论文解读(LG2AR)《Learning Graph Augmentations to Learn Graph Representations》
论文信息
论文标题:Learning Graph Augmentations to Learn Graph Representations
论文作者:Kaveh Hassani, Amir Hosein Khasahmadi
论文来源:2022, arXiv
论文地址:download
论文代码:download
1 Introduction
我们引入了 LG2AR,学习图增强来学习图表示,这是一个端到端自动图增强框架,帮助编码器学习节点和图级别上的泛化表示。LG2AR由一个学习增强参数上的分布的概率策略和一组学习增强参数上的分布的概率增强头组成。我们表明,与之前在线性和半监督评估协议下的无监督模型相比,LG2AR在20个图级和节点级基准中的18个上取得了最先进的结果。
2 Method
整体框架如下:
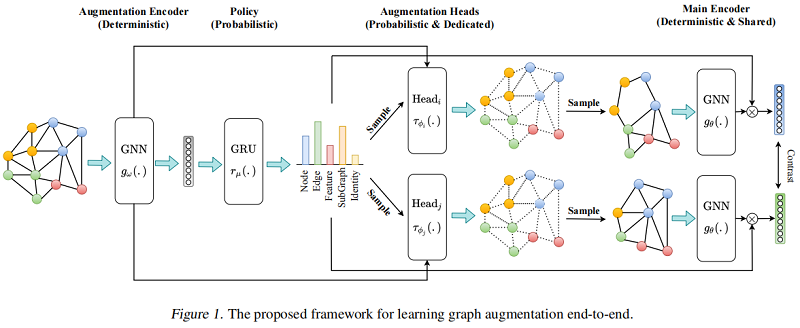
2.1 Augmentation Encoder
增强编码器 $g_{\omega}(.): \mathbb{R}^{|\mathcal{V}| \times d_{x}} \times \mathbb{R}^{|\mathcal{E}|} \longmapsto \mathbb{R}^{|\mathcal{V}| \times d_{h}} \times \mathbb{R}^{d_{h}}$ 基于图 $G_{k}$ 产生节点表示 $\mathbf{H}_{v} \in \mathbb{R}^{|\mathcal{V}| \times d_{h}}$ 和图表示 $h_{g} \in \mathbb{R}^{d_{h}}$ 。
增强编码器 $g_{\omega}(.)$ 的组成:
-
- GNN Encoder;
- Readout function;
- Two MLP projection head;
2.2 Policy
Policy $r_{\mu}(.): \mathbb{R}^{|\mathcal{B}| \times d_{h}} \longmapsto \mathbb{R}^{|\tau|}$ 是一个概率模块,接收一批从增强编码器得到的图级表示 $\mathbf{H}_{g} \in \mathbb{R}^{|\mathcal{B}| \times d_{h}}$ ,构造一个增强分布 $\mathcal{T}$,然后采样两个数据增强 $\tau_{\phi_{i}}$ 和 $\tau_{\phi_{j}}$。由于在整个数据集上进行增强采样代价昂贵,本文选则小批量的处理方式来近似。
此外,Policy 必须对批处理内表示的顺序保持不变,所以本文尝试了两种策略:
- a policy instantiated as a deep set where representations are first projected and then aggregated into a batch representation.
- a policy instantiated as an RNN where we impose an order on the representations by sorting them based on their L2-norm and then feeding them into a GRU.
本文使用最后一个隐藏状态作为批处理表示形式。我们观察到GRU政策表现得更好。该策略模块自动化了特别的试错增强选择过程。为了让梯度流回策略模块,我们使用了一个跳跃连接,并将最终的图表示乘以策略预测的增强概率。
2.3 Augmentations
Topological augmentations:
-
- node dropping
- edge perturbation
- subgraph inducing
Feature augmentation:
-
- feature masking
Identity augmentation
与之前的工作中,增强的参数是随机或启发式选择的,我们选择端到端学习它们。例如,我们不是随机丢弃节点或计算与中心性度量成比例的概率,而是训练一个模型来预测图中所有节点的分布,然后从它中抽取样本来决定丢弃哪些节点。与 Policy 模块不同,增强功能以单个图为条件。我们为每个增强使用一个专用的头,建模为一个两层MLP,学习增强参数的分布。头部的输入是原始图 $G$ 和表示来自增强编码器的 $\mathbf{H}_{v}$ 和 $h_{G}$。我们使用 Gumbel-Softmax 技巧对学习到的分布进行采样。
Node Dropping Head
以节点和图表示为条件,以决定删除图中的哪些节点。
它接收节点和图表示作为输入,并预测节点上的分类分布。然后使用 Gumbel-Top-K技巧,使用比率超参数对该分布进行采样。我们也尝试了伯努利抽样,但我们观察到它在最初的几个时期积极地减少节点,模型在以后无法恢复。为了让梯度从增广图回流到头部,我们在增广图上引入了边权值,其中一个边权值 $w_{i j}$ 被计算为 $p\left(v_{i}\right)+p\left(v_{j}\right)$,而 $p\left(v_{i}\right)$ 是分配给节点 $v_{i}$ 的概率。
算法如下:

Edge Perturbation Head
以头部和尾部节点为条件,以决定添加/删除哪些边。
首先随机采样 $|\mathcal{E}|$ 个负边( $\overline{\mathcal{E}}$ ),形成一组大小为 $2|\mathcal{E}|$ 的负边和正边集合 $\mathcal{E} \cup \overline{\mathcal{E}}$。边表示为 $\left[h_{v_{i}}+h_{v_{j}} \| \mathbb{1}_{\mathcal{E}}\left(e_{i j}\right)\right]$ ( $h_{v_{i}}$ 和 $h_{v_{j}}$ 分别代表边 $e_{i j}$ 的头和尾部节点的表示,$\mathbb{1}_{\mathcal{E}}\left(e_{i j}\right)$ 用于判断边是属于positivate edge 或者 negative edge )输入 Heads 去学习伯努利分布。我们使用预测的概率 $p\left(e_{i j}\right)$ 作为边权重,让梯度流回头部。
算法如下:

以节点和图表示为条件来决定中心节点。
它接收节点和图表示(即 $\left[h_{v} \| h_{g}\right]$ )的连接作为输入,并学习节点上的分类分布。然后对分布进行采样,为每个图选择一个中心节点,围绕该节点使用具有 $K-hop$ 的广度优先搜索(BFS)诱导一个子图。我们使用类似的技巧来实现节点删除增强,以跨越梯度回到原始图。
算法过程:

以节点表示为条件,以决定要屏蔽的节点特征的哪些维度。头部接收节点表示 $h_v$,并在原始节点特征的每个特征维数上学习伯努利分布。然后对该分布进行采样,在初始特征空间上构造一个二值掩模 $m$。因为初始节点特征可以由类别属性组成,所以我们使用一个线性层将它们投射到一个连续的空间中,从而得到 $x_{v}^{\prime}$。增广图具有与原始图相同的结构,具有初始节点特征 $x_{v}^{\prime} \odot m$($\odot$ 为哈达玛乘积)。
算法过程:

2.4 Base Encoder
基本编码器 $g_{\theta}(.): \mathbb{R}^{\left|\mathcal{V}^{\prime}\right| \times d_{x}^{\prime}} \times \mathbb{R}^{\left|\mathcal{V}^{\prime}\right| \times\left|\mathcal{V}^{\prime}\right|} \longmapsto \mathbb{R}^{\left|\mathcal{V}^{\prime}\right| \times d_{h}} \times \mathbb{R}^{d_{h}}$ 是一个共享的图编码器,的增强接收增强图 $G^{\prime}=\left(\mathcal{V}^{\prime}, \mathcal{E}^{\prime}\right)$ 从相应的增强头接收一个增强图 $G^{\prime}=\left(\mathcal{V}^{\prime}, \mathcal{E}^{\prime}\right)$,并学习一组节点表示 $\mathbf{H}_{v}^{\prime} \in \mathbb{R}^{\left|\mathcal{V}^{\prime}\right| \times d_{h}} $ 和增强图 $G^{\prime}$ 上的图表示 $h_{G}^{\prime} \in \mathbb{R}^{d_{h}}$。学习增强的目标是帮助基编码器学习这些增强的不变性,从而产生鲁棒的表示。基础编码器用策略和增强头进行训练。在推理时,输入图被直接输入给基编码器,以计算下游任务的编码。
2.5 Training
本文采用 InfooMax 目标函数:
$\underset{\omega, \mu \phi_{i}, \phi_{j}, \theta}{\text{max}} \frac{1}{|\mathcal{G}|} \sum\limits _{G \in \mathcal{G}}\left[\frac{1}{|\mathcal{V}|} \sum_{v \in \mathcal{V}}\left[\mathrm{I}\left(h_{v}^{i}, h_{G}^{j}\right)+\mathrm{I}\left(h_{v}^{j}, h_{G}^{i}\right)\right]\right]$
其中,$\omega$, $\mu$, $\phi_{i}$, $\phi_{j}$, $\theta$ 是待学习模块的参数,$h_{v}^{i}$、$h_{G}^{j}$ 是由增强 $i$ 和 $j$ 编码的节点 $v$ 和图 $G$ 的表示,$I$ 是互信息估计量。我们使用 Jensen-Shannon MI estimator:
$\mathcal{D}(., .): \mathbb{R}^{d_{h}} \times \mathbb{R}^{d_{h}} \longmapsto \mathbb{R}$ 是一个鉴别器,它接受一个节点和一个图表示,并对它们之间的一致性进行评分,并实现为 $\mathcal{D}\left(h_{v}, h_{g}\right)=h_{n} \cdot h_{g}^{T}$。我们提供了来自联合分布 $p$ 的正样本和来自边缘 $p \times \tilde{p}$ 乘积的负样本,并使用小批量随机梯度下降对模型参数进行了优化。我们发现,通过训练基编码器和增强编码器之间的随机交替来正则化编码器有助于基编码器更好地泛化。为此,我们在每一步都训练策略和增强头,但我们从伯努利中采样,以决定是更新基编码器还是增强编码器的权值。算法1总结了训练过程。

3 Experiments
数据集
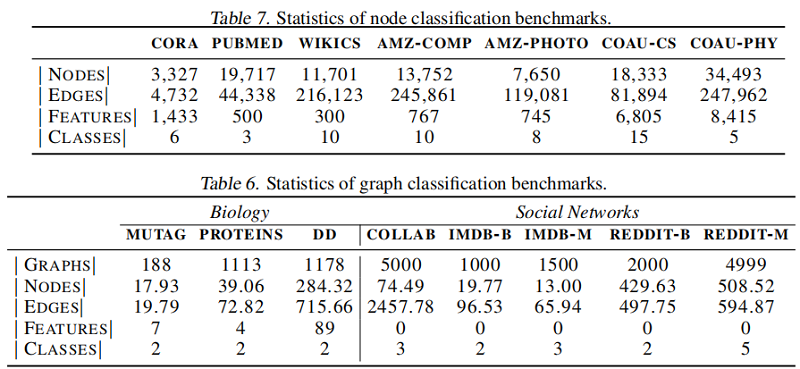
节点分类

图分类

4 Conclusion
我们引入了LG2AR和端到端框架来自动化图对比学习。所提出的框架可以端到端学习增强、视图选择策略和编码器,而不需要为每个数据集设计增强的特别试错过程。实验结果表明,LG2AR在8个图分类中的8个上取得了最先进的结果基准测试,与以前的无监督方法相比,7个节点分类基准测试中的6个。结果还表明,LG2AR缩小了与监督同行的差距。此外,研究结果表明,学习策略和学习增强功能都有助于提高性能。在未来的工作中,我们计划研究所提出的方法的大型预训练和迁移学习能力。
修改历史
2022-06-26 创建文章
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16409040.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号