

Microsoft Naive Bayes 算法——三国人物身份划分
Microsoft朴素贝叶斯是SSAS中最简单的算法,通常用作理解数据基本分组的起点。这类处理的一般特征就是分类。这个算法之所以称为“朴素”,是因为所有属性的重要性是一样的,没有谁比谁更高。贝叶斯之名则源于Thomas Bayes,他想出了一种运用算术(可能性)原则来理解数据的方法。对此算法的另一个理解就是:所有属性都是独立的,互不相关。从字面来看,该算法只是计算所有属性之间的关联。虽然该算法既可用于预测也可用于分组,但最常用于模型构建的早期阶段,更常用于分组而不是预测某个具体的值。通过要将所有属性标记为简单输入或者既是输入又是可预测的,因为这就可以算法在执行的时候考虑到所有属性。在标记属性时的工作量可能有些大。很常见的情况是,在输入中包含大量属性,然后处理模型再评估结果。如果结果看起来没什么意义,我们经常减少包含的属性数量,以便更好地理解关联最紧密的关系。
如果拥有大量数据,而对数据的了解又很少,这时可以使用朴素贝叶斯算法。例如,公司可能由于兼并了一家竞争对手而获得了大量销售数据。在处理这类数据的时候,可以用朴素贝叶斯作为起点。
应该了解的是,这个算法有一个明显的局限,只能处理离散(或离散化)的内容类型。如果选择的数据结构中包含有内容类型不是Discrete(如Continuous)的数据列,那么朴素贝叶斯建立的挖掘模型会忽略这些数据。
朴素贝叶斯算法有4个可以配置的参数:MAXIMUM_INPUT_ATTRIBUTE、MAXIMUM_OUTPUT_ATTRIBUTE、MAXIMUM_STATUS、MINIMUM_DEPENDENCY_PROBABILITY。可以在“值”中输入新值来修改配置的(默认)值。这个信息在“算法参数”对话框的“说明”区中有说明。
有人可能想知道是否经常需要调整算法参数的默认值。我们发现,随着对各个算法功能的逐渐了解,我们开始倾向于手动调节。因为朴素贝叶斯频繁地用于数据挖掘项目,尤其用于项目的早期,所以我们发现自己经常要调整它的相关参数。前3个参数的作用一目了然:调整配置的值为的是减少输入值、输出值或分组状态的最大数量。最后的依赖关系可能性的意义不太明显。在减小这个值的时候,实际是在要求减少模型生成的节点或分组的数量。
下面我们进入主题,同样我们继续利用上次的解决方案,依次步骤如下:


选择所需输入变量与预测变量,以及索引键。此例以序列为索引,身份为预测变量,选中统率、武力、智力、政治、魅力五个变量为输入变量,完成后点击“确定”按钮,这时会到原来的页面,点击“下一步”按钮,如图所示。
选择正确的数据属性,修正了变量的数据属性后点击“下一步”按钮。
更改挖掘结构名称,点击“完成”按钮。
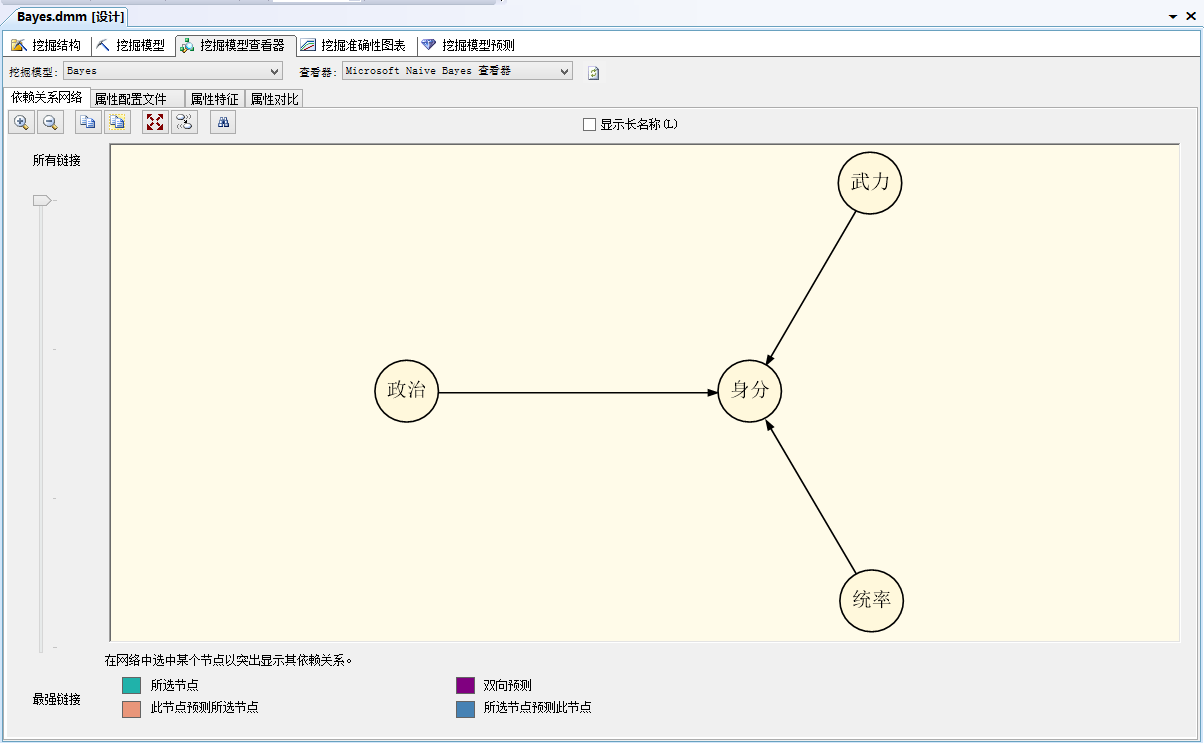
挖掘模型查看器则是呈现此依赖关系网络,对于数据的分布进一步加以了解。
从“属性配置”文件可以了解每个变量的特性分布状况。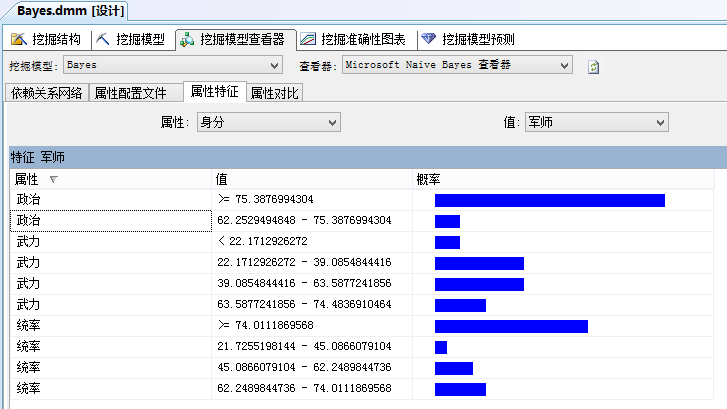
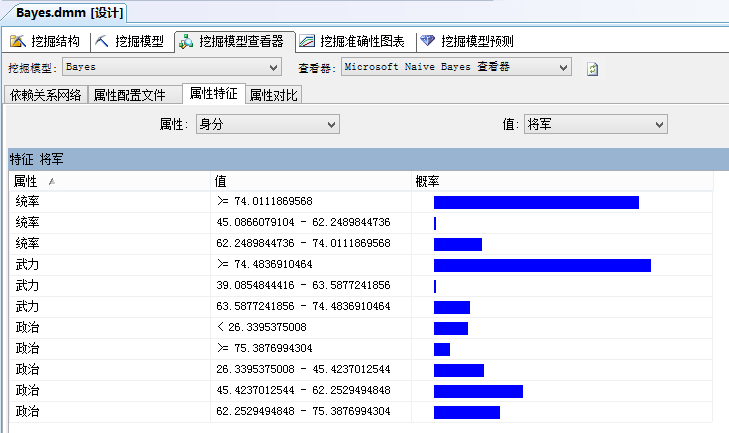
而从“属性特性”可以看出,不同群的基本特性概率。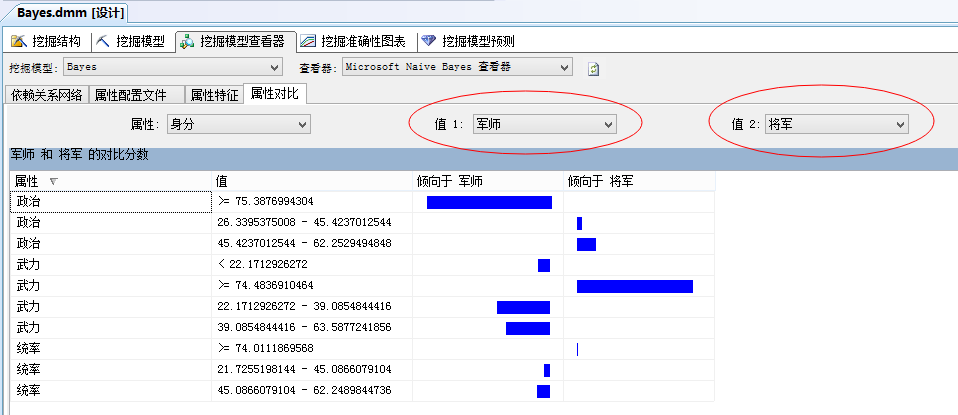
而从“属性对比”中,主要可以比较不同群体的特性。
参考文献:
Microsoft Naive Bayes 算法
http://msdn.microsoft.com/zh-cn/library/ms174806(v=sql.105).aspx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号