准确率、精确率、召回率【转载】
转自:https://www.cnblogs.com/sddai/p/5696870.html
//原来三者是不同的。。。
1.例子
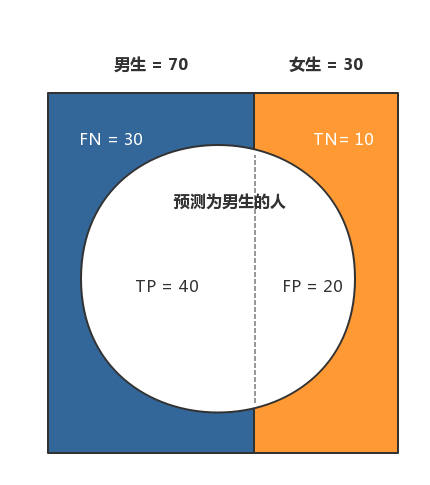
- 准确率(Accuracy) = (TP + TN) / 总样本 =(40 + 10)/100 = 50%。 定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。
- 精确率(Precision) = TP / (TP + FP) = 40/60 = 66.67%。它表示:预测为正的样本中有多少是真正的正样本,它是针对我们预测结果而言的。Precision又称为查准率。
- 召回率(Recall) = TP / (TP + FN) = 40/70 = 57.14% 。它表示:样本中的正例有多少被预测正确了, 它是针对我们原来的样本而言的。Recall又称为查全率。
2.理解
对于检测癌症来说,假设共有100个,95为负例,5为正例,假设不论情况全都判断为没病,也就是负例:
那么对于准确率来说就是95%,但是精确率和召回率都是0.
如果全都预测为正例,那么准确率为5%,精确率为5%,召回率为100%。
2020-3-14更新——————————
感觉自己看多少遍都记不住,好难理解啊。
1.这个下面的回答挺好的
https://www.zhihu.com/question/30643044
但是为什么查准和查全不能双高呢?有什么能解释吗?https://zhuanlan.zhihu.com/p/61919708 这个博主有考虑,但是我觉得他想的不对,反正还是没搞懂二者为啥是负相关的。
看了之后我还是不明白ROC曲线,为啥FP率和TP率会成正比,有没有什么直觉理解?
只能有一个大概的理解,FP率越大说明查的越广,那么TP率更有可能会更高了。
里面还有一个新颖的理解,就是为什么精确率受样本不均衡的影响,而召回率不受,从条件概率的角度来理解两者的含义,其中precision的条件就是,在预测为1的情况下真实为1的比例,条件为预测为1,这就和样本的分布产生了关系;而recall是在真实样本中有多少被预测为1,这就和样本原来是啥没关系了,无论y的真是概率是多少,都不会影响有多少被预测为1。
//但是我还是有点不能接受这个说法。。。
反正就是ROC曲线下面的面积就是AUC,越大越好,并且和样本的不均衡没关系,不受影响;recall的应用场景是金融判断坏用户的时候,宁可查多一点。
2020-6-2更新——————————
1.精准率、召回率的平衡
https://cloud.tencent.com/developer/article/1621157
对PR需求的不同场景:

这里面也后面举了逻辑分类的例子,这个应该是最好理解的一个例子了。
就是通过不同的阈值来理解,要想精确度高,那么阈值就得高,相应地召回率就会变低;而要想召回率高,那么设置阈值低,相应地精确率就会低。
那么如何选择呢?可以通过PR曲线来确定,如果要选择两者平衡的点的话,比如下面这张图,最往外凸的那个点就可以选择那个对应的阈值。
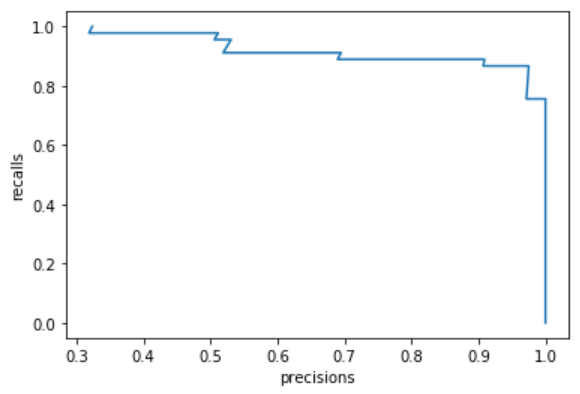
这个就解决了更偏向召回或者是精确率的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号