论文解读(SCGC)《SCGC : Self-Supervised Contrastive Graph Clustering》
论文信息
论文标题:SCGC : Self-Supervised Contrastive Graph Clustering
论文作者:Gayan K. Kulatilleke, Marius Portmann, Shekhar S. Chandra
论文来源:2022, arXiv
论文地址:download
论文代码:download
1 Introduction
目前 GAE 存在的问题
-
- over-smoothing
- noisy neighbours (heterophily)
- the suspended animation problem
创新点:
-
- 使用 MLP 作为 backbone,简单、高效;
- 为加入结构信息,使用 结构损失 作为目标函数;
模型:Graph-MLP 改版
2 Method
整体框架如 Figure 1 所示:
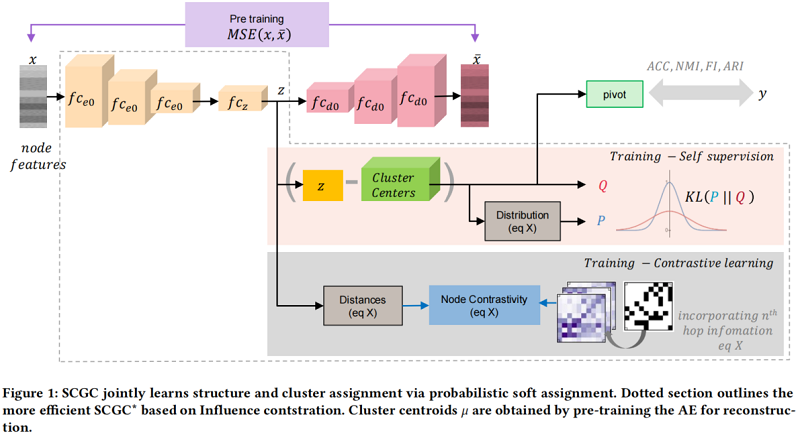
2.1 Graph structure by contrastive loss
对比损失使正或连通节点更近,负或不连通节点在特征空间中更远。基于此思想,将拓扑结构信息合并到嵌入中。
2.1.1 Influence Augmented Contrastive (IAC) loss.
考虑不同深度的节点之间的影响,本文考虑 可加性,对于一个给定的 $𝑅$ 深度,总影响定义为:
$\gamma_{i j}=\operatorname{Effect}_{R i j}=\sum\limits _{r=1}^{R} \alpha_{i j r} \text { relationship }{ }_{r}(i, j) \quad\quad \quad\quad(1)$
其中,$\alpha_{i j r}$ 为深度 $r$ 处节点 $i, j$ 之间关系的系数。
给定 $\gamma_{i j}$,将 $i^{t h}$ 节点的 $\text{IAC}$ 损失表示为:
${\large \ell_{i}=-\log \frac{\sum\limits _{j=1}^{B} \mathbf{1}_{[j \neq i]} \gamma_{i j} \exp \left(\operatorname{distance}\left(z_{i}, z_{j}\right) / \tau\right)}{10^{-8}+\sum\limits _{k=1}^{B} \mathbf{1}_{[k \neq i]} \exp \left(\operatorname{distance}\left(z_{i}, z_{k}\right) / \tau\right)} } \quad\quad \quad\quad(2)$
其中,$\tau$ 为温度参数,$\gamma_{i j}$ 为节点 $i$ 与 $j$ 之间连接的影响。
对于每个节点,$\text{R -hop}$ 邻域内的节点被认为是正样本,将其与所有节点进行对比。$\text{IAC}$ 损失鼓励有影响的节点在嵌入空间中比无影响的节点更近。接下来,概述了如何计算累积影响。
2.1.2 Determining Influence
归一化邻接矩阵:
$\widehat{A}=\mathrm{D}^{-\frac{1}{2} }(A+I) \mathrm{D}^{-\frac{1}{2} } \quad\quad\quad\quad(3)$
$r$ 次幂提供了节点 $i$ 和 $j$之间的 $r$ 跳关系的强度。
通过计算节点之间的累加关系作为节点关系强度,而不是限制在任意的第 $r $ 跳邻域上。即,将归一化邻接矩阵的 $R$ 次累积幂定义为 $\widehat{A}^{R}: \gamma_{i j}=\widehat{A}_{i j}^{R}$,其中,$\widehat{A}^{R}= \sum\limits \limits _{r=1}^{K} \widehat{A}^{r} $。$\widehat{A}^{R}$ 包含了$k=1 \cdots K$ 中所有先前的邻域跳跃关系的聚合集。 $\widehat{A}^{K}$ 只需要在训练之前计算一次,开销很少。另外,当节点 $j$ 对节点 $i$ 的 $\text{r -hop}$ 邻居产生非零影响时,$\gamma^{i j}$ 才能得到非零值。
$\gamma_{i j}\left\{\begin{array}{ll}=0, & \text { node } i \text { has no influence, nor is it connected } \\& \text { to node } j \text { for } K \text { hops } \\\neq 0, & \text { node } i \text { 's cumulative influence from } j \text { within } \\& \text { an } R \text {-hop neighbourhood }\end{array}\right. $
与我们在影响方面的工作不同,Graph-MLP 提出了基于余弦相似度的 NContrast (NC) 损失进行分类,其中每个节点只考虑 $𝑟-th$ 邻域,而不考虑更全面的加性影响。其 $\gamma_{i j}$ 的计算如下:
$\gamma_{i j}\left\{\begin{array}{ll}=0, & \text { node } j \text { is the } r \text {-hop neighbour of node } i \\\neq 0, & \text { node } j \text { is not the } r \text {-hop neighbour of node } i\end{array}\right.$
$\text{IAC}$ 或 $\text{NC}$ 的对比损失定义为:
$\operatorname{loss}_{\text {contrastive }}=\frac{1}{B} \sum\limits _{i=1}^{B} \ell_{i} \quad\quad\quad\quad(4)$
2.2 Self supervised clustering
图聚类本质上是一项无监督的任务,没有反馈来指导优化过程。为此,使用概率分布导出的软标签作为聚类增强的自监督机制,有效地将聚类叠加到嵌入上。
首先获得软集群分配概率 $q_{i u}$,嵌入 $z_{i}$ 和簇中心 $\mu_{u}$,使用 student's t -distribution 作为内核来衡量嵌入和质心之间的相似性,为处理不同的簇:
${\large q_{i u}=\frac{\left(1+\left\|z_{i}-\mu_{u}\right\|^{2} / \eta\right)^{-\frac{\eta+1}{2}}}{\sum_{u^{\prime}}\left(1+\left\|z_{i}-\mu_{u^{\prime}}\right\|^{2} / \eta\right)^{-\frac{\eta+1}{2}}}} \quad\quad\quad\quad(5)$
其中,簇中心 $\mu$ 由预先训练过的 AE 的嵌入上的 $z$ 经 $\text{K -means}$ 初始化,$\eta$ 是 Student's t-distribution 的自由度。使用 $Q=\left[q_{i u}\right]$ 作为所有样本的聚类分配的分布,并在实验中设置 $\eta=1$。
节点在 $Q$ 中具有更高的软分配概率,通过将 $Q$ 提高到二次幂并进行归一化,定义一个强调高置信度分配的目标分布$P$,将其定义为:
${\large p_{i u}=\frac{q_{i u}^{2} / \sum\limits _{i} q_{i u}}{\sum\limits _{k}\left(q_{i k}^{2} / \sum\limits _{i} q_{i k}\right)}} \quad\quad\quad\quad(6)$
其中,$\sum\limits _{i} q_{i u}$ 为质心 $u$ 的软簇频率。
为了使数据表示更接近聚类中心,将 KL 散度损失用于 $Q$ 和 $P$ 分布最小化,迫使当前分布 $Q$ 接近高置信度的目标分布 $P$。通过使用分布 $Q$ 来实现目标分布 $P$ 来自监督簇分配,然后通过最小化 KL 散度来依次监督分布 $Q$,如下:
$\operatorname{loss}_{\text {cluster }}=K L(P \| Q)=\sum\limits \limits _{i} \sum\limits \limits _{u} p_{i u} \log \frac{p_{i u}}{q_{i u}} \quad\quad\quad\quad(7)$
2.3 Initial centroids and embeddings
为了提取节点特征并获得初始嵌入 $z$ 和聚类质心 $\mu$ 进行优化,我们采用了基于AE的预训练阶段。首先,我们使用编码器-解码器通过最小化原始数据 $\mathrm{X} \in \mathbb{R}^{n \times d}$ 和重建数据 $\hat{\mathrm{X}} \in \mathbb{R}^{n \times d}$ 重构损失来提取潜在嵌入 $z$,即:
$loss _{\text {recon }}=\|\mathbf{X}-\hat{\mathbf{X}}\|_{F}^{2} \quad\quad\quad\quad(8)$
2.4 Final proposed models
$\begin{array}{l}\text { SCGC : } &\quad\mathrm{E}_{\mathrm{final}}=\alpha \operatorname{loss}_{\mathrm{nc}}(\mathrm{K}, \tau)+\beta \operatorname{loss}_{\text {cluster }}+\operatorname{loss}_{\text {recon }} \\\text { SCGC }^{*}: &\quad \mathrm{E}_{\text {final }}=\alpha \operatorname{loss}_{\mathrm{iac}}(\mathrm{K}, \tau)+\beta \operatorname{loss}_{\text {cluster }}\end{array} \quad\quad\quad\quad(9)$
3 Experiments
数据集
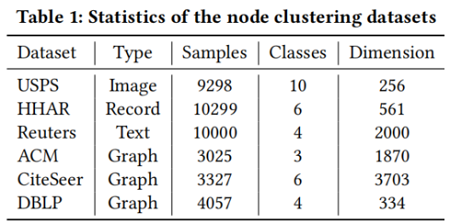
聚类性能

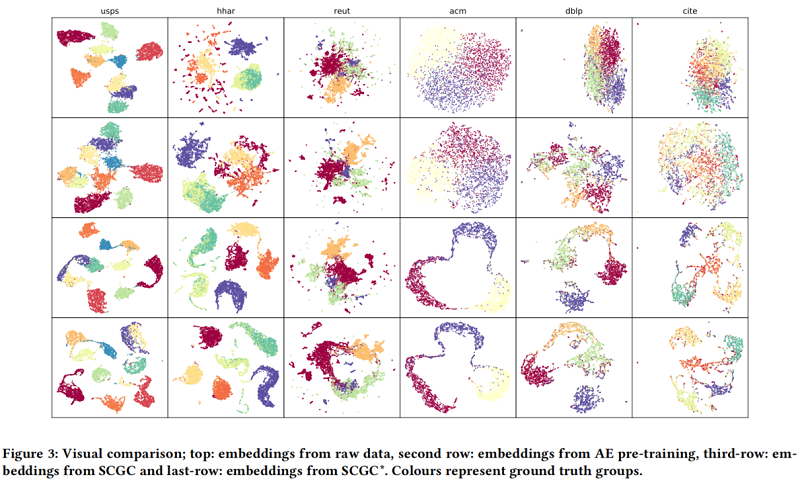
定性结果
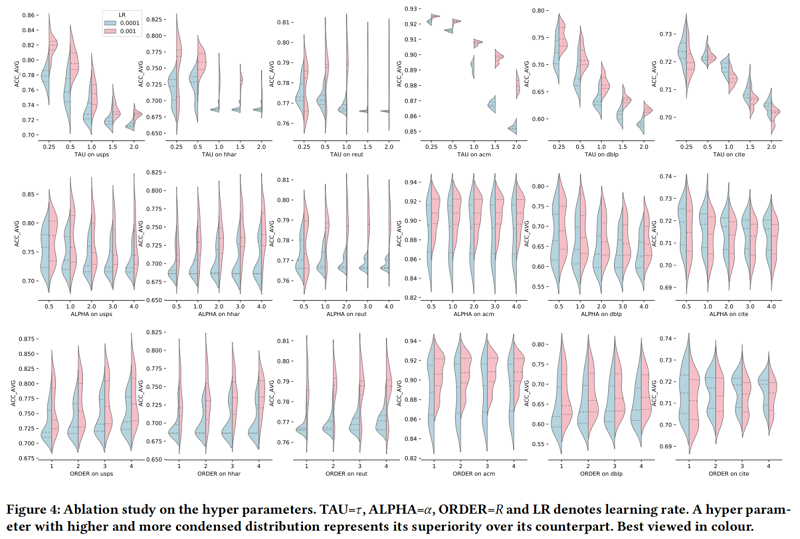
消融实验
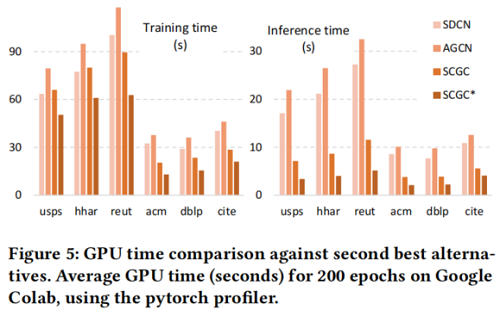
时间开销
4 Conclusion
使用 MLP 作为编码器,并采用结构对比损失做指导。
修改历史
2022-05-20 创建文章
2022-06-23 二次修改
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16290017.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号