NOIP/CSP-J/S初赛集锦
鸣谢
一、系统总线
分类:数据总线、地址总线、控制总线
理解:就像邮递员收发邮件。数据总线就像改邮递员一次最多收发几公斤邮件。比如8位的单片机数据总线就像邮递员一次可以最多收8公斤邮件。16位的单片机数据总线就像邮递员一次可以最多收16公斤邮件. DSP一次可以传输32位,就像邮递员一次可以最多收32公斤邮件.
地址就像邮递员负责的派送范围,(也就是寻址空间)比较某人负责哪几个小区,这几个小区的人有需求可以联系到他派送邮件。超出这个范围他不响应,也就是不负责。
控制总线有点类似于给这个邮递员打电话,下命令。是收快递还是发快递,联系方式,地址等信息。
设地址总线位数为n位,则寻址空间大小为2^n Byte
二、计算机硬件
分类:运算器、控制器、存储器、输入设备、输出设备
组成:
1.中央处理器(CPU):运算器、控制器、一些寄存器
主要性能指标:主频和字长
主频:CPU内核工作的时钟频率,单位:G/M/KHz
一般计算机主频:100MHz-1GHz
品牌:
Intel、AMD、IBM和Cyrix、IDT、VIA(台湾)、龙芯(中国大陆)
pentium II(PII)(奔腾)300 (∈Intel)(300指主频为300MHz)
2.存储器: 内存、外存
(1)内存(主存): 快速缓冲存储器(Cache)、主存储器(中央处理器能直接访问的存储器称为内部存储器)
只读存储器(ROM)、随机存储器(RAM)
(2)外存(辅存): 硬盘、软盘、光盘(CD-ROM)
速度:寄存器 > Cache(快存) > RAM > ROM > 硬盘 > 光盘 > 软盘
主机:CPU、内存
三、位、字、字节和字长
位:一个二进制位,取值范围:{0,1}
字:在计算机中,一串数码作为一个整体来处理或运算的,称为一个计算机字,简称字。字通常分为若干个字节。例如,送往控制器去的字是指令,而送往运算器去的字就是一个数。
字长:计算机的每个字所包含的位数称为字长。大型计算机的字长为32-64位,小型计算机为12-32位,而微型计算机为4-16位。比如一台十六位机,则一个字由两个字节构成,那么一个字的字长为16位。实际上,现在的个人电脑一般都是32位或以上的(比如64位)。
若某台计算机的字长为n位,则在CPU中能够作为一个整体加以处理的二进制数据为n/8字节
寄存器的位数取决于计算机的字长
字节:字节是指一小组相邻的二进制数码。通常是8位作为一个字节。它是构成信息的一个小单位,并作为一个整体来参加操作,比字小,是构成字的单位。表示存储器的存储容量。
四、奇偶校验法
根据被传输的一组二进制代码的数位中“1”的个数是奇数或偶数来进行校验。采用奇数的称为奇校验,反之,称为偶校验。若用奇校验,则当接收端收到这组代码时,校验“1”的个数是否为奇数,从而确定传输代码的正确性。
.不.可以检测出数据中哪一位在传输中出了差错。
五、打印机、绘图仪原理
针式打印机:通过打印头中的24根针击打复写纸,从而形成字体
喷墨打印机:将彩色液体油墨经喷嘴变成细小微粒喷到印纸上
激光打印机:激光打印机工作的整个过程可以说是充电、曝光、显像、转像、定影、清除及除像等七大步骤的循环。整个激光打印流程由“充电”动作展开,先在感光鼓上充满负电荷或正电荷,打印控制器中光栅位图图像数据转换为激光扫描器的激光束信息,通过反射棱镜对感光鼓“曝光”,感光鼓表面就形成了以正电荷表示的与打印图像完全相同的图像信息,然后吸附碳粉盒中的碳粉颗粒,形成了感光鼓表面的碳粉图像。而打印纸在与感光鼓接触前被一充电单元充满负电荷,当打印纸走过感光鼓时,由于正负电荷相互吸引,感光鼓的碳粉图像就转印到打印纸上。经过热转印单元加热使碳粉颗粒完全与纸张纤维吸附,形成了打印图像。然后将感光鼓上残留的碳粉“清除”,最后的动作为“除像”,也就是除去静电,使感光鼓表面的电位回复到初始状态,以便展开下一个循环动作。
综上所述,用静电吸附墨粉后转移到纸张。
六、进制
\(2\rightarrow 10\)
\((1011.01)_2\)
\(=(1×23+0×22+1×21+1×20+0×2-1+1×2-2)_{10}\)
\(=(8+0+2+1+0+0.25)_{10}\)
\(=(11.25)_{10}\)
\(10\rightarrow 2\)
乘以2取整,顺序排列
\((0.625)_{10}= (0.101)_2\)
| \(0.625\) | ||
| \(×\) | \(2\) | |
| \(1.25\) | \(1\) | |
| \(×\) | \(2\) | |
| \(0.5\) | \(0\) | |
| \(×\) | \(2\) | |
| \(1.0\) | \(1\) |
\(8\rightarrow 2\)
\((37.416)_8=(11111.10000111)_2\)
| 3 | 7. | 4 | 1 | 6 |
|---|---|---|---|---|
| 011 | 111. | 100 | 001 | 110 |
\(16\rightarrow 2\)
| 5 | D | F. | 9 |
|---|---|---|---|
| 0101 | 1101 | 1111. | 1001 |
\((5DF.9)_16=(10111011111.1001)_2\)
七、原码、反码、补码
(以下+为string::operator+)
| 原码 | 反码 | 补码 |
|---|---|---|
| \(0+x,x>0\) | \(x_{原},x>0\) | \(x_{原},x>0\) |
| \(1+x,x<0\) | \(1+x(取反),x<0\) | \(x_{反}+1\)(此处+为int::operator+) |
8位二进制原码、反码、补码
| 真值 | 原码(B) | 反码(B) | 补码(B) | 补码(H) |
|---|---|---|---|---|
| +127 | 0 111 1111 | 0 111 1111 | 0 111 1111 | 7F |
| +39 | 0 010 0111 | 0 010 0111 | 0 010 0111 | 27 |
| +0 | 0 000 0000 | 0 000 0000 | 0 000 0000 | 00 |
| -0 | 1 000 0000 | 1 111 1111 | 0 000 0000 | 00 |
| -39 | 1 010 0111 | 1 101 1000 | 1 101 1001 | D9 |
| -127 | 1 111 1111 | 1 000 0000 | 1 000 0001 | 81 |
| -128 | 无法表示 | 无法表示 | 1 000 0000 | 80 |
八、浮点数
N=M×R^E
M:尾数
R:基数
E:阶码(指数)
一般规定R为2、8或16,是一个确定的常数,不需要在浮点数中明确表示出来。
∵ 0.3=0.3×100=0.03×101=0.003×102=0.0003×103,
∴ 为了提高数据的表示精度同时保证数据表示的唯一性,需要对浮点数做规格化处理。
在计算机内,对非0值的浮点数,要求尾数的绝对值必须大于基数的倒数,即|M|≥1/R。
尾数用原码;阶码用“移码”;基为2
原码非0值浮点数的尾数数值最高位必定为1,因此可以忽略掉该位
32位浮点数:31 S 30-23 E 22-0 M
64位浮点数:63 S 62-52 E 51-0 M
一个规格化的32位浮点数x的真值为:
x=(-1)s×(1.M)×2^(E-127)
一个规格化的64位浮点数x的真值为:
x=(-1)s×(1.M)×2^(E-1023)
下面举一个32位单精度浮点数-3.75表示的例子帮助理解:
(1)首先转化为2进制表示
-3.75=-(2+1+1/2+1/4)=-1.111×2^1
(2)整理符号位并进行规格化表示
-1.111×21=(-1)(1)×(1+0.1110 0000 0000 0000 0000 000)×2^1
(3)进行阶码的移码处理
(-1)^(1)×(1+0.1110 0000 0000 0000 0000 000)×2^1
=(-1)^(1)×(1+0.1110 0000 0000 0000 0000 000)×2^(128-127)
于是,符号位S=1,尾数M为1110 0000 0000 0000 0000 000阶码E为128(10)=1000 0000(2),
则最终的32位单精度浮点数为
1 1110 0000 0000 0000 0000 000 1000 0000
零值:E=0 & M=0 若sgn>0,+0 若sgn<0,-0 规定:+0=-0
无穷值:E=11111111(2) & M=0 若sgn>0,+∞ 若sgn<0,-∞
NAN:E=0 & M≠0
float的有效位为6-7位, double的有效位为15-16位。
九、字符存储码
字形存储码:指供计算机输出汉字(显示或打印)用的二进制信息,也称字模。通常,采用的是数字化点阵字模。

一般的点阵规模有16×16,24×24,32×32,64×64等,每一个点在存储器中用一个二进制位(bit)存储。例如,在16×16的点阵中,需16×16 bit=32 byte 的存储空间。
GB2312-80汉字国标码规定了一级汉字3755个(按汉语拼音字母/笔形顺序排列),二级汉字3008个(按部首/笔画顺序排列)。
十、信息安全
计算机病毒传染的必要条件是对磁盘进行读写操作,特点是传播性、潜伏性、破坏性与隐蔽性。
十一、网络
(一)计算机网络:利用通信线路和设备,把分布在不同地理位置上的多台计算机连接起来。
(二)协议:网络中计算机与计算机之间的通信依靠协议进行。协议是计算机收、发数据的规则。
1.TCP/IP
四层模型:
(1)链路层(数据链路层/网络接口层):设备驱动程序、接口卡
包括操作系统中的设备驱动程序、计算机中对应的网络接口卡。
(2)网络层(互联网层):IP
处理分组在网络中的活动,比如分组的选路。
(3)运输层:TCP(传输控制协议,面向连接,可靠)、UDP(面向无连接,不可靠)
主要为两台主机上的应用提供端到端的通信。
(4)应用层:Telnet(远程登录)、FTP(文件传输协议)、HTTP(超文本传输协议)、e-mail
负责处理特定的应用程序细节。
e-mail协议有SMTP(发邮件)、POP3(收邮件)等。
2.OSI
七层模型:
| 应用层 |
| 表示层、会话层 |
| 传输层 |
| 网络层 |
| 数据链路层 |
| 物理层 |
TCP/IP与OSI的对应关系:
| OSI | TCP/IP |
|---|---|
| 应用层 | 应用层 |
| 表示层 | |
| 会话层 | |
| 传输层 | 传输层 |
| 网络层 | 网络层 |
| 数据链路层 | 网络接口 |
| 物理层 |
3.Netbeui
4.IP
IP地址:我们把整个Internet看作一个单一的、抽象的网络,所谓IP地址,就是为Internet中的每一台主机分配一个在全球范围唯一地址。
IP地址是用“.”隔开地四个十进制整数,每个数字取值为0-255。由32位二进制数码表示。
例:210.33.19.103
网络IP地址主要分为ABC三类,以下是覆盖范围:
A类:0.0.0.0 - 127.255.255.255,标谁的子网掩码是255.0.0.0(按子网掩码的另一种标注方法是/8,就是将子网掩码换算成二进制后,从左数起8个1)
B类:128.0.0.0 - 191.255.255.255,标谁的子网掩码是255.255.0.0(按子网掩码的另一种标注方法是/16,就是将子网掩码换算成二进制后,从左数起16个1)
C类:192.0.0.0 - 223.255.255.255,标谁的子网掩码是255.255.255.0(按子网掩码的另一种标注方法是/24,就是将子网掩码换算成二进制后,从左数起24个1)
(三)Web
Web1.0的主要特点:用户通过浏览器获取信息
Web2.0的主要特点:更注重用户的交互作用
Web2.0技术主要包括:博客(BLOG)、RSS、百科全书(Wiki)、网摘、社会网络(SNS)、P2P、即时信息(IM)等。典型应用是Flickr,雅虎(Yahoo)旗下的图片分享网站。
十二、时间复杂度
十三、NOI竞赛
(一)推荐语言及环境
NOI官网
Pascal:free pascal,lazarus
C/C++:Dev C++,gcc/g++(Visual C++不是)
(二)NOI历史
NOI官网
- 1984年,*:“计算机的普及要从娃娃做起。”,第一届NOI举办。
- 1995年,第一届NOIP。
- 1989年,IOI,保加利亚。
- 1995年,WC。
- 1999年,NOI网络同步赛。
- 2007年,APIO。
- 2011年,NOIP取消保送。
- 2014年,CSP认证(Certified Software Professional,软件能力认证)。
- 2019年,CSP非专业级别的能力认证。
十四、奖项
(一)图灵奖
图灵奖是美国计算机协会于1966年设立的,专门奖励那些对计算机事业作出重要贡献的个人,有“计算机界诺贝尔奖”之称,其名称取自计算机科学的先驱、英国科学家阿兰·图灵。迄今为止,仅一位华裔科学家或此殊荣,姚期智。
十五、数学
十六、运算符优先级
按位运算符:
~ > << == >> > & > ^ > |
逻辑运算符:
| 运算符 | 优先级 | 备注 |
|---|---|---|
¬ |
1 | |
∧ |
2 | 合取(与) |
∨ |
3 | 析取(或) |
-> |
4 | 蕴含(当前真后假时为假) |
<-> |
5 | 等价(当前后值相等时为真) |
十七、P,NP,NPC,NPhard
问题分为可解问题和不可解问题(e.g. 停机问题)
P:在多项式时间内可解的问题
NP:能在多项式时间内检验一个解是否合法的可解问题
NPC:NP完备是NP与NP困难的交集,是NP中最难的决定性问题。
NPhard:如果所有NP问题都可以多项式时间归约到某个问题,则称该问题为NP困难。

十八、编程语言
(一)分类
1.机器语言
2.汇编语言
3.高级语言
(二)原理
机器语言计算机能直接识别。
汇编语言通过汇编过程转换成机器指令。
编译器将高级语言程序转变为目标机器代码。
(三)记录
第一个高级语言:Fortran
第一个面向对象高级语言:Simula(Simula 67)(引入类class的概念)
第二个面向对象高级语言:Smalltalk(引入继承性思想)
世界上第一位程序员:Ada Lovelace(著名英国诗人拜伦之女)
Ada语言:源于美国军方的一个计划,旨在整合美军事系统中运行着上百种不同的程序设计语言。其命名是为了纪念世界上第一位程序员Ada Lovelace。它是迄今为止最复杂、最完备的软件工具。
十九、计算机发展
ENIAC是世界上第一台通用计算机,第一台现代电子计算机,也是继ABC(阿塔纳索夫-贝瑞计算机)之后的第二台电子计算机。
EDVAC采用二进制,而且是一台冯·诺伊曼结构的计算机。
EDSAC是世界上第一台实际运行的存储程序式电子计算机。
二十、常见文件格式
图形文件:gif、jpg、png、psd、bmp
视频文件:wmv、asf、rm、rmvb、mov、mp4、avi
声音文件:wav、mp3
more
二十一、算法
哈夫曼树
1.节点的权
节点的权指的是为树中的每一个节点赋予的一个非负的值,如上图中每一个节点中的值。
2.节点的带权路径长度
节点的带权路径长度指的是从根节点到该节点之间的路径长度与该节点权的乘积:如对于1节点的带权路径长度为:2。
3.树的带权路径长度
树的带权路径长度指的是所有叶子节点的带权路径长度之和。
有了如上的概念,对于Huffman树,其定义为:
给定n权值作为n个叶子节点,构造一棵二叉树,若这棵二叉树的带权路径长度达到最小,则称这样的二叉树为最优二叉树,也称为Huffman树。由以上的定义可以知道,Huffman树是带权路径长度最小的二叉树。
4.构建Huffman树
例:
| A | 8 |
| D | 1 |
| E | 4 |
| F | 1 |
| R | 5 |
| T | 3 |
重复以下的步骤:
(1)按照权值对每一个节点排序:D-F-T-E-R-A
(2)选择权值最小的两个节点(此处为D和F)生成新的节点,节点的权重为这两个节点的权重之和,为2
(3)直到只剩最后的根节点
Huffman树
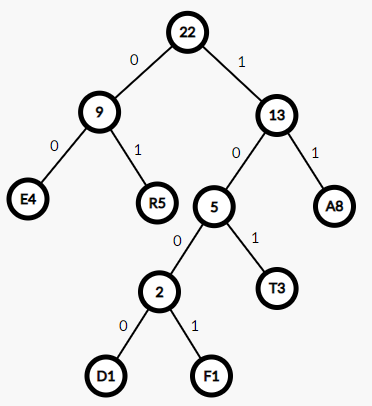
5.Huffman编码
有了上述的Huffman树的结构,现在我们需要利用Huffman树对每一个字符编码,该编码又称为Huffman编码,Huffman编码是一种前缀编码,即一个字符的编码不是另一个字符编码的前缀。
将权值小的最为左节点,权值大的作为右节点
左孩子编码为0,右孩子编码为1
E的编码:00
D的编码:1000
哈希(散列表)
1.查找成功和不成功时的平均查找长度
线性探查法:
(设关键字为 \(A_i\) , \(M=7\) , \(H(key)=3*key\%M\) ,查找次数为 \(C_i\) ,与最近的下标为 \(i\text{~}M-1\) 的空哈希表元素距离 \(D_i\) )
成功:\(sum(C_i)/len(A)\)
失败:\(sum(D_i)/M\)
例:
| 序号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 哈希值 | 7 | 14 | 8 | 11 | 30 | 18 | 9 | |||
| 查找次数 | 1 | 2 | 1 | 1 | 1 | 3 | 3 | |||
| 与最近空元素距离 | 3 | 2 | 1 | 2 | 1 | 5 | 4 |
查找成功的平均查找长度 \(=(1+1+1+1+3+3+2)/7=12/7\)
查找失败的平均查找长度 \(=(3+2+1+2+1+5+4)/7=18/7\)
链地址法:
(设关键字为 \(A_i\) , \(M=13\) , \(H(key)=key\%M\) ,查找次数为 \(C_i\) ,链长度为 \(D_i\) )
成功:\(sum(C_i)/len(A)\)
失败:\(sum(D_i)/M=len(A)/M\)
例:
| 0 | ||||
| 1 | 14 | 1 | 27 | 53 |
| 2 | ||||
| 3 | 42 | 55 | ||
| 4 | ||||
| 5 | ||||
| 6 | 32 | 45 | ||
| 7 | 20 | |||
| 8 | ||||
| 9 | ||||
| 10 | 23 | 10 | ||
| 11 | 24 | |||
| 12 |
成功 \(=(1*6+2*4+3*1+4*1)/12=7/4\)
失败 \(=(4+2+2+1+2+1)/13=12/13\)
二叉排序树
二叉树是二叉排序树的充要条件:左子树上所有结点的值均小于它的根结点的值;右子树上所有结点的值均大于它的根结点的值。
排序

图论
最短路
Dijkstra 朴素 \(O(n^2)\) ,二叉堆 \(O(m\log n)\) ,配对堆 \(O(m+n\log n)\)
最小生成树
Prim 朴素 \(O(n^2)\) ,二叉堆 \(O(m\log n)\)
Kruskal \(O(m\log m)\)
欧拉与哈密顿
欧拉图:具有欧拉回路的图
- 无向连通图 G 是欧拉图,当且仅当 G 不含奇数度结点( G 的所有结点度数为偶数);
- 无向连通图 G 含有欧拉通路,当且仅当 G 有零个或两个奇数度的结点。
哈密顿图:存在哈密顿回路的图
0
二分图:无奇环的图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号