
现代编译原理--第二章(语法分析之上下文无关文法)
(转载请表明出处 http://www.cnblogs.com/BlackWalnut/p/4471938.html )
我们知道了词法分析是专注于一个检测一个语言中是否有不合格的单词,以及将单词进行分类。那么为什么要分类呢?其目的就是为了规范化。只有无限的东西规范到一个范围内,我们才能对其进行识别和分析。例如,我们定义在加号两边只能是两个ID。这样,如果出现IF PLUS ID 这样的结构就说明是不正确的,其犯了语法错误。
从上例可以看出,我们已经从单词级别的分析转换到了单词与单词之间的关系的分析。他们之间的关系就是我们定义的相关语法。
类似于词法分析,我们为了描述一类单词,使用了正则表达式,在这里,我们为了描述一类语法,我们使用了上下文无关文法。由此可以知道,文法是用来定义句子结构的(单词与单词之间的关系),上下文无关文法是指,该文法所定义的所有的句子结构之间是没有关系的。例如ID = ID + ID,我们不关心ID在怎么来的,经历了那些东西,我们只关心一个字符是不是ID,以及ID的等价形式有那些。
以上只是对文法的感性描述,比较正规的定义是:一个上下文无关文法包含四个成分,终结符号集合,非终结符号集合,起始符号,产生式集合。
产生式的形式是A->B这种形式,其中左面一定是非终结符,右面是终结符和非终结符的混合。所以,凡事能够放到左面的符号都成为非终结符,是由语法的设计者定义的。终结符就是不能产生产生式的符号,比如语言中的+,-,),>等。起始符号是非终结符集合中的一个,表示语法分析从这个符号开始。例如:A->B+C, B->A,C->-C,使用B和C代替第一产生式中的相应部分,就可以得到一个能不限数字个数的加减法运算表达式。考虑下面一个文法:
如果使用上面的文法来分析1+2*3这样的语句,我们就可能得到两个同的分析过程:
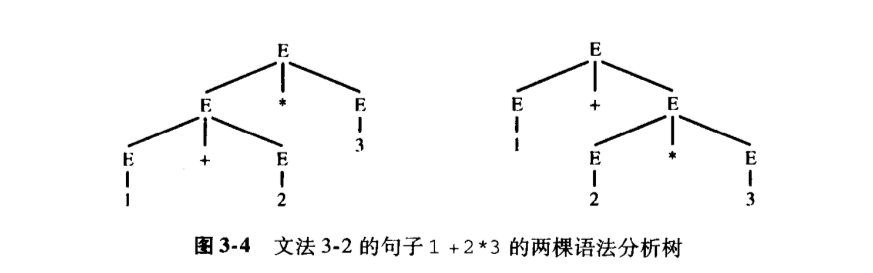
上面的树形结构就是语法分析树。采用自底向上的方式来计算表达式,第一个是(1+2)*3,第二个是1+(2*3)。如果一个文法对一个句子进行分析可以产生多个语法分析树,我们就称这个文法是二义文法。这个时候计算机就不知道该使用哪个过程了。但是,通常二义文法可以转化成非二义文法:
上面这个文法就规定了*具有更高的优先级,且文法是左结合的文法。这里的S就是起始符号,💲的意思是如果遇到这个符号表示一个文法分析过程的结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号