seek(0) f.write('你好') #移动完指针之后,是只能读,写的时候,还是从最后开始写
练习:
随机生成手机号码
保存到文件中
如下,随机产生的号码如下:
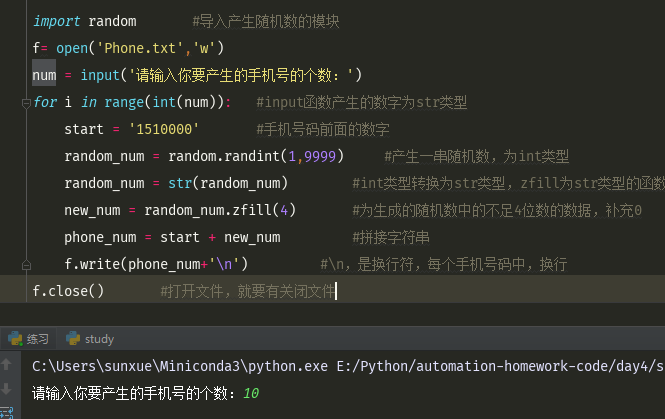
import random #导入产生随机数的模块 f= open('Phone.txt','w') num = input('请输入你要产生的手机号的个数:') for i in range(int(num)): #input函数产生的数字为str类型 start = '1510000' #手机号码前面的数字 random_num = random.randint(1,9999) #产生一串随机数,为int类型 random_num = str(random_num) #int类型转换为str类型,zfill为str类型的函数 new_num = random_num.zfill(4) #为生成的随机数中的不足4位数的数据,补充0 phone_num = start + new_num #拼接字符串 f.write(phone_num+'\n') #\n,是换行符,每个手机号码中,换行 f.close() #打开文件,就要有关闭文件
练习2:
# 1、监控日志,如果有攻击咱们的,就把ip加入黑名单
#分析:
#1、打开日志文件
#2、把ip地址拿出来
#3、判断每一个ip出现的次数,如果大于100次的话,加入黑名单
#4、每分钟读一次
只统计一个文件中的数据,且文件中的数据不会变化的情况,如下
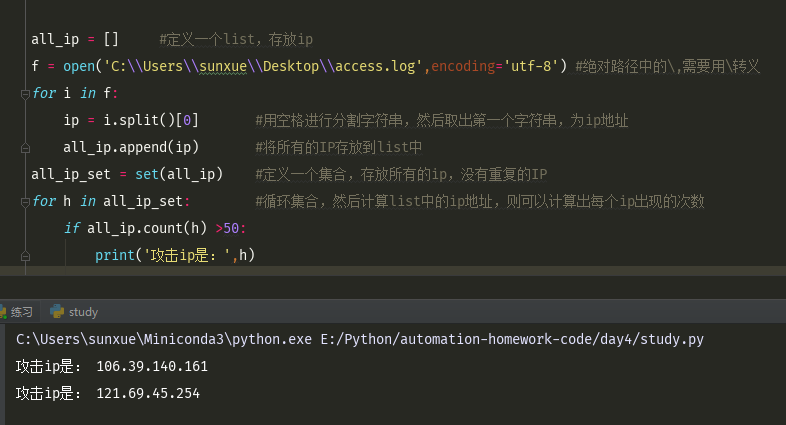
循环执行,每隔60秒,统计一次
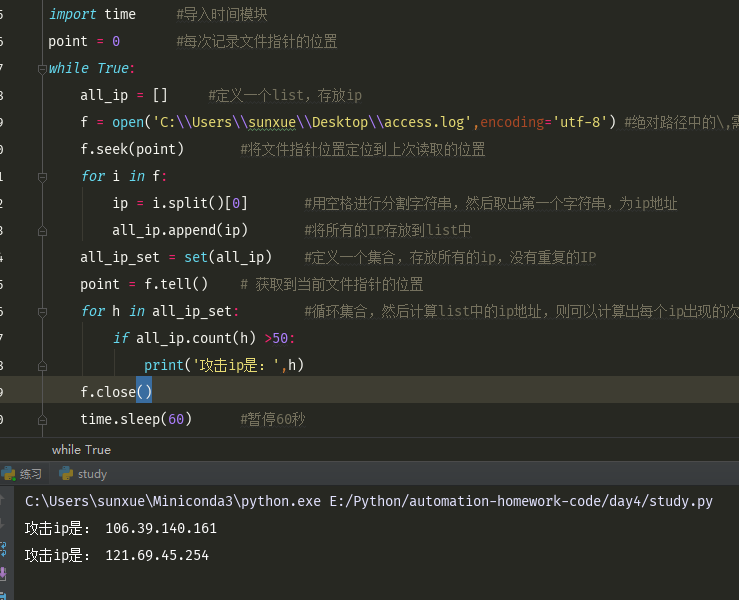
import time #导入时间模块 point = 0 #每次记录文件指针的位置 while True: all_ip = [] #定义一个list,存放ip f = open('C:\\Users\\sunxue\\Desktop\\access.log',encoding='utf-8') #绝对路径中的\,需要用\转义 f.seek(point) #将文件指针位置定位到上次读取的位置 for i in f: ip = i.split()[0] #用空格进行分割字符串,然后取出第一个字符串,为ip地址 all_ip.append(ip) #将所有的IP存放到list中 all_ip_set = set(all_ip) #定义一个集合,存放所有的ip,没有重复的IP point = f.tell() # 获取到当前文件指针的位置 for h in all_ip_set: #循环集合,然后计算list中的ip地址,则可以计算出每个ip出现的次数 if all_ip.count(h) >50: print('攻击ip是:',h) f.close() time.sleep(60) #暂停60秒

 浙公网安备 33010602011771号
浙公网安备 33010602011771号