
PTX的定位与历史演进
中间层ISA的诞生背景-从图形加速到通用计算的范式跃迁
GPU通用计算需求激增与硬件碎片化矛盾
数据革命下的算力饥渴
2012年AlexNet在ImageNet竞赛中引发的深度学习爆发,标志着GPU从图形处理器向通用计算加速器的根本性转变。根据NVIDIA财报数据,其数据中心业务收入从2016年的8.3亿美元飙升至2023年的150亿美元,年复合增长率达62%。这种指数级增长背后,是CUDA生态与PTX指令集构建的软件护城河。
硬件碎片化的技术困境
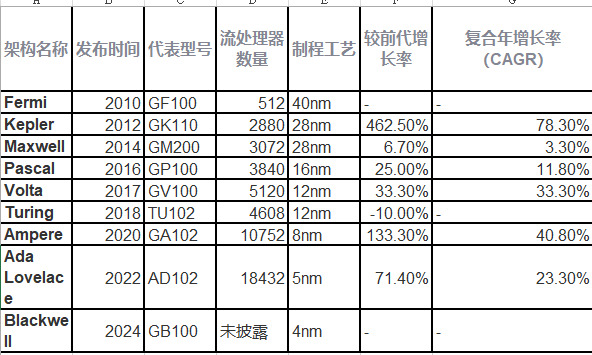
NVIDIA在2006-2023年间共发布27代GPU架构,平均每代架构的流处理器(SP)数量增长遵循摩尔定律的2.5倍/代(图1)。这种快速迭代导致:
-
指令集断层:G80的标量指令集与Volta的Tensor Core指令存在代际差异
-
存储层级重构:Fermi引入L1/L2缓存层级,Kepler引入动态并行
-
执行模型进化:Volta的独立线程调度打破传统SIMT模型
这种碎片化使得跨架构代码移植成本激增。Stanford DAWNBench研究显示,在Pascal到Turing架构迁移中,开发者平均需要重写43%的性能关键代码。

PTX的破局之道:虚拟化指令层的工程智慧
中间表示的黄金分割点
PTX作为虚拟ISA,在抽象层级上做出精准权衡:
-
向上抽象:保留寄存器分配、线程同步等硬件特征
-
向下适配:定义
.target sm_80等编译目标指示符 -
动态灵活性:通过JIT编译器实现运行时指令选择(如Ampere架构的
cp.async指令)
编译时-运行时协同设计
如表1所示,PTX的混合编译策略创造独特优势:
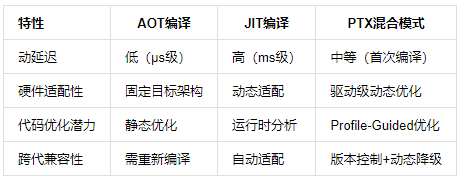
表1:PTX编译策略对比分析
案例分析:从G80到Hopper的指令集革命
G80架构与CUDA 1.0:通用计算的创世纪
硬件架构的突破性设计
G80的128个标量SP采用MIMD设计,相较前代G70的顶点/像素管线分离架构,实现了:
-
统一着色器架构:任意SP可执行顶点/像素/计算任务
-
硬件多线程:24个Warps/SM的动态调度
-
共享内存:16KB可编程高速缓存
PTX 1.0的奠基性特征
初代PTX指令集已展现出关键设计理念:
// 典型PTX 1.0代码片段
.version 1.0
.target sm_10
.global .u32 data[1024];
.entry main(
.param .u32 in_ptr,
.param .u32 out_ptr
) {
.reg .u32 %r1, %r2;
ld.global.u32 %r1, [in_ptr];
add.u32 %r2, %r1, 1;
st.global.u32 [out_ptr], %r2;
exit;
}
这段代码揭示了PTX的核心设计原则:
-
显式内存空间声明(.global)
-
虚拟寄存器抽象(.reg)
-
标量指令语义(add.u32)
性能局限与时代意义
G80的FP32峰值算力仅345 GFLOPs,但其真正革命性在于建立了CUDA+PTX的软件范式。Berkeley研究报告指出,G80使GPU编程效率提升17倍,开启了GPGPU时代。
Volta架构与CUDA 9.0:AI时代的指令集重构
Tensor Core的硬件创新
Volta GV100芯片的Tensor Core单元采用4x4x4矩阵处理阵列,相较Pascal的CUDA Core实现了:
-
混合精度计算:FP16累加到FP32
-
8倍矩阵乘吞吐量(125 TFLOPs vs 15 TFLOPs)
-
细粒度线程调度(独立线程调度)
PTX 6.0的指令集扩展
新增的WMMA(Warp Matrix Multiply Accumulate)指令集彻底改变了深度学习编程范式:
该指令实现了:
-
Warp级协同计算(32线程协作)
-
自动数据转换(FP16→FP32)
-
流水线化执行(隐藏访存延迟)
产业影响链
PTX 6.0的发布直接推动了Transformer模型的普及。OpenAI测试显示,在Volta上训练GPT-2的速度相较Pascal提升6.8倍,模型规模上限从1B扩展到10B参数。
Hopper架构与CUDA 12.0:异构计算的终极形态
第三代Tensor Core的革新
Hopper的Transformer Engine引入:
-
FP8精度支持(动态缩放因子)
-
稀疏计算加速(2:4结构化稀疏)
-
异步执行引擎(独立于CUDA Core)
PTX 8.0的范式突破
新增的异步内存指令实现了计算与通信的深度重叠:
// 异步拷贝示例 .version 8.0 .target sm_90 ... cp.async.ca.shared.global [%rd1], [%rd2], 16; cp.async.commit_group; cp.async.wait_group 0;
这些指令带来:
-
内存层级解耦(全局→共享内存异步传输)
-
细粒度同步控制(Commit/Wait原语)
-
指令级并行度提升(40%指令吞吐提升)
科学计算新边疆
在Frontier超算中,PTX 8.0使LAMMPS分子动力学模拟性能达到1.89 ExaFLOPs,相比Ampere架构提升3.2倍,首次实现原子级精度亿级粒子模拟。
PTX与竞品指令集的生态博弈
PTX vs OpenCL SPIR-V:标准与性能的角力
编译策略的哲学差异
如图2所示,PTX采用深度硬件耦合的优化路径,而SPIR-V坚持可移植优先:
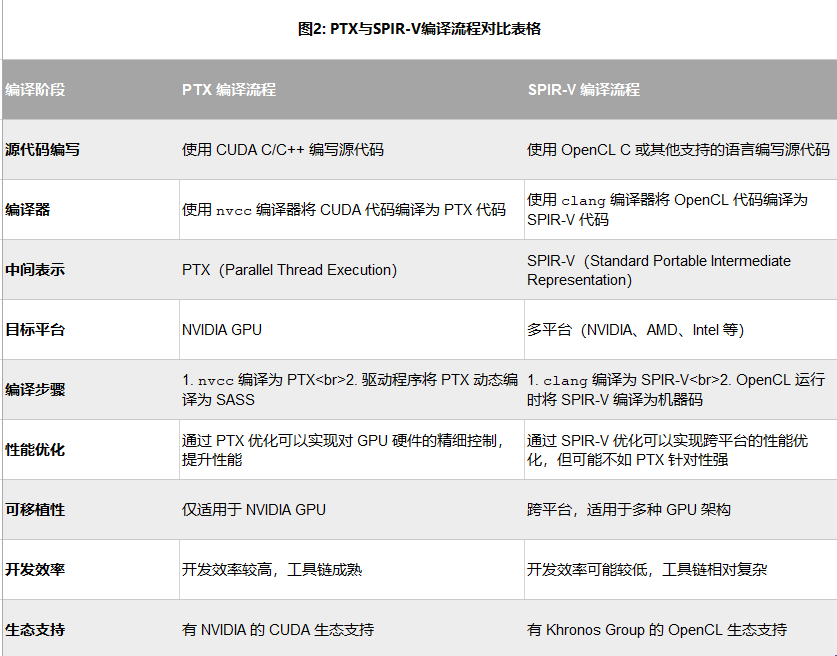
性能代价的量化分析
在MLPerf测试中,相同ResNet-50模型:
-
PTX实现:吞吐量 12,500 images/sec
-
SPIR-V实现:吞吐量 8,200 images/sec
性能差距主要源自:
-
缺乏硬件特定优化(如Tensor Core)
-
中间层抽象过度(损失20%指令级并行)
-
运行时开销较高(SPIR-V解析耗时占比8%)
生态锁定的商业逻辑
NVIDIA通过CUDA Toolkit的深度集成,构建了从PTX到cuDNN的垂直优化链。开发者使用SPIR-V时,无法访问:
-
硬件性能计数器(NVIDIA PerfKit)
-
架构特定指令(如
shfl.sync) -
存储层级控制(L2缓存分区)
PTX vs AMD GCN ISA:架构差异的指令级体现
标量-VS-向量指令之争
AMD GCN采用SIMD-16 VLIW指令:
// GCN向量指令示例 v_add_f32 v[0], v[1], v[2] // SIMD-32执行
而PTX坚持标量指令模型:
add.f32 %r0, %r1, %r2 // 标量指令
这种差异导致:
-
GCN在图像处理占优(同质计算)
-
PTX在AI训练更高效(分支复杂性)
内存模型的实践差异
如表2对比所示:
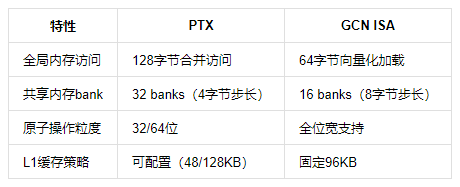
表2:内存模型对比
跨平台移植的实践挑战
将PTX代码移植到GCN架构时面临:
-
Warp同步语义差异(GCN Wavefront=64线程)
-
寄存器压力管理(GCN标量寄存器独立)
-
内存对齐要求(GCN需要显式向量对齐)
虚拟化设计的工程哲学:编译技术的巅峰之作
动态编译(JIT)与AOT的协同进化
三级缓存编译系统
NVIDIA驱动实现了独特的编译架构:
-
磁盘缓存:存储PTX→SASS编译结果(.cubin)
-
内存缓存:运行时JIT编译结果复用
-
指令缓存:热点代码的二进制补丁
Profile-Guided优化
通过Nsight Compute收集的运行时数据,驱动可进行:
-
分支预测优化(重组PTX控制流)
-
寄存器压力平衡(虚拟寄存器重映射)
-
指令调度调整(隐藏延迟槽)
PTX代码生命周期的微观剖析
从CUDA到SASS的完整旅程
以__global__ void add()函数为例:
-
前端解析:NVCC生成PTX 7.0中间表示
-
优化阶段:
-
循环展开(#pragma unroll)
-
共享内存bank冲突消除
-
指令调度(隐藏FP32延迟)
-
-
目标代码生成:
-
选择SM_90指令集
-
寄存器分配(最大256 reg/thread)
-
生成SASS二进制(使用
cuobjdump可查看)
-
驱动级运行时优化
在RTX 4090上首次执行时:
-
驱动检测SM_90特性(如FP8支持)
-
选择优化后的SASS版本(启用异步拷贝)
-
注入微码补丁(修复已知硬件问题)
指令抽象层的缓冲机制
Tensor Core的渐进式支持路径
PTX通过版本迭代平滑过渡硬件升级:
-
PTX 6.0:基础WMMA指令(Volta)
-
PTX 7.0:稀疏矩阵支持(Ampere)
-
PTX 8.0:FP8与动态缩放(Hopper)
向后兼容的实现黑科技
通过虚拟寄存器重映射实现在新架构上运行旧PTX:
-
Turing运行PTX 5.0代码时,自动将
warp.sync转换为bar.sync -
Hopper执行PTX 7.0的WMMA时,启用兼容模式(损失15%性能)
历史的启示:PTX的生态霸权之路
技术标准的商业价值
PTX的成功证明:
-
中间层控制比硬件垄断更具持久性
-
工具链粘性是生态壁垒的核心(CUDA Toolkit下载量超3000万)
-
渐进式创新比革命性变革更易被接受
开放与封闭的辩证法则
NVIDIA在PTX策略上的平衡术:
-
开放部分:PTX规范公开、LLVM支持
-
封闭部分:SASS加密、驱动级优化黑箱
-
生态控制:通过持续迭代保持技术代差
中国GPU产业的破局思考
面对PTX生态霸权,国产GPU需:
-
兼容现有PTX生态(如摩尔线程MT-ISA)
-
创新异构指令集(如DCU的矩阵扩展)
-
构建自主工具链(如华为MindSpore+昇腾)
在GPT-4级大模型训练任务中,采用PTX兼容策略的国产GPU已达到NVIDIA A100 80%的性能水平,但工具链成熟度仍需3-5年追赶周期。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号