HashMap原理解析
Hash函数
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(关键字),通过散列算法,变换成固定长度的输出,该输出就是散列值。 这种转换是一种压缩映射(输入的长度小于输出的长度)。常见的Hash函数有以下几个:除留余数法、直接寻址法、数字分析法、平方取中法、分段折叠法、随机数法。
1. 除留余数法 : hash(k) = k % a. [其中,a为正整数]
直接以余数作为散列值。【HashMap中,a为HashMap的表长】
2. 直接寻址法:hash(k) = a * k + c .[其中,a,c为常数 & a <> 0]
直接以关键字的某个线性函数作为散列值。
3. 数字分析法 :
提取关键字中取值比较均匀(重复概率比较小)的数字作为散列值。例如:同一个班级的学生的生日,年份的重复率比较高,冲突的概率大,所以取值的时候就尽量避开年份。
4. 平方取中法:hash(k) = (k^2) / (10^a) % (10^b) [其中,a,b为正整数 & a > b]
取关键字平方后的中间几位为哈希地址。
5. 分段折叠法 :
将关键字分成长度相等的几段(最后一段可以短一些),将几部分相加,舍弃最高位的结果作为散列值。
6. 随机数法 :
采用一个随机数作为散列值。(计算机中没有真正的随机数,所谓的随机数都是通过某种算法获取。既然有算法,就不可能真正的随机)
Hash碰撞
对不同的关键字可能得到同一散列地址,即key1≠key2,而hash(key1)=hash(key2),这就是hash碰撞。衡量一个哈希函数的好坏的重要指标就是发生碰撞的概率以及发生碰撞的解决方案(任何哈希函数基本都无法彻底避免碰撞)。常见的解决碰撞的方法有以下几种:链地址法、开放地址法、再哈希法、建立公共溢出区。
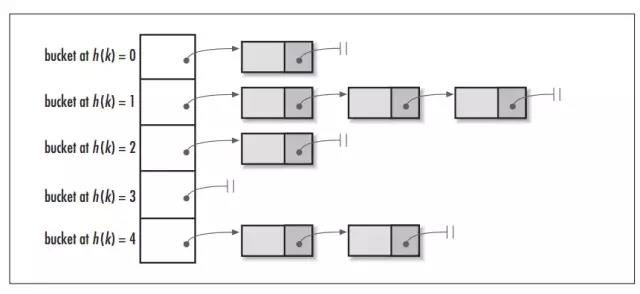
1. 链地址法:将哈希表的每个单元作为链表的头结点,所有散列值(即哈希地址)相同的元素添加到一个链表里。
2. 开放地址法:一旦发生Hash碰撞,就去寻找下一个空的哈希地址。
3. 再哈希法:当Hash碰撞时,就再次通过hash函数计算出新的哈希地址,直到碰撞不再发生。
4. 建立公共溢出区:将哈希表分为基本表和溢出表两部分,放生Hash碰撞的元素都存入溢出表中。
HashMap
1. 继承关系

2. 存储结构【对于哈希地址相同的key-value对象,依次被添加到链表的尾端】
2.1 Java8中,HashMap采用数组+链表+红黑树实现。【Node<K,V>[] table】
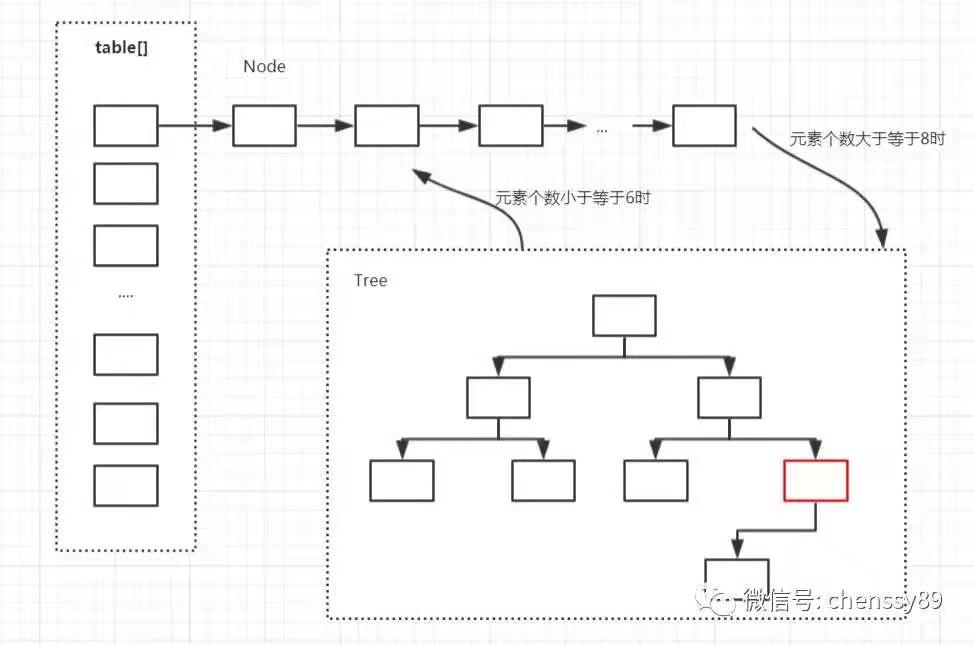
2.2 Java7中,HashMap采用数组+链表实现。
3. 实现过程
3.1 在添加元素时,会根据hash值算出元素在数组中的位置[index = hash & (length - 1)],如果该位置没有元素,直接把元素放到该处,如果该位置已经有元素,则把该元素以链表的形式放置在链表的尾部。当链表和数组的长度达到一定程度时,则把链表转化为红黑树。
3.2 当容量达到64且链表长度达到8时进行树化,当链表小于6时进行反树化。
4. HashMap采用链地址法解决Hash碰撞(采用除留余数法确定数组下标),链表对象(Entry<K,V>)的存储地址(即:索引)是通过hash(int h)和indexFor(int h, int length)联合获取的。
/** * 该方法是为了获取高质量的hashCode,即:减少碰撞的概率,尽量做到任何一位的变化都能对最终得到的结果产生影响。 * 算法思想:把高位的特征和低位的特征组合起来 */ //Java 7 static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } //Java 8 static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
/** * 该方法是为了获取数组的下标。 * 算法思想:将hashcode对数组的长度取模
* Java8中移除了该方法,在计算位置时直接使用该算法
*/ static int indexFor(int h, int length) { //等价于: h % length //因为数组的长度恒等于2^n,所以可以通过位运算符计算(直接对内存操作,不用转换成十进制,效率高) //位运算还可以很好的解决负数的问题(负数的模运算结果仍为负数,但是位运算返回的结果为正数). return h & (length-1); }
5. Java 7中使用单向链表存储冲突元素,Java 8中使用平衡树来替代链表存储冲突的元素。在最坏的情况下,Java7将HashMap的get方法的性能为 O(n),Java 8的性能为O(logn) 。如果恶意程序知道我们用的是Hash算法,则在单向链表情况下,它能够发送大量请求导致哈希碰撞,然后不停访问这些key导致HashMap忙于进行线性查找,最终陷入瘫痪,即形成了拒绝服务攻击(DoS)。
6. HashMap的数组是有长度的,Java中规定这个长度只能是2的倍数(即:size = 2^n),初始值为16。每次扩容为原来的二倍。
7. HashMap 的实现不是线程同步的,这意味着它不是线程安全的。
8. 加载因子:是哈希表在其容量自动增加之前可以达到多满的一种尺度,默认值为0.75。【当哈希表的数据量 >=(容器*加载因子)时,哈希表将进行扩容】
9. 数组的查询效率是O(1),链表的查询效率是O(k),红黑树的查询效率是O(log k)
10. New HashMap()的时候只是初始化参数,真实创建是在第一次调用put()的时候.
11. HashMap中,key、value都可以为null。
参考资料
1. 百度百科 : 《Hash(散列函数)》
2. Hollis : 《全网把 Map 中的 hash() 分析的最透彻的文章,别无二家》
3. JDK源码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号