
LinkedHashMap源码分析
先来说说它的特点,然后在一一通过分析源码来验证其实现原理
1、能够保证插入元素的顺序。深入一点讲,有两种迭代元素的方式,一种是按照插入元素时的顺序迭代,比如,插入A,B,C,那么迭代也是A,B,C,另一种是按照访问顺序,比如,在迭代前,访问了B,那么迭代的顺序就是A,C,B,比如在迭代前,访问了B,接着又访问了A,那么迭代顺序为C,B,A,比如,在迭代前访问了B,接着又访问了B,然后在访问了A,迭代顺序还是C,B,A。要说明的意思就是不是近期访问的次数最多,就放最后面迭代,而是看迭代前被访问的时间长短决定。
2、内部存储的元素的模型。entry是下面这样的,相比HashMap,多了两个属性,一个before,一个after。next和after有时候会指向同一个entry,有时候next指向null,而after指向entry。这个具体后面分析,同时,这里提醒一点,在这里的header一般指的是虚拟节点(不通过用户加入的节点,只是一种虚拟表示)。

3、linkedHashMap和HashMap在存储操作上是一样的,但是LinkedHashMap多的东西是会记住在此之前插入的元素,这些元素不一定是在一个桶中,画个图。
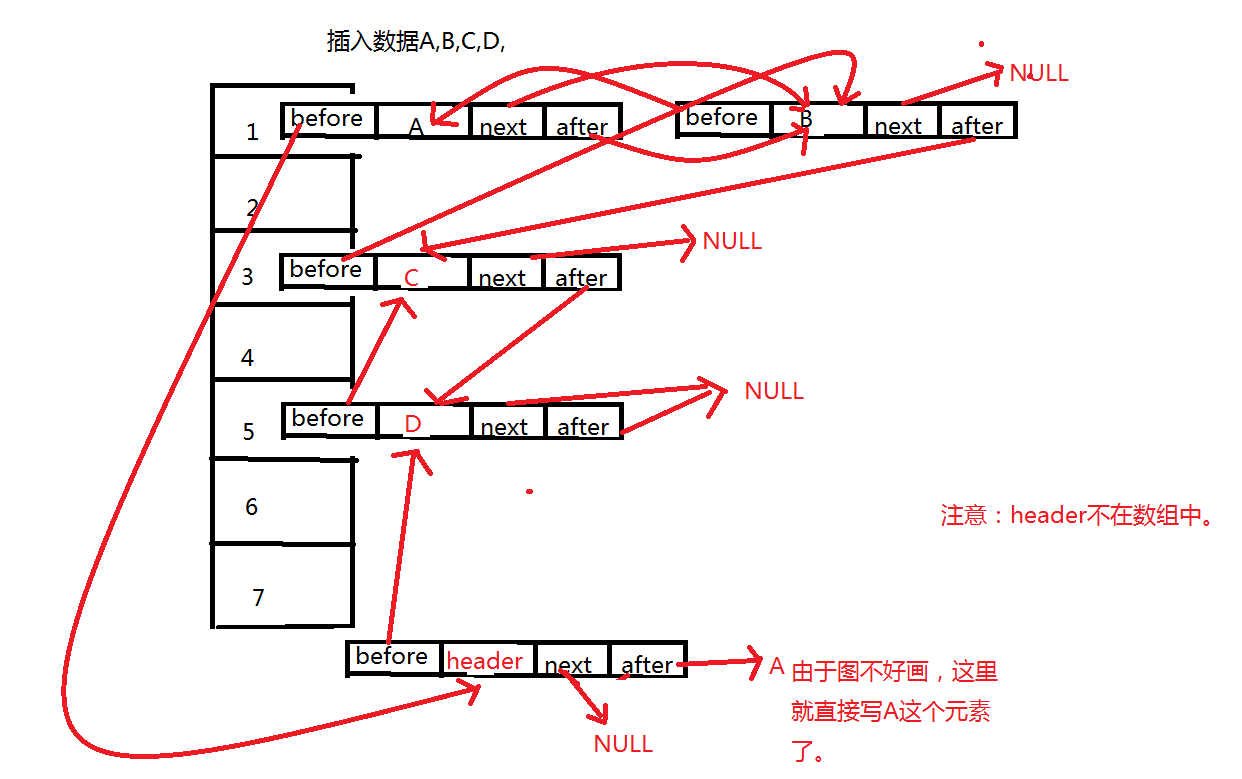
也就是说,对于linkedHashMap的基本操作还是和HashMap一样,在其上面加了两个属性,也就是为了记录前一个插入的元素和记录后一个插入的元素。也就是只要和hashmap一样进行操作之后把这两个属性的值设置好,就OK了。注意一点,会有一个header的实体,目的是为了记录第一个插入的元素是谁,在遍历的时候能够找到第一个元素。实际上存储的样子就像上面这个图一样,这里要分清楚哦。实际上的存储方式是和hashMap一样,但是同时增加了一个新的东西就是 双向循环链表。就是因为有了这个双向循环链表,LinkedHashMap才和HashMap不一样。
4、其他一些比如如何实现的循环双向链表,插入顺序和访问顺序如何实现的就看下面的详细讲解了。
/**
* LinkedHashMap entry.
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
//通过上面这句源码的解释,我们可以知道这两个字段,是用来给迭代时使用的,相当于一个双向链表,实际上用的时候,操作LinkedHashMap的entry和操作HashMap的Entry是一样的,只操作相同的四个属性,这两个字段是由linkedHashMap中一些方法所操作。所以LinkedHashMap的很多方法度是直接继承自HashMap。
//before:指向前一个entry元素。after:指向后一个entry元素
Entry<K,V> before, after;
//使用的是HashMap的Entry构造,调用父类构造器
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
//删除当前的entry
private void remove() {
before.after = after;
after.before = before;
}
//一般传进来的都是header,把当前的entry(也就是this)插入到链表的末尾,同时更新一下四个引用关系
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
//在LRU算法里,一般很少访问的元素都会排在双向循环链表的靠前部分,而经常访问的元素一般都是在双向链表的靠后部分,而这些功能就是取决于该方法的。当前的entry被访问到时,我们调用此方法,先删除掉当前链表里的
this(就是entry),然后再通过addBefore方法把this重新添加到链表的尾部,并且更新一下四个引用(当然这都是addBefore里的过程了),这样,访问到的元素就转移到了末尾,达到了活跃更新的状态
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
接下来就是常用方法操作了,例如put方法(该方法是继承于HashMap的):
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
//如果该entry存在,直接改值,然后将该entry移到末尾
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//注意,这里的addEntry方法是被LinkedHashMap覆盖了,所以调用的其实是LinkedHashMap的addEntry
addEntry(hash, key, value, i);
return null;
}
LinkedHashMap重写了void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex)
void addEntry(int hash, K key, V value, int bucketIndex) {
//先调用父类的addEntry,把元素添加进哈希链表中
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
//这里的header是虚拟节点,他的after是真正的最老的那个节点
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
我们创建一个entry,因为是新创建的,我们先计算出该entry在数组中的位置,然后把它添加到链表的第一个节点,这时候在双向链表中,新建的entry应该添加到双向链表的末尾,因为新创建是最新鲜的,所以我们应该移到末尾,如上图操作。
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
//把最新鲜的元素e转到双向链表的尾部
e.addBefore(header);
size++;
}
其实到这里,LinkedHashMap的常用操作流程已经差不多了
5、来看看迭代器的使用。对双向循环链表的遍历操作。但是这个迭代器是abstract的,不能直接被对象所用,但是能够间接使用,就是通过keySet().interator(),就是使用的这个迭代器
//主要是针对双向循环链表的遍历操作
private abstract class LinkedHashIterator<T> implements Iterator<T> {
// 要返回的值 Entry<K,V> nextEntry = header.after; Entry<K,V> lastReturned = null; int expectedModCount = modCount; // 只要nextEntry不是指向头节点,代表有元素 public boolean hasNext() { return nextEntry != header; } public void remove() { if (lastReturned == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key); lastReturned = null; expectedModCount = modCount; } Entry<K,V> nextEntry() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (nextEntry == header) throw new NoSuchElementException(); // 记录lastReturned,更新nextEntry,返回上一个nextEntry Entry<K,V> e = lastReturned = nextEntry; nextEntry = e.after; return e; } }
6、我们再来看看LinkedHashMap是如何实现访问顺序和插入顺序一致的,其实就是通过双向链表,我们找到LinkedHashMap的get方法,发现竟然是属于自己的
public V get(Object key) {
// getEntry方法是调用的父类的
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
之所以该Map可以达到访问顺序和插入顺序一致,双向链表功不可没,但是如果lm.accessOrder为true的话,这时候顺序就是一个全新的顺序,因为访问的顺序是不怎么访问的元素靠前,而经常访问的元素靠末尾。
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
总结:
(1)LinkedHashMap和HashMap在数组链表存储时都是一样的
(2)LinkedHashMap的老元素靠前,新元素靠后,取决于accessOrder属性和recordAccess方法
(3)LinkedHashMap是HashMap的子类,实现的原理跟HashMap差不多,唯一的区别就是LinkedHashMap多了一个双向循环链表。因为有双向循环列表,所以LinkedHashMap能够记录插入元素的顺序,而HashMap不能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号