论文解读(WDGRL)《Wasserstein Distance Guided Representation Learning for Domain Adaptation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Wasserstein Distance Guided Representation Learning for Domain Adaptation
论文作者:Jian Shen、Yanru Qu、Weinan Zhang、Yong Yu
论文来源:2018 ACL
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
动机:受 Wasserstein GAN 的启发,本文提出了一种学习领域不变特征表示的新方法,即 WDGRL ;
优势:瓦瑟斯坦距离对域自适应的理论优势在于其梯度特性和有希望的泛化界;
贡献:
- 对公共领域自适应基准的实证研究表明,WDGRL 在领域适应方面优于最先进的表示学习方法;
- WDGRL成功地统一了两个域分布,并保持了明显的标签区分;
2 相关
$\text{Borel probability measure}$ $\mathbb{P}$ 和 $\mathbb{Q}$ 之间的 $\text{p-th Wasserstein distance}$:
$W_{p}(\mathbb{P}, \mathbb{Q})=\left(\inf _{\mu \in \Gamma(\mathbb{P}, \mathbb{Q})} \int \rho(x, y)^{p} d \mu(x, y)\right)^{1 / p}$
其中:
-
- $\mathbb{P}, \mathbb{Q} \in\left\{\mathbb{P}: \int \rho(x, y)^{p} d \mathbb{P}(x)<\infty, \forall y \in M\right\} $ ;
- $\Gamma(\mathbb{P}, \mathbb{Q})$ 是基于边缘分布 $\mathbb{P}$ 和 $\mathbb{Q}$ 的 $M \times M$ 大小的策略;
- $\mu(x, y)$ 是一种随机策略,在满足 $x \in \mathbb{P}$ 和 $y \in \mathbb{Q}$ 的情况下,将单位数量的材料从一个随机位置 $x$ 运输到另一个位置 $y$ ;
- $\rho(x, y)^{p}$ 代表将单位数量的材料 从 $x \in \mathbb{P}$ 搬到 $y \in \mathbb{Q}$ 需要的成本;
- $W_{p}(\mathbb{P}, \mathbb{Q})$ 代表最小运输成本;
$W_{1}(\mathbb{P}, \mathbb{Q})= \underset{\|f\|_{L} \leq 1}{\text{sup}} \; \mathbb{E}_{x \sim \mathbb{P}}[f(x)]-\mathbb{E}_{x \sim \mathbb{Q}}[f(x)]$
其中,$\|f\|_{L}= \sup |f(x)-f(y)| / \rho(x, y) $;3 方法
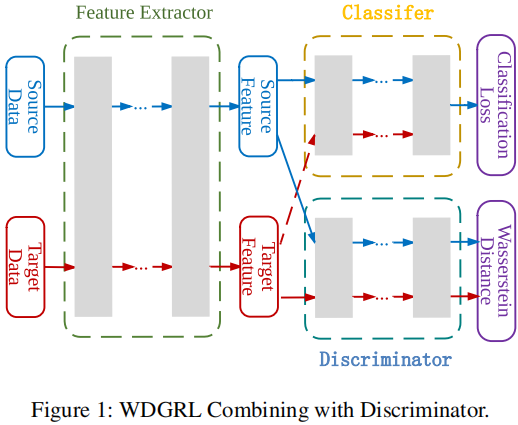
组件:
-
- 特征提取器 $f_{g}: \mathbb{R}^{m} \rightarrow \mathbb{R}^{d}$;
- 域鉴别器 $f_{w}: \mathbb{R}^{d} \rightarrow \mathbb{R}$;
- 分类器 $f_{c}: \mathbb{R}^{d} \rightarrow \mathbb{R}^{l}$;
3.1 域不变表示学习
为减少源域和目标域之间的差异,使用 域鉴别器,目标是估计源域和目标表示分布之间的瓦瑟斯坦距离:
$\begin{aligned}W_{1}\left(\mathbb{P}_{h^{*}}, \mathbb{P}_{h^{t}}\right) & = \underset{\left\|f_{w}\right\|_{L} \leq 1}{\text{sup}} \; \mathbb{E}_{\mathbb{P}_{h^{*}}}\left[f_{w}(h)\right]-\mathbb{E}_{\mathfrak{h}^{t}}\left[f_{w}(h)\right] \\& = \underset{\left\|f_{w}\right\|_{L} \leq 1}{\text{sup}} \;\mathbb{E}_{\mathbb{P}_{x^{*}}}\left[f_{w}\left(f_{g}(x)\right)\right]-\mathbb{E}_{\mathbb{P}_{x^{t}}}\left[f_{w}\left(f_{g}(x)\right)\right] \end{aligned}$
如果参数化的域鉴别器函数族 $\left\{f_{w}\right\} $ 都是 $\text{1-Lipschitz}$,那么可通过最大化关于参数 $\theta_{w}$ 的域鉴别损失 $\mathcal{L}_{w d}$ 来近似经验瓦瑟斯坦距离:
$\mathcal{L}_{w d}\left(x^{s}, x^{t}\right)=\frac{1}{n^{s}} \sum_{x^{x} \in X^{*}} f_{w}\left(f_{g}\left(x^{s}\right)\right)-\frac{1}{n^{t}} \sum_{x^{t} \in X^{t}} f_{w}\left(f_{g}\left(x^{t}\right)\right)$
关于执行利普希茨约束的问题,Arjovsky 提出,在每次梯度更新后,将域鉴别器的权重剪辑在一个紧凑的空间内 $\text{[−c,c]}$。Gulrajani 指出,权重裁剪将导致梯度消失或爆炸的问题,并提出一种更合理的方法是对域鉴别器参数 $\theta_{w}$ 实施梯度惩罚 $\mathcal{L}_{\text {grad }}$ :
$\mathcal{L}_{\text {grad }}(\hat{h})=\left(\left\|\nabla_{\hat{h}} f_{w}(\hat{h})\right\|_{2}-1\right)^{2}$
其中,惩罚梯度的特征表示 $\hat{h}$ 不仅定义在源和目标表示上,而且还定义在源和目标表示对之间的直线上的随机点上。
可通过解决这个问题来估计经验的瓦瑟斯坦距离:
$\underset{\theta_{w}}{\text{max}}\;\left\{\mathcal{L}_{w d}-\gamma \mathcal{L}_{\text {grad }}\right\}$
最终,表示学习可以通过求解极大极小问题来实现:
$\underset{\theta_{g}}{\text{min}}\; \underset{\theta_{w}}{\text{max}} \; \left\{\mathcal{L}_{w d}-\gamma \mathcal{L}_{\text {grad }}\right\}$
注意,在优化最小操作时,$\gamma$ 应该设置为 $0$,因为梯度惩罚不应该指导表示学习过程;
3.2 鉴别性学习
源域监督学习:
$\mathcal{L}_{c}\left(x^{s}, y^{s}\right)=-\frac{1}{n^{s}} \sum_{i=1}^{n^{s}} \sum_{k=1}^{l} 1\left(y_{i}^{s}=k\right) \cdot \log f_{c}\left(f_{g}\left(x_{i}^{s}\right)\right)_{k}$
3.3 训练目标
总体训练目标:
$\underset{\theta_{g}, \theta_{c}}{\text{min}} \; \left\{\mathcal{L}_{c}+\lambda \underset{\theta_{w}}{\text{max}} \; \left[\mathcal{L}_{w d}-\gamma \mathcal{L}_{\text {grad }}\right]\right\}$
3.4 算法

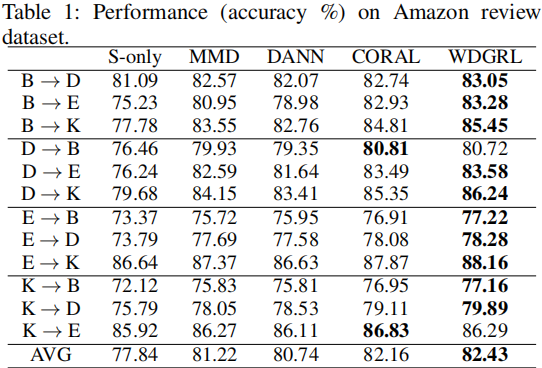
4 实验
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17667583.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号