Python 基于 NLP 的文本分类
这是前一段时间在做的事情,有些python库需要python3.5以上,所以mac请先升级 brew安装以下就好,然后Preference(comm+',')->Project: Text-Classification-m...->Project Interpreter->setting button->add,添加python的虚拟环境(usr/local/bin/python3.7),然后就去安装那些包
然后去github找一份代码学习下,在此之前请先连接这个技术需要什么,我找到了是这份代码Text-Classification
通过代码继续学习
我们需要掌握JieBa 分词的内部实现原理,了解 TF-IDF 统计方法的基本原理。然后进行网络的训练、网络的预测,以此来达到一个比较高的文本分类正确率。
我们需要大量的测试集,并给其标上标签,单一标签和多标签方法并不一样,当然我们经常面对的是多标签
深度学习文本分类模型:
1,fastText
原理:句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接连接一个 softmax 层进行分类。
2,TextCNN
原理: 利用CNN来提取句子中类似 n-gram 的关键信息。
改进: fastText 中的网络结果是完全没有考虑词序信息的,而TextCNN提取句子中类似 n-gram 的关键信息。
3,TextRNN
模型: Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 “n-gram” 信息。
改进: CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。
4,TextRNN + Attention
改进:注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献,基本成了Seq2Seq模型的标配了。实际上文本分类从某种意义上也可以理解为一种特殊的Seq2Seq,所以考虑把Attention机制引入近来。
5,TextRCNN(TextRNN + CNN)
过程:
利用前向和后向RNN得到每个词的前向和后向上下文的表示:
词的表示变成词向量和前向后向上下文向量连接起来的形式:
再接跟TextCNN相同卷积层,pooling层即可,唯一不同的是卷积层 filter_size = 1就可以了,不再需要更大 filter_size 获得更大视野。
上面那份代码使用的是TextCNN,我们可以来分析下这个的使用
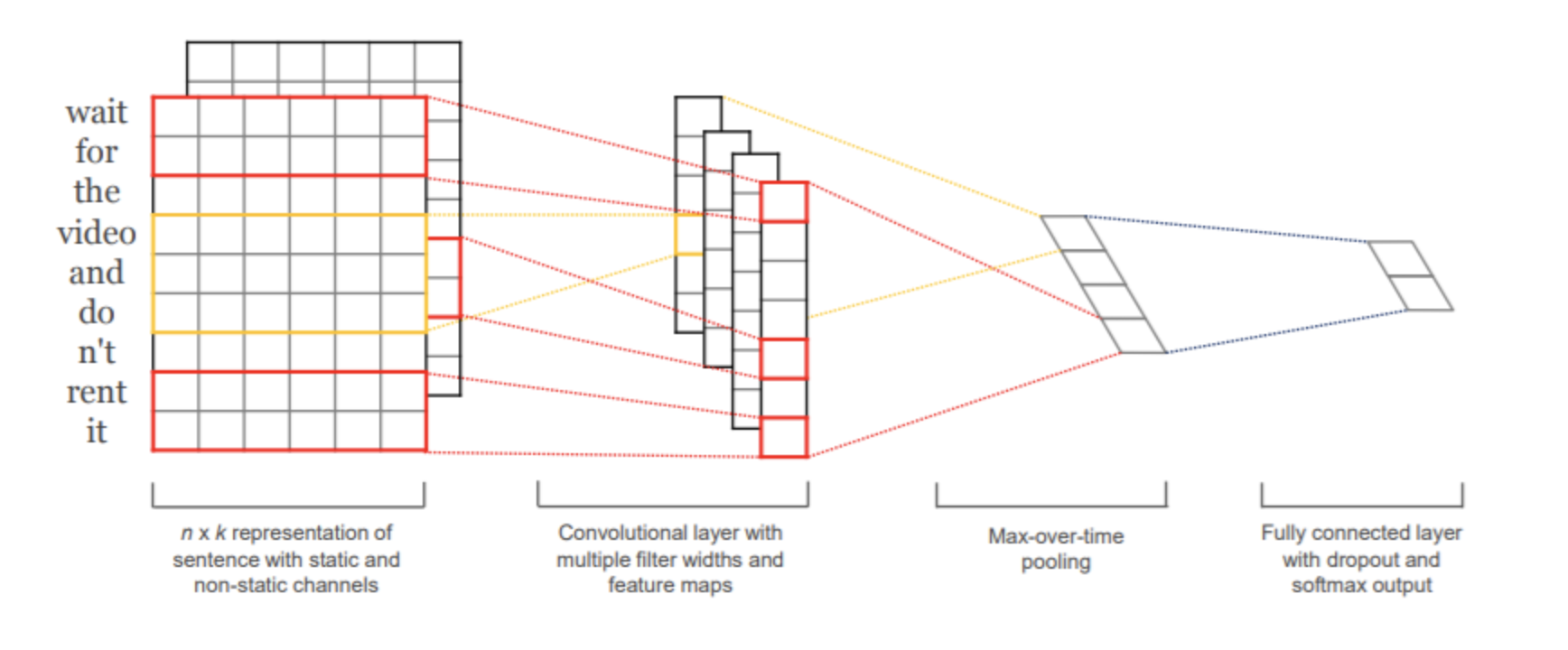
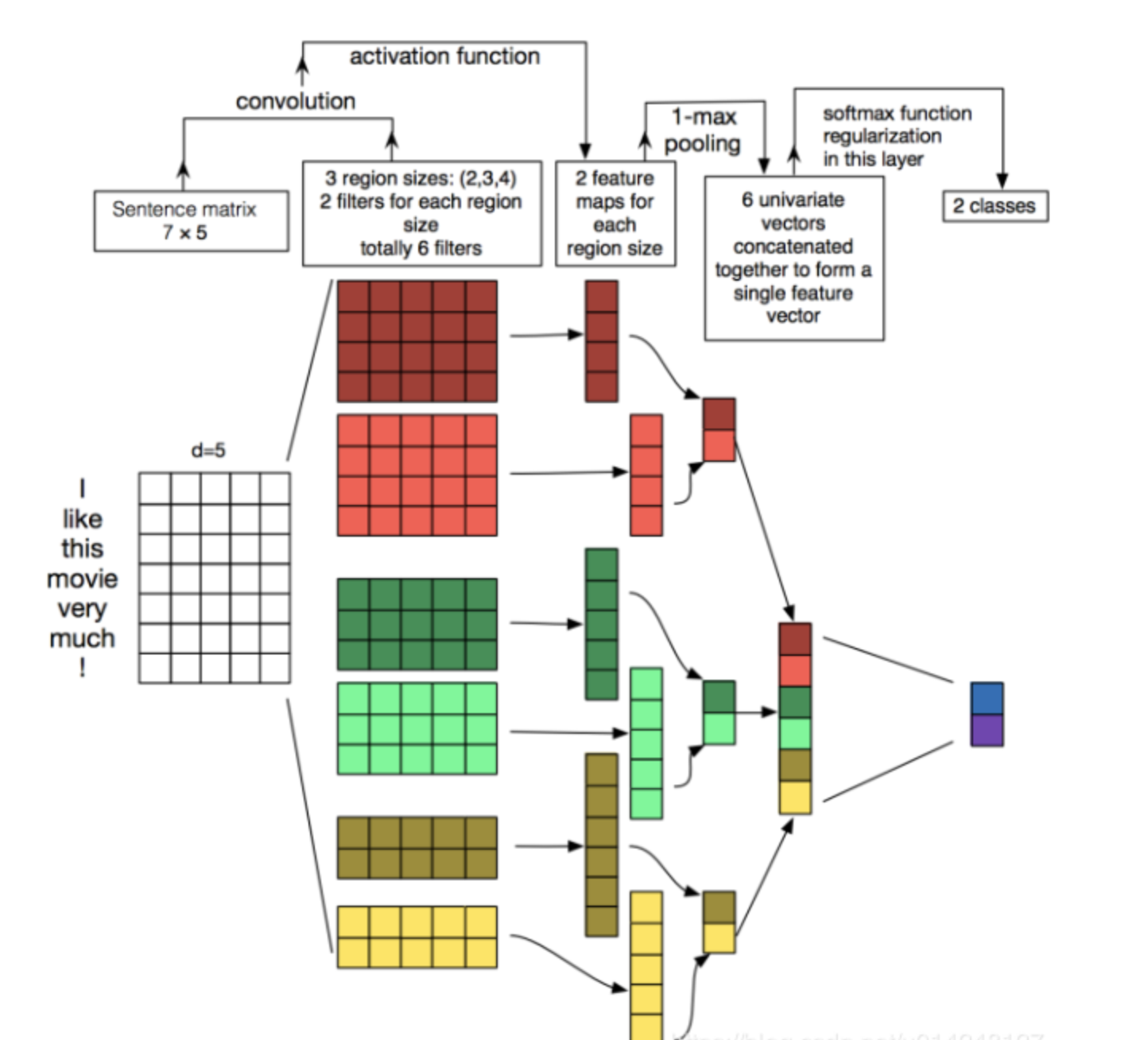
本文来自博客园,作者:暴力都不会的蒟蒻,转载请注明原文链接:https://www.cnblogs.com/BobHuang/p/11157489.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号