
mysql的全文索引
全文索引使用倒排索引(inverted index)的方式,将字段中的内容进行分词,存储分词与自身所在位置的映射,从而加快查询效率。
创建索引
CREATE FULLTEXT INDEX full_index_name ON table_name(col_name) [WITH PARSER ngram];注意,如果该字段中的内容是中文,一定要使用 WITH PARSER ngram 指定 N-gram 分词插件
假如使用navicat创建索引,为了保证中文可用,需要指定解析器:
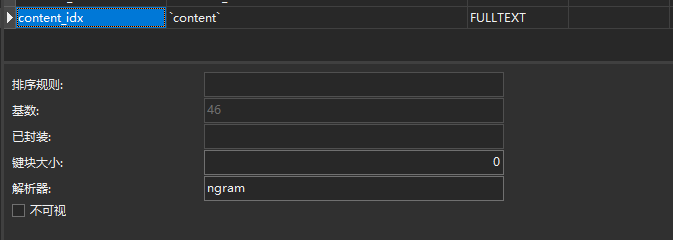
基本语法
自然语言搜索
-- 查询head,content列中包含“科技”的结果
SELECT
*
FROM
`pre_article`
WHERE
MATCH ( head, content ) AGAINST ( '科技' );-- 查询相关性
SELECT
id,head,content,
MATCH ( head, content ) AGAINST ( '理想' )
FROM
pre_article;需要注意的是,包含在stopword里面的关键词是检索不出来的
-- 查看mysql内置的stopword
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD;使用中文的自然语言搜索,在搜索关键词是英文的时候,通常会发生一些莫名其妙的问题,将不该被搜索到的信息搜索出来。
布尔搜索
包括特殊的查询语言规则,默认用法如下:
SELECT
id,head,content
FROM
`pre_article`
WHERE
MATCH ( head, content ) AGAINST ( '科技' IN BOOLEAN MODE);
1. + 表示某个关键词必须存在
SELECT
id,head,content
FROM
`pre_article`
WHERE
MATCH ( head, content ) AGAINST ( '+科技' IN BOOLEAN MODE);
2. - 表示关键词必须不存在
-- 包含科技但不包含文物,注意中间的空格
SELECT
id,head,content
FROM
`pre_article`
WHERE
MATCH ( head, content ) AGAINST ( '+科技 -文物' IN BOOLEAN MODE);
3. 没有操作符
-- 表示包含“科技”或者“文物”
SELECT
id,head,content
FROM
`pre_article`
WHERE
MATCH ( head, content ) AGAINST ( '科技 文物' IN BOOLEAN MODE);
4. * 表示已关键词开头
-- 这通常用在英文的查询中
SELECT
id,head,content
FROM
`pre_article`
WHERE
MATCH ( head, content ) AGAINST ( 'sec*' IN BOOLEAN MODE);
5. ""表示短语
SELECT
id,head,content
FROM
`pre_article`
WHERE
MATCH ( head, content ) AGAINST ( '"高考数学"' IN BOOLEAN MODE);查询扩展搜索
通常用在查询词太短,进行一次查询后,根据第一查询结果产生的分词进行第二次查询。请谨慎使用。
SELECT
id,head,content
FROM
`pre_article`
WHERE
MATCH ( head, content ) AGAINST ( '科技' WITH QUERY expansion);
本文来自博客园,作者:Bin_x,转载请注明原文链接:https://www.cnblogs.com/Bin-x/p/16571700.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号