2025.8.12学习日记
1.全流程
AI全流程包括AI应用->AI框架+AI推理引擎->计算架构+传统编译器->硬件结构体系
1.1 推理路线
AI应用就是一系列的数学公式的文本文件例如Conv,Relu,Sigmoid,Mul等,现在我们假设在CPU上进行推理,那么CPU其实并不了解这一串数学公式,因为CPU只看得懂自己的机器语言以及汇编语言,此时AI推理引擎-ONNX作为第一位翻译,负责将数学公式翻译成高级语言代码,例如C代码等,交由编译器-GCC作为第二位翻译,将高级语言代码编译成CPU可执行指令
现在假设在GPU上进行推理,AI推理引擎-ONNX仍然作为第一位翻译,此时会将其翻译为C代码,但这个C语言是GPU厂家为自己的硬件所开发的C标准,交由CUDAC编程语言+NVCC编译器作为第二位翻译,将高级语言代码编译成GPU可以执行的指令
【注】:英伟达的GPU硬件,其汇编语言称为PTX;华为的昇腾显卡针对自己的GPU硬件也拥有AscendC编程语言+毕昇编译器;编程语言(cudac)+编译器(nvcc)+算子加速库(cudnn),这一形式也被称为计算架构,实际上计算架构的最小范式是语言+编译器
1.2 训练路线
AI应用是如何被制造出来的,答案就在训练这个流程里,这个过程分为两步,首先是编写数学公式,之后是根据数据集确定数学公式的参数。为了更方便地制作模型,AI框架由此诞生,通过提供软件工具+预设模块(预设的公式)帮助我们搭建模型。之后就是交由计算架构以及硬件,完成一次训练。
2.工具说明
2.1 计算架构与硬件架构
计算架构版本主要指CudaToolkit中的cuda驱动版本,主要是使用nvcc命令来查看;硬件架构版本(特指GPU)主要是指硬件驱动版本和cuda版本,使用nvidia-smi查看。理论上只要计算架构版本不超过硬件驱动版本,CudaToolkit就可以正常工作。
【注】:安装CudaToolkit时,请取消勾选驱动组件,仅安装CUDA 编译器 (nvcc),CUDA 库 (cuBLAS, cuDNN 等),开发头文件,工具链(如 nsight)
2.2 CUDAToolkit
- conda install cudatoolkit:适合运行深度学习框架,简单快捷。
- NVIDIA 官方 CUDA Toolkit:适合开发和编译 CUDA 程序,功能完整。
3.Torchvision
3.1 变换模块
torchvision.transforms.v2模块中支持的图像对象有纯张量,Image类型图像,PIL图像类型,Image类型的构造如下:

支持的视频对象有Video,其类型的构造如下:

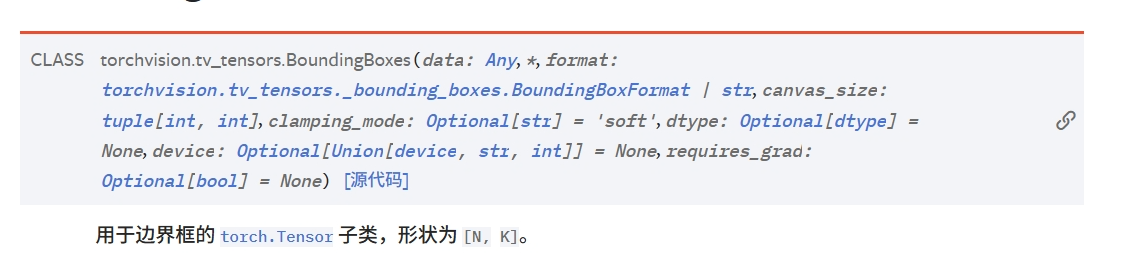
支持边界框BoundingBoxes,一般大小为[N,K],其中N代表边界框数量,K一般等于4,用于表示方形边界框,其类型构造如下:
支持用于分割和检测的Mask,其类型的构造如下:

用于表示2D点序列的KeyPoints,其类型构造如下:


3.1 输入类型以及约定
Transforms支持PIL图像以及张量输入,在张量输入中,CPU张量和CUDA张量也受到支持。可以使用conversion-transforms对两种输入进行转换。
张量形状为[C,H,W],变换支持批量输入[N,C,H,W,]张量,v2支持节后任意数量的前导维度的[...,C,H,W]张量
3.2 数据类型与数据范围
浮点数据类型的张量数据范围为[0,1],整数数据类型(uint8)的张量数据范围为[0,255],使用ToDtype可以将输入转为为特定的数据类型
3.3 性能注意事项
- 依赖 torchvision.transforms.v2 中的 v2 转换
- 使用张量而非 PIL 图像
- 使用 torch.uint8 数据类型,特别是在调整大小时
- 使用双线性或三次插值模式进行缩放
4.模型和预训练权重
torchvision对不同的任务,提供模型和预训练权重,包括:图像分类,像素级语义分割,实例分割...
4.1 通用操作
对于torchvision中的预训练模型,通常包含了如下操作:初始化内置预训练模型,使用预训练模型,检索可用的内置模型,使用外部Hub中的模型,这里重点介绍一下如下两个操作
- 使用预训练模型:
按官方文档的描述,使用预训练模型之前,需要对图像进行预处理变换,所有预训练模型的推理信息在文中文档中.使用方法如下:
# Initialize the Weight Transforms
weights = ResNet50_Weights.DEFAULT
preprocess = weights.transforms()
# Apply it to the input image
img_transformed = preprocess(img)
- 列出和检索可用模型:
torchvision提供了一种新的机制,允许按名称列出和检索模型,使用如下语句可以将支持的所有模型写入demo1.txt文件中.
"""
列出与检索可用模型
"""
import torchvision
all_models = torchvision.models.list_models()
with open("demo1.txt","w") as f:
f.write("Available models:\n")
[f.write(f"{item}\n") for item in all_models]
4.2 分类模型
下面是一个使用预训练图像分类模型的示例,当模型权重在/root/.cache/torch/hub中找不到时,会自动从www.pytorch.org/models中下载,命令行会进行提示
"""
使用分类模型
"""
from pathlib import Path
from torchvision.io import decode_image
from torchvision.models import resnet50, ResNet50_Weights
img = decode_image(Path(__file__).parent.parent / "assets" / "meow.jpg")
# 如果是4通道变3通道
if img.shape[0] == 4:
img = img[:3]
# Step 1: Initialize model with the best available weights
weights = ResNet50_Weights.DEFAULT
model = resnet50(weights=weights)
model.eval()
# Step 2: Initialize the inference transforms
preprocess = weights.transforms()
# Step 3: Apply inference preprocessing transforms
batch = preprocess(img).unsqueeze(0)
# Step 4: Use the model and print the predicted category
prediction = model(batch).squeeze(0).softmax(0)
class_id = prediction.argmax().item()
score = prediction[class_id].item()
category_name = weights.meta["categories"][class_id]
print(f"{category_name}: {100 * score:.1f}%")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号