tcmalloc原理分析总结
实习期间遇到的项目,网上找了很多资料简单的扒了一下源码,这里发出markdown记录一下。
写的内容基本上是摘抄各个大佬的文章分析,建议直接看原文分析,非常感谢各位前辈!
下面是原文链接↓
https://kernelmaker.github.io/
https://wallenwang.com/2018/11/tcmalloc/#ftoc-heading-19
https://paper.seebug.org/papers/Archive/refs/heap/glibc%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86ptmalloc%E6%BA%90%E4%BB%A3%E7%A0%81%E5%88%86%E6%9E%90.pdf
初始化
-
初始化SizeMap(Size Class)
-
初始化各种Allocator
-
初始化CentralCache
-
创建PageHeap
就是创建TCMalloc自身需要并定义的一些数据结构,如SizeClass, PageHeap, Span之类的。
TCmalloc的内存如何进行分配
基本的数据结构
按照所分配内存的大小,TCMalloc将内存分配分为三类:
-
小对象,(0, 256KB]
-
中对象,(256KB, 1MB]
-
大对象,(1MB, +∞)
在TCmalloc中有三个抽象的数据结构,用来区分内存的等级(大小?),分别是Page,Span,PageHeap,详细如下:
TCMalloc将整个虚拟内存空间划分为n个同等大小的Page,每个page默认8KB。又将连续的n个page称为一个Span。
TCMalloc定义了PageHeap类来处理向OS申请内存相关的操作,并提供了一层缓存。可以认为,PageHeap就是整个可供应用程序动态分配的内存的抽象。
PageHeap以span为单位向系统申请内存,申请到的span可能只有一个page,也可能包含n个page。可能会被划分为一系列的小对象,供小对象分配使用,也可能当做一整块当做中对象或大对象分配。

整体结构图
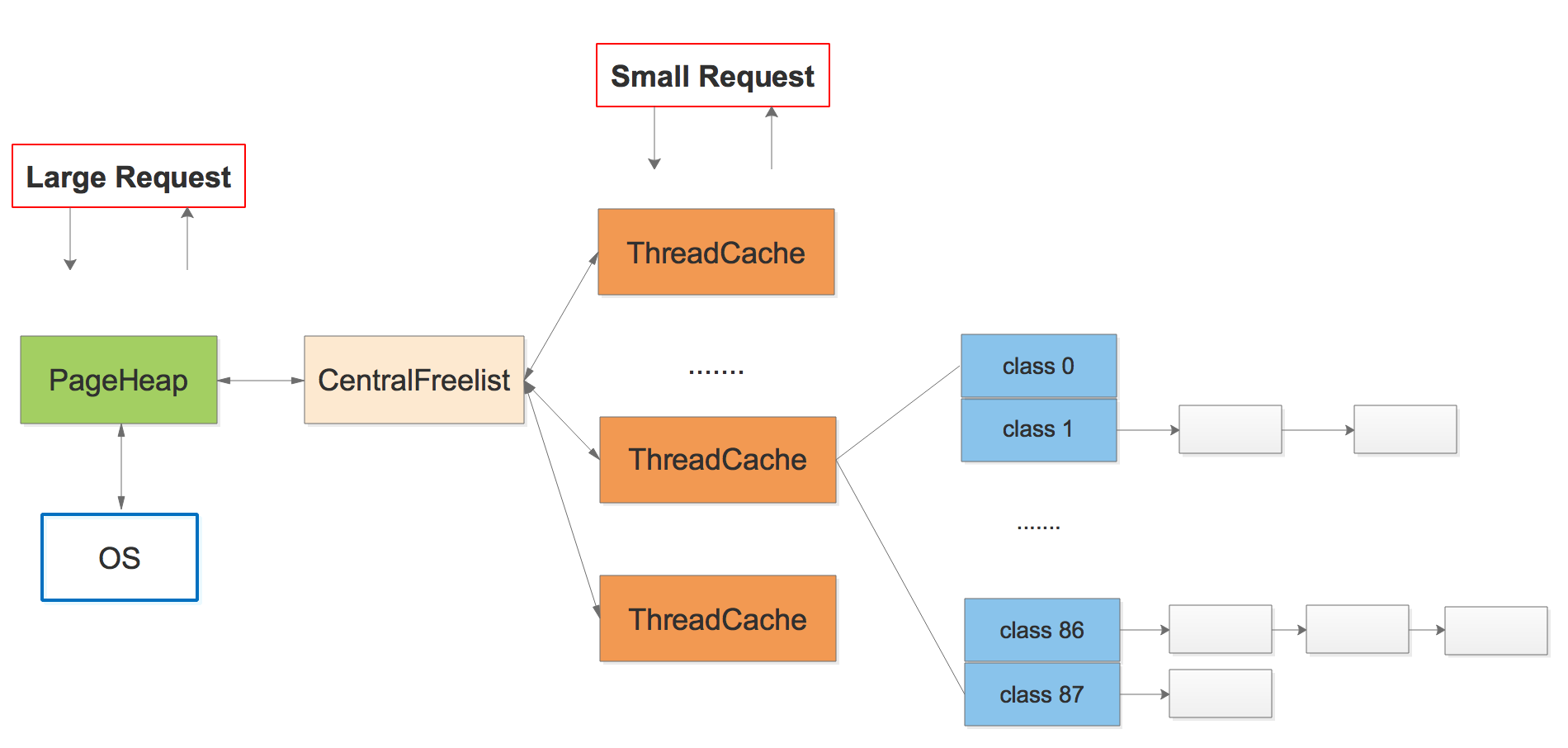
上图是TCmalloc的主要分配结构,分为三个部分:PageHeap,CentralFreeList,ThreadCache.
-
ThreadCache:线程缓存,是一个线程本地的数据,tcmalloc指定小于256k的小内存申请均由threadcache进行分配;因为是线程的私有变量,不需要加锁进行保护,所以可以极大地提高分配速度。
-
PageHeap: 中央堆分配器,被线程共享,所以需要进行加锁保护线程安全,负责与OS的直接交互,tcmalloc指定大对象由pageheap进行分配。
-
CentralFreeList:作为PageHeap与ThreadCache的中间人,负责
-
将PageHeap中的内存切分为span,在恰当时机分配给ThreadCache。
-
-
获取从ThreadCache中回收的内存并在恰当的时机将部分内存归还给PageHeap
分配总结
小对象分配:
总结一下,小对象分配流程大致如下:
-
将要分配的内存大小映射到对应的size class。
-
查看ThreadCache中该size class对应的FreeList。
-
如果FreeList非空,则移除FreeList的第一个空闲对象并将其返回,分配结束。
-
如果FreeList是空的:
-
从CentralCache中size class对应的CentralFreeList获取一堆空闲对象。
-
如果CentralFreeList也是空的,则:
-
向PageHeap申请一个span。
-
拆分成size class对应大小的空闲对象,放入CentralFreeList中。
-
-
-
将这堆对象放置到ThreadCache中size class对应的FreeList中(第一个对象除外)。
-
返回从CentralCache获取的第一个对象,分配结束。
-
中对象分配:
中对象也就是大小小于128page的span对象。
首先,tcmalloc会将所需要的内存大小向上对齐到整数个page(会产生内存碎片),之后返回对应的Pagespan中的span的起始地址即可。
不过中对象的申请内存并不是每次都像系统请求,他提供了特俗的缓存分配策略,
假设要分配一块内存,其大小经过向上取整之后对应k个page,因此需要从PageHeap取一个大小为k个page的span,过程如下:
-
从k个page的span链表开始,到128个page的span链表,按顺序找到第一个非空链表。
-
取出这个非空链表中的一个span,假设有n个page,将这个span拆分成两个span:
-
一个span大小为k个page,作为分配结果返回。
-
另一个span大小为n – k个page,重新插入到n – k个page的span链表中。
-
-
如果找不到非空链表,则将这次分配看做是大对象分配。
大对象分配:
超过128个page(128 * 8)的内存分配称为大对象分配,与中对象分配类似,也是先将所要分配的内存大小向上取整到整数个page,假设是k个page,然后向PageHeap申请一个k个page大小的span。
对于中对象的分配,如果上述的span链表无法满足,也会被当做是大对象来处理。也就是说,TCMalloc在源码层面其实并没有区分中对象和大对象,只是对于不同大小的span的缓存方式不一样罢了。
大对象分配用到的span都是超过128个page的span,其缓存方式不是链表,而是一个按span大小排序的有序set(std::set),以便按大小进行搜索。
假设要分配一块超过1MB的内存,其大小经过向上取整之后对应k个page(k>128),或者是要分配一块1MB以内的内存,但无法由中对象分配逻辑来满足,此时k <= 128。不管哪种情况,都是要从PageHeap的span set中取一个大小为k个page的span,其过程如下:
-
搜索set,找到不小于k个page的最小的span(best-fit),假设该span有n个page。
-
将这个span拆分为两个span:
-
一个span大小为k个page,作为结果返回。
-
另一个span大小为n – k个page,如果n – k > 128,则将其插入到大span的set中,否则,将其插入到对应的小span链表中。
-
-
如果找不到合适的span,则使用sbrk或mmap向系统申请新的内存以生成新的span,并重新执行中对象或大对象的分配算法。
归纳:
整体的思路是,tcmalloc为每个线程都提供一个线程局部的 ThreadCache,ThreadCache中包含一个链表数组FreeList,维护了不同规格的空闲内存的链表;当申请内存的时候可以直接根据大小寻找恰当的规则的内存。如果ThreadCache的对象不够了,就从 CentralCache 进行批量申请;如果 CentralCache 依然没有,就从PageHeap申请Span;128个Page以内的span,PageHeap首先在free[n,128]中查找,超过128个page的到large set中查找,目标就是找到一个最小的满足要求的空闲Span,优先使用normal类链表中的Span。如果找到了一个Span,则尝试分裂(Carve)这个Span并分配出去;如果所有的链表中都没找到length>=n的Span,则从操作系统申请了。Tcmalloc一次最少向系统申请1MB的内存,默认情况下,使用sbrk申请,在sbrk失败的时候,使用mmap申请。
实现细节
PageID
TCMalloc并非只将堆内存看做是一个个的page,而是将整个虚拟内存空间都看做是page的集合。从内存地址0x0开始,每个page对应一个递增的PageID,如下图(以32位系统为例):
对于任意内存地址ptr,都可通过简单的移位操作来计算其所在page的PageID:
const int KPageShif = 13; //也就是2^13 8KB
inline PageId PageIdContaining(const void* p) {
return PageId(reinterpret_cast<uintptr_t>(p) >> kPageShift);
}
即,ptr所属page的PageID为ptr / page_size
Span
一个或多个连续的Page组成一个Span(a contiguous run of pages)。TCMalloc以Span为单位向系统申请内存。
Span记录了起始Page的PageID(start),以及所包含的Page的数量。
一个Span要么被拆分成多个相同size class的小对象用于小对象分配,要么作为一个整体用于中对象或大对象分配。当作用作小对象分配时,span的sizeclass成员变量记录了其对应的size class。
Span类型继承了TList::Elen类(双链表),拥有prev和next指针,将多个Span以链表形式存储。
Span的三种类型
-
IN_USE
-
ON_NORMAL_FREELIST
-
ON_RETURNED_FREELIS
了,要么已经分配给应用程序了。因为span是由PageHeap来管理的,因此即使只是分配给了CentralCache,还没有被应用程序所申请,在PageHeap看来,也是IN_USE了。
ON_NORMAL_FREELIST和ON_RETURNED_FREELIST都可以认为是空闲状态,区别在于ON_RETURNED_FREELIST是指span对应的内存已经被PageHeap释放给系统了(在Linux中,对于MAP_PRIVATE|MAP_ANONYMOUS的内存使用madvise来实现)。需要注意的是,即使归还给系统,其虚拟内存地址依然是可访问的,只是对这些内存的修改丢失了而已,在下一次访问时会导致page fault以用0来重新初始化
空闲对象链表
被拆分成多个小对象的span还包含了一个记录空闲对象的链表objects,由CentralFreeList来维护。
对于新创建的span,将其对应的内存按size class的大小均分成若干小对象,在每一个小对象的起始位置处存储下一个小对象的地址,首首相连:
class Span : public SpanList::Elem{
PageId first_page_; // Starting page number.
Length num_pages_; // Number of pages in span.
enum Location {
IN_USE, // not on PageHeap lists
ON_NORMAL_FREELIST, // on normal PageHeap list
ON_RETURNED_FREELIST, // on returned PageHeap list
};
}
PageMap
PageMap用于记录PageID到span的映射关系。

在root_数组中包含512个指向Leaf的指针,每个Leaf又是1024个void*的数组,数组索引为PageID,数组元素为page所属Span的指针。一共$2^{19}$个数组元素,对应32位系统的$2^{19}$个page。
使用两级map可以减少TCMalloc元数据的内存占用,因为初始只会给第一层(即root_数组)分配内存(2KB),第二层只有在实际用到时才会实际分配内存。而如果初始就给$2^{19}$个page都分配内存的话,则会占用$2^{19} * 4 bytes = 2MB$的内存。
Size Class
TCmalloc将每个对象大小分成不同的类别,称为Size class,每个size class一个索引。
划分跨度
-
16字节以内,每8字节划分一个size class。
-
满足这种情况的size class只有两个:8字节、16字节。
-
-
16~128字节,每16字节划分一个size class。
-
满足这种情况的size class有7个:32, 48, 64, 80, 96, 112, 128字节。
-
-
128B~256KB,按照每次步进
(size/8)字节的长度划分,并且步长需要向下对齐到2的整数次幂,比如:-
144字节:128 + 128 / 8 = 128 + 16 = 144
-
160字节:144 + 144 / 8 = 144 + 18 = 144 + 16 = 160
-
176字节:160 + 160 / 8 = 160 + 20 = 160 + 16 = 176
-
以此类推
-
一次移动多个对象
ThreadCache会从CentralCache中获取空闲对象,也会将超出限制的空闲对象放回CentralCache。ThreadCache和CentralCache之间的对象移动是批量进行的,即一次移动多个空闲对象。CentralCache由于是所有线程公用,因此对其进行操作时需要加锁,一次移动多个对象可以均摊锁操作的开销,提升效率。
每次移动的个数为batch size,由size class直接指定。
由以上划分规则可以看到,一个size class对应:
-
一个对象大小
-
一个申请page的数量
-
一个批量移动对象的数量
TCMalloc将size class与这些信息的映射关系分别记录在三个以size class的编号为索引的数组中(class_to_size_,num_objects_to_move_, class_to_pages_)。
计算任意内存地址对应的对象大小
当应用程序调用free()或delete释放内存时,需要有一种方式获取所要释放的内存地址对应的内存大小。结合前文所述的各种映射关系,在TCMalloc中按照以下顺序计算任意内存地址对应的对象大小:
-
计算给定地址计所在的PageID(ptr >> 13)
-
从PageMap中查询该page所在的span
-
span中记录了size class编号
-
根据size class编号从
class_to_size_数组中查询对应的对象大小
这样做的好处是:当应用程序调用free()或delete释放内存时,需要有一种方式获取所要释放的内存地址对应的内存大小。结合前文所述的各种映射关系,在TCMalloc中按照以下顺序计算任意内存地址对应的对象大小:
-
计算给定地址计所在的PageID(ptr >> 13)
-
从PageMap中查询该page所在的span
-
span中记录了size class编号
-
根据size class编号从
class_to_size_数组中查询对应的对象大小
这样做的好处是:不需要在内存块的头部记录内存大小,减少内存的浪费。
Page Heap
Span管理器
128page以内的page和128page以上的Span采用了不同的处理策略。小Span使用的是链表进行管理,而大Span采用的是标准库std::set。
从另一个维度来看,PageHeap是分开管理ON_NORMAL_FREELIST和ON_RETURNED_FREELIST状态的span的。因此,每个小span对应两个链表,所有大span对应两个set。
struct SpanList {
Span normal;
Span returned;
};
// Array mapping from span length to a doubly linked list of free spans
//
// NOTE: index 'i' stores spans of length 'i + 1'.
SpanList free_[kMaxPages]; // 128
typedef std::set<SpanPtrWithLength, SpanBestFitLess, STLPageHeapAllocator<SpanPtrWithLength, void> > SpanSet;
// Sets of spans with length > kMaxPages.
//
// Rather than using a linked list, we use sets here for efficient
// best-fit search.
如图所示:
创建Span
假设创建K个Page大小的Span,过程如下:
-
搜索空闲span链表,按照以下顺序,找出第一个不小于k的span:
-
从大小为k的span的链表开始依次搜索
-
对于某个大小的span,先搜normal链表,再搜returned链表
-
如果span链表中没找到合适的span,则搜索存储大span的set:
-
从大小为k的span开始搜索
-
同样先搜normal再搜returned
-
优先使用长度最小并且起始地址最小的span(best-fit)
-
如果通过以上两步找到了一个大小为m的span,则将其拆成两个span:
-
大小为m – k的span重新根据大小和状态放回链表或set中
-
大小为k的span作为结果返回,创建span结束
-
如果没搜到合适的span,则向系统申请内存。
向系统申请内存
bool GrowHeap(Length n);
找不到合适的空闲span,就只能向系统申请新的内存了。
TCMalloc以sbrk()和mmap()两种方式向系统申请内存,所申请内存的大小和位置均按page对齐,优先使用sbrk(),申请失败则会尝试使用mmap().
删除Span
// Delete the span "[p, p+n-1]".
// REQUIRES: span was returned by earlier call to New() and
// has not yet been deleted.
void Delete(Span* span);
当span所拆分成的小对象全部被应用程序释放变为空闲对象,或者作为中对象或大对象使用的span被应用程序释放时,需要将span删除。不过并不是真正的删除,而是放到空闲span的链表或set中。
删除的操作非常简单,但可能会触发合并span的操作,以及释放内存到系统的操作。
释放Span
Length ReleaseAtLeastNPages(Length num_pages);
在delete一个span时还会以一定的频率触发释放span的内存给系统的操作(ReleaseAtLeastNPages())。释放的频率可以通过环境变量TCMALLOC_RELEASE_RATE来修改。默认值为1,表示每删除1000个page就尝试释放至少1个page,2表示每删除500个page尝试释放至少1个page,依次类推,10表示每删除100个page尝试释放至少1个page。0表示永远不释放,值越大表示释放的越快。
释放规则:
-
从小到大循环,按顺序释放空闲span,直到释放的page数量满足需求。
-
多次调用会从上一次循环结束的位置继续循环,而不会重新从头(1 page)开始。
-
释放的过程中能合并span就合并span
-
可能释放少于num_pages,没那么多free的span了。
-
可能释放多于num_pages,还差一点就够num_pages了,但刚好碰到一个很大的span。
ThreadHeap
线程缓存
ThreadCache是一组FreeList。对于每个size class,在ThreadCache中都有一个FreeList,缓存了一组空闲对象,应用程序申请256KB以内的小内存时,优先返回FreeList中的一个空闲对象。因为每个线程每个size class都有单独的FreeList,因此这个过程是无锁的,速度快。
线程的本地缓存是通过TSD和TLS实现的。
何时创建threadCache
当某线程第一次申请分配内存时,TCMalloc为该线程创建其专属的
ThreadCache(ThreadCache::GetCache() -> ThreadCache::CreateCacheIfNecessary())。
何时销毁ThreadCache
在TCMalloc初始化TSD时,会调用Pthreads API中的pthread_key_create()创建ThreadCache对应的key,并且指定了销毁ThreadCache的函数ThreadCache::DestroyThreadCache()。因此,当一个线程销毁时,其对应的ThreadCache会由该函数销毁。
慢启动算法: freelist长度控制
控制ThreadCache中各个FreeList中元素的数量是很重要的:
-
太小:不够用,需要经常去CentralCache获取空闲对象,带锁操作
-
太大:太多对象在空闲列表中闲置,浪费内存
不仅是内存分配,对于内存释放来说控制FreeList的长度也很重要:
-
太小:需要经常将空闲对象移至CentralCache,带锁操作
-
太大:太多对象在空闲列表中闲置,浪费内存
并且,有些线程的分配和释放是不对称的,比如生产者线程和消费者线程,这也是需要考虑的一个点。
类似TCP的拥塞控制算法,TCMalloc采用了慢启动(slow start)的方式来控制FreeList的长度,其效果如下:
-
FreeList被使用的越频繁,最大长度就越大。
-
如果FreeList更多的用于释放而不是分配,则其最大长度将仅会增长到某一个点,以有效的将整个空闲对象链表一次性移动到CentralCache中。
分配内存时的慢启动代码如下(FetchFromCentralCache):
const int batch_size = Static::sizemap()->num_objects_to_move(cl);
// Increase max length slowly up to batch_size. After that,
// increase by batch_size in one shot so that the length is a
// multiple of batch_size.
if (list->max_length() < batch_size) {
list->set_max_length(list->max_length() + 1);
} else {
// Don't let the list get too long. In 32 bit builds, the length
// is represented by a 16 bit int, so we need to watch out for
// integer overflow.
int new_length = min<int>(list->max_length() + batch_size,
kMaxDynamicFreeListLength);
// The list's max_length must always be a multiple of batch_size,
// and kMaxDynamicFreeListLength is not necessarily a multiple
// of batch_size.
new_length -= new_length % batch_size;
ASSERT(new_length % batch_size == 0);
list->set_max_length(new_length);
}
max_length即为FreeList的最大长度,初始值为1。batch_size是size class一节提到的一次性移动空闲对象的数量,其值因size class而异。
可以看到,只要max_length没有超过batch_size,每当FreeList中没有元素需要从CentralCache获取空闲对象时(即FetchFromCentralCache),max_length就加1。
一旦max_length达到batch_size,接下来每次FetchFromCentralCache就会导致max_length增加batch_size。
但并不会无限制的增加,最大到kMaxDynamicFreeListLength(8192),以避免从FreeList向CentralCache移动对象时,因为对象过多而过长的占用锁。
再来看内存回收时的情况,每次释放小对象,都会检查FreeList的当前长度是否超过max_length:
if (PREDICT_FALSE(length > list->max_length())) {
ListTooLong(list, cl);
return;
}
如果超长,则执行以下逻辑:
void ThreadCache::ListTooLong(FreeList* list, uint32 cl) {
size_ += list->object_size();
const int batch_size = Static::sizemap()->num_objects_to_move(cl);
ReleaseToCentralCache(list, cl, batch_size);
// If the list is too long, we need to transfer some number of
// objects to the central cache. Ideally, we would transfer
// num_objects_to_move, so the code below tries to make max_length
// converge on num_objects_to_move.
if (list->max_length() < batch_size) {
// Slow start the max_length so we don't overreserve.
list->set_max_length(list->max_length() + 1);
} else if (list->max_length() > batch_size) {
// If we consistently go over max_length, shrink max_length. If we don't
// shrink it, some amount of memory will always stay in this freelist.
list->set_length_overages(list->length_overages() + 1);
if (list->length_overages() > kMaxOverages) {
ASSERT(list->max_length() > batch_size);
list->set_max_length(list->max_length() - batch_size);
list->set_length_overages(0);
}
}
if (PREDICT_FALSE(size_ > max_size_)) {
Scavenge();
}
}
与内存分配的情况类似,只要max_length还没有达到batch_size,每当FreeList的长度超过max_length,max_length的值就加1。
当max_length达到或超过batch_size后,并不会立即调整max_length,而是累计超过3次(kMaxOverages)后,才会将max_length减少batch_size。
CentralCache
CentralCache是逻辑上的概念,其本质是CentralFreeListPadded类型(CentralFreeList的子类,用于64字节对齐)的数组,每个size class对应数组中的一个元素。
各线程公用一个CentralCache,所以使用CentralCache时需要加锁。
以下讨论都是针对某一个size class的。
CentralFreeList中缓存了一系列小对象,供各线程的ThreadCache取用,各线程也会将多余的空闲小对象还给CentralFreeList,另外CentralFreeList还负责从PageHeap申请span以分割成小对象,以及将不再使用的span还给PageHeap。
分割Span
CentralFreeList真正管理的是span,而小对象是包含在span中的空闲对象链表中的。CentralFreeList的empty_链表保存了已经没有空闲对象可用的span,nonempty_链表保存了还有空闲对象可用的span:
从PageHeap获取span
当ThreadCache从CentralFreeList取用空闲对象(RemoveRange),但CentralFreeList的空闲对象数量不够时,CentralFreeList调用Populate()从PageHeap申请一个span拆分成若干小对象,首首连接记录在span的objects指针中,即每个小对象的起始位置处,记录了下一个小对象的地址。此时的span如下图:
归还Span
CentralFreeList维护span的成员变量refcount,用来记录ThreadCache从中获取了多少对象。
当ThreadCache将不再使用的对象归还给CentralCache以致refcount减为0,即span中所有对象都空闲时,则CentralCache将这个span还给PageHeap。截取CentralFreeList::ReleaseToSpans()部分代码如下:
span->refcount--;
if (span->refcount == 0) {
Event(span, '#', 0);
counter_ -= ((span->length<<kPageShift) /
Static::sizemap()->ByteSizeForClass(span->sizeclass));
tcmalloc::DLL_Remove(span);
--num_spans_;
// Release central list lock while operating on pageheap
lock_.Unlock();
{
SpinLockHolder h(Static::pageheap_lock());
Static::pageheap()->Delete(span);
}
lock_.Lock();
}
CentralFreeList与ThreadCache的交互
一次移动多个对象,为了减少操作次数提高效率。
// Insert the specified range into the central freelist. N is the number of // elements in the range. RemoveRange() is the opposite operation. void InsertRange(void *start, void *end, int N); // Returns the actual number of fetched elements and sets *start and *end. int RemoveRange(void **start, void **end, int N);
start和end指定小对象链表的范围,N指定小对象的数量。批量移动小对象可以均摊锁操作的开销。
当ThreadCache中某个size class没有空闲对象可用时,需要从CentralFreeList获取N个对象
const int batch_size = Static::sizemap()->num_objects_to_move(cl); const int num_to_move = min<int>(list->max_length(), batch_size); void *start, *end; int fetch_count = Static::central_cache()[cl].RemoveRange(&start, &end, num_to_move);
移动数量N为max_length和batch_size的最小值。
假设只考虑内存分配的情况,一开始移动1个,然后是2个、3个,以此类推,同时max_length每次也加1,直到达到batch_size后,每次移动batch_size个对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号