3-18学习记录|3-20学习记录
1.R写入文件
https://blog.csdn.net/EnjoySmile/article/details/50610805
write.csv(df1,"d://data//dummmyData.csv",row.names = FALSE)
2020-3-20——————————————————
1. 值为非负就要用激活函数吗?
https://zhuanlan.zhihu.com/p/34998569

4.REGEX = "[\u4e00-\u9fa5]+"
https://zhidao.baidu.com/question/571169183.html
“\u4e00”和“\u9fa5”是unicode编码,并且正好是中文编码的开始和结束的两个值,所以这个正则表达式可以用来判断字符串中是否包含中文。
6.显存爆炸时的解决方案
https://blog.csdn.net/xiaoxifei/article/details/84377204
try: output = model(input) except RuntimeError as exception: if "out of memory" in str(exception): print("WARNING: out of memory") if hasattr(torch.cuda, 'empty_cache'): torch.cuda.empty_cache() else: raise exception
如果是在测试的时候,一定要加上with torch.no_grad()
7.如何将训练信息写入日志文件
https://www.ctolib.com/topics-131605.html
import logging logging.basicConfig(filename='log.log', format='%(asctime)s - %(name)s - %(levelname)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=10) logging.debug('debug') logging.info('info') logging.warning('warning') logging.error('error') logging.critical('critical') logging.log(10,'log')
输出:到log.log文件中,默认命名为log。
2020-03-21 21:23:59 PM - root - DEBUG -test: debug 2020-03-21 21:23:59 PM - root - INFO -test: info 2020-03-21 21:23:59 PM - root - WARNING -test: warning 2020-03-21 21:23:59 PM - root - ERROR -test: error 2020-03-21 21:23:59 PM - root - CRITICAL -test: critical 2020-03-21 21:23:59 PM - root - DEBUG -test: log
2020-5-2周六更新——————
https://blog.csdn.net/liuchunming033/article/details/39080457
有 debug 、info 、warning 、error 、critical。默认的是WARNING,当在WARNING或之上时才被跟踪。
上面我写的这个是最简单的方式,写入到文件,如果不设置filename的话,就会输出到控制台,那么如果要同时输入到文件+控制台呢?
需要引入Logger对象:
# coding=utf-8 __author__ = 'liu.chunming' import logging # 第一步,创建一个logger logger = logging.getLogger() logger.setLevel(logging.INFO) # Log等级总开关 # 第二步,创建一个handler,用于写入日志文件 logfile = './log/logger.txt' fh = logging.FileHandler(logfile, mode='w') fh.setLevel(logging.DEBUG) # 输出到file的log等级的开关 # 第三步,再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() ch.setLevel(logging.WARNING) # 输出到console的log等级的开关 # 第四步,定义handler的输出格式 formatter = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s")#常用打印时间的格式 fh.setFormatter(formatter) ch.setFormatter(formatter) # 第五步,将logger添加到handler里面 logger.addHandler(fh) logger.addHandler(ch) # 日志 logger.debug('this is a logger debug message') logger.info('this is a logger info message') logger.warning('this is a logger warning message') logger.error('this is a logger error message') logger.critical('this is a logger critical message')
输出到控制台的和文件的,可以是不同的等级。
后面的高级进阶部分讲的也特别好。
常用:
1、logging.basicConfig([**kwargs]): 为日志模块配置基本信息。不返回任何东西,即返回None。
2、logging.getLogger([name]):创建Logger对象。居然还能根据name来设置层次关系,以继承上面的config设置:
import logging p = logging.getLogger("root") c1 = logging.getLogger("root.c1") c2 = logging.getLogger("root.c2") #输出: >>> p <Logger root (WARNING)> >>> c1 <Logger root.c1 (WARNING)> >>> c2 <Logger root.c2 (WARNING)>
命名举例:
import logging '''命名''' log2=logging.getLogger('BeginMan') #生成一个日志对象 print(log2) #<logging.Logger object at 0x00000000026D1710> '''无名''' log3 = logging.getLogger() print(log3) #<logging.RootLogger object at 0x0000000002721630> 如果没有指定name,则返回RootLogger '''最好的方式''' log = logging.getLogger(__name__)#__name__ is the module’s name in the Python package namespace. print(log) #<logging.Logger object at 0x0000000001CD5518> Logger对象 print (__name__ )#__main__
Logger对象,也有很多属性方法。
9.第一次输出
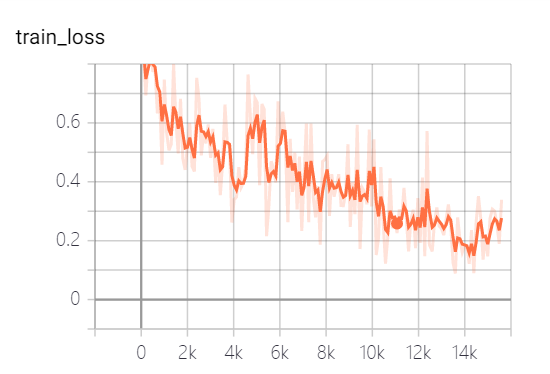
但是训练损失为什么又会增大呢?
https://blog.csdn.net/github_38052581/article/details/87978546
这里有一些解决办法,但不是很针对的那种。只是泛泛而谈。
10.标点和停用词要去掉吗?
https://www.zhihu.com/question/296573656
这里面的回答是要根据具体的任务,就像情感分类这样,标点最好不要去掉,去掉停用词也可能会影响语义。
https://www.cnblogs.com/61355ing/p/10770871.html

这个文章里也是说在停用词中蕴含着一定的意义,所以在情感分类的任务中还是不要去掉停用词了。
目前我的理解是去掉停用词适用于搜索或者摘要的任务。
11.预处理
1.利用正则表达式去掉转发格式。
2.不处理text为None的,而是直接赋值为0,看能不能减小对文本误差的影响。
3.训练epoch数目由5增长为10.
import re str="我的名字!【】" str=re.sub('[^\u4e00-\u9fa5]'," ",str) #输出: >>> str '我的名字 '
unicode编码,中文标点符号编码不在其中。
https://blog.csdn.net/yuan892173701/article/details/8731490
查看了一下编码范围,感觉十分不连续,不能去的,不能用以上的方法处理。
https://blog.csdn.net/blmoistawinde/article/details/103648044 找到了一个非常认真地微博预处理。
13.删掉微博的用户转发
https://www.zhihu.com/question/19816153
@[\u4e00-\u9fa5a-zA-Z0-9_-]{4,30} 根据微博用户名的规则。
import re str="我的名字!//@aofaf://@明天更好:说不定吧" s=re.sub('//@[\u4e00-\u9fa5a-zA-Z0-9_-]{4,30}'," ",str) print(s) #输出: 我的名字! : :说不定吧
之后就可以把:和中文的:都再去掉
但是像这样:
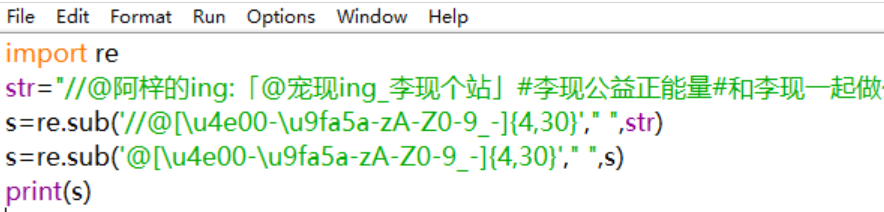
输出前面就会还有
![]()
https://blog.csdn.net/blmoistawinde/article/details/103648044 这个里面对文本的预处理更加详细。
import re def clean(text): text = re.sub(r"(回复)?(//)?\s*@\S*?\s*(:| |$)", " ", text) # 去除正文中的@和回复/转发中的用户名 text = re.sub(r"\[\S+\]", "", text) # 去除表情符号 # text = re.sub(r"#\S+#", "", text) # 保留话题内容 URL_REGEX = re.compile( r'(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,<>?«»“”‘’]))', re.IGNORECASE) text = re.sub(URL_REGEX, "", text) # 去除网址 text = text.replace("转发微博", "") # 去除无意义的词语 text = re.sub(r"\s+", " ", text) # 合并正文中过多的空格 return text.strip()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号