关于算法与数据结构的整理1.0
位操作
& 与运算
两个位上都为1时,结果才为1
| 或运算
两个位上都为0时,结果才为0
异或运算(重要)
相同为0,不同为1
无进位相加
0 ^ N = N; N ^ N = 0;异或满足交换律、结合律
~ 取反运算
0变1 1变0
二分法
注意点:
mid = (L + R)/2 (L + R)有可能会溢出
上式写成mid = L + (R - L)/2 ————>mid = L + (R - L)>>1
- 时间复杂度:O(log n)
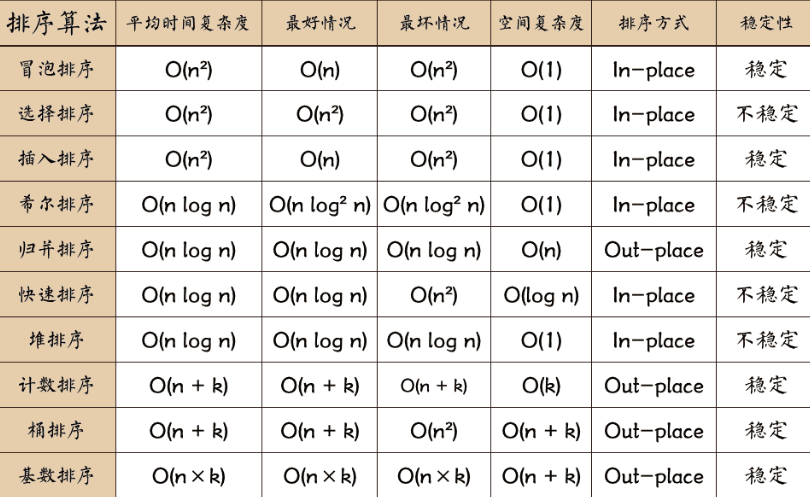
十大排序算法
https://www.cnblogs.com/guoyaohua/p/8600214.html
选择排序 (每一次外循环要把当前循环最小的值排到队首)
思想概述
每次循环溜一圈,把遍历到较小值的下标保存,遍历到尾值后,将保存的下标最小值与最左边的值(未排序过的)交换
每次找到先记录位置,遍历完一圈后再交换
双层循环
public static void selectionSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
for (int i = 0; i < arr.length - 1; i++) {
int minIndex = i;
for (int j = i + 1; j < arr.length; j++) {
minIndex = arr[j] < arr[minIndex] ? j : minIndex;
}
swap(arr, i, minIndex);
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
-
时间复杂度:O(n^2)
-
空间复杂度:O(1)
冒泡排序 (每一次外循环要把当前循环最大的值排到队尾)
思想概述
每次把最大值的冒泡到最右边
每当遍历到较大的就交换
public static void bubbleSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
for (int e = arr.length - 1; e > 0; e--) {
for (int i = 0; i < e; i++) {
if (arr[i] > arr[i + 1]) {
swap(arr, i, i + 1);
}
}
}
}
public static void swap(int[] arr, int i, int j) {
arr[i] = arr[i] ^ arr[j];
arr[j] = arr[i] ^ arr[j];
arr[i] = arr[i] ^ arr[j];
}
-
时间复杂度:O(n^2)
-
空间复杂度:O(1)
插入排序 (打扑克:每次外循环要把已经排到当前位置及之前的数排好顺序)
从前向后遍历,依次做到当前位置上向前数的数全都有序
把最小的排到前面
public static void insertionSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
//i = 1:0~0已经有序
//使0~i有序
for (int i = 1; i < arr.length; i++) {//使0~i做到有序
for (int j = i - 1; j >= 0 && arr[j] > arr[j + 1]; j--) { //每次排到i位置,i之前的位置上的数已经有序
swap(arr, j, j + 1);
}
}
}
//i和j是一个位置的话,会出错
public static void swap(int[] arr, int i, int j) {
arr[i] = arr[i] ^ arr[j];
arr[j] = arr[i] ^ arr[j];
arr[i] = arr[i] ^ arr[j];
}
-
时间复杂度:O(n^2)
- 数据状况不同,时间复杂度不同
-
空间复杂度:O(1)
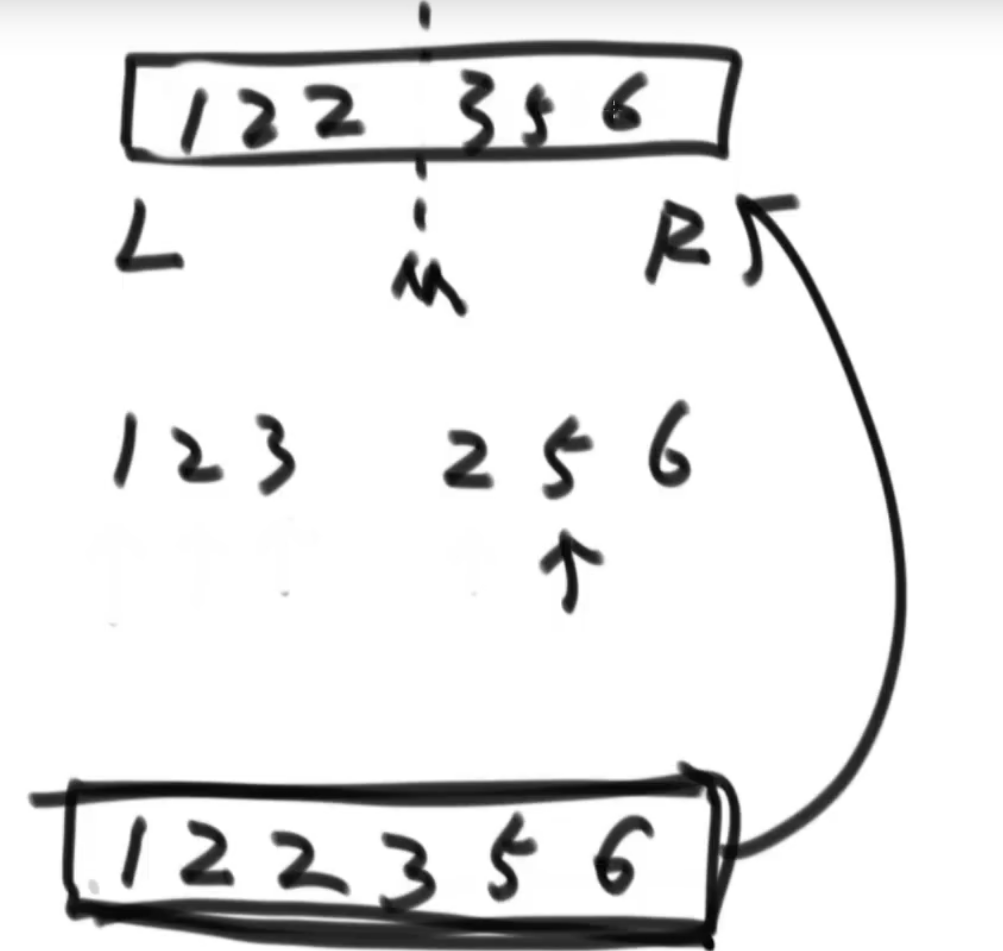
归并排序
思路:递归 + 二分
public static void mergeSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
mergeSort(arr, 0, arr.length - 1);
}
public static void mergeSort(int[] arr, int l, int r) {
if (l == r) {
return;
}
int mid = l + ((r - l) >> 1;
mergeSort(arr, l, mid);
mergeSort(arr, mid + 1, r);
merge(arr, l, mid, r);
}
public static void merge(int[] arr, int l, int m, int r) {
int[] help = new int[r - l + 1];
int i = 0;
int p1 = l;
int p2 = m + 1;
while (p1 <= m && p2 <= r) { // p1和p2都没有越界
help[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
}
while (p1 <= m) { // p1没有越界、p2越界
help[i++] = arr[p1++];
}
while (p2 <= r) { // p2没有越界、p1越界
help[i++] = arr[p2++];
}
for (i = 0; i < help.length; i++) {
arr[l + i] = help[i];
}
}
注意点
int a[3] = {0, 1, 2};
int i = 0;
a[i++] = a[2]//数组变成{2, 1, 2}显然在这里是先进行a[i] = a[2]的赋值操作,再对i进行加一操作。
a[++i] = a[2]//数组变成{0, 2, 2}显然在这里是先进行i加一操作,再进行a[i] = a[2]的赋值操作。
归并排序需要借助额外空间

关于快排的算法题


——————————————————————————————————————————
——————————————————————————————————————————

快速排序
思想:
不改进的快速排序
1)把数组范围中的最后一个数作为划分值,然后把数组分成三个部分:
左侧<划分值、中间==划分值、右侧>划分值
2)对左侧范围和右侧范围,递归执行
分析
1)划分值越靠近两侧,复杂度越高;划分值越靠近中间,复杂度越低
2)可以轻而易举的举出最差的例子,所以不改进的快速排序时间复杂度为O(N^2)随机快速排序 (改进的快速排序)
1)在数组范围中,等概率随机选一个数作为划分值,将该数与原本数组最后一个数做交换,然后把数组分成三个部分:
左侧<划分值、中间==划分值、右侧>划分值
2)对左侧范围和右侧范围,递归执行
3)时间复杂度为O(N*logN)
public static void quickSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
quickSort(arr, 0, arr.length - 1);
}
//arr[l...r]排好序
public static void quickSort(int[] arr, int l, int r) {
if (l < r) {
swap(arr, l + (int) (Math.random() * (r - l + 1)), r);//在数组范围中,等概率随机选一个数作为划分值,将该数与原本数组最后一个数做交换,然后把数组分成三个部分
int[] p = partition(arr, l, r);
quickSort(arr, l, p[0] - 1);// <区域
quickSort(arr, p[1] + 1, r);// >区域
}
}
//这是处理一个arr[l..r]的分片函数
//默认以arr[r]做划分,arr[r]-> p <p == p >p
//返回等于区域(左边界的下标、右边界的下标),所以返回一个长度为2的数组res,res[0] res[1]
public static int[] partition(int[] arr, int l, int r) {
int less = l - 1; // <区右边界: 最开始 < 区域右边界指向0角标的前一个
int more = r; // >区左边界: 最开始 > 区域左边界指向基准数
while (l < more) { // l表示当前数
if (arr[l] < arr[r]) {
swap(arr, ++less, l++);
} else if (arr[l] > arr[r]) {
swap(arr, --more, l);
} else {
l++;
}
}
swap(arr, more, r);
return new int[] { less + 1, more };
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
堆结构及堆排序
1,堆结构就是用数组实现的完全二叉树结构
2,完全二叉树中如果每棵子树的最大值都在顶部就是大根堆
3,完全二叉树中如果每棵子树的最小值都在顶部就是小根堆
4,堆结构的heapInsert与heapify操作
5,堆结构的增大和减少
6,优先级队列结构,就是堆结构
堆排序
1,先让整个数组都变成大根堆结构,建立堆的过程:
1)从上到下的方法,时间复杂度为O(NlogN)
2)从下到上的方法,时间复杂度为O(N)
2,把堆的最大值和堆末尾的值交换,然后减少堆的大小之后,再去调
整堆,一直周而复始,时间复杂度为O(NlogN)
3,堆的大小减小成0之后,排序完成
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
for (int i = 0; i < arr.length; i++) {
heapInsert(arr, i);
}
int size = arr.length;
swap(arr, 0, --size);
while (size > 0) {
heapify(arr, 0, size);
swap(arr, 0, --size);
}
}
public static void heapInsert(int[] arr, int index) {
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) /2);
index = (index - 1)/2 ;
}
}
public static void heapify(int[] arr, int index, int size) { //堆化
int left = index * 2 + 1;
while (left < size) {
int largest = left + 1 < size && arr[left + 1] > arr[left] ? left + 1 : left;
largest = arr[largest] > arr[index] ? largest : index;
if (largest == index) {
break;
}
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
桶排序
不基于比较的排序,基于数据状况的排序
桶排序思想下的排序
1)计数排序
2)基数排序: 从个位一直到最高位排序,依次进桶 出桶
分析:
1)桶排序思想下的排序都是不基于比较的排序
2)时间复杂度为O(N),额外空间负载度O(M)
3)应用范围有限,需要样本的数据状况满足桶的划分
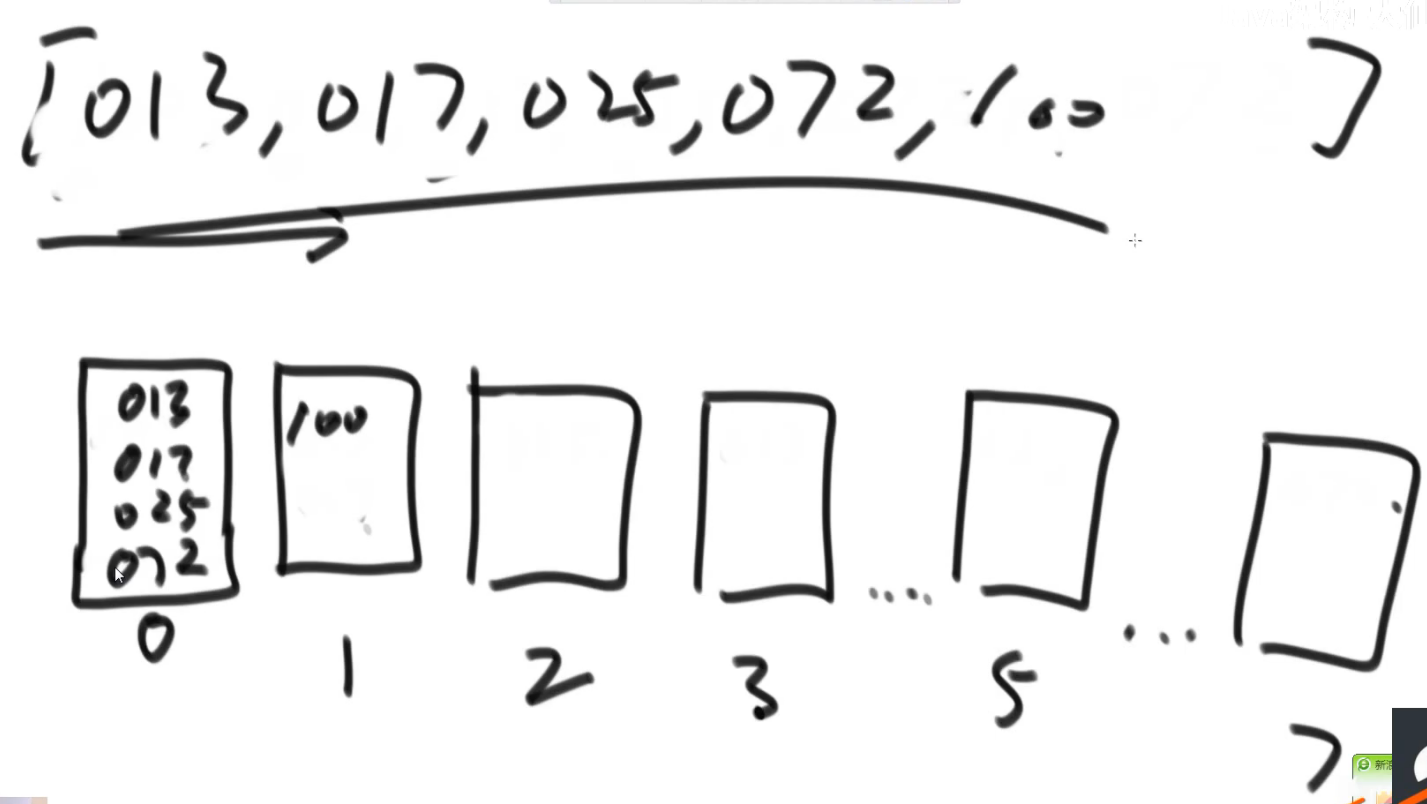
// only for no-negative value
public static void radixSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
radixSort(arr, 0, arr.length - 1, maxbits(arr));
}
public static int maxbits(int[] arr) { //统计最大值的十进制位数
int max = Integer.MIN_VALUE;
for (int i = 0; i < arr.length; i++) {
max = Math.max(max, arr[i]);
}
int res = 0;
while (max != 0) {
res++;
max /= 10;
}
return res;
}
public static void radixSort(int[] arr, int begin, int end, int digit) {
final int radix = 10;
int i = 0, j = 0;
//有多少个数准备多少个辅助空间
int[] bucket = new int[end - begin + 1];
for (int d = 1; d <= digit; d++) { //有多少位就进出几次 digit
//10个空间
//cont[0] 当前位(d位)是0的数字有多少个
//cont[1] 当前位(d位)是(0和1)的数字有多少个
//cont[0] 当前位(d位)是(0、1和2)的数字有多少个
//cont[i] 当前位(d位)是(0~i)的数字有多少个
int[] count = new int[radix];
for (i = begin; i <= end; i++) {
j = getDigit(arr[i], d);
count[j]++;
}
for (i = 1; i < radix; i++) {
count[i] = count[i] + count[i - 1];
}
for (i = end; i >= begin; i--) {
j = getDigit(arr[i], d);
bucket[count[j] - 1] = arr[i];
count[j]--;
}
for (i = begin, j = 0; i <= end; i++, j++) {
arr[i] = bucket[j];
}
}
}
总结
排序算法的稳定性及其汇总
同样值的个体之间,如果不因为排序而改变相对次序,就是这个排序是有稳定性的;否则就没有。
不具备稳定性的排序:
选择排序、快速排序、堆排序
具备稳定性的排序:
冒泡排序、插入排序、归并排序、一切桶排序思想下的排序
目前没有找到时间复杂度O(N*logN),额外空间复杂度O(1),又稳定的排序。
常见的坑
1,归并排序的额外空间复杂度可以变成O(1),但是非常难,不需要掌握,有兴趣可以搜“归并排序 内部缓存法”
2,“原地归并排序”的帖子都是垃圾,会让归并排序的时间复杂度变成O(N^2)
3,快速排序可以做到稳定性问题,但是非常难,不需要掌握, 可以搜“01stable sort”
4,所有的改进都不重要,因为目前没有找到时间复杂度O(N*logN),额外空间复杂度O(1),又稳定的排序。
5,有一道题目,是奇数放在数组左边,偶数放在数组右边,还要求原始的相对次序不变,碰到这个问题,可以怼面试官。

栈stack,队列queue,双端队列deque
队列(queue)简述
https://www.cnblogs.com/shamo89/p/6774080.html
队列(queue)是一种常用的数据结构,可以将队列看做是一种特殊的线性表,该结构遵循的先进先出原则。Java中,LinkedList实现了Queue接口,因为LinkedList进行插入、删除操作效率较高。
| 抛出异常 | 返回特殊值 | |
|---|---|---|
| 插入 | add(e) | offer(e) |
| 移除 | remove() | poll() |
| 检查 | element() | peek() |
-
队列通常(但并非一定)以 FIFO(先进先出)的方式排序各个元素。不过优先级队列和 LIFO 队列(或堆栈)例外,前者根据提供的比较器或元素的自然顺序对元素进行排序,后者按 LIFO(后进先出)的方式对元素进行排序。无论使用哪种排序方式,队列的头 都是调用 remove() 或 poll() 所移除的元素。在 FIFO 队列中,所有的新元素都插入队列的末尾。其他种类的队列可能使用不同的元素放置规则。每个 Queue 实现必须指定其顺序属性。
-
Queue 接口并未定义阻塞队列的方法,而这在并发编程中是很常见的。BlockingQueue 接口定义了那些等待元素出现或等待队列中有可用空间的方法,这些方法扩展了此接口。
-
Queue 实现通常不允许插入 null 元素,尽管某些实现(如 LinkedList)并不禁止插入 null。即使在允许 null 的实现中,也不应该将 null 插入到 Queue 中,因为 null 也用作 poll 方法的一个特殊返回值,表明队列不包含元素。
-
Queue 实现通常未定义 equals 和 hashCode 方法的基于元素的版本,而是从 Object 类继承了基于身份的版本,因为对于具有相同元素但有不同排序属性的队列而言,基于元素的相等性并非总是定义良好的。
-
Queue常用方法:
- boolean add(E e);将指定的元素插入此队列(如果立即可行且不会违反容量限制),在成功时返回 true,如果当前没有可用的空间,则抛出 IllegalStateException。
- boolean offer(E e);将指定的元素插入此队列(如果立即可行且不会违反容量限制),当使用有容量限制的队列时,此方法通常要优于 add(E),后者可能无法插入元素,而只是抛出一个异常。
- E remove();获取并移除此队列的头。
- E poll();获取并移除此队列的头,如果此队列为空,则返回 null。
- E element();获取,但是不移除此队列的头。
- E peek();获取但不移除此队列的头;如果此队列为空,则返回 null。
双端队列(Deque)简述
双向队列(Deque),是Queue的一个子接口,双向队列是指该队列两端的元素既能入队(offer)也能出队(poll),如果将Deque限制为只能从一端入队和出队,则可实现栈的数据结构。对于栈而言,有入栈(push)和出栈(pop),遵循先进后出原则。
一个线性 collection,支持在两端插入和移除元素。名称 deque 是“double ended queue(双端队列)”的缩写,通常读为“deck”。大多数 Deque 实现对于它们能够包含的元素数没有固定限制,但此接口既支持有容量限制的双端队列,也支持没有固定大小限制的双端队列。
此接口定义在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是专为使用有容量限制的 Deque 实现设计的;在大多数实现中,插入操作不能失败
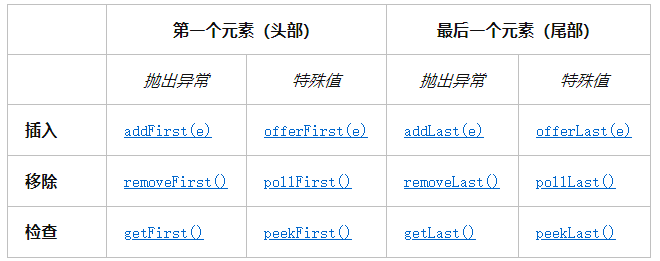
此接口扩展了 Queue 接口。在将双端队列用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。
栈(stack)实现
双端队列也可用作 LIFO(后进先出)堆栈。应优先使用此接口而不是遗留 Stack 类。在将双端队列用作堆栈时,元素被推入双端队列的开头并从双端队列开头弹出。堆栈方法完全等效于 Deque 方法,如下表所示:
| 堆栈方法 | 等效 Deque 方法 |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
注意,在将双端队列用作队列或堆栈时,peek 方法同样正常工作;无论哪种情况下,都从双端队列的开头抽取元素。
此接口提供了两种移除内部元素的方法:removeFirstOccurrence 和 removeLastOccurrence。
与 List 接口不同,此接口不支持通过索引访问元素。
虽然 Deque 实现没有严格要求禁止插入 null 元素,但建议最好这样做。建议任何事实上允许 null 元素的 Deque 实现用户最好不 要利用插入 null 的功能。这是因为各种方法会将 null 用作特殊的返回值来指示双端队列为空。
Deque 实现通常不定义基于元素的 equals 和 hashCode 方法,而是从 Object 类继承基于身份的 equals 和 hashCode 方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号