[原]分享一下我和MongoDB与Redis那些事
缘起:来自于我在近期一个项目上遇到的问题,在Segmentfault上发表了提问
知识背景:
对不是很熟悉MongoDB和Redis的同学做一下介绍。
1.MongoDB数组查询:MongoDB自带List,可以存放类似这样的结构 List = [1, 2, 3, 4, 5, 6, 7, 8, 9].
如果我们有一个 l = [2, 3, 8], 则可以进行这样的查询:spce = { 'List' : { '$in' : l }, 这里spce就是一个查询条件,代表 l 是 List的一个子集。
2.Redis队列: Redis提供基本的List(普通链表),set(集合),Zset(有序集合) 类型的结构,将List的 lpush, rpop操作运用起来,可以做一个普通的队列,运用Zset 可以做一个带权值的最小堆排序的队列(可以看做优先级)。
整体架构如下图所示:
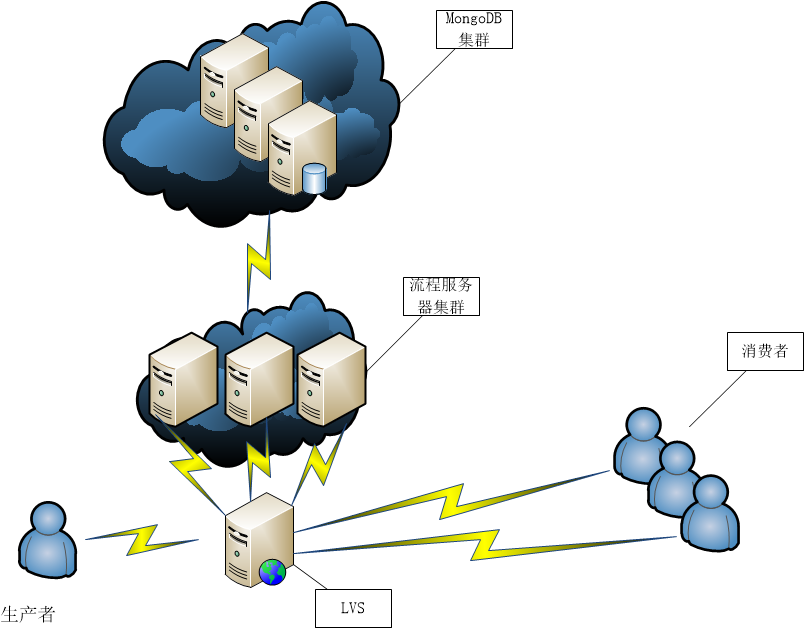
生产者产生任务,通过LVS与RPC服务器将任务记录到MongoDB,消费者同样通过RPC服务获取任务,这是个很简单的架构,一般服务可能去掉集群都是这样的。
整个业务架构需要一个前提,任务不能丢失,也就是说任务即使失败也需要重新加入到队列,至少若干次后任然失败也要知道为什么失败(非记录日志形式)。
很多人问为什么不直接用RabbitMQ或者Redis,因为这类消息队列无法做到管理任务超时等情况,因为业务需要,也需要做一些简单的查询,这类队列是不支持某些稍复杂的查询的,而且一开始我们的任务量估计在5KW/Day这样,担心Redis扛不住,后来我发现这是个错误的假设。
问题内容如下:
问题背景: 近期在重构公司内部一个重要的任务系统,由于原来的任务系统使用了MongoDB来保存任务,客户端从MongoDB来取,至于为什么用MongoDB,是一个历史问题,也是因为如果使用到MongoDB的数组查询可以减少任务数量很多次,假设这样的情况,一个md5(看做一条记录的唯一标识)需要针对N种情况做任务处理,如果用到MongoDB的数组,只需要将一个md5作为一条任务,其中包含一个长度为N的待处理任务列表,可以使用到MongoDB的数组(只有N个子任务都处理完后整个任务才算处理完毕),这样整个任务系统的数量级就变为原来的 1/N(如果需要用到普通的关系型数据库,可能需要创建 m*n 个任务,这样算下来我们的任务数量将可能达到一个很大的值,主要是因为处理任务的进程由于某些不确定因素无法控制,所以比较慢)
细节描述: 1.当MongoDB的任务数量增多的时候,数组查询相当的慢(已经做索引),任务数达到5K就已经不能容忍了,和我们每天的任务数不在一个数量级。
2.任务处理每个md5对应的N个子任务必须要全部完成才从MongoDB中删除
3.任务有相应的优先级(保证高优先级优先处理),任务在超时后可以重置。
改进方案如下: 由于原有代码的耦合,不能完全抛弃MongoDB,所以决定加一个Redis缓存。一个md5对应的N个子任务分发到N个Redis队列中(拆分子任务)。一个单独的进程从MongoDB中向Redis中将任务同步,客户端不再从MongoDB取任务。这样做的好处是抛弃了原有的MongoDB的数组查询,同步进程从MongoDB中取任务是按照任务的优先级偏移(已做索引)来取,所以速度比数组查询要快。这样客户端向Redis的N个队列中取子任务,把任务结果返回原来的MongoDB任务记录中(根据md5返回子任务)。
改进过程遇到的问题: 由于任务处理端向MongoDB返回时候会有一个update操作,如果N个子任务都完成,就将任务从MongoDB中删除。这样的一个问题就是,经过测试后发现MongoDB在高并发写的情况下性能很低下,整个任务系统任务处理速度最大为200/s(16核, 16G, CentOS, 内核2.6.32-358.6.3.el6.x86_64),原因大致为在频繁写情况下,MongoDB的性能会由于锁表操作急剧下降(锁表时间可以达到60%-70%,熟悉MongoDB的人都知道这是多么恐怖的数字)。
具体问题: (Think out of the Box)能否提出一个好的解决方案,能够保存任务状态(子任务状态),速度至少超过MongoDB的?
提出这个问题后,很感谢官方将问题发到微博首页,有一个回答我觉得可以采纳:
初步的思考了一下,仅供参考:
首先,提一下索引,相信这个你应该加了索引。
有个问题确认一下,mongodb最新版本中的锁粒度还是Database级别吧,不知道你用的哪个版本,还没到锁表(Collection)这个粒度,所以写并发大的情况下比较糟糕,不过应该性能也不至于糟到像你描述的那样啊?不解,建议考虑任务分库的可能性?
能否考虑把子任务的状态和主任务的状态分开保存。子任务的状态,可以放到redis,主任务只负责自己本身的状态,这样每个主任务更新频率降为1/N,可大大减少mongodb中主任务表的压力。
子任务完成或超时后,可否考虑后台异步单线程顺序同步mongodb的主任务状态?
上面这个Answer可以考虑,但是在做同步过程中发现很多问题。
在开发过程中发现,由单一进程从MongoDB向Redis同步数据,可以采取两种可参考的方案:
1.模拟MongoDB replication机制,一个进程模拟slave向master请求oplog,然后自己解析数据格式存放到Redis.
2.一个进程从MongoDB中按照优先级取数据然后同步到Redis.
两种参考方案各有优劣,我最终选择了第二种。
第一种方案
优点:
1.主MongoDB查询压力变小
2.以后业务扩展很方便(可以运用到查询缓存啊,读写分离什么的)
缺点:
1.可参考文档较少,需要模拟MongoDB replication的机制较为复杂
2.同步实时性无法估计确切时间
第二种方案:
优点:
1.编码相对简单,按照优先级做索引后查询不影响原有逻辑
2.开发较为灵活(似乎和第一点是一样的)
缺点:
1.(项目完成后测试不理想,具体原因会做说明)
2.同步进程单点,如果进程卡死或者机器崩溃会造成系统卡死
方案确定:由单一进程从MongoDB同步任务到Redis.
架构变迁到这样:

加上Redis,做到MongoDB的读写分离,单一进程从MongoDB及时把任务同步到Redis中。
看起来很完美,但是上线后出现了各种各样的问题,列举一下:
1.Redis队列长度为多少合适?
2.同步进程根据优先级从MongoDB向Redis同步过程中,一次取多少任务合适?太大导致很多无谓的开销,太小又会频繁操作MongoDB
3.当某一个子任务处理较慢的时候,会导致MongoDB的前面优先级较高的任务没有结束,而优先级较低的确得不到处理,造成消费者空闲
最终方案:

在生产者产生一个任务的同时,向Redis同步任务,Redis sort set(有序集合,保证优先级顺序不变),消费者通过RPC调用时候,RPC服务器从Redis中取出任务,然后结束任务后从MongoDB中删除。
测试结果,Redis插入效率。Redis-benchmark 并发150,32byte一个任务,一共100W个,插入效率7.3W(不使用持久化)
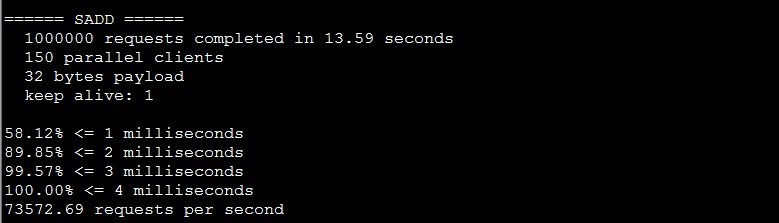
在这之前我们的担心都是没必要的,Redis的性能非常的好。
目前此套系统可以胜任每天5KW量的任务,我相信可以更多。后面有文章可能会讲到Redis的事务操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号