新兴 Python 算子开发:Triton、CuteDSL、MOJO 🔥等概览
我最近3个月都在研究Python DSL,在此记录下我的一些想法。目前还在学习中,若理解有偏差,烦请指正。
DSL 即 Domain Specific Language,是指为特定领域(domain)设计的专用语言,广为人知的包含 HTML、SQL和正则表达式。本文讨论的内容更准确的名词是eDSL,e即embedded,表示复用Python语法,使用编译器来改变代码运行的方式。
AI模型的开发通常在Python上进行,并运行在GPGPU上。但是Python是不能运行在GPU上的,为了方便研究人员,OpenAI构建了Triton。Triton非常Pythonic,用户不需要熟练硬件架构和CUDA,就能方便得写出高性能代码。Python DSL能否在极致性能和可用性两全其美?这大概是需要奋斗且不太好达到的目标。Python DSL是不是绕道而行,有可能改变现有CUDA生态吗?目前看已经让CUDA拥抱Python了,CUDA: New Features and Beyond,Nvidia更是宣布要用CuTile解决以前库太多的问题。最终结果要交给时间检验,其本质还是tradeoff,No Silver Bullet。
6.23更 关注性能的朋友有福了,群友为我推荐了pytorch-labs/tritonbench这个项目,我将加更在最后做下性能对比。
一、triton-lang/triton 15.9k
AI的Kernel运算非常规整,往往做下tile就能拿到性能。所以Triton的设计就是牺牲部分通用性换来DSL的简洁,Triton不用关心线程组织,只需要关心 tile 和 核心部分hardcode float的配置。Triton还有一个重要议题就是支持Nvidia显卡最新的feature,编程模型在改变,DSL因为抽象更高级,拿到甜点性能还是非常方便的。GPU 计算与编程模型演进:异步计算编程中的吞吐与延迟平衡
1、介绍
Triton作者Tillet关于其设计的论文发表在MAPL2019,其设计了多层 tiling、自动优化等核心特性,希望通过 类C语言的DSL + 编译器 支持 tile 编程。之后用MLIR重构了,并使用了Python做为前端语言就一发不可收拾了,2023年3月Pytorch2.0的发布为我们带来了Triton的Inductor的接入。
在Triton代码的编写中我们更关心一个Block,用户不需要感知shared memory。Triton借助Layout设计以及Pass优化,能够减轻用户写kernel的负担,也能保证一定的性能,关于Triton和CUDA的对比如下图所示,来源Pytorch2023会议

随着FlagTree的开源,目前Triton有nvidia、amd、intel、cpu、华为昇腾、摩尔线程、沐曦、昆仑芯、ARM china、清微智能、天数智芯、寒武纪(部分) 共12个后端,当然其他公司也做了,但是没开源。
Triton能很轻松得写出性能不错的kernel,在矩阵乘的kernel上你能很轻松得用上tma,对比native的CUDA kernel,可以在B200上获得近5倍的加速。matmul.cu vs matmul-with-tma.py
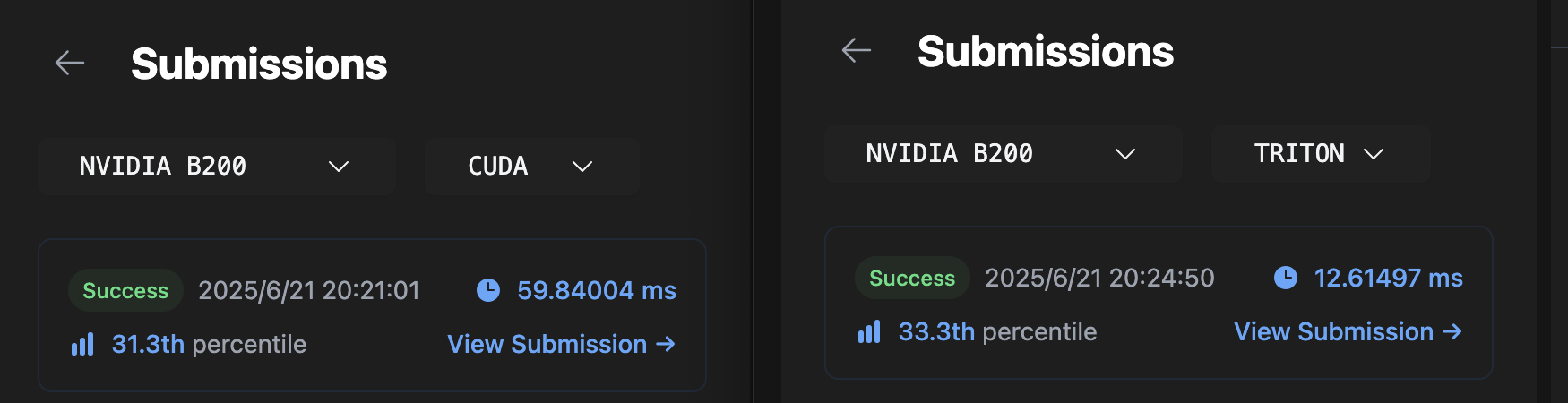
真正部署的话性能确实有些着急,
我也在尝试做一个Triton的开源OpenCL后端,为想要接入Triton的公司提供样本。有兴趣可以关注OpenMLIR/triton-spirv。triton-spirv项目文档
我的另一篇文章更详细介绍了Triton的执行流程,有兴趣可以阅读。浅析 Triton 执行流程
现在DSL大战一触即发,打响Triton保卫战刻不容缓,Triton upstream 在做kernel的bench。python/triton_kernels
2、扩展相关
ByteDance-Seed/Triton-distributed Seed对Triton做了扩展来支持通信,大模型时代通信计算融合是现在一个非常重要且具有挑战的议题,思泽提出了在Triton上添加通信Op,并做了实现。目前通算融合更多还是在框架层面用计算图做的,但是MegaKernel和FlashDMoE一经推出都反响很大。Triton-distributed: 用Python写出高性能计算通信重叠kernel
Triton在甜点性能拿到后,后续优化和硬件是强相关的,开发者为了性能必须要去开发Triton,这个难度不小。facebookexperimental/triton meta在搞TLX (Triton Low-level Language Extensions),把 warp-aware, hardware-near 带回Triton,以求拿到性能。把 Low-level 带回Triton也是有收益的,能拿到性能,缺点就是Triton也要变成NVIDIA的形状。
NPU/DSA的粒度相比GPGPU要更粗,造一整套工具链轮子和打磨多年CUDA的竞争是非常难的,也可以直接在Triton上做适配。microsoft/triton-shared 最先对lower到linalg这个层级的dialect做了探索,拿到了不错的效果,后续的很多项目都基于此做了实现。另外当前Triton的Op定义对于这种粗粒度的硬件是远远不够的,python/triton/language/standard.py 文件里我们可以看到有些函数如sigmoid是直接用的数学实现,这些在NPU/DSA往往有自己的lower路径,另外硬件可能提供了更多的函数抽象需要在Triton这边扩展。抽象High-level Op比提供Low-level op影响相对小一点,毕竟NPU/DSA声量也不够大,基本还在手搓算子甚至是IR。这会不会又让Triton成DSA的形状呢,总之做一个公平的标准很难,OpenCL之死值得警惕。
目前Triton主线是不太关心这些的,他们非常严格得控制着自己的编程模型。这一点有点像语言委员会,或许他们的心目中理想硬件就应该是他们坚守的编程模型模样。
3、生态相关
有了一个可视化与分析工具pytorch-labs/tritonparse。我对GPU的调试全靠print,Triton的print并不好用,去Debug IR是一件常见的事情,感谢作者。TritonParse:Triton IR 编译的可视化工具
还有人在整活Mogball/triton_lite,Triton 风格接口的MOJO,还提供了一个在torch.compile来把Triton替换为MOJO。我觉得项目想要达成的目标就是进一步细化粒度,想推Triton前端的统一化,替换掉它的编译器后端。
Triton更多的生态体现在诸如Pytorch、vllm、sglang、flash-attention等对于Triton的接入,项目已经形成了一定影响力。我们还可以看到srush/Triton-Puzzles 这样非常精美的Triton教程,甚至还有了Triton培训班。
二、pytorch-labs/helion 0.16k
helion是一个面向Tensor的DSL,比Triton的抽象层级更高。在这一级想做出性能是非常难的,但是他们将kernel编译到了Triton,直接拿Triton的性能。挺有意思的,如果说一款新的芯片为了生态完全可以借鉴这个思路,abstract is all you need。
三、NVIDIA/cutlass(CuTeDSL) 7.7k
Nvidia看到Triton的成功还是比较眼红的,很快就开始反击了,Nvidia作为一家成熟的商业公司估计在杨军老师去给Triton做支持就有想法了。
CuTeDSL和CUDA类似,是thread级别,以CuTe抽象为中心。改用MLIR后带来的首要收益是编译速度的显著提升,当前还有Pytorch的集成。
-
支持DLPack接口,我可以直接用Pytorch申请的tensor,直接check答案。当然其他AI框架也可以,零拷贝、跨框架的数据互操作的收益很大。
-
将静态layout转换为动态layout,通过mark_layout_dynamic来避免JIT functions的重复编译。
-
直接集成到AI模型中,你可以把你的算子直接替换进去,这也是Pythonic带来的收益。这也是为什么Pytorch、vllm、sglang都集成了Triton的原因,无感接入的感觉很爽。
Python还能为用户带来什么呢,Nvidia不得不暴露一些interface出来,被迫开源。安装Python包后在site-packages文件就可以看到。OpenMLIR/CuTeDSLSource
我也将在下面的文章继续对其进行持续探索。CuTe DSL(CUTLASS Python)的初步实践ing
四、tile-ai/tilelang 1.3k
基于TVM的thread级别的primitives(原语),有如下三种编程接口。
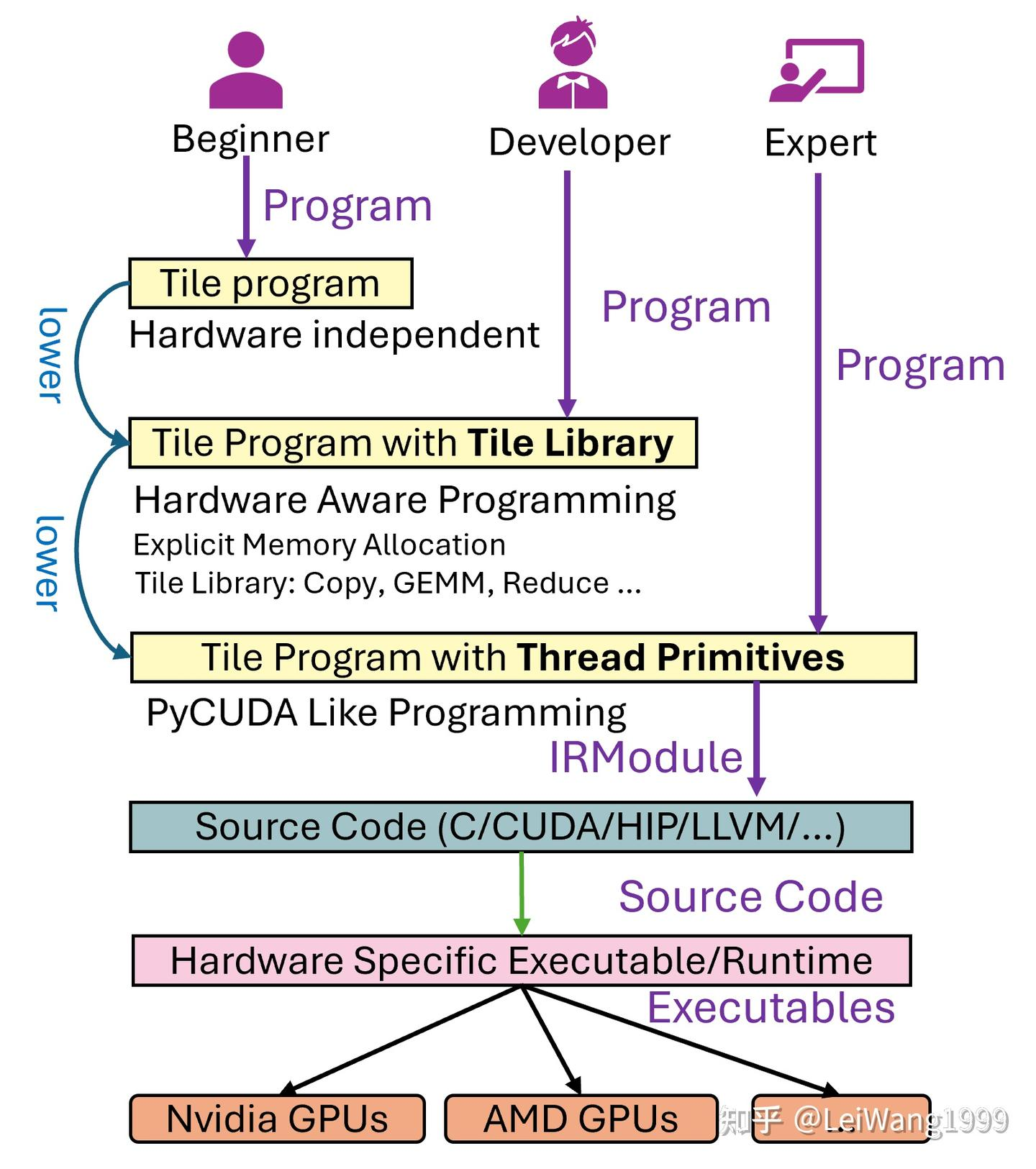
能显式声明内存,能显式控制线程了。当然你也可以选择不控制,对于大多数用户我认为就在Developer这一层级,可能meta Triton tlx会达到和这边差不多的效果。这个设计理念是非常好的,不仅支持3种语法,且这三种语法可以出现在同一个program中。
我们不容忽视的是tilelang在推理部署的实力,好搓性能又好。我感觉CuTeDSL很快就会和其竞争起来,因为既然想要性能那肯定要追求到底,看双方的算子大师们的进度和实际性能了。
五、apache/tvm 12.4k
TVM 是一个非常完善的深度学习框架,且提供了DSL的算子书写。近几年热度在减退,Pytorch更好用已成为事实标准AI框架。
TVM中的Tensor Expression、TensorIR都是适合写算子的,Relax主要描述计算图。TileLang实际上是TensorIR 的用户层 DSL 抽象,
TE(Tensor Expression)提供了丰富的并行抽象:可以使用s.bind(axis, te.thread_axis("blockIdx.x"))、("threadIdx.x")等将循环轴绑定到GPU线程块和线程上,支持unroll循环展开、vectorize向量化,并通过cache_read/cache_write引入共享内存缓存等手段优化访存。TE 具有完整的可调度性接口,并支持 AutoTVM/AutoScheduler 等自动调优框架,在此基础上可搜索最佳调度策略以实现高效的GPU内核生成。
TensorIR 设计定位于前端算子建模完成后、生成硬件代码前的阶段,承接 TE 或高层IR的计算,并提供完全可调度的循环级别结构。这个是我们想要用户控制的那个级别,但是语法风格是TVMScript式Python AST(显式循环+with T.block),偏命令式,用户还是不太能接受的。没事有TileLang。
六、modular/modular(MOJO) 24.3k
在AI民主化的终章,chris提出了自己的解决方案,就是MOJO,他想作为AI infra公司为各vendor提供服务。
我在LeetGPU对MOJO做了尝试。LeetGPU的MOJO 🔥 实践
MOJO写起来很像CUDA,也是thread级别。MOJO是强类型的语言,不支持implicit conversions(隐式类型转换),提供了@parameter做为编译期常量参数(compile-time constant)的修饰符。当然也有一些类似Triton的封装,但是why not CuTeDSL or tilelang。比较好的结局大概是被AMD收购,大多数vendor应该都没动力买它的服务,vendor对自己的硬件都很保密。
七、halide/Halide 6.1k
Halide 提供了 Python绑定,所以可以不用C++。主要用于图像处理、张量运算、信号处理等数据局部性强的场景,有独立的计算+调度语法。
八、Tiramisu-Compiler/tiraisu 0.94k
Tiramisu 受到 Halide 启发,但设计目标更偏向多层嵌套循环、复杂调度结构和 polyhedral 分析。基于 ISL,偏向手工 schedule。
九、NVIDIA的cuTile
准备阻击 Triton 的DSL,对标Triton。Vendor比用户更容易拿到性能,估计不会开源。

cuTile 软件设计
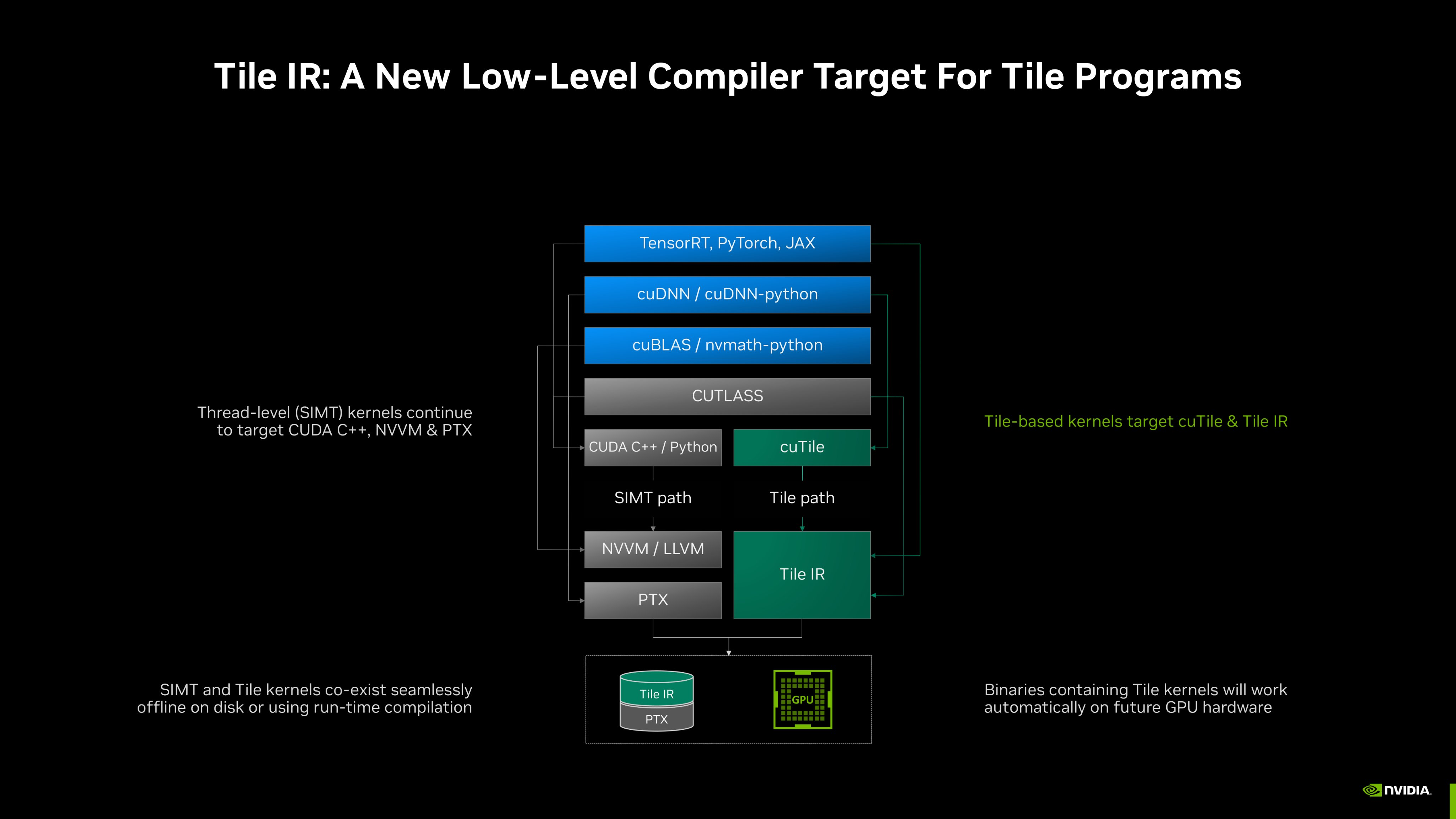
我在这里也说下我的看法,cuTile的性能需要跑过Triton这座大山比较多才能挤掉Triton已经占据的空间。不暴露底层接口看起来有困难的,但是从CuTeDSL那里搞点优化经验or用一些没暴露的硬件接口也能得到。Triton是开源的,用户可以修改Triton源码去拿到性能,开源对于想要榨干性能的客户是非常重要的。有Triton和CuTeDSL打样cuTile肯定是易用的,所以实际看Nvidia能为我们带来多少性能提升了,黑盒非常牛的话大家是会买账的。
十、pytorch-labs/tritonbench 性能对比
附录
HazyResearch/ThunderKittens 2.5k
偏框架了些,包含 DSL 风格的 kernel 定义和 schedule API,但是性能不错的,是C++
jax-ml/jax 32.6k
以 NumPy 风格为基础的高性能数值计算框架,支持自动微分(Autograd)、JIT 编译和 GPU/TPU 加速
Jittor/jittor 3.2k
深度学习框架
NVIDIA/warp 5.2k
评论区的大佬提到了NVIDIA的warp,写Python来进行物理仿真,用于机器人、布料、柔体、弹簧等模拟,1:1 复刻CUDA,也有点像框架。
本文来自博客园,作者:暴力都不会的蒟蒻,转载请注明原文链接:https://www.cnblogs.com/BobHuang/p/18939372

 浙公网安备 33010602011771号
浙公网安备 33010602011771号